
Introduction
OpenAI Whisper excels in converting speech from various media files, including both audio and video, into written text. This tutorial will guide you through the essential and more sophisticated uses of the Whisper command, facilitating high-accuracy transcriptions.
Mastering Whisper for Media Transcription
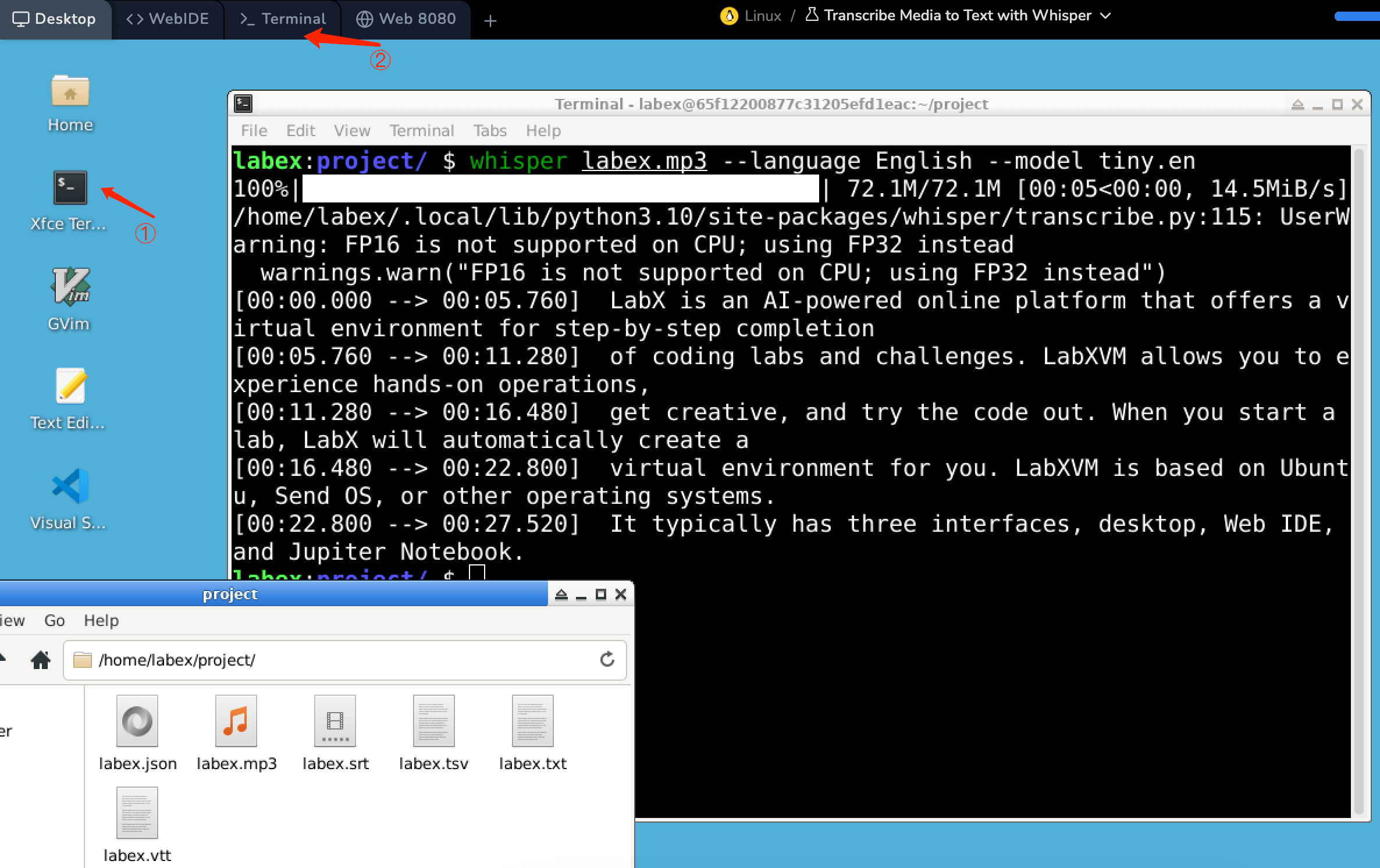
There is an audio labex.mp3 in /home/labex/project, open the terminal ( ① or ② in the figure ) in the environment and enter the following command:
whisper labex.mp3 --language English --model tiny.en
In this command, whisper is instructed to transcribe the media file labex.mp3.
- The
--languageparameter is set to English, indicating the language spoken in the media. - The
--modeloption selects the Whisper model to use, withtiny.enbeing a smaller, faster model optimized for English language that is suitable for quick tasks or less powerful hardware.
After executing the Whisper command to transcribe media content, several files can be generated in /home/labex/project, each serving a distinct purpose and format for the transcribed text. Here's an overview of each file type:
- output.json: This file contains the detailed transcription results in JSON format, which is a lightweight data interchange format that's easy to read and write for humans and easy to parse and generate for machines. The JSON file includes not just the transcribed text but also additional metadata such as timestamps, confidence scores, and possibly speaker identification. This format is particularly useful for applications that require detailed processing or analysis of the transcription results, such as for generating subtitles with precise timing or for analyzing speech patterns.
- output.srt: The SRT (SubRip Subtitle) file format is used for representing subtitles or captions. Each entry in an SRT file consists of a sequence number, the time range during which the text should be displayed, and the text itself. SRT files are widely supported by video playback software and platforms, making this format ideal for adding subtitles to videos.
- output.tsv: TSV stands for Tab-Separated Values. This format is similar to CSV (Comma-Separated Values) but uses tabs as delimiters between data fields. An output.tsv file from Whisper might contain transcribed text along with timing information and confidence scores, separated by tabs. This format can be useful for data analysis tasks or for importing the transcription results into databases or spreadsheets.
- output.txt: This is a plain text file containing just the transcribed text without any timestamps or metadata. The simplicity of this format makes it suitable for applications where the text's content is more important than the timing or where the text needs to be read or processed by humans or basic text-processing software.
- output.vtt: VTT (Web Video Text Tracks) is another subtitle file format similar to SRT but with more features. It's the standard format for HTML5 video tag captions and offers support for styling and positioning of subtitles. The VTT format is particularly useful for web video content, as it allows for a richer viewing experience with customizable subtitles.
Each of these files serves different use cases, from simple text documents to detailed analyses or video subtitling, providing flexibility in how the transcription results are utilized.
Summary
This tutorial walked you through using OpenAI Whisper for transcribing content from media files into text. Starting from the basics, we learned to transcribe a simple English media file. We then advanced to explore additional features for optimizing the transcription process, such as choosing different models and batch processing. Whisper stands out as a versatile tool for transcribing a wide array of media files with ease.


