
Introduction
This lab will continue to talk about HDFS, one of the major Hadoop components. Learning this lab will help you understand the working principles and basic operations of HDFS, as well as access methods for WebHDFS in the Hadoop software architecture.
Introduction to HDFS
As its name shows, HDFS (Hadoop Distributed File System) is a component of distributed storage within the Hadoop framework, and it's fault tolerant and scalable.
HDFS can be used as part of a Hadoop cluster or as a stand-alone, universal distributed file system. For example, HBase is built on the basis of HDFS and Spark can also use HDFS as one of the data sources. Learning the architecture and basic operations of HDFS will be of great help for configuration, improvement and diagnostics of particular clusters.
HDFS is the distributed storage used by Hadoop applications, the source of data and the destination of data. HDFS clusters are mainly composed of NameNodes that manage file system metadata and DataNodes that store actual data. The architecture is shown in the following picture which depicts the interaction patterns among NameNodes, DataNodes and Clients:
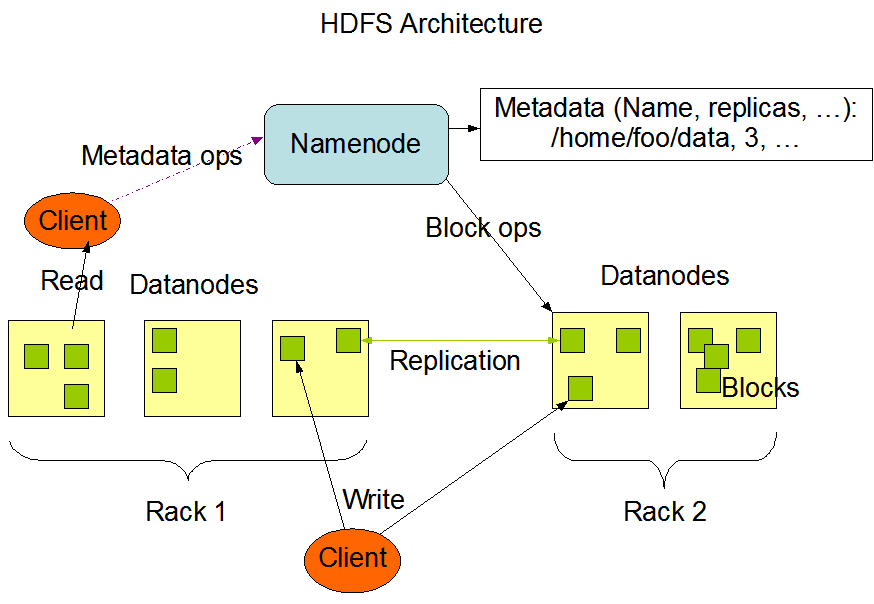 This picture is quoted from Hadoop's official website.
This picture is quoted from Hadoop's official website.
Summary of the Introduction to HDFS:
- HDFS Overview: HDFS (Hadoop Distributed File System) is a fault-tolerant and scalable distributed storage component within the Hadoop framework.
- Architecture: HDFS clusters consist of NameNodes for managing metadata and DataNodes for storing actual data. The architecture follows a Master/Slave model with one NameNode and multiple DataNodes.
- File Storage: Files in HDFS are divided into blocks stored across DataNodes, with a default block size of 64MB.
- Operations: NameNode handles file system namespace operations, while DataNodes manage read and write requests from clients.
- Interactions: Clients communicate with the NameNode for metadata and directly interact with DataNodes for file data.
- Deployment: Typically, a single dedicated node runs the NameNode, while each other node runs a DataNode instance. HDFS is built using Java, providing portability across different environments.
Understanding these key points about HDFS will help in configuring, optimizing, and diagnosing Hadoop clusters effectively.
The Summary of File System
File System Namespace
- Hierarchical Organization: Both HDFS and traditional Linux file systems support hierarchical file organization with a directory tree structure, allowing users and applications to create directories and store files.
- Access and Operations: Users can interact with HDFS through various access interfaces such as command lines and APIs, enabling operations like file creation, deletion, moving, and renaming.
- Feature Support: As of version 3.3.6, HDFS does not implement user quotas, access rights, hard links, or soft links. However, future releases may support these features, as the architecture allows for their implementation.
- NameNode Management: The NameNode in HDFS handles all changes to the file system namespace and properties, including managing the replication factor of files, which specifies the number of copies of a file to be maintained on HDFS.
Data Copy
At the beginning of development, HDFS was designed to store very large files in a large cluster in a cross-node, highly reliable way. As mentioned earlier, HDFS stores files in blocks. Specifically, it stores each file as a sequence of blocks. Except for the last block, all the blocks in the file are the same size.
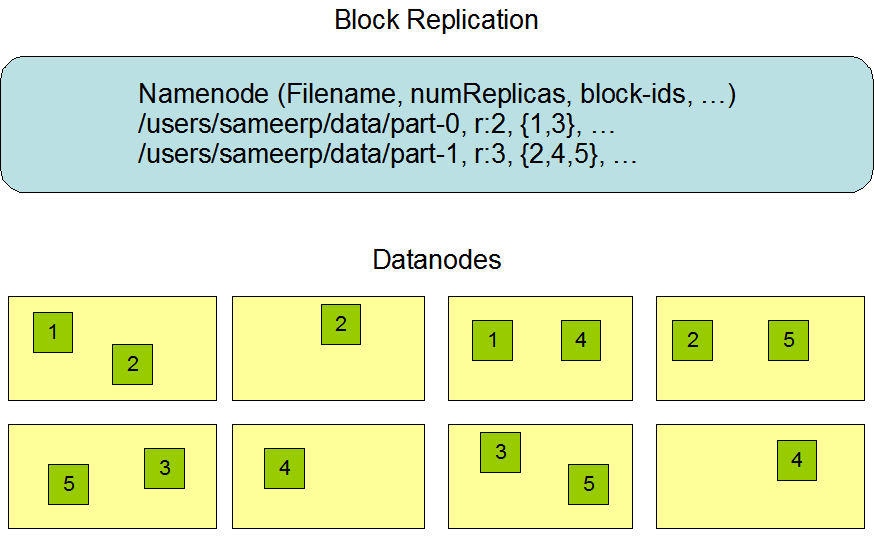 This picture is quoted from Hadoop's official website.
This picture is quoted from Hadoop's official website.
The HDFS Data Replication and High Availability:
- Data Replication: In HDFS, files are divided into blocks that are replicated across multiple DataNodes to ensure fault tolerance. The replication factor can be specified when the file is created or modified, with each file having a single writer at any given time.
- Replication Management: The NameNode manages how file blocks are copied by receiving heartbeat and block status reports from DataNodes. DataNodes report their working state through heartbeats, and block status reports contain information about all blocks stored on the DataNode.
- High Availability: HDFS provides a degree of high availability by internally restoring lost file copies from other parts of the cluster in case of disk corruption or other failures. This mechanism helps maintain data integrity and reliability within the distributed storage system.
Persistence of File System Metadata
- Namespace Management: The HDFS namespace, containing file system metadata, is stored in the NameNode. Every change in the file system metadata is recorded in an EditLog, which persists transactions like file creations. The EditLog is stored in the local file system.
- FsImage: The entire file system namespace, including block-to-file mapping and attributes, is stored in a file called FsImage. This file is also saved in the local file system where the NameNode resides.
- Checkpoint Process: The Checkpoint process involves reading the FsImage and EditLog from disk at NameNode startup. All transactions in the EditLog are applied to the in-memory FsImage, which is then saved back to disk for persistence. After this process, the old EditLog can be truncated. In the current version (3.3.6), checkpoints occur only during NameNode startup, but future versions may introduce periodic checkpointing for improved reliability and data consistency.
Other Features
- TCP/IP Foundation: All communication protocols in HDFS are built on top of the TCP/IP protocol suite, ensuring reliable data exchange between nodes in the distributed file system.
- Client Protocol: The communication between the client and the NameNode is facilitated through the Client protocol. The client initiates a connection to configurable TCP ports on the NameNode to interact with the file system metadata.
- DataNode Protocol: Communication between DataNodes and the NameNode relies on the DataNode protocol. DataNodes communicate with the NameNode to report their status, send heartbeat signals, and transfer data blocks as part of the distributed storage system.
- Remote Procedure Call (RPC): Both the Client protocol and DataNode protocol are abstracted using Remote Procedure Call (RPC) mechanisms. The NameNode responds to RPC requests initiated by DataNodes or clients, maintaining a passive role in the communication process.
The following is some material for extended reading:
Switch the User
Before writing the task code, you should first switch to the hadoop user. Double-click to open the Xfce terminal on your desktop and enter the following command. The password of the hadoop user is hadoop; it will be needed when switching users:
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
tip: the password of the hadoop user is hadoop
Initializing HDFS
The Namenode should be initialized before using HDFS for the first time. This operation can be compared to formatting a disk, so use this command with caution when storing data on HDFS.
Otherwise restart the experiment in this section. Use the "Default Environment" and initialize HDFS with the following command:
/home/hadoop/hadoop/bin/hdfs namenode -format
tip: The command above will format the HDFS file system, you need delete the HDFS data directory before running the command.
So you need stop the services about Hadoop and delete Hadoop data.
stop-all.sh
rm -rf ~/hadoopdata
When you see the following message, the initialization is complete:
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Importing Files
Since HDFS is a layered distributed storage system built on top of local disks, you need to import data into it before using HDFS.
The first and most convenient way to prepare some files is to use Hadoop's configuration file as an example.
First you need to start the HDFS daemon:
/home/hadoop/hadoop/sbin/start-dfs.sh
View the services:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
Create a directory and copy the data by entering the following command in the terminal:
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
List the contents of the directory:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
Any operation on the HDFS begins with hdfs dfs and is supplemented by the corresponding operational parameters. The most commonly used parameter is put, which is used as follows, and can be entered in the terminal:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
List the contents of the directory:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
The last /policy.xml of the command means that the file name stored in HDFS is policy.xml and the path is / (root directory). If you want to continue using the previous file name, you can specify the path / directly.
If you need to upload multiple files, you can specify the file path of the local directory continuously and end with the HDFS target storage path:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
List the contents of the directory:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
For specifying path-related parameters, the rules are the same as those in the Linux system. You can use wildcards (such as *.sh) to simplify the operation.
File Operations
Similarly you can use the -ls parameter to list the files in the specified directory:
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
The files listed here may vary depending on the experiment environment.
If you need to see the content of a file, you can use the cat parameter. The easiest thing to think about is to specify a file path directly on HDFS. If you need to compare local directories with files on top of HDFS, you can specify their paths separately. However, it should be noted that the local directory needs to start with the file:// indicator, supplemented by the file path (such as /home/hadoop/.bashrc, don't forget the / in the front). Otherwise, any path specified here will be recognized by default as the path on HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
The output is as follows:
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
If you need to copy a file to another path, you can use the cp parameter:
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
Similarly, if you need to move a file, use the mv parameter. This is basically the same as the Linux file system command format:
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
Use the lsr parameter to list the contents of the current directory, including the contents of subdirectories. The output is as follows:
hdfs dfs -lsr /
If you want to append some new content to a file on HDFS, you can use the appendToFile parameter. And, when specifying the local file path to be appended, you can specify multiple of them. The last parameter will be the object to be appended. The file must exist on HDFS, otherwise an error will be reported:
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
You can use the tail parameter to see the contents of the file tail (the end part of the file) to confirm whether the append was successful:
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
View the output of the tail command:
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
If you need to delete a file or a directory, use the rm parameter. This parameter can also be accompanied by -r and -f, which have the same meanings as they have for the Linux file system command rm:
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
The content of the file moved_file.txt will be deleted, and the command will return the following output 'Deleted /moved_file.txt'
Directory Operations
In the previous content, we have learned how to create a directory in HDFS. In fact, if you need to create multiple directories at once, you can directly specify the paths of multiple directories as parameters. The -p parameter indicates that its parent directory will be created automatically if it does not exist:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
If you want to see how much space a certain file or directory occupies, you can use the du parameter:
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
The output is as follows:
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
Exporting Files
In the previous section, we mainly introduced the file and directory operations in HDFS. If an application such as MapReduce is calculated and the file that records the result is generated, you can use the get parameter to export it to the local directory of the Linux system.
The first path parameter here refers to the path in HDFS, and the last path refers to the path saved in the local directory:
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
If the export is successful, you can find the file in your local directory:
cd ~
ls
The output is as follows:
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Hadoop Web Operation
Web Management Interface
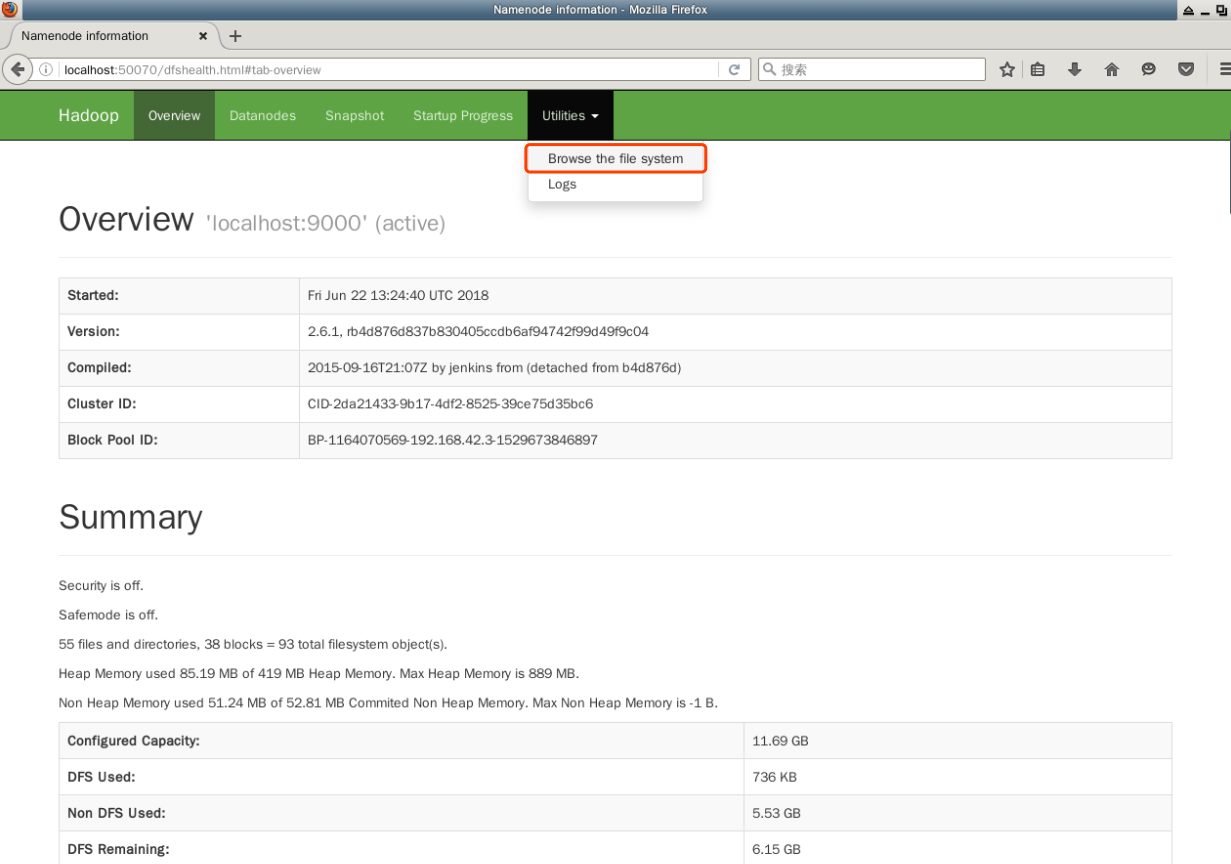
Each NameNode or DataNode runs a web server internally that displays basic information such as the current state of the cluster. In the default configuration, the home page of the NameNode is http://localhost:9870/. It lists basic statistics for DataNodes and clusters.
Open a web browser and input the following in the address bar:
http://localhost:9870/
You can see the number of active DataNode nodes in the current "cluster" in Summary:
The web interface can also be used to browse directories and files inside HDFS. In the menu bar on the top, click on the “Browse the file system” link under “Utilities”:
Close a Hadoop Cluster
Now we have finished introducing some of the basic operations of WebHDFS. More instructions can be found in the documentation for WebHDFS. This lab has come to an end. As a habit, we still need to close the Hadoop cluster:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
Summary
This lab has introduced the architecture of HDFS. Also, we have learned the basic HDFS operation commands from the command line and then turned on to the HDFS web access pattern, which will help HDFS work as a real storage service for external applications.
This lab does not list any scenario of deleting files in WebHDFS. You can check the documentation yourself. More features are hidden in the official documentation, so make sure to keep an interest in reading the documentation.
The following is the material for extended reading:


