
Einführung
Dieses Labor befasst sich hauptsächlich mit den Grundlagen von Hadoop und ist für Studierende mit einer gewissen Linux-Kenntnis geschrieben, um die Architektur des Hadoop-Software-Systems sowie die grundlegenden Bereitstellungsmethoden zu verstehen.
Bitte geben Sie den gesamten Beispielcode im Dokument selbst ein und vermeiden Sie möglichst das bloße Kopieren und Einfügen. Erst auf diese Weise können Sie sich besser mit dem Code vertraut machen. Wenn Sie Probleme haben, überprüfen Sie die Dokumentation gründlich. Andernfalls können Sie auf das Forum gehen, um Hilfe und Austausch zu suchen.
Einführung in Hadoop
Apache Hadoop ist ein quelloffenes Softwareframework, das unter der Apache 2.0-Lizenz veröffentlicht wurde und datenintensive verteilte Anwendungen unterstützt.
Die Apache Hadoop-Softwarebibliothek ist ein Framework, das die verteilte Verarbeitung großer Datensätze über Rechencluster ermöglicht, indem ein einfaches Programmiermodell verwendet wird. Es ist so konzipiert, dass es sich von einem einzelnen Server bis zu Tausenden von Maschinen skalieren lässt, wobei jede Maschine lokale Rechenleistung und Speicher zur Verfügung stellt, anstatt auf Hardware zur Bereitstellung hoher Verfügbarkeit zu setzen.
Kernkonzepte
Ein Hadoop-Projekt umfasst hauptsächlich die folgenden vier Module:
- Hadoop Common: Eine öffentliche Anwendung, die anderen Hadoop-Modulen Unterstützung bietet.
- Hadoop Distributed File System (HDFS): Ein verteiltes Dateisystem, das einen hohen Durchsatz für die Zugang zu Anwendungsdaten bietet.
- Hadoop YARN: Task-Scheduling- und Clusterressourcenverwaltung-Framework.
- Hadoop MapReduce: Ein Framework für die parallele Verarbeitung großer Datensätze auf der Grundlage von YARN.
Für Nutzer, die neu zu Hadoop sind, sollten Sie sich auf HDFS und MapReduce konzentrieren. Als verteiltes Rechenframework bietet HDFS die Speicheranforderungen des Frameworks für Daten und MapReduce die Berechnunganforderungen des Frameworks für Daten.
Das folgende Diagramm zeigt die grundlegende Architektur eines Hadoop-Clusters:
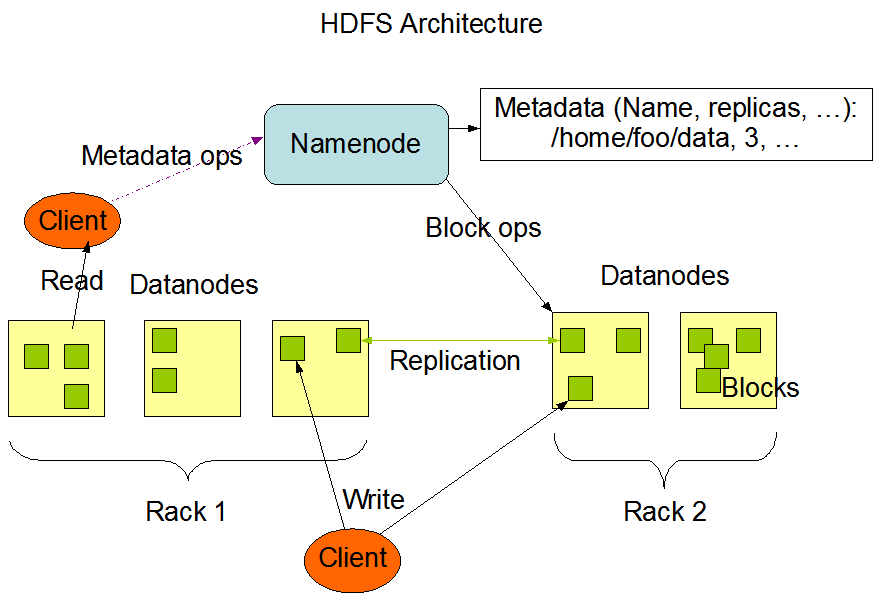
Dieses Diagramm stammt von der offiziellen Website von Hadoop.
Hadoop-Ekosystem
Genau wie Facebook auf der Grundlage von Hadoop das Hive-Datenrepository abgeleitet hat, gibt es in der Community eine Vielzahl von quelloffenen Projekten, die damit zusammenhängen. Hier sind einige kürzlich aktive Projekte:
- HBase: Ein skalierbares, verteiltes Datenbanksystem, das die strukturierten Datenspeicherung für große Tabellen unterstützt.
- Hive: Eine Infrastruktur für Datenrepositories, die die Datenzusammenfassung und temporäre Abfragen bietet.
- Pig: Ein fortgeschrittenes Datenfluss-Sprache- und Ausführungsframework für parallele Rechenoperationen.
- ZooKeeper: Ein Hochleistungs-Koordinierungsdienst für verteilte Anwendungen.
- Spark: Ein schneller und vielseitiger Hadoop-Datencalculationsmotor mit einem einfachen und ausdrucksstarken Programmiermodell, das die Daten-ETL (Extraktion, Transformation und Laden), maschinelles Lernen, Streamverarbeitung und Grafikberechnung unterstützt.
In diesem Labor starten wir mit Hadoop und führen die grundlegenden Anwendungen der zugehörigen Komponenten ein.
Es ist zu beachten, dass Spark, ein verteiltes Arbeitsspeicher-Rechenframework, aus dem Hadoop-System hervorgegangen ist. Es hat eine gute Vererbung für Komponenten wie HDFS und YARN und verbessert auch einige bestehende Mängel von Hadoop.
Einige von Ihnen könnten Fragen zur Überlappung der Anwendungsfälle von Hadoop und Spark haben, aber das Lernen des Arbeits- und Programmiermodells von Hadoop wird dazu beitragen, das Verständnis des Spark-Frameworks zu vertiefen, weshalb Sie zuerst Hadoop lernen sollten.
Bereitstellung von Hadoop
Für Einsteiger besteht kaum ein Unterschied zwischen späteren Hadoop-Versionen und der Version 2.0. In diesem Abschnitt wird die Version 3.3.6 als Beispiel genommen.
Hadoop hat drei Hauptbereitstellungsmuster:
- Stand-alone-Muster: Läuft in einem einzelnen Prozess auf einem einzelnen Computer.
- Pseudo-verteiltes Muster: Läuft in mehreren Prozessen auf einem einzelnen Computer. Dieses Muster simuliert ein „mehrere Knoten“-Szenario unter einem einzelnen Knoten.
- Fully-distributed-Muster: Läuft in einem einzelnen Prozess auf jedem von mehreren Computern.
Als nächstes installieren wir die Hadoop-Version 3.3.6 auf einem einzelnen Computer.
Benutzer und Benutzergruppen einrichten
Doppelklicken Sie, um das Xfce-Terminal auf Ihrem Desktop zu öffnen, und geben Sie den folgenden Befehl ein, um einen Benutzer namens hadoop zu erstellen:
cd ~
sudo adduser hadoop
Folgen Sie den Anweisungen, um das Passwort des hadoop-Benutzers einzugeben; z. B. um das Passwort auf hadoop zu setzen.
Hinweis: Wenn Sie das Passwort eingeben, gibt es keine Aufforderung in der Eingabeaufforderung. Sie können einfach die Eingabetaste drücken, wenn Sie fertig sind.
Fügen Sie dann den neu erstellten hadoop-Benutzer zur sudo-Benutzergruppe hinzu, um dem Benutzer höhere Rechte zu erteilen:
sudo usermod -G sudo hadoop
Vergewissern Sie sich, dass der hadoop-Benutzer der sudo-Gruppe hinzugefügt wurde, indem Sie folgenden Befehl eingeben:
sudo cat /etc/group | grep hadoop
Sie sollten die folgende Ausgabe sehen:
sudo:x:27:shiyanlou,labex,hadoop
JDK installieren
Wie im vorherigen Inhalt erwähnt, wird Hadoop hauptsächlich in Java entwickelt. Daher erfordert das Ausführen von Hadoop eine Java-Umgebung.
Es gibt subtilen Unterschiede in den Anforderungen an die Java-Version zwischen verschiedenen Versionen von Hadoop. Um herauszufinden, welche JDK-Version Sie für Ihr Hadoop wählen sollten, können Sie Hadoop Java Versions auf der Hadoop-Wiki-Website lesen.
Wechseln Sie den Benutzer:
su - hadoop
Installieren Sie die JDK 11-Version, indem Sie folgenden Befehl im Terminal eingeben:
sudo apt update
sudo apt install openjdk-11-jdk -y
Sobald die Installation erfolgreich abgeschlossen ist, überprüfen Sie die aktuelle Java-Version:
java -version
Schauen Sie sich die Ausgabe an:
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
Passwortfreien SSH-Login konfigurieren
Zweck der Installation und Konfiguration von SSH ist es, es Hadoop zu erleichtern, Skripte für den Remote-Management-Dämon auszuführen. Diese Skripte erfordern den sshd-Dienst.
Beim Konfigurieren wechseln Sie zunächst zum hadoop-Benutzer. Geben Sie dazu folgenden Befehl im Terminal ein:
su hadoop
Wenn eine Aufforderung erscheint, bei der Sie ein Passwort eingeben müssen, geben Sie einfach das Passwort ein, das beim vorherigen Erstellen des Benutzers (hadoop) angegeben wurde:
Nachdem der Benutzer erfolgreich gewechselt wurde, sollte der Befehlsprompt wie oben gezeigt sein. In den nachfolgenden Schritten werden die Vorgänge als hadoop-Benutzer ausgeführt.
Als nächstes generieren Sie den Schlüssel für den passwortlosen SSH-Login.
Unter „passwortlos“ versteht man, dass das Authentifizierungsmuster von SSH von Passwort-Login auf Schlüssel-Login umgestellt wird, sodass jedes Hadoop-Component nicht mehr das Passwort über die Benutzeroberfläche eingeben muss, wenn es auf andere zugreift. Dadurch können viele redundante Vorgänge vermieden werden.
Wechseln Sie zunächst in das Home-Verzeichnis des Benutzers und verwenden Sie dann den Befehl ssh-keygen, um den RSA-Schlüssel zu generieren.
Geben Sie folgenden Befehl im Terminal ein:
cd /home/hadoop
ssh-keygen -t rsa
Wenn Sie Informationen wie der Speicherort des Schlüssels erhalten, können Sie die Eingabetaste drücken, um den Standardwert zu verwenden.
The key's randomart image is:
+---[RSA 3072]----+
| ..+. |
| . =. o |
| .o o *. |
| o... + o |
| = +.S.. + |
| + + +++.. |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
Nachdem der Schlüssel generiert wurde, wird der öffentliche Schlüssel im .ssh-Verzeichnis unterhalb des Home-Verzeichnisses des Benutzers erstellt.
Die genaue Vorgehensweise ist in der folgenden Abbildung dargestellt:
Führen Sie dann folgenden Befehl aus, um den generierten öffentlichen Schlüssel in die Host-Authentifizierungsdatei hinzuzufügen. Geben Sie der Datei authorized_keys die Schreibberechtigung, andernfalls wird die Überprüfung nicht korrekt durchgeführt:
cat.ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600.ssh/authorized_keys
Nachdem die Hinzufügung erfolgreich war, versuchen Sie, sich auf den localhost zu loggen. Geben Sie folgenden Befehl im Terminal ein:
ssh localhost
Beim ersten Login werden Sie dazu aufgefordert, die Fingerabdruck des öffentlichen Schlüssels zu bestätigen. Geben Sie einfach yes ein und bestätigen Sie. Beim nächsten Login erfolgt dann ein passwortloses Login:
...
Welcome to Alibaba Cloud Elastic Compute Service!
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
hadoop:~$
Sie müssen den Befehl history -w eingeben oder das Terminal schließen, um die Änderungen zu speichern, damit das Verifizierungsskript erfolgreich abläuft.
Hadoop installieren
Jetzt können Sie das Hadoop-Installationspaket herunterladen. Die offizielle Website liefert den Downloadlink für die neueste Hadoop-Version. Sie können auch den wget-Befehl verwenden, um das Paket direkt im Terminal herunterzuladen.
Geben Sie folgenden Befehl im Terminal ein, um das Paket herunterzuladen:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Sobald der Download abgeschlossen ist, können Sie den tar-Befehl verwenden, um das Paket zu extrahieren:
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
Sie können den JAVA_HOME-Speicherort finden, indem Sie den Befehl dirname $(dirname $(readlink -f $(which java))) im Terminal ausführen.
dirname $(readlink -f $(which java))
Öffnen Sie dann die Datei .zshrc mit einem Texteditor im Terminal:
vim /home/hadoop/.bashrc
Fügen Sie am Ende der Datei /home/hadoop/.bashrc Folgendes hinzu:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Speichern Sie die Datei und beenden Sie den vim-Editor. Geben Sie dann im Terminal den source-Befehl ein, um die neu hinzugefügten Umgebungsvariablen zu aktivieren:
source /home/hadoop/.bashrc
Verifizieren Sie die Installation, indem Sie den Befehl hadoop version im Terminal ausführen.
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
Konfiguration des pseudo-verteilten Musters
In den meisten Fällen wird Hadoop in einem clusterbasierten Umfeld eingesetzt, d.h., wir müssen Hadoop auf mehreren Knoten bereitstellen. Gleichzeitig kann Hadoop auch im pseudo-verteilten Muster auf einem einzelnen Knoten ausgeführt werden, indem mehrere unabhängige Java-Prozesse multi-Knoten-Szenarien simulieren. Im Anfangsstadium des Lernens ist es nicht erforderlich, viele Ressourcen aufzuwenden, um verschiedene Knoten zu erstellen. Deshalb werden in diesem Abschnitt und in den folgenden Kapiteln hauptsächlich das pseudo-verteilte Muster für die Hadoop-„Cluster“-Bereitstellung verwendet.
Verzeichnisse erstellen
Zunächst erstellen Sie die Verzeichnisse namenode und datanode im Home-Verzeichnis des Hadoop-Benutzers. Führen Sie den folgenden Befehl aus, um diese Verzeichnisse zu erstellen:
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Anschließend müssen Sie die Konfigurationsdateien von Hadoop bearbeiten, um es im pseudo-verteilten Muster auszuführen.
core-site.xml bearbeiten
Öffnen Sie die Datei core-site.xml mit einem Texteditor im Terminal:
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
Ändern Sie im Konfigurationsfile den Wert des configuration-Tags in den folgenden Inhalt:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Der fs.defaultFS-Konfigurationsparameter wird verwendet, um den Standort des Dateisystems anzugeben, das der Cluster standardmäßig verwendet:
Speichern Sie die Datei und beenden Sie vim nach der Bearbeitung.
hdfs-site.xml bearbeiten
Öffnen Sie eine weitere Konfigurationsdatei hdfs-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
Ändern Sie im Konfigurationsfile den Wert des configuration-Tags wie folgt:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Dieser Konfigurationsparameter wird verwendet, um die Anzahl der Dateikopien in HDFS anzugeben, die standardmäßig 3 beträgt. Da wir es in pseudo-verteilter Weise auf einem einzelnen Knoten bereitgestellt haben, wird es auf 1更改为:
Speichern Sie die Datei und beenden Sie vim nach der Bearbeitung.
hadoop-env.sh bearbeiten
Als nächstes bearbeiten Sie die Datei hadoop-env.sh:
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
Ändern Sie den Wert von JAVA_HOME in den tatsächlichen Standort der installierten JDK, also /usr/lib/jvm/java-11-openjdk-amd64.
Hinweis: Sie können den Befehl
echo $JAVA_HOMEverwenden, um den tatsächlichen Standort der installierten JDK zu überprüfen.
Speichern Sie die Datei und beenden Sie den vim-Editor nach der Bearbeitung.
yarn-site.xml bearbeiten
Als nächstes bearbeiten Sie die Datei yarn-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
Fügen Sie dem configuration-Tag Folgendes hinzu:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Speichern Sie die Datei und beenden Sie den vim-Editor nach der Bearbeitung.
mapred-site.xml bearbeiten
Schließlich müssen Sie die Datei mapred-site.xml bearbeiten.
Öffnen Sie die Datei mit dem vim-Editor:
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
Ähnlich wie zuvor fügen Sie dem configuration-Tag Folgendes hinzu:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
Speichern Sie die Datei und beenden Sie den vim-Editor nach der Bearbeitung.
Hadoop-Starttest
Öffnen Sie zunächst das Xfce-Terminal auf dem Desktop und wechseln Sie zum Hadoop-Benutzer:
su -l hadoop
Die Initialisierung von HDFS besteht hauptsächlich darin, es zu formatieren:
/home/hadoop/hadoop/bin/hdfs namenode -format
Tipp: Sie müssen das HDFS-Datenverzeichnis löschen, bevor Sie es formatieren.
Wenn Sie diese Meldung sehen, bedeutet das, dass es erfolgreich war:
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Sie müssen den Befehl history -w eingeben oder das Terminal schließen, um die Historie zu speichern, damit das Verifizierungsskript erfolgreich abläuft.
Starte HDFS
Sobald die Initialisierung von HDFS abgeschlossen ist, können Sie die Demons für NameNode und DataNode starten. Nachdem sie gestartet wurden, können Hadoop-Anwendungen (wie MapReduce-Aufgaben) Dateien in HDFS lesen und schreiben.
Starte den Demon, indem Sie folgenden Befehl im Terminal eingeben:
/home/hadoop/hadoop/sbin/start-dfs.sh
Schau dir die Ausgabe an:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Um zu bestätigen, dass Hadoop erfolgreich im pseudo-verteilten Muster ausgeführt wird, können Sie das Java-Process-View-Tool jps verwenden, um zu sehen, ob ein entsprechender Prozess vorhanden ist.
Geben Sie folgenden Befehl im Terminal ein:
jps
Wie in der Abbildung gezeigt, wenn Sie die Prozesse von NameNode, DataNode und SecondaryNameNode sehen, bedeutet das, dass der Hadoop-Dienst fehlerfrei läuft:
Logdateien und WebUI anzeigen
Wenn Hadoop nicht starten kann oder Fehler während der Ausführung einer Aufgabe (oder sonstiger Probleme) gemeldet werden, ist neben der Prompt-Information im Terminal das Anzeigen von Logs der beste Weg, um ein Problem zu lokalisieren. Die meisten Probleme können durch die Logs der relevanten Software gefunden werden, um die Ursache und eine Lösung zu finden. Als Lernender auf dem Gebiet des Big Data ist die Fähigkeit, Logs zu analysieren, genauso wichtig wie die Fähigkeit, das Rechenframework zu lernen, und sollte ernst genommen werden.
Die standardmäßige Ausgabe der Hadoop-Demon-Logs befindet sich im Log-Verzeichnis (logs) unter dem Installationsverzeichnis. Geben Sie folgenden Befehl im Terminal ein, um in das Log-Verzeichnis zu gelangen:
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
Sie können den vim-Editor verwenden, um jede Logdatei anzuzeigen.
Nachdem HDFS gestartet wurde, wird auch eine Webanwendung bereitgestellt, die den Clusterstatus anzeigt. Wechseln Sie zum oberen Bereich der LabEx-VM und klicken Sie auf "Web 8088", um die Webanwendung zu öffnen:
Nachdem die Webanwendung geöffnet wurde, können Sie einen Überblick über den Cluster, den Status des DataNode usw. sehen:
Klicken Sie gerne auf das Menü oben auf der Seite, um die Tipps und Funktionen zu erkunden.
Sie müssen den Befehl history -w eingeben oder das Terminal schließen, um die Historie zu speichern, damit das Verifizierungsskript erfolgreich abläuft.
HDFS-Dateiuploadtest
Sobald HDFS läuft, kann es als Dateisystem betrachtet werden. Um die Dateiuploadfunktionalität zu testen, müssen Sie ein Verzeichnis erstellen (eine Ebene pro Schritt, bis zur erforderlichen Verzeichnisebene) und versuchen, einige Dateien aus dem Linux-System in HDFS hochzuladen:
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
Nachdem das Verzeichnis erfolgreich erstellt wurde, verwenden Sie den Befehl hdfs dfs -put, um die Dateien auf der lokalen Festplatte (hier die zufällig ausgewählten Hadoop-Konfigurationsdateien) in HDFS hochzuladen:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
PI-Testfälle
Der überwiegende Teil der in realen Produktionsumgebungen bereitgestellten und realweltliche Probleme lösenden Hadoop-Anwendungen basiert auf dem MapReduce-Programmiermodell, das durch WordCount repräsentiert wird. Daher kann WordCount als "HelloWorld"-Programm für den Einstieg in Hadoop verwendet werden, oder Sie können eigene Ideen hinzufügen, um spezifische Probleme zu lösen.
Starte die Aufgabe
Am Ende des vorherigen Abschnitts haben wir einige Konfigurationsdateien in HDFS hochgeladen, als Beispiel. Als nächstes können wir versuchen, den PI-Testfall auszuführen, um die Häufigkeit von Wörtern in diesen Dateien zu statistizieren und sie gemäß unseren Filterregeln auszugeben.
Starte zunächst den YARN-Rechendienst im Terminal:
/home/hadoop/hadoop/sbin/start-yarn.sh
Geben Sie dann folgenden Befehl ein, um die Aufgabe zu starten:
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Schau dir die Ausgabenergebnisse an:
Estimated value of Pi is 3.55555555555555555556
Unter den oben genannten Parametern gibt es drei Parameter, die sich auf den Pfad beziehen. Sie sind: der Ort der jar-Paketdatei, der Ort der Eingabedatei und der Speicherort des Ausgabenergebnisses. Wenn Sie den Pfad angeben, sollten Sie die Gewohnheit entwickeln, einen absoluten Pfad anzugeben. Dies wird helfen, Probleme schnell zu lokalisieren und die Arbeit bald zu erledigen.
Wenn die Aufgabe abgeschlossen ist, können Sie die Ergebnisse ansehen.
Schließe den HDFS-Dienst
Nach der Berechnung sollten Sie den HDFS-Demon zeitnah schließen, wenn es keine anderen Softwareprogramme gibt, die die Dateien in HDFS verwenden.
Als Benutzer von verteilten Clustern und den zugehörigen Rechenframeworks sollten Sie die gute Gewohnheit entwickeln, sich jedes Mal, wenn es um das Öffnen und Schließen von Clustern, die Installation von Hardware und Software oder jede Art von Updates geht, aktiv den Status der zugehörigen Hardware und Software zu überprüfen.
Verwenden Sie folgenden Befehl im Terminal, um die HDFS- und YARN-Demons zu schließen:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
Sie müssen den Befehl history -w eingeben oder das Terminal schließen, um die Historie zu speichern, damit das Verifizierungsskript erfolgreich abläuft.
Zusammenfassung
In diesem Lab wurde die Architektur von Hadoop, die Installations- und Deploymentmethoden im Einzellauf- und Pseudo-Verteilten-Muster vorgestellt, und WordCount wurde für grundlegende Tests ausgeführt.
Hier sind die wichtigsten Punkte dieses Labs:
- Hadoop-Architektur
- Hadoop-Hauptmodule
- Wie man Hadoop im Einzellauf-Muster verwendet
- Hadoop-Pseudo-Verteilte-Muster-Deployment
- Grundlegende Verwendung von HDFS
- WordCount-Testfall
Im Allgemeinen ist Hadoop ein Rechen- und Speicherframework, das in der Big-Data-Branche häufig verwendet wird. Seine Funktionen müssen weiter erforscht werden. Halten Sie sich die Gewohnheit, sich auf technische Materialien zu beziehen, und lernen Sie die Folgefs weiter.


