
はじめに
このチュートリアルでは、Python の defaultdict データ構造を調べます。これは、標準の辞書の強力なバリエーションで、欠けているキーを上手に処理します。具体的には、デフォルト値が 0 の defaultdict を作成する方法を学びます。これは、Python プログラムで値をカウントしたり蓄積したりする際に特に便利です。
この実験が終わるとき、あなたは defaultdict が何であるか、デフォルト値が 0 のものを作成する方法、および実際のシナリオでそれを適用して、よりエレガントでエラーに強いコードを書く方法を理解しているでしょう。
通常の辞書の問題を理解する
defaultdict に入る前に、まず defaultdict が解決してくれる通常の辞書の制限を理解しましょう。
KeyError の問題
Python では、標準の辞書 (dict) はキーと値のペアを格納するために使用されます。ただし、通常の辞書に存在しないキーにアクセスしようとすると、Python は KeyError を発生させます。
この問題を示すための簡単な例を作成しましょう。
- エディタで
regular_dict_demo.pyという新しいファイルを作成します。
## 果物のカウントをするための通常の辞書を作成する
fruit_counts = {}
## 'apple' のカウントを増やそうとする
try:
fruit_counts['apple'] += 1
except KeyError:
print("KeyError: 'apple' キーは辞書に存在しません")
## 通常の辞書でこれを行う適切な方法
if 'banana' in fruit_counts:
fruit_counts['banana'] += 1
else:
fruit_counts['banana'] = 1
print(f"果物のカウント:{fruit_counts}")
- ターミナルからスクリプトを実行します。
python3 regular_dict_demo.py
以下のような出力が表示されるはずです。
KeyError: 'apple' キーは辞書に存在しません
果物のカウント: {'banana': 1}
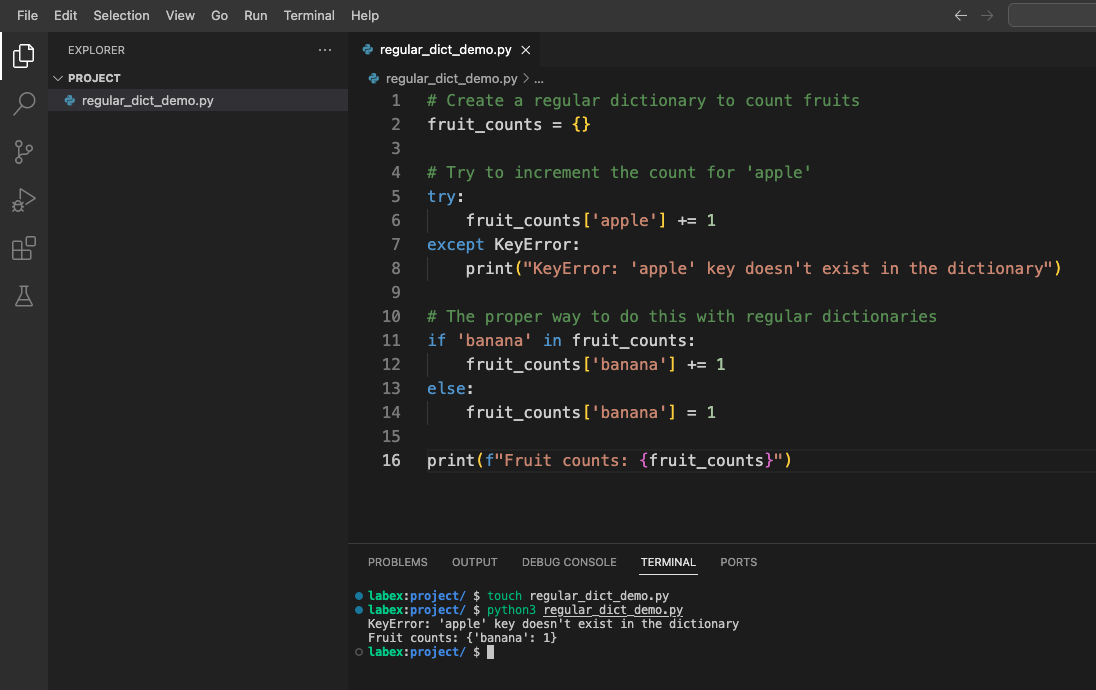
ご覧の通り、存在しないキーのカウントを増やそうとするとエラーが発生します。一般的な回避策は、アクセスしようとする前にキーが存在するかどうかを確認することですが、これはコードがより冗長になります。
ここで defaultdict が助けになります。アクセスされたときにデフォルト値でキーを作成することで、欠けているキーを自動的に処理します。
デフォルト値 0 での defaultdict の紹介
通常の辞書の問題を理解したので、defaultdict を使ってそれを解決する方法を学びましょう。
defaultdict とは?
defaultdict は、Python の組み込み dict クラスのサブクラスで、最初の引数として関数(「デフォルトファクトリ」と呼ばれます)を受け取ります。存在しないキーにアクセスすると、defaultdict は自動的にそのキーをデフォルトファクトリ関数が返す値で作成します。
デフォルト値 0 での defaultdict の作成
欠けているキーに対してデフォルト値 0 を提供する defaultdict を作成しましょう。
- エディタで
default_dict_zero.pyという新しいファイルを作成します。
## まず、collections モジュールから defaultdict クラスをインポートする
from collections import defaultdict
## 方法 1: int をデフォルトファクトリとして使用する
## 引数なしで呼び出された int() 関数は 0 を返す
counter = defaultdict(int)
print("counter の初期状態:", dict(counter))
## まだ存在しないキーにアクセスする
print("'apple' の値 (前):", counter['apple'])
## カウントを増やす
counter['apple'] += 1
counter['apple'] += 1
counter['banana'] += 1
print("'apple' の値 (後):", counter['apple'])
print("操作後の辞書:", dict(counter))
## 方法 2: lambda 関数を使用する (代替アプローチ)
counter2 = defaultdict(lambda: 0)
print("\nlambda 関数を使用する:")
print("'cherry' の値 (前):", counter2['cherry'])
counter2['cherry'] += 5
print("'cherry' の値 (後):", counter2['cherry'])
print("操作後の辞書:", dict(counter2))
- ターミナルからスクリプトを実行します。
python3 default_dict_zero.py
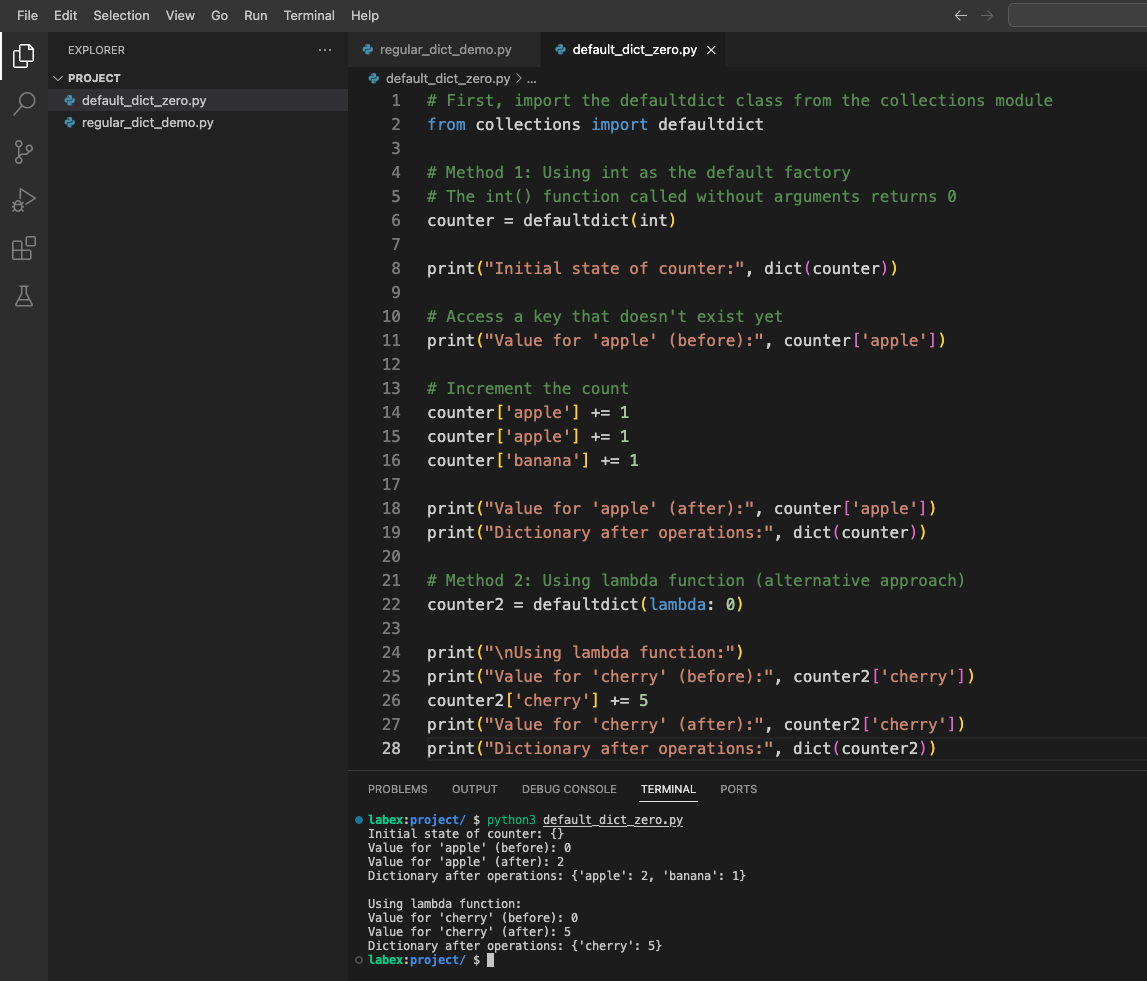
以下のような出力が表示されるはずです。
counter の初期状態: {}
'apple' の値 (前): 0
'apple' の値 (後): 2
操作後の辞書: {'apple': 2, 'banana': 1}
lambda 関数を使用する:
'cherry' の値 (前): 0
'cherry' の値 (後): 5
操作後の辞書: {'cherry': 5}
動作の仕組み
defaultdict(int) を作成するとき、Python に対して int() 関数をデフォルトファクトリとして使用するように指示しています。引数なしで呼び出されたとき、int() は 0 を返し、これが欠けているキーのデフォルト値になります。
同様に、単に呼び出されたときに 0 を返す lambda 関数 lambda: 0 を使用することもできます。
以前存在しなかったキーの値に直接アクセスして増やすことができ、エラーも起こさないことに注意してください。
実用的な使い方:単語の頻度をカウントする
デフォルト値が 0 の defaultdict の最も一般的な用途の 1 つは、頻度をカウントすることです。この実用的な使い方を示すために、単語頻度カウンターを実装しましょう。
- エディタで
word_counter.pyという新しいファイルを作成します。
from collections import defaultdict
def count_word_frequencies(text):
## デフォルト値 0 の defaultdict を作成する
word_counts = defaultdict(int)
## テキストを単語に分割して小文字に変換する
words = text.lower().split()
## 各単語をクリーンアップし(句読点を削除し)出現回数をカウントする
for word in words:
## 一般的な句読点を削除する
clean_word = word.strip('.,!?:;()"\'')
if clean_word: ## 空の文字列をスキップする
word_counts[clean_word] += 1
return word_counts
## サンプルテキストで関数をテストする
sample_text = """
Python is amazing! Python is easy to learn, and Python is very powerful.
With Python, you can create web applications, analyze data, build games,
and automate tasks. Python's syntax is clear and readable.
"""
word_frequencies = count_word_frequencies(sample_text)
## 結果を表示する
print("単語頻度:")
for word, count in sorted(word_frequencies.items()):
print(f" {word}: {count}")
## 最も頻出する単語を見つける
print("\n最も頻出する単語:")
sorted_words = sorted(word_frequencies.items(), key=lambda x: x[1], reverse=True)
for word, count in sorted_words[:5]: ## 上位 5 つの単語
print(f" {word}: {count}")
- ターミナルからスクリプトを実行します。
python3 word_counter.py
以下のような出力が表示されるはずです。
単語頻度:
amazing: 1
analyze: 1
and: 3
applications: 1
automate: 1
build: 1
can: 1
clear: 1
create: 1
data: 1
easy: 1
games: 1
is: 4
learn: 1
powerful: 1
python: 4
python's: 1
readable: 1
syntax: 1
tasks: 1
to: 1
very: 1
web: 1
with: 1
you: 1
最も頻出する単語:
python: 4
is: 4
and: 3
amazing: 1
easy: 1
この動作の仕組み
- 単語のカウントをデフォルト値 0 で格納するために
defaultdict(int)を作成します。 - テキスト内の各単語を処理し、句読点をクリーンアップします。
word_counts[word] += 1を使用して各単語のカウントを単純に増やします。- 初めて登場する単語に対しては、自動的にデフォルト値 0 が割り当てられます。
このアプローチは、存在チェックを行う通常の辞書を使用する場合よりもはるかにクリーンで効率的です。
デフォルト値 0 での defaultdict の利点
- コードの簡略化:増やす前にキーが存在するかどうかをチェックする必要がない。
- コード行数の削減:キーの存在チェックの定型文を削除する。
- エラーの軽減:潜在的な KeyError 例外を排除する。
- 読みやすさの向上:カウントのロジックをより明確で簡潔にする。
デフォルト値が 0 の defaultdict は、頻度分析、ヒストグラム、カテゴリ別のデータの集計、ログやデータセットの出現回数の追跡など、カウントまたは値の蓄積を伴う任意のタスクに特に役立ちます。
性能比較:defaultdict と通常の辞書
一般的なカウントタスクにおいて、デフォルト値が 0 の defaultdict と通常の辞書の性能を比較しましょう。これにより、どちらを選ぶべきかを理解する手助けになります。
- エディタで
performance_comparison.pyという新しいファイルを作成します。
import time
from collections import defaultdict
def count_with_regular_dict(data):
"""通常の辞書を使って頻度をカウントする。"""
counts = {}
for item in data:
if item in counts:
counts[item] += 1
else:
counts[item] = 1
return counts
def count_with_defaultdict(data):
"""デフォルト値 0 の defaultdict を使って頻度をカウントする。"""
counts = defaultdict(int)
for item in data:
counts[item] += 1
return counts
## テストデータを生成する - 0 から 99 までの乱数のリスト
import random
random.seed(42) ## 再現可能な結果のため
data = [random.randint(0, 99) for _ in range(1000000)]
## 通常の辞書のアプローチの時間計測
start_time = time.time()
result1 = count_with_regular_dict(data)
regular_dict_time = time.time() - start_time
## defaultdict のアプローチの時間計測
start_time = time.time()
result2 = count_with_defaultdict(data)
defaultdict_time = time.time() - start_time
## 結果を表示する
print(f"通常の辞書の時間:{regular_dict_time:.4f} 秒")
print(f"defaultdict の時間: {defaultdict_time:.4f} 秒")
print(f"defaultdict は {regular_dict_time/defaultdict_time:.2f} 倍速い")
## 両方の方法が同じ結果を返すことを確認する
assert dict(result2) == result1, "カウント結果が一致しません!"
print("\n両方の方法で同じカウント結果が得られました ✓")
## カウント結果のサンプルを表示する
print("\nカウント結果のサンプル (最初の 5 項目):")
for i, (key, value) in enumerate(sorted(result1.items())):
if i >= 5:
break
print(f" 数字 {key}: {value} 回出現")
- ターミナルからスクリプトを実行します。
python3 performance_comparison.py
以下のような出力が表示されるはずです。
通常の辞書の時間: 0.1075 秒
defaultdict の時間: 0.0963 秒
defaultdict は 1.12 倍速い
両方の方法で同じカウント結果が得られました ✓
カウント結果のサンプル (最初の 5 項目):
数字 0: 10192 回出現
数字 1: 9949 回出現
数字 2: 9929 回出現
数字 3: 9881 回出現
数字 4: 9922 回出現
注:正確な計測結果はシステムによって異なる場合があります。
結果の分析
性能比較によると、defaultdict は通常の辞書よりもカウントタスクで一般的に速いことがわかります。その理由は以下の通りです。
- キーの存在チェック (
if key in dictionary) が不要になる。 - 各項目に対する辞書の検索回数が減る。
- コードが単純化され、Python インタプリタによる最適化の可能性がある。
性能上の利点に加えて、defaultdict は以下の利点も備えています。
- コードの簡素化:コードがより簡潔で読みやすくなる。
- 認知負荷の軽減:欠けているキーのケースを処理することを忘れる必要がない。
- バグの発生機会の減少:コードが少ないため、エラーの発生機会が少なくなる。
このため、デフォルト値が 0 の defaultdict は、Python でのカウント操作、頻度分析、その他の蓄積タスクにおいて優れた選択肢になります。
まとめ
この実験では、Python の defaultdict とデフォルト値 0 での使い方を学びました。まとめると以下の通りです。
- 存在しないキーにアクセスしたときに
KeyErrorを発生させる通常の辞書の制限を特定しました。 defaultdict(int)とdefaultdict(lambda: 0)の両方を使って、デフォルト値 0 のdefaultdictを作成する方法を学びました。- 単語頻度カウンターを実装することで、実用的な使い方を検討しました。
defaultdictと通常の辞書の性能を比較し、defaultdictがカウントタスクにおいてより便利で高速であることを確認しました。
デフォルト値 0 の defaultdict は、Python でのカウント、蓄積、頻度分析を簡素化する強力なツールです。欠けているキーを自動的に処理することで、コードをクリーンに、効率的に、エラーが起きにくくします。
このパターンは一般的に以下の分野で使用されます。
- データ処理と分析
- 自然言語処理
- ログ分析
- ゲーム開発(スコアリングシステム用)
- カウンターや蓄積器を含む任意のシナリオ
デフォルト値 0 の defaultdict をマスターすることで、よりエレガントで効率的なコードを書くのに役立つ重要なツールを Python プログラミングツールキットに追加しました。


