
Introducción
Este laboratorio seguirá hablando sobre HDFS, uno de los componentes principales de Hadoop. Aprender este laboratorio te ayudará a comprender los principios de funcionamiento y las operaciones básicas de HDFS, así como los métodos de acceso a WebHDFS en la arquitectura de software de Hadoop.
Introducción a HDFS
Como su nombre indica, HDFS (Hadoop Distributed File System) es un componente de almacenamiento distribuido dentro del marco de Hadoop, y es tolerante a fallos y escalable.
HDFS se puede utilizar como parte de un clúster de Hadoop o como un sistema de archivos distribuidos universal y autónomo. Por ejemplo, HBase se construye sobre la base de HDFS y Spark también puede utilizar HDFS como una de las fuentes de datos. Aprender la arquitectura y las operaciones básicas de HDFS será de gran ayuda para la configuración, mejora y diagnóstico de clústers particulares.
HDFS es el almacenamiento distribuido utilizado por las aplicaciones de Hadoop, la fuente de datos y el destino de datos. Los clústers de HDFS se componen principalmente de NameNodes que administran los metadatos del sistema de archivos y DataNodes que almacenan los datos reales. La arquitectura se muestra en la siguiente imagen que describe los patrones de interacción entre NameNodes, DataNodes y Clients:
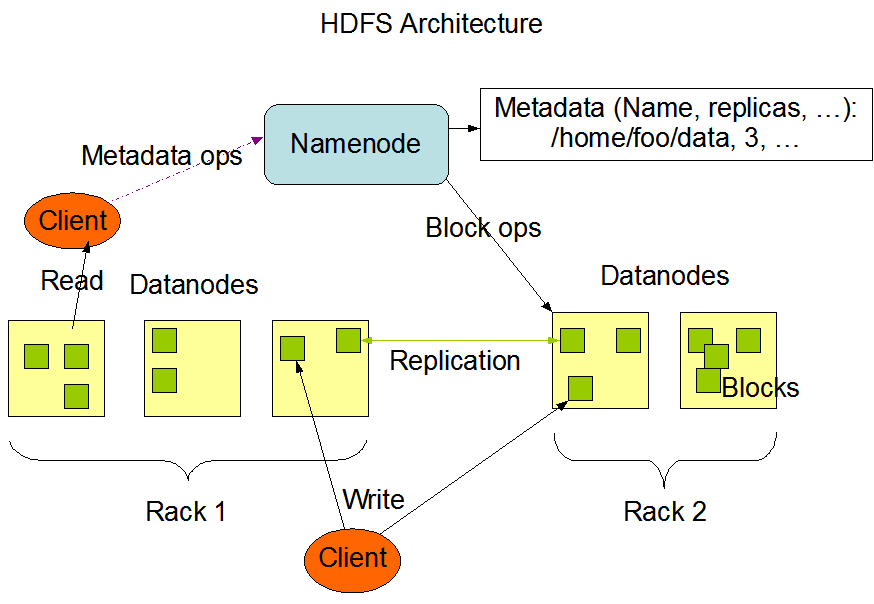 Esta imagen se cita del sitio web oficial de Hadoop.
Esta imagen se cita del sitio web oficial de Hadoop.
Resumen de la Introducción a HDFS:
- Visión general de HDFS: HDFS (Hadoop Distributed File System) es un componente de almacenamiento distribuido tolerante a fallos y escalable dentro del marco de Hadoop.
- Arquitectura: Los clústers de HDFS constan de NameNodes para administrar los metadatos y DataNodes para almacenar los datos reales. La arquitectura sigue un modelo Maestro/Espíritu con un NameNode y múltiples DataNodes.
- Almacenamiento de archivos: Los archivos en HDFS se dividen en bloques almacenados en los DataNodes, con un tamaño de bloque predeterminado de 64MB.
- Operaciones: El NameNode maneja las operaciones del espacio de nombres del sistema de archivos, mientras que los DataNodes administran las solicitudes de lectura y escritura de los clientes.
- Interacciones: Los clientes se comunican con el NameNode para obtener metadatos y se interactúan directamente con los DataNodes para obtener datos de archivos.
- Implementación: Típicamente, un nodo dedicado único ejecuta el NameNode, mientras que cada otro nodo ejecuta una instancia de DataNode. HDFS se construye utilizando Java, lo que proporciona portabilidad en diferentes entornos.
Comprender estos puntos clave sobre HDFS ayudará a configurar, optimizar y diagnosticar eficazmente los clústers de Hadoop.
El resumen del sistema de archivos
Espacio de nombres del sistema de archivos
- Organización jerárquica: Tanto HDFS como los sistemas de archivos tradicionales de Linux admiten una organización jerárquica de archivos con una estructura de árbol de directorios, lo que permite a los usuarios y aplicaciones crear directorios y almacenar archivos.
- Acceso y operaciones: Los usuarios pueden interactuar con HDFS a través de diversas interfaces de acceso, como líneas de comandos y APIs, lo que permite realizar operaciones como la creación, eliminación, movimiento y renombrado de archivos.
- Soporte de características: A partir de la versión 3.3.6, HDFS no implementa cuotas de usuario, derechos de acceso, enlaces duros o enlaces blandos. Sin embargo, futuras versiones pueden admitir estas características, ya que la arquitectura permite su implementación.
- Administración del NameNode: El NameNode en HDFS maneja todos los cambios en el espacio de nombres y propiedades del sistema de archivos, incluyendo la gestión del factor de replicación de archivos, que especifica el número de copias de un archivo que se deben mantener en HDFS.
Copia de datos
Al comienzo del desarrollo, HDFS se diseñó para almacenar archivos muy grandes en un gran clúster de manera transnodo y altamente confiable. Como se mencionó anteriormente, HDFS almacena archivos en bloques. Específicamente, almacena cada archivo como una secuencia de bloques. Excepto el último bloque, todos los bloques en el archivo son del mismo tamaño.
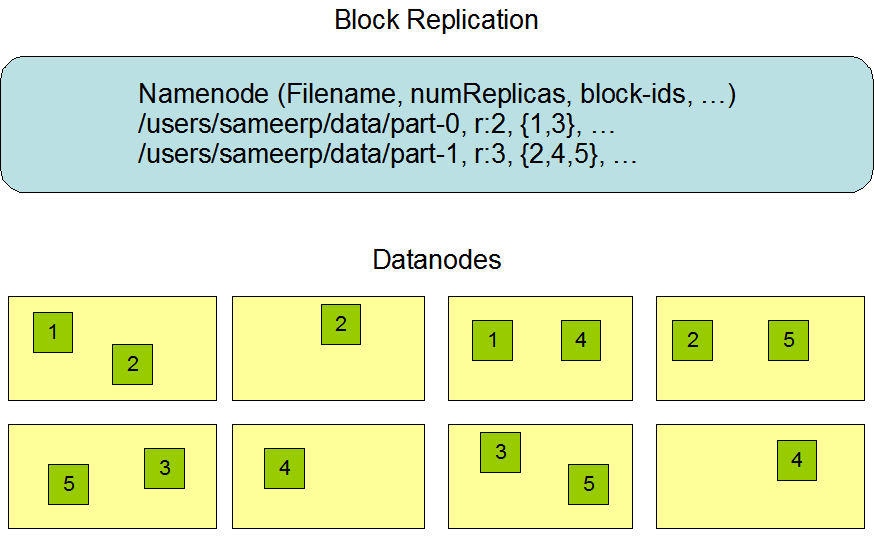 Esta imagen se cita del sitio web oficial de Hadoop.
Esta imagen se cita del sitio web oficial de Hadoop.
La replicación de datos y la alta disponibilidad de HDFS:
- Replicación de datos: En HDFS, los archivos se dividen en bloques que se replican en múltiples DataNodes para garantizar la tolerancia a fallos. El factor de replicación se puede especificar cuando se crea o modifica el archivo, y cada archivo tiene un único escritor en cualquier momento dado.
- Administración de replicación: El NameNode gestiona cómo se copian los bloques de archivos al recibir informes de latido cardíaco y estado de bloque de los DataNodes. Los DataNodes informan de su estado de trabajo a través de latidos cardíacos, y los informes de estado de bloque contienen información sobre todos los bloques almacenados en el DataNode.
- Alta disponibilidad: HDFS ofrece cierto grado de alta disponibilidad restaurando internamente copias de archivos perdidas de otras partes del clúster en caso de daño en el disco u otras fallas. Este mecanismo ayuda a mantener la integridad y la confiabilidad de los datos dentro del sistema de almacenamiento distribuido.
Persistencia de los metadatos del sistema de archivos
- Administración del espacio de nombres: El espacio de nombres de HDFS, que contiene los metadatos del sistema de archivos, se almacena en el NameNode. Cada cambio en los metadatos del sistema de archivos se registra en un EditLog, que persiste transacciones como la creación de archivos. El EditLog se almacena en el sistema de archivos local.
- FsImage: Todo el espacio de nombres del sistema de archivos, incluyendo la asignación de bloques a archivos y atributos, se almacena en un archivo llamado FsImage. Este archivo también se guarda en el sistema de archivos local donde reside el NameNode.
- Proceso de punto de control: El proceso de punto de control implica la lectura del FsImage y el EditLog desde el disco al inicio del NameNode. Todas las transacciones en el EditLog se aplican al FsImage en memoria, que luego se guarda de nuevo en el disco para la persistencia. Después de este proceso, el antiguo EditLog se puede truncar. En la versión actual (3.3.6), los puntos de control solo ocurren durante el inicio del NameNode, pero futuras versiones pueden introducir puntos de control periódicos para mejorar la confiabilidad y la consistencia de los datos.
Otras características
- Fundamento en TCP/IP: Todos los protocolos de comunicación en HDFS se construyen sobre el conjunto de protocolos TCP/IP, lo que garantiza un intercambio de datos confiable entre nodos en el sistema de archivos distribuido.
- Protocolo del cliente: La comunicación entre el cliente y el NameNode se facilita a través del Protocolo del cliente. El cliente inicia una conexión a puertos TCP configurables en el NameNode para interactuar con los metadatos del sistema de archivos.
- Protocolo del DataNode: La comunicación entre DataNodes y el NameNode se basa en el Protocolo del DataNode. Los DataNodes se comunican con el NameNode para informar de su estado, enviar señales de latido cardíaco y transferir bloques de datos como parte del sistema de almacenamiento distribuido.
- Llamada a procedimiento remoto (RPC): Tanto el Protocolo del cliente como el Protocolo del DataNode se abstraen utilizando mecanismos de Llamada a procedimiento remoto (RPC). El NameNode responde a solicitudes RPC iniciadas por DataNodes o clientes, manteniendo un papel pasivo en el proceso de comunicación.
A continuación se presentan algunos materiales para lectura adicional:
Cambiar de usuario
Antes de escribir el código de la tarea, primero debes cambiar al usuario hadoop. Haz doble clic para abrir la terminal Xfce en tu escritorio y escribe el siguiente comando. La contraseña del usuario hadoop es hadoop; se necesitará al cambiar de usuario:
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
Consejo: la contraseña del usuario hadoop es hadoop
Inicializando HDFS
El NameNode debe inicializarse antes de utilizar HDFS por primera vez. Esta operación se puede comparar con la forma de un disco, por lo que utilice este comando con precaución cuando almacene datos en HDFS.
De lo contrario, reinicie el experimento en esta sección. Utilice el "Entorno predeterminado" e inicialice HDFS con el siguiente comando:
/home/hadoop/hadoop/bin/hdfs namenode -format
Consejo: El comando anterior formateará el sistema de archivos HDFS, debe eliminar el directorio de datos de HDFS antes de ejecutar el comando.
Por lo tanto, debe detener los servicios de Hadoop y eliminar los datos de Hadoop.
stop-all.sh
rm -rf ~/hadoopdata
Cuando ve el siguiente mensaje, la inicialización está completa:
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Importando archivos
Dado que HDFS es un sistema de almacenamiento distribuido jerarquizado construido sobre discos locales, debes importar datos en él antes de utilizar HDFS.
La primera y más conveniente forma de preparar algunos archivos es utilizar el archivo de configuración de Hadoop como ejemplo.
Primero debes iniciar el demonio de HDFS:
/home/hadoop/hadoop/sbin/start-dfs.sh
Ver los servicios:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
Crea un directorio y copia los datos escribiendo el siguiente comando en la terminal:
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
Lista el contenido del directorio:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
Cualquier operación en HDFS comienza con hdfs dfs y se complementa con los parámetros de operación correspondientes. El parámetro más comúnmente utilizado es put, que se utiliza de la siguiente manera y se puede escribir en la terminal:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
Lista el contenido del directorio:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
La última /policy.xml del comando significa que el nombre del archivo almacenado en HDFS es policy.xml y la ruta es / (directorio raíz). Si quieres seguir utilizando el nombre de archivo anterior, puedes especificar la ruta / directamente.
Si necesitas subir múltiples archivos, puedes especificar la ruta de archivo del directorio local de forma continua y terminar con la ruta de almacenamiento objetivo de HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
Lista el contenido del directorio:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
Para especificar parámetros relacionados con la ruta, las reglas son las mismas que en el sistema Linux. Puedes utilizar comodines (por ejemplo, *.sh) para simplificar la operación.
Operaciones de archivos
Del mismo modo, puedes utilizar el parámetro -ls para listar los archivos en el directorio especificado:
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
Los archivos listados aquí pueden variar según el entorno del experimento.
Si necesitas ver el contenido de un archivo, puedes utilizar el parámetro cat. Lo más fácil de pensar es especificar directamente la ruta del archivo en HDFS. Si necesitas comparar directorios locales con archivos en HDFS, puedes especificar sus rutas por separado. Sin embargo, debe tenerse en cuenta que el directorio local debe comenzar con el indicador file://, seguido de la ruta del archivo (por ejemplo, /home/hadoop/.bashrc, no olvides el / al principio). De lo contrario, cualquier ruta especificada aquí se reconocerá por defecto como la ruta en HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
La salida es la siguiente:
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
Si necesitas copiar un archivo a otra ruta, puedes utilizar el parámetro cp:
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
Del mismo modo, si necesitas mover un archivo, utiliza el parámetro mv. Esto es básicamente lo mismo que el formato del comando del sistema de archivos de Linux:
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
Utiliza el parámetro lsr para listar el contenido del directorio actual, incluyendo el contenido de los subdirectorios. La salida es la siguiente:
hdfs dfs -lsr /
Si quieres agregar algún nuevo contenido a un archivo en HDFS, puedes utilizar el parámetro appendToFile. Y, al especificar la ruta del archivo local que se va a agregar, puedes especificar múltiples rutas. El último parámetro será el objeto al que se va a agregar. El archivo debe existir en HDFS, de lo contrario se generará un error:
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
Puedes utilizar el parámetro tail para ver el contenido de la cola del archivo (la parte final del archivo) para confirmar si la adición fue exitosa:
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
Ver la salida del comando tail:
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
Si necesitas eliminar un archivo o un directorio, utiliza el parámetro rm. Este parámetro también puede ir acompañado de -r y -f, que tienen los mismos significados que en el comando del sistema de archivos de Linux rm:
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
El contenido del archivo moved_file.txt se eliminará y el comando devolverá la siguiente salida 'Deleted /moved_file.txt'
Operaciones de directorio
En el contenido anterior, hemos aprendido cómo crear un directorio en HDFS. De hecho, si necesitas crear múltiples directorios a la vez, puedes directamente especificar las rutas de múltiples directorios como parámetros. El parámetro -p indica que su directorio padre se creará automáticamente si no existe:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
Si quieres ver cuánto espacio ocupa un determinado archivo o directorio, puedes utilizar el parámetro du:
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
La salida es la siguiente:
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
Exportando archivos
En la sección anterior, principalmente introdujimos las operaciones de archivos y directorios en HDFS. Si se realiza un cálculo con una aplicación como MapReduce y se genera un archivo que registra el resultado, puedes utilizar el parámetro get para exportarlo al directorio local del sistema Linux.
El primer parámetro de ruta aquí se refiere a la ruta en HDFS, y la última ruta se refiere a la ruta guardada en el directorio local:
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
Si la exportación es exitosa, puedes encontrar el archivo en tu directorio local:
cd ~
ls
La salida es la siguiente:
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Operación web de Hadoop
Interfaz de administración web
Cada NameNode o DataNode ejecuta internamente un servidor web que muestra información básica como el estado actual del clúster. En la configuración predeterminada, la página principal del NameNode es http://localhost:9870/. Muestra estadísticas básicas de los DataNodes y del clúster.
Abre un navegador web e ingresa lo siguiente en la barra de direcciones:
http://localhost:9870/
Puedes ver el número de nodos DataNode activos en el "clúster" actual en Resumen:
La interfaz web también se puede utilizar para explorar directorios y archivos dentro de HDFS. En la barra de menús superior, haz clic en el enlace “Explorar el sistema de archivos” debajo de “Utilidades”:
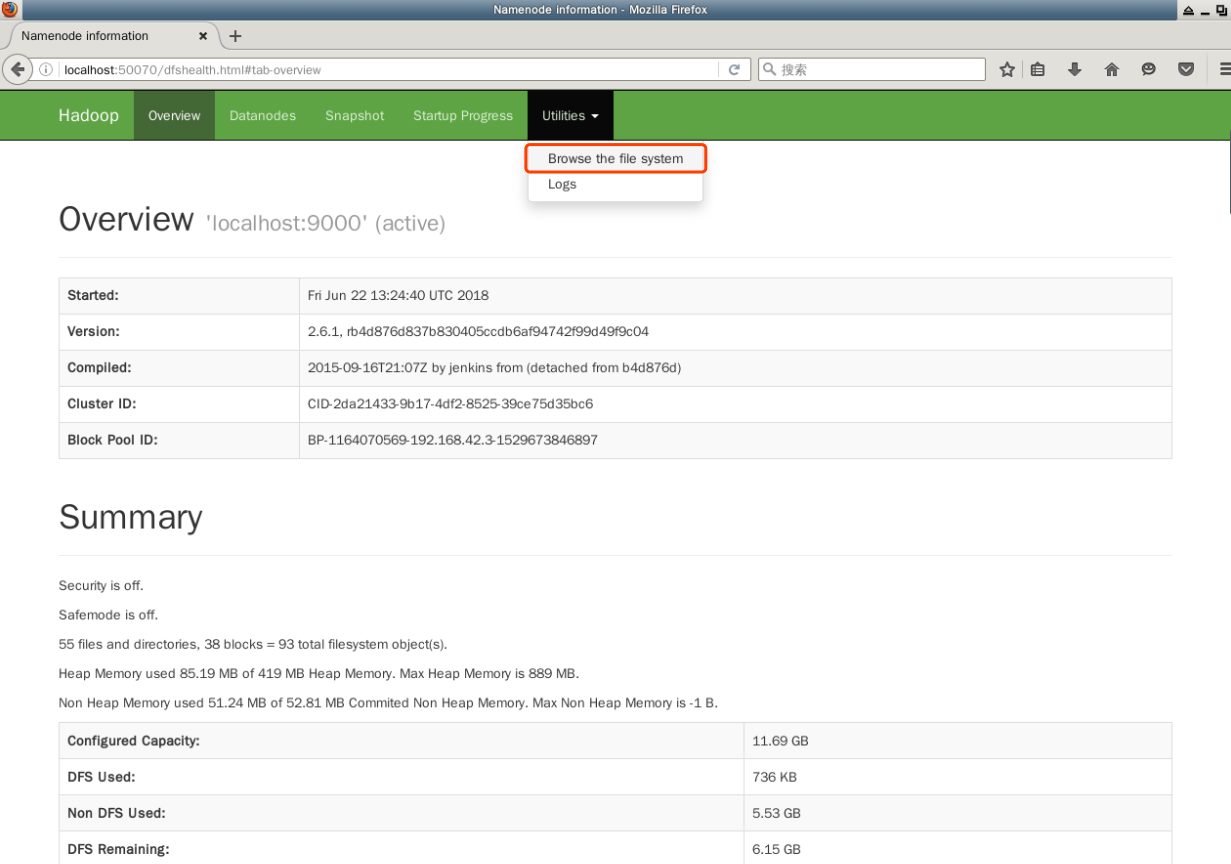
Cerrar un clúster de Hadoop
Ahora hemos terminado de introducir algunas de las operaciones básicas de WebHDFS. Puedes encontrar más instrucciones en la documentación de WebHDFS. Esta práctica ha llegado a su fin. Como costumbre, todavía necesitamos detener el clúster de Hadoop:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
Resumen
Esta práctica ha introducido la arquitectura de HDFS. Además, hemos aprendido los comandos básicos de operación de HDFS desde la línea de comandos y luego hemos accedido al patrón web de HDFS, lo cual ayudará a que HDFS funcione como un servicio de almacenamiento real para aplicaciones externas.
Esta práctica no lista ningún escenario de eliminación de archivos en WebHDFS. Puedes revisar la documentación por tu cuenta. Hay más funciones ocultas en la documentación oficial, así que asegúrate de mantener el interés por leer la documentación.
A continuación se presenta el material para lectura adicional:


