
はじめに
この実験は主に Hadoop の基礎に関するもので、Linux の基礎を持つ学生を対象に、Hadoop ソフトウェアシステムのアーキテクチャと基本的な展開方法を理解するために書かれています。
本文書のサンプルコードはすべて自分で入力してください。できるだけコピー&ペーストをせずにください。これによってのみ、コードに慣れることができます。問題がある場合は、文書を注意深く確認してください。そうでない場合は、フォーラムで助けを求めて交流してください。
Hadoop の紹介
Apache 2.0 ライセンスの下でリリースされた Apache Hadoop は、データ集約型の分散アプリケーションをサポートするオープンソースソフトウェアフレームワークです。
Apache Hadoop ソフトウェアライブラリは、単純なプログラミングモデルを使用して、コンピューティングクラスタ全体で大規模なデータセットの分散処理を可能にするフレームワークです。それは、1 台のサーバーから数千台のマシンまで拡張できるように設計されており、各マシンがローカルコンピューティングとストレージを提供し、高可用性を提供するハードウェアに依存しないようになっています。
コアコンセプト
Hadoop プロジェクトは主に以下の 4 つのモジュールで構成されています。
- Hadoop Common:他の Hadoop モジュールに対するサポートを提供する共通アプリケーション。
- **Hadoop Distributed File System (HDFS)**:アプリケーションデータへの高スループットアクセスを提供する分散型ファイルシステム。
- Hadoop YARN:タスクスケジューリングとクラスタリソース管理フレームワーク。
- Hadoop MapReduce:YARN に基づく大規模なデータセット並列計算フレームワーク。
Hadoop に初めて触れるユーザーは、HDFS と MapReduce に焦点を当てる必要があります。分散コンピューティングフレームワークとして、HDFS はフレームワークのデータの保存要件を満たし、MapReduce はフレームワークのデータの計算要件を満たします。
次の図は、Hadoop クラスタの基本アーキテクチャを示しています。
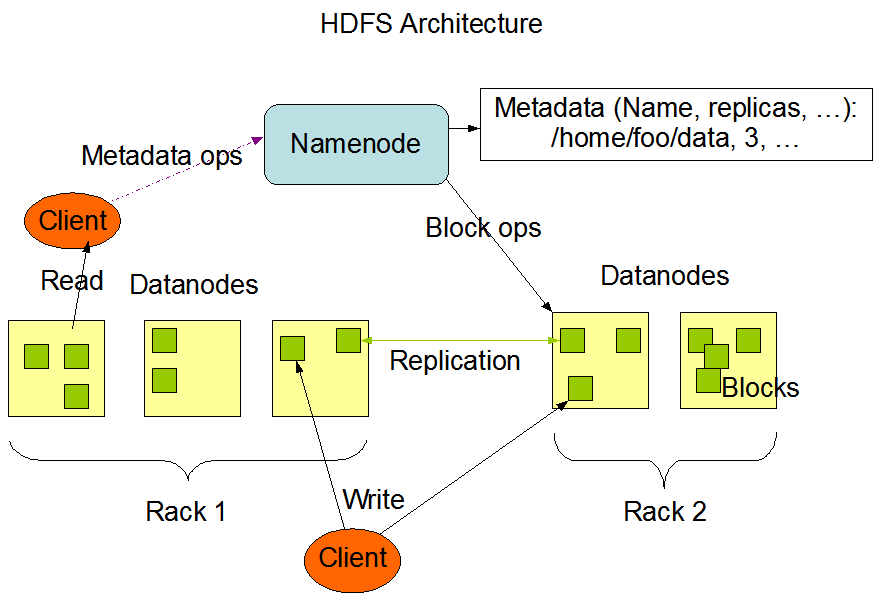
この画像は Hadoop の公式サイトから引用しています。
Hadoop エコシステム
Facebook が Hadoop に基づいて Hive データリポジトリを派生させたように、コミュニティにはそれに関連する多くのオープンソースプロジェクトがあります。最近のアクティブなプロジェクトをいくつか挙げると、以下の通りです。
- HBase:大規模なテーブルの構造化データ保存をサポートする拡張可能な分散型データベース。
- Hive:データの要約と一時的な照会を提供するデータリポジトリインフラストラクチャ。
- Pig:並列計算用の高度なデータフロー言語と実行フレームワーク。
- ZooKeeper:分散アプリケーション用の高性能なコーディネーションサービス。
- Spark:単純で表現力のあるプログラミングモデルを持ち、データ ETL(抽出、変換、ロード)、機械学習、ストリーム処理、グラフィックスコンピューティングをサポートする高速で多用途な Hadoop データ計算エンジン。
この実験では、Hadoop から始めて、関連コンポーネントの基本的な使い方を紹介します。
Hadoop と Spark の使用シナリオに重複があるという疑問を持つ人もいるかもしれませんが、Hadoop の動作パターンとプログラミングパターンを学ぶことは、Spark フレームワークの理解を深めるのに役立ちます。これが、まず Hadoop を学ぶべき理由です。
Hadoop の展開
初心者にとっては、2.0 以降の Hadoop バージョンに大きな違いはありません。このセクションでは、3.3.6 バージョンを例にとります。
Hadoop には主に 3 つの展開パターンがあります。
- スタンドアロンパターン:1 台のコンピュータ上の単一のプロセスで実行されます。
- 疑似分散パターン:1 台のコンピュータ上の複数のプロセスで実行されます。このパターンは、単一ノードの下で「マルチノード」シナリオをシミュレートします。
- 完全分散パターン:複数のコンピュータのそれぞれの単一のプロセスで実行されます。
次に、1 台のコンピュータに Hadoop 3.3.6 バージョンをインストールします。
ユーザーとユーザーグループの設定
デスクトップ上の「Xfce」ターミナルをダブルクリックして開き、次のコマンドを入力して、「hadoop」という名前のユーザーを作成します。
cd ~
sudo adduser hadoop
そして、プロンプトに従って「hadoop」ユーザーのパスワードを入力します。たとえば、パスワードを「hadoop」に設定します。
注:パスワードを入力する際、コマンドにはプロンプトが表示されません。入力が終わったら Enter キーを押すだけです。
次に、作成した「hadoop」ユーザーを「sudo」ユーザーグループに追加して、ユーザーにより高い権限を与えます。
sudo usermod -G sudo hadoop
次のコマンドを入力して、「hadoop」ユーザーが「sudo」グループに追加されたことを確認します。
sudo cat /etc/group | grep hadoop
次の出力が表示されるはずです。
sudo:x:27:shiyanlou,labex,hadoop
JDK のインストール
前のコンテンツでも述べた通り、Hadoop は主に Java で開発されています。したがって、それを実行するには Java 環境が必要です。
Hadoop の異なるバージョンは、Java バージョンの要件に微妙な違いがあります。自分の Hadoop に対してどのバージョンの JDK を選ぶべきかを知るには、Hadoop Wiki サイトのHadoop Java Versionsを読むことができます。
ユーザーを切り替えます。
su - hadoop
ターミナルに次のコマンドを入力して JDK 11 バージョンをインストールします。
sudo apt update
sudo apt install openjdk-11-jdk -y
正常にインストールが完了したら、現在の Java バージョンを確認します。
java -version
出力を表示します。
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
パスワード不要の SSH ログインの設定
SSHをインストールして設定する目的は、Hadoop がリモート管理デーモンに関連するスクリプトを実行しやすくすることです。これらのスクリプトにはsshdサービスが必要です。
設定する際は、まずhadoopユーザーに切り替えます。ターミナルに次のコマンドを入力して行います。
su hadoop
パスワードを入力するプロンプトが表示された場合は、ユーザー(hadoop)を作成する際に指定したパスワードを入力します。
ユーザーを正常に切り替えた後、コマンドプロンプトは上記のようになります。以降の手順はhadoopユーザーとして操作を行います。
次に、パスワード不要の SSH ログイン用のキーを生成します。
いわゆる「パスワード不要」とは、SSH の認証方式をパスワードログインからキーログインに変更することで、Hadoop の各コンポーネントが相互にアクセスする際にユーザーインタラクションを通じてパスワードを入力する必要がなくなり、多くの冗長な操作を省略できるようになります。
まず、ユーザーのホームディレクトリに切り替え、次にssh-keygenコマンドを使用して RSA キーを生成します。
ターミナルに次のコマンドを入力してください。
cd /home/hadoop
ssh-keygen -t rsa
キーの保存場所などの情報が表示された場合は、Enter キーを押してデフォルト値を使用してください。
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . =. o |
| .o o *. |
| o... + o |
| = +.S.. + |
| + + +++.. |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
キーが生成されると、ユーザーのホームディレクトリ直下の.sshディレクトリに公開キーが生成されます。
具体的な操作は以下の図に示されています。
次に、生成した公開キーをホスト認証レコードに追加するために、次のコマンドを入力し続けます。authorized_keysファイルに書き込み権限を与えてください。そうしないと、検証時に正常に実行されません。
cat.ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600.ssh/authorized_keys
追加が成功した後、localhostにログインしてみましょう。ターミナルに次のコマンドを入力してください。
ssh localhost
初めてログインすると、公開キーの指紋を確認するプロンプトが表示されますので、yesを入力して確認してください。その後、再度ログインすると、パスワード不要のログインになります。
...
Welcome to Alibaba Cloud Elastic Compute Service!
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
検証スクリプトを通過するために、変更を保存するにはhistory -wを入力するか、ターミナルを終了してください。
Hadoop のインストール
ここで、Hadoop のインストールパッケージをダウンロードできます。公式サイトでは、Hadoop の最新バージョンのダウンロードリンクが提供されています。また、ターミナルでwgetコマンドを使って直接パッケージをダウンロードすることもできます。
ターミナルに次のコマンドを入力してパッケージをダウンロードします。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
ダウンロードが完了したら、tarコマンドを使ってパッケージを展開します。
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
ターミナルでdirname $(dirname $(readlink -f $(which java)))コマンドを実行することで、JAVA_HOMEの場所を見つけることができます。
dirname $(readlink -f $(which java))
次に、ターミナルでテキストエディタで.zshrcファイルを開きます。
vim /home/hadoop/.bashrc
/home/hadoop/.bashrcファイルの末尾に次の内容を追加します。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
vimエディタを保存して終了します。そして、ターミナルでsourceコマンドを入力して新しく追加した環境変数を有効にします。
source /home/hadoop/.bashrc
ターミナルでhadoop versionコマンドを実行してインストールを確認します。
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
疑似分散パターンの設定
ほとんどの場合、Hadoop はクラスタ環境で使用されます。つまり、複数のノードに Hadoop を展開する必要があります。同時に、Hadoop は疑似分散パターンで単一ノード上でも実行でき、複数の独立した Java プロセスを通じてマルチノードシナリオをシミュレートします。初期の学習段階では、異なるノードを作成するために多くのリソースを費やす必要はありません。したがって、このセクションとその後の章では、主に疑似分散パターンを使って Hadoop の「クラスタ」展開を行います。
ディレクトリを作成する
まず、Hadoop ユーザーのホームディレクトリ内にnamenodeとdatanodeのディレクトリを作成します。以下のコマンドを実行してこれらのディレクトリを作成します。
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
次に、Hadoop の設定ファイルを編集して、疑似分散パターンで実行するようにします。
core-site.xmlを編集する
ターミナルでテキストエディタでcore-site.xmlファイルを開きます。
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
設定ファイルで、configurationタグの値を以下の内容に変更します。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
fs.defaultFS設定項目は、クラスタがデフォルトで使用するファイルシステムの場所を示すために使用されます。
編集後、ファイルを保存してvimを終了します。
hdfs-site.xmlを編集する
別の設定ファイルhdfs-site.xmlを開きます。
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
設定ファイルで、configurationタグの値を以下のように変更します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
この設定項目は、HDFS におけるファイルコピー数を示すために使用されます。デフォルトでは3です。単一ノード上で疑似分散方式で展開しているため、1に変更します。
編集後、ファイルを保存してvimを終了します。
hadoop-env.shを編集する
次にhadoop-env.shファイルを編集します。
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
JAVA_HOMEの値をインストールされた JDK の実際の場所、つまり/usr/lib/jvm/java-11-openjdk-amd64に変更します。
注:インストールされた JDK の実際の場所を確認するには、
echo $JAVA_HOMEコマンドを使用できます。
編集後、ファイルを保存してvimエディタを終了します。
yarn-site.xmlを編集する
次にyarn-site.xmlファイルを編集します。
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
configurationタグに以下の内容を追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
編集後、ファイルを保存してvimエディタを終了します。
mapred-site.xmlを編集する
最後に、mapred-site.xmlファイルを編集する必要があります。
vimエディタでファイルを開きます。
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
同様に、configurationタグに以下の内容を追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
編集後、ファイルを保存してvimエディタを終了します。
Hadoop 起動テスト
まず、デスクトップ上のXfceターミナルを開き、Hadoop ユーザーに切り替えます。
su -l hadoop
HDFS の初期化は主にフォーマットです。
/home/hadoop/hadoop/bin/hdfs namenode -format
ヒント:フォーマットする前に、HDFS データディレクトリを削除する必要があります。
このメッセージを見ると、成功したことがわかります。
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
検証スクリプトを通過するために、履歴を保存するにはhistory -wを入力するか、ターミナルを終了してください。
HDFS を起動する
HDFS の初期化が完了すると、ネームノードとデータノードのデーモンを起動できます。起動後、Hadoop アプリケーション(たとえばMapReduceタスク)は HDFS からファイルを読み書きできます。
ターミナルに次のコマンドを入力してデーモンを起動します。
/home/hadoop/hadoop/sbin/start-dfs.sh
出力を表示します。
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Hadoop が疑似分散パターンで正常に実行されていることを確認するには、Java のプロセスビューツールjpsを使用して、対応するプロセスが表示されるかどうかを確認します。
ターミナルに次のコマンドを入力します。
jps
図に示すように、ネームノード、データノード、セカンダリネームノードのプロセスが表示されれば、Hadoop のサービスが正常に動作していることを示します。
ログファイルと WebUI を表示する
Hadoop が起動に失敗した場合、またはタスク(その他)の実行中にエラーが報告された場合、ターミナルのプロンプト情報に加えて、ログを見ることが問題を特定するための最善の方法です。ほとんどの問題は、関連するソフトウェアのログを通じて原因と解決策を見つけることができます。ビッグデータの分野の学習者として、ログを分析する能力は、コンピューティングフレームワークを学ぶ能力と同じくらい重要であり、真摯に受け止める必要があります。
Hadoop のデーモンログの既定の出力は、インストールディレクトリの下のログディレクトリ(logs)にあります。ターミナルに次のコマンドを入力してログディレクトリに移動します。
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
任意のログファイルを表示するには、vimエディタを使用できます。
HDFS が起動された後、クラスタの状態を表示する Web ページも内部 Web サービスによって提供されます。LabEx VM のトップに切り替え、「Web 8088」をクリックして Web ページを開きます。
Web ページを開いた後、クラスタの概要やデータノードの状態などを確認できます。
ページ上部のメニューをクリックして、ヒントや機能を探検してください。
検証スクリプトを通過するために、履歴を保存するにはhistory -wを入力するか、ターミナルを終了してください。
HDFS ファイルアップロードテスト
HDFS が稼働していると、ファイルシステムと考えることができます。ここでは、ファイルアップロード機能をテストするために、ディレクトリを作成(1 段階ごとに深さを 1 段階下げて、必要なディレクトリ階層まで)し、Linux システム内のいくつかのファイルを HDFS にアップロードしてみます。
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
ディレクトリが正常に作成された後、hdfs dfs -putコマンドを使用して、ローカルディスク上のファイル(ここではランダムに選択された Hadoop 設定ファイル)を HDFS にアップロードします。
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
PI テストケース
現実世界の生産環境に展開され、現実世界の問題を解決する Hadoop アプリケーションの大部分は、WordCountに代表される MapReduce プログラミングモデルに基づいています。したがって、WordCountを Hadoop の入門用の「HelloWorld」プログラムとして使用することができます。または、独自の考えを加えて特定の問題を解決することもできます。
タスクを開始する
前節の最後では、例としていくつかの設定ファイルを HDFS にアップロードしました。次に、これらのファイルの単語頻度統計を取得し、フィルタリングルールに従って出力するために、PIテストケースを実行してみましょう。
まず、ターミナルでYARN計算サービスを起動します。
/home/hadoop/hadoop/sbin/start-yarn.sh
次に、次のコマンドを入力してタスクを開始します。
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
出力結果を表示します。
Estimated value of Pi is 3.55555555555555555556
上記のパラメータのうち、パスに関するパラメータは 3 つあります。それらは、jarパッケージの場所、入力ファイルの場所、および出力結果の保存場所です。パスを指定する際は、絶対パスを指定する習慣を養う必要があります。これにより、迅速に問題を特定し、作業をすぐに引き渡すことができます。
タスクが完了すると、結果を確認できます。
HDFS サービスを終了する
計算が終了した後、HDFS 上のファイルを使用する他のソフトウェアプログラムがない場合、HDFS デーモンを適切に終了する必要があります。
分散クラスタと関連するコンピューティングフレームワークのユーザとして、クラスタの起動と終了、ハードウェアとソフトウェアのインストール、またはどんな種類の更新にも関わるたびに、関連するハードウェアとソフトウェアの状態を積極的に確認する良い習慣を養う必要があります。
ターミナルで次のコマンドを使用して、HDFS と YARN デーモンを終了します。
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
検証スクリプトを通過するために、履歴を保存するにはhistory -wを入力するか、ターミナルを終了してください。
まとめ
この実験では、Hadoop のアーキテクチャ、単一パターンと疑似分散パターンのインストールと展開方法を紹介し、基本的なテストとして WordCount を実行しました。
この実験の主なポイントは以下の通りです。
- Hadoop アーキテクチャ
- Hadoop の主なモジュール
- Hadoop の単一パターンの使い方
- Hadoop 疑似分散パターンの展開
- HDFS の基本的な使い方
- WordCount テストケース
一般的に、Hadoop はビッグデータの分野で一般的に使用されるコンピューティングとストレージフレームワークです。その機能はさらに掘り下げて検討する必要があります。技術資料を参照する習慣を保ち、続きの学習を続けてください。


