

Introduction
Cette section présente plus de détails sur le modèle d'objet interne de Python et discute de certains sujets liés à la gestion de la mémoire, à la copie et à la vérification de type.
This tutorial is from open-source community. Access the source code
💡 Ce tutoriel est traduit par l'IA à partir de la version anglaise. Pour voir la version originale, vous pouvez cliquer ici
Cette section présente plus de détails sur le modèle d'objet interne de Python et discute de certains sujets liés à la gestion de la mémoire, à la copie et à la vérification de type.
Plusieurs opérations en Python sont liées à l'affectation ou au stockage de valeurs.
a = valeur ## Affectation à une variable
s[n] = valeur ## Affectation à une liste
s.append(valeur) ## Ajout à une liste
d['clé'] = valeur ## Ajout à un dictionnaireAttention : les opérations d'affectation ne font jamais de copie de la valeur affectée. Toutes les affectations ne sont que des copies de référence (ou des copies de pointeur si vous préférez).
Considérez ce fragment de code.
a = [1,2,3]
b = a
c = [a,b]Une représentation des opérations mémoire sous-jacentes. Dans cet exemple, il n'y a qu'un seul objet liste [1,2,3], mais quatre références différentes à cet objet.
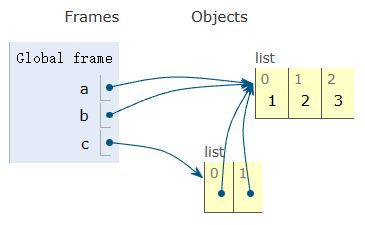
Cela signifie que modifier une valeur affecte toutes les références.
>>> a.append(999)
>>> a
[1,2,3,999]
>>> b
[1,2,3,999]
>>> c
[[1,2,3,999], [1,2,3,999]]
>>>Remarquez comment un changement dans la liste d'origine se reflète partout ailleurs (yikes!). C'est parce qu'aucune copie n'a été faite. Tout pointe vers la même chose.
La réaffectation d'une valeur n'écrase jamais la mémoire utilisée par la valeur précédente.
a = [1,2,3]
b = a
a = [4,5,6]
print(a) ## [4, 5, 6]
print(b) ## [1, 2, 3] Conserve la valeur d'origineRappelez-vous : Les variables sont des noms, pas des emplacements mémoire.
Si vous n'êtes pas au courant de ce partage, vous vous piquerez vous-même le pied à un moment donné. Scénario typique. Vous modifiez certaines données en pensant que c'est votre propre copie privée et vous corrompez accidentellement certaines données dans une autre partie du programme.
Commentaire : C'est l'une des raisons pour lesquelles les types de données primitifs (int, float, chaîne) sont immuables (en lecture seule).
Utilisez l'opérateur is pour vérifier si deux valeurs sont exactement le même objet.
>>> a = [1,2,3]
>>> b = a
>>> a is b
True
>>>is compare l'identité de l'objet (un entier). L'identité peut être obtenue en utilisant id().
>>> id(a)
3588944
>>> id(b)
3588944
>>>Note : Il est presque toujours préférable d'utiliser == pour vérifier des objets. Le comportement de is est souvent inattendu :
>>> a = [1,2,3]
>>> b = a
>>> c = [1,2,3]
>>> a is b
True
>>> a is c
False
>>> a == c
True
>>>Les listes et les dictionnaires ont des méthodes pour effectuer des copies.
>>> a = [2,3,[100,101],4]
>>> b = list(a) ## Effectuez une copie
>>> a is b
FalseC'est une nouvelle liste, mais les éléments de la liste sont partagés.
>>> a[2].append(102)
>>> b[2]
[100,101,102]
>>>
>>> a[2] is b[2]
True
>>>Par exemple, la liste interne [100, 101, 102] est partagée. Ceci est connu sous le nom de copie superficielle. Voici une illustration.
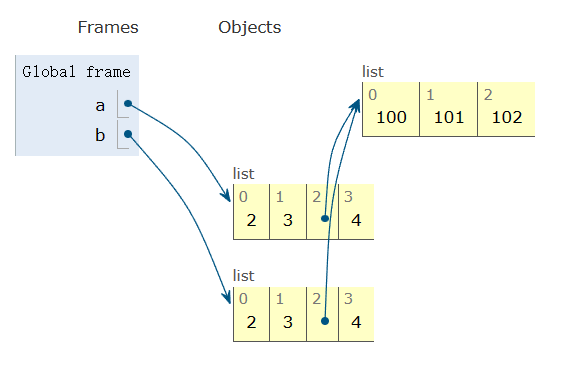
Parfois, vous avez besoin de créer une copie d'un objet et de tous les objets qu'il contient. Vous pouvez utiliser le module copy pour ce faire :
>>> a = [2,3,[100,101],4]
>>> import copy
>>> b = copy.deepcopy(a)
>>> a[2].append(102)
>>> b[2]
[100,101]
>>> a[2] is b[2]
False
>>>Les noms de variables n'ont pas de type. C'est seulement un nom. Cependant, les valeurs ont un type sous-jacent.
>>> a = 42
>>> b = 'Hello World'
>>> type(a)
<type 'int'>
>>> type(b)
<type 'str'>type() vous dira de quel type il s'agit. Le nom de type est généralement utilisé comme une fonction qui crée ou convertit une valeur en ce type.
Comment déterminer si un objet est d'un type spécifique.
if isinstance(a, list):
print('a est une liste')Vérification pour l'un de plusieurs types possibles.
if isinstance(a, (list,tuple)):
print('a est une liste ou un tuple')*Attention : Ne poussez pas trop loin la vérification de type. Cela peut entraîner une complexité excessive du code. En général, vous ne le feriez que si cela permet de prévenir les erreurs courantes commises par d'autres utilisant votre code.
Les nombres, les chaînes de caractères, les listes, les fonctions, les exceptions, les classes, les instances, etc. sont tous des objets. Cela signifie que tous les objets qui peuvent être nommés peuvent être passés comme des données, placés dans des conteneurs, etc., sans aucune restriction. Il n'y a pas de types spéciaux d'objets. Parfois, on dit que tous les objets sont "de première classe".
Un exemple simple :
>>> import math
>>> items = [abs, math, ValueError ]
>>> items
[<fonction intégrée abs>,
<module'math' (builtin)>,
<type 'exceptions.ValueError'>]
>>> items[0](-45)
45
>>> items[1].sqrt(2)
1.4142135623730951
>>> try:
x = int('not a number')
except items[2]:
print('Échoué!')
Échoué!
>>>Ici, items est une liste contenant une fonction, un module et une exception. Vous pouvez directement utiliser les éléments de la liste à la place des noms originaux :
items[0](-45) ## abs
items[1].sqrt(2) ## math
except items[2]: ## ValueErrorAvec un grand pouvoir vient une grande responsabilité. Juste parce que vous pouvez le faire ne signifie pas que vous devriez.
Dans cet ensemble d'exercices, nous examinons quelques-uns des pouvoirs issus des objets de première classe.
Dans le fichier portfolio.csv, nous lisons des données organisées en colonnes qui ressemblent à ceci :
name,shares,price
"AA",100,32.20
"IBM",50,91.10
...Dans le code précédent, nous avons utilisé le module csv pour lire le fichier, mais avons encore dû effectuer des conversions de type manuellement. Par exemple :
for row in rows:
name = row[0]
shares = int(row[1])
price = float(row[2])Ce type de conversion peut également être effectué de manière plus astucieuse en utilisant certaines opérations de base de liste.
Créez une liste Python qui contient les noms des fonctions de conversion que vous utiliseriez pour convertir chaque colonne en son type approprié :
>>> types = [str, int, float]
>>>La raison pour laquelle vous pouvez même créer cette liste est que tout en Python est de première classe. Donc, si vous voulez avoir une liste de fonctions, c'est parfait. Les éléments de la liste que vous avez créé sont des fonctions pour convertir une valeur x en un type donné (par exemple, str(x), int(x), float(x)).
Maintenant, lisez une ligne de données à partir du fichier ci-dessus :
>>> import csv
>>> f = open('portfolio.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> row
['AA', '100', '32.20']
>>>Comme indiqué, cette ligne n'est pas suffisante pour effectuer des calculs car les types sont incorrects. Par exemple :
>>> row[1] * row[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't multiply sequence by non-int of type'str'
>>>Cependant, peut-être que les données peuvent être associées aux types que vous avez spécifiés dans types. Par exemple :
>>> types[1]
<type 'int'>
>>> row[1]
'100'
>>>Essayez de convertir l'une des valeurs :
>>> types[1](row[1]) ## Identique à int(row[1])
100
>>>Essayez de convertir une autre valeur :
>>> types[2](row[2]) ## Identique à float(row[2])
32.2
>>>Essayez le calcul avec les valeurs converties :
>>> types[1](row[1])*types[2](row[2])
3220.0000000000005
>>>Associez les types de colonne aux champs et regardez le résultat :
>>> r = list(zip(types, row))
>>> r
[(<type'str'>, 'AA'), (<type 'int'>, '100'), (<type 'float'>,'32.20')]
>>>Vous remarquerez que cela a associé une conversion de type avec une valeur. Par exemple, int est associé à la valeur '100'.
La liste associée est utile si vous voulez effectuer des conversions sur toutes les valeurs, l'une après l'autre. Essayez ceci :
>>> converted = []
>>> for func, val in zip(types, row):
converted.append(func(val))
...
>>> converted
['AA', 100, 32.2]
>>> converted[1] * converted[2]
3220.0000000000005
>>>Assurez-vous de comprendre ce qui se passe dans le code ci-dessus. Dans la boucle, la variable func est l'une des fonctions de conversion de type (par exemple, str, int, etc.) et la variable val est l'une des valeurs telles que 'AA', '100'. L'expression func(val) convertit une valeur (un peu comme un cast de type).
Le code ci-dessus peut être compressé en une seule compréhension de liste.
>>> converted = [func(val) for func, val in zip(types, row)]
>>> converted
['AA', 100, 32.2]
>>>Souvenez-vous de la manière dont la fonction dict() peut facilement créer un dictionnaire si vous avez une séquence de noms de clés et de valeurs? Créons un dictionnaire à partir des en-têtes de colonne :
>>> headers
['name','shares', 'price']
>>> converted
['AA', 100, 32.2]
>>> dict(zip(headers, converted))
{'price': 32.2, 'name': 'AA','shares': 100}
>>>Bien sûr, si vous maîtrisez les compréhensions de liste, vous pouvez effectuer toute la conversion d'un seul coup en utilisant une compréhension de dictionnaire :
>>> { name: func(val) for name, func, val in zip(headers, types, row) }
{'price': 32.2, 'name': 'AA','shares': 100}
>>>En utilisant les techniques de cet exercice, vous pourriez écrire des instructions qui convertissent facilement les champs à partir de presque tout fichier de données orienté colonnes en un dictionnaire Python.
Pour illustrer, supposons que vous lisez des données à partir d'un autre fichier de données comme ceci :
>>> f = open('dowstocks.csv')
>>> rows = csv.reader(f)
>>> headers = next(rows)
>>> row = next(rows)
>>> headers
['name', 'price', 'date', 'time', 'change', 'open', 'high', 'low', 'volume']
>>> row
['AA', '39.48', '6/11/2007', '9:36am', '-0.18', '39.67', '39.69', '39.45', '181800']
>>>Convertissons les champs en utilisant un truc similaire :
>>> types = [str, float, str, str, float, float, float, float, int]
>>> converted = [func(val) for func, val in zip(types, row)]
>>> record = dict(zip(headers, converted))
>>> record
{'volume': 181800, 'name': 'AA', 'price': 39.48, 'high': 39.69,
'low': 39.45, 'time': '9:36am', 'date': '6/11/2007', 'open': 39.67,
'change': -0.18}
>>> record['name']
'AA'
>>> record['price']
39.48
>>>Bonus : Comment modifieriez-vous cet exemple pour analyser en outre l'entrée date en un tuple tel que (6, 11, 2007)?
Prenez le temps de réfléchir à ce que vous avez fait dans cet exercice. Nous reviendrons sur ces idées un peu plus tard.
Félicitations! Vous avez terminé le laboratoire sur les objets. Vous pouvez pratiquer d'autres laboratoires sur LabEx pour améliorer vos compétences.


