

はじめに
このセクションでは、Pythonの内部オブジェクトモデルに関する詳細を紹介し、メモリ管理、コピー、型チェックに関連するいくつかの事柄について議論します。
This tutorial is from open-source community. Access the source code
💡 このチュートリアルは英語版からAIによって翻訳されています。原文を確認するには、 ここをクリックしてください
このセクションでは、Pythonの内部オブジェクトモデルに関する詳細を紹介し、メモリ管理、コピー、型チェックに関連するいくつかの事柄について議論します。
Pythonにおける多くの操作は、値の「代入」または「格納」に関連しています。
a = value ## 変数への代入
s[n] = value ## リストへの代入
s.append(value) ## リストへの追加
d['key'] = value ## 辞書への追加注意: 代入操作は、代入される値のコピーを 決して行いません。すべての代入は、単に参照コピー(好きならポインタコピー)です。
このコードフラグメントを考えてみましょう。
a = [1,2,3]
b = a
c = [a,b]根底にあるメモリ操作の図。この例では、リストオブジェクトは[1,2,3]だけですが、それへの参照は4つあります。
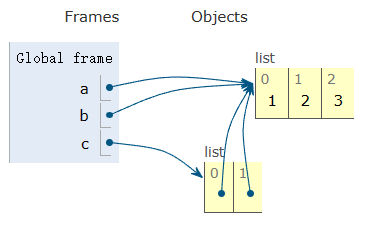
これは、値を変更すると、すべての参照に影響が及ぶことを意味します。
>>> a.append(999)
>>> a
[1,2,3,999]
>>> b
[1,2,3,999]
>>> c
[[1,2,3,999], [1,2,3,999]]
>>>元のリストの変更が他のすべての場所に反映される様子にご注目ください(ひどい!)。これは、コピーがまったく作られていないためです。すべてが同じオブジェクトを指しているからです。
値を再代入するときは、以前の値が使用していたメモリを 決して上書きしません。
a = [1,2,3]
b = a
a = [4,5,6]
print(a) ## [4, 5, 6]
print(b) ## [1, 2, 3] 元の値を保持しています忘れないでください:変数は名前であり、メモリ位置ではありません。
この共有について知らないと、いつか自分自身を害することになります。典型的なシナリオです。あなたは自分だけのプライベートコピーだと思ってデータを変更しますが、それが偶然にもプログラムの他の部分のデータを破損させてしまいます。
注釈: これは、プリミティブデータ型 (int、float、string) が不変 (読み取り専用) である理由の1つです。
2つの値がまったく同じオブジェクトであるかどうかを確認するには、is演算子を使用します。
>>> a = [1,2,3]
>>> b = a
>>> a is b
True
>>>isは、オブジェクト識別(整数)を比較します。識別はid()を使用して取得できます。
>>> id(a)
3588944
>>> id(b)
3588944
>>>注: オブジェクトをチェックする際には、ほとんどの場合==を使用する方が良いです。isの動作はしばしば予期しない場合があります。
>>> a = [1,2,3]
>>> b = a
>>> c = [1,2,3]
>>> a is b
True
>>> a is c
False
>>> a == c
True
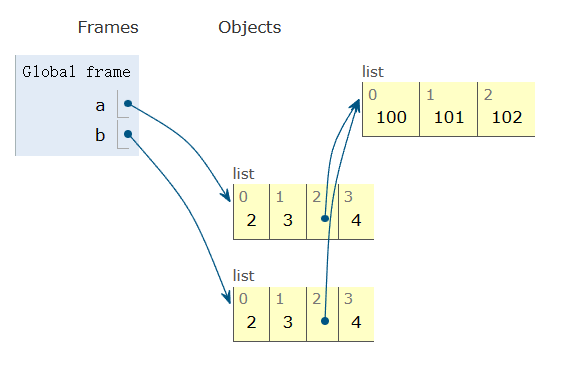
>>>リストと辞書にはコピーするためのメソッドがあります。
>>> a = [2,3,[100,101],4]
>>> b = list(a) ## コピーを作成する
>>> a is b
False新しいリストですが、リストの要素は共有されています。
>>> a[2].append(102)
>>> b[2]
[100,101,102]
>>>
>>> a[2] is b[2]
True
>>>たとえば、内側のリスト[100, 101, 102]が共有されています。これはシャローコピーと呼ばれます。以下はその図です。
時には、オブジェクトとその中に含まれるすべてのオブジェクトのコピーを作成する必要があります。この場合、copyモジュールを使用できます。
>>> a = [2,3,[100,101],4]
>>> import copy
>>> b = copy.deepcopy(a)
>>> a[2].append(102)
>>> b[2]
[100,101]
>>> a[2] is b[2]
False
>>>変数名には 型 はありません。ただの名前です。ただし、値には基本的な型があります。
>>> a = 42
>>> b = 'Hello World'
>>> type(a)
<type 'int'>
>>> type(b)
<type 'str'>type() は、それが何であるかを教えてくれます。型名は通常、値を作成またはその型に変換する関数として使用されます。
オブジェクトが特定の型であるかどうかを判断する方法。
if isinstance(a, list):
print('a is a list')複数の可能性のある型のうちの1つをチェックする。
if isinstance(a, (list,tuple)):
print('a is a list or tuple')*注意: 型のチェックには度を越してはいけません。それはコードの複雑さを余計に招く可能性があります。通常は、他の人があなたのコードを使用する際に起こりうる一般的なミスを防ぐためにのみ行います。
数値、文字列、リスト、関数、例外、クラス、インスタンスなどはすべてオブジェクトです。これは、名前を付けることができるすべてのオブジェクトが、制限なくデータとして渡され、コンテナに配置されるなどということを意味します。特別な種類のオブジェクトはありません。時には、すべてのオブジェクトが「一等公民」であると言われます。
簡単な例:
>>> import math
>>> items = [abs, math, ValueError ]
>>> items
[<built-in function abs>,
<module'math' (builtin)>,
<type 'exceptions.ValueError'>]
>>> items[0](-45)
45
>>> items[1].sqrt(2)
1.4142135623730951
>>> try:
x = int('not a number')
except items[2]:
print('Failed!')
Failed!
>>>ここで、items は関数、モジュール、例外を含むリストです。リスト内の要素を元の名前の代わりに直接使用できます:
items[0](-45) ## abs
items[1].sqrt(2) ## math
except items[2]: ## ValueError力は責任を伴います。それができるからといって、やるべきだというわけではありません。
このセットの演習では、一等公民オブジェクトから生じる力のいくつかを見てみましょう。
portfolio.csv ファイルには、次のような列で整理されたデータが含まれています。
name,shares,price
"AA",100,32.20
"IBM",50,91.10
...以前のコードでは、csv モジュールを使ってファイルを読み取りましたが、手動で型変換を行う必要がありました。たとえば:
for row in rows:
name = row[0]
shares = int(row[1])
price = float(row[2])この種の変換は、いくつかのリスト基本操作を使って、もっと賢く行うこともできます。
各列を適切な型に変換するために使用する変換関数の名前を含むPythonリストを作成してください。
>>> types = [str, int, float]
>>>Pythonではすべてが 一等公民 であるため、このようなリストを作成できるのです。つまり、関数のリストが欲しい場合でも問題ありません。作成したリストの要素は、値 x を指定された型に変換する関数です (たとえば、str(x)、int(x)、float(x) など)。
次に、上記のファイルから1行のデータを読み取ります。
>>> import csv
>>> f = open('portfolio.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> row
['AA', '100', '32.20']
>>>前述の通り、この行だけでは計算を行うことができません。なぜなら型が正しくないからです。たとえば:
>>> row[1] * row[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't multiply sequence by non-int of type'str'
>>>しかし、データを types に指定した型とペアにすることができるかもしれません。たとえば:
>>> types[1]
<type 'int'>
>>> row[1]
'100'
>>>値の1つを変換してみましょう。
>>> types[1](row[1]) ## Same as int(row[1])
100
>>>別の値を変換してみましょう。
>>> types[2](row[2]) ## Same as float(row[2])
32.2
>>>変換後の値を使って計算を試してみましょう。
>>> types[1](row[1])*types[2](row[2])
3220.0000000000005
>>>列の型とフィールドをzipして結果を見てみましょう。
>>> r = list(zip(types, row))
>>> r
[(<type'str'>, 'AA'), (<type 'int'>, '100'), (<type 'float'>,'32.20')]
>>>これで型変換と値がペアになっていることがわかります。たとえば、int は値 '100' とペアになっています。
zipされたリストは、すべての値に対して1つずつ型変換を行いたい場合に便利です。試してみましょう。
>>> converted = []
>>> for func, val in zip(types, row):
converted.append(func(val))
...
>>> converted
['AA', 100, 32.2]
>>> converted[1] * converted[2]
3220.0000000000005
>>>上記のコードで何が起こっているか必ず理解してください。ループ内では、func 変数は型変換関数の1つ (たとえば、str、int など) であり、val 変数は 'AA'、'100' のような値の1つです。式 func(val) は値を変換しています (一種の型キャストのようなものです)。
上記のコードは、単一のリスト内包表記に圧縮することができます。
>>> converted = [func(val) for func, val in zip(types, row)]
>>> converted
['AA', 100, 32.2]
>>>キー名と値のシーケンスがある場合、dict() 関数が簡単に辞書を作成できることを覚えていますか?列ヘッダーから辞書を作成してみましょう。
>>> headers
['name','shares', 'price']
>>> converted
['AA', 100, 32.2]
>>> dict(zip(headers, converted))
{'price': 32.2, 'name': 'AA','shares': 100}
>>>もちろん、あなたがリスト内包表記に精通しているなら、辞書内包表記を使って1ステップで全体の変換を行うことができます。
>>> { name: func(val) for name, func, val in zip(headers, types, row) }
{'price': 32.2, 'name': 'AA','shares': 100}
>>>この演習で学んだ手法を使えば、ほとんどの列指向データファイルのフィールドを簡単にPythonの辞書に変換する文を書けます。
例を挙げるために、別のデータファイルからデータを読み取るとしましょう。
>>> f = open('dowstocks.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> headers
['name', 'price', 'date', 'time', 'change', 'open', 'high', 'low', 'volume']
>>> row
['AA', '39.48', '6/11/2007', '9:36am', '-0.18', '39.67', '39.69', '39.45', '181800']
>>>同じようなトリックを使ってフィールドを変換してみましょう。
>>> types = [str, float, str, str, float, float, float, float, int]
>>> converted = [func(val) for func, val in zip(types, row)]
>>> record = dict(zip(headers, converted))
>>> record
{'volume': 181800, 'name': 'AA', 'price': 39.48, 'high': 39.69,
'low': 39.45, 'time': '9:36am', 'date': '6/11/2007', 'open': 39.67,
'change': -0.18}
>>> record['name']
'AA'
>>> record['price']
39.48
>>>ボーナス: この例をどのように変更すれば、date エントリを (6, 11, 2007) のようなタプルに追加でパースできるようになりますか?
この演習で行ったことを少し考えてみましょう。後ほどこれらのアイデアに戻ります。
おめでとうございます!あなたはオブジェクトの実験を完了しました。あなたのスキルを向上させるために、LabExでさらに多くの実験を練習できます。


