
Einführung
In diesem Lab wird es weitergehend um HDFS gehen, einen der wichtigsten Hadoop-Komponenten. Durch das Bearbeiten dieses Labs lernen Sie die Arbeitsweisen und die grundlegenden Operationen von HDFS sowie die Zugangsmethoden für WebHDFS im Hadoop-Software-Architektur.
Einführung in HDFS
Wie der Name schon sagt, ist HDFS (Hadoop Distributed File System) ein Komponenten der verteilten Speicherung innerhalb des Hadoop-Frameworks und ist fehler tolerant und skalierbar.
HDFS kann als Teil eines Hadoop-Clusters oder als eigenständiges, universelles verteiltes Dateisystem verwendet werden. Beispielsweise ist HBase auf der Grundlage von HDFS aufgebaut und Spark kann auch HDFS als eine der Datenquellen verwenden. Das Lernen der Architektur und der grundlegenden Operationen von HDFS wird von großer Hilfe bei der Konfiguration, Verbesserung und Diagnose von bestimmten Clustern sein.
HDFS ist die verteilte Speicherung, die von Hadoop-Anwendungen verwendet wird, die Quelle und der Zielort von Daten. HDFS-Clustern bestehen hauptsächlich aus NameNodes, die die Metadaten des Dateisystems verwalten, und DataNodes, die die tatsächlichen Daten speichern. Die Architektur ist in dem folgenden Diagramm dargestellt, das die Interaktionsmuster zwischen NameNodes, DataNodes und Clients zeigt:
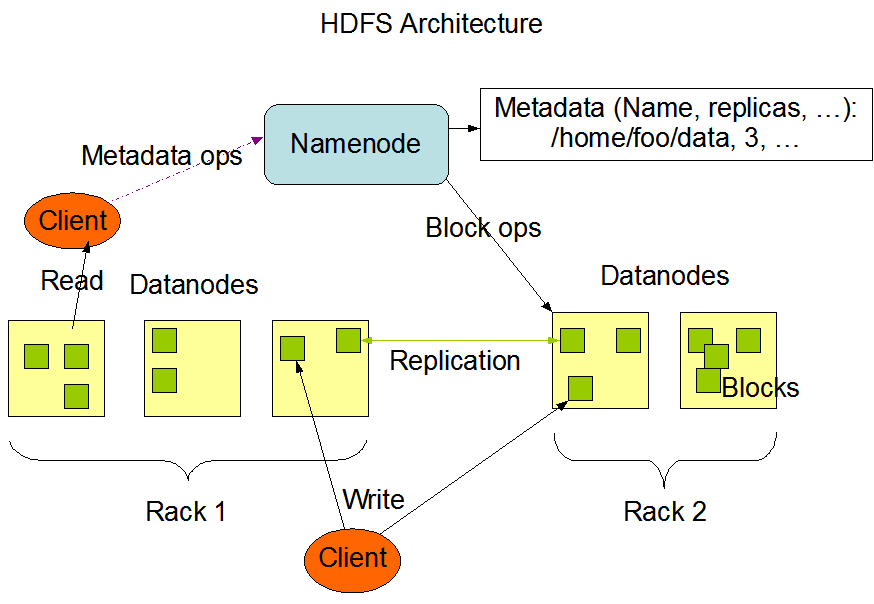 Dieses Diagramm stammt von der offiziellen Website von Hadoop.
Dieses Diagramm stammt von der offiziellen Website von Hadoop.
Zusammenfassung der Einführung in HDFS:
- HDFS-Übersicht: HDFS (Hadoop Distributed File System) ist eine fehler tolerant und skalierbare Komponente der verteilten Speicherung innerhalb des Hadoop-Frameworks.
- Architektur: HDFS-Clustern bestehen aus NameNodes zur Verwaltung von Metadaten und DataNodes zur Speicherung von tatsächlichen Daten. Die Architektur folgt einem Master/Slave-Modell mit einem einzigen NameNode und mehreren DataNodes.
- Dateispeicherung: Dateien in HDFS werden in Blöcke unterteilt, die auf verschiedenen DataNodes gespeichert werden, mit einer Standardblockgröße von 64 MB.
- Operationen: Der NameNode behandelt die Operationen des Dateisystem-Namespace, während die DataNodes die Lese- und Schreibanforderungen von Clients verwalten.
- Interaktionen: Clients kommunizieren mit dem NameNode für Metadaten und interagieren direkt mit den DataNodes für die Dateidaten.
- Bereitstellung: Typischerweise führt ein einzelner dedizierter Knoten den NameNode aus, während jeder andere Knoten eine DataNode-Instanz ausführt. HDFS wird mit Java gebaut und bietet Portabilität zwischen verschiedenen Umgebungen.
Das Verständnis dieser wichtigen Punkte zu HDFS wird helfen, Hadoop-Cluster effektiv zu konfigurieren, zu optimieren und zu diagnostizieren.
Zusammenfassung des Dateisystems
Dateisystem-Namespace
- Hierarchische Organisation: Sowohl HDFS als auch traditionelle Linux-Dateisysteme unterstützen die hierarchische Dateiorganisation mit einem Verzeichnisbaum-Struktur, was es Benutzern und Anwendungen ermöglicht, Verzeichnisse zu erstellen und Dateien zu speichern.
- Zugang und Operationen: Benutzer können mit HDFS über verschiedene Zugangsschnittstellen wie Befehlszeilen und APIs interagieren, was Operationen wie das Erstellen, Löschen, Verschieben und Umbenennen von Dateien ermöglicht.
- Funktionsunterstützung: Ab Version 3.3.6 implementiert HDFS keine Benutzerquoten, Zugangsberechtigungen, harte Links oder weiche Links. Zukünftige Versionen können jedoch diese Funktionen unterstützen, da die Architektur ihre Implementierung ermöglicht.
- NameNode-Verwaltung: Der NameNode in HDFS behandelt alle Änderungen am Dateisystem-Namespace und seinen Eigenschaften, einschließlich der Verwaltung des Replikationsfaktors von Dateien, der angibt, wie viele Kopien einer Datei auf HDFS aufbewahrt werden sollen.
Datensicherung
Am Anfang der Entwicklung war HDFS so konzipiert, um sehr große Dateien in einem großen Cluster auf einem cross-node, hoch zuverlässigen Weg zu speichern. Wie bereits erwähnt, speichert HDFS Dateien in Blöcken. Genauer gesagt, speichert es jede Datei als eine Sequenz von Blöcken. Mit Ausnahme des letzten Blocks sind alle Blöcke in der Datei die gleiche Größe.
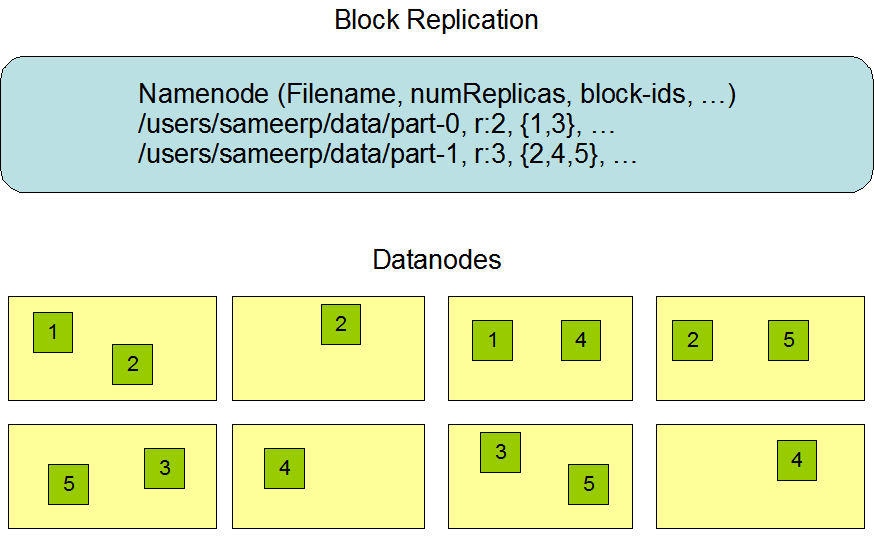 Dieses Diagramm stammt von der offiziellen Website von Hadoop.
Dieses Diagramm stammt von der offiziellen Website von Hadoop.
Die HDFS-Datensicherung und -Hochverfügbarkeit:
- Datensicherung: In HDFS werden Dateien in Blöcke unterteilt, die auf mehreren DataNodes repliziert werden, um Fehlertoleranz zu gewährleisten. Der Replikationsfaktor kann beim Erstellen oder Ändern der Datei angegeben werden, wobei jede Datei zu einem bestimmten Zeitpunkt nur einen Schreiber hat.
- Replikationsverwaltung: Der NameNode verwaltet, wie Dateiblöcke kopiert werden, indem er Heartbeat- und Blockstatusberichte von DataNodes empfängt. DataNodes melden ihren Arbeitszustand über Heartbeats, und Blockstatusberichte enthalten Informationen über alle Blöcke, die auf dem DataNode gespeichert sind.
- Hochverfügbarkeit: HDFS bietet einen gewissen Grad an Hochverfügbarkeit, indem es intern verlorene Dateikopien aus anderen Teilen des Clusters wiederherstellt, falls es zu Datenträgerfehlern oder anderen Ausfällen kommt. Dieses Mechanismus hilft, die Datengüte und Zuverlässigkeit im verteilten Speichersystem aufrechtzuerhalten.
Persistenz von Dateisystem-Metadaten
- Namespace-Verwaltung: Der HDFS-Namespace, der die Dateisystem-Metadaten enthält, wird im NameNode gespeichert. Jede Änderung am Dateisystem-Metadaten wird in einem EditLog aufgezeichnet, das Transaktionen wie das Erstellen von Dateien persistent macht. Das EditLog wird im lokalen Dateisystem gespeichert.
- FsImage: Der gesamte Dateisystem-Namespace, einschließlich der Zuordnung von Blöcken zu Dateien und der Attribute, wird in einer Datei namens FsImage gespeichert. Diese Datei wird ebenfalls im lokalen Dateisystem gespeichert, in dem der NameNode reside.
- Checkpoint-Prozess: Der Checkpoint-Prozess besteht darin, beim Start des NameNodes das FsImage und das EditLog von der Festplatte zu lesen. Alle Transaktionen im EditLog werden auf das in der Hauptspeicher befindliche FsImage angewendet, das dann wieder auf die Festplatte gespeichert wird, um die Persistenz zu gewährleisten. Nach diesem Prozess kann das alte EditLog abgeschnitten werden. In der aktuellen Version (3.3.6) treten Checkpoints nur beim Start des NameNodes auf, aber zukünftige Versionen können regelmäßige Checkpoints einführen, um die Zuverlässigkeit und die Datensynchronität zu verbessern.
Weitere Funktionen
- TCP/IP-Basis: Alle Kommunikationsprotokolle in HDFS basieren auf der TCP/IP-Protokollsuit, was eine zuverlässige Datenaustausch zwischen Knoten im verteilten Dateisystem gewährleistet.
- Client-Protokoll: Die Kommunikation zwischen dem Client und dem NameNode wird durch das Client-Protokoll erleichtert. Der Client startet eine Verbindung zu den konfigurierbaren TCP-Ports auf dem NameNode, um mit den Dateisystem-Metadaten zu interagieren.
- DataNode-Protokoll: Die Kommunikation zwischen DataNodes und dem NameNode stützt sich auf das DataNode-Protokoll. DataNodes kommunizieren mit dem NameNode, um ihren Status zu melden, Heartbeat-Signale zu senden und Datenspeicherblöcke als Teil des verteilten Speichersystems zu übertragen.
- Remote Procedure Call (RPC): Sowohl das Client-Protokoll als auch das DataNode-Protokoll werden mithilfe von Remote Procedure Call (RPC)-Mechanismen abstrahiert. Der NameNode antwortet auf RPC-Anfragen, die von DataNodes oder Clients initiiert werden, und spielt dabei eine passive Rolle im Kommunikationsprozess.
Das folgende ist einige Material für das erweitertes Lesen:
Benutzer wechseln
Bevor Sie den Task-Code schreiben, sollten Sie zunächst zum Benutzer hadoop wechseln. Doppelklicken Sie, um das Xfce-Terminal auf Ihrem Desktop zu öffnen, und geben Sie den folgenden Befehl ein. Das Passwort des Benutzers hadoop ist hadoop; es wird benötigt, wenn Sie sich wechseln:
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
Tipp: Das Passwort des Benutzers hadoop ist hadoop
Initialisierung von HDFS
Der Namenode sollte vor der ersten Verwendung von HDFS initialisiert werden. Diese Operation kann mit der Formatierung einer Festplatte verglichen werden, daher verwenden Sie diesen Befehl mit Vorsicht, wenn Sie Daten auf HDFS speichern.
Andernfalls starten Sie das Experiment in diesem Abschnitt neu. Verwenden Sie die "Standardumgebung" und initialisieren Sie HDFS mit dem folgenden Befehl:
/home/hadoop/hadoop/bin/hdfs namenode -format
Tipp: Der obige Befehl wird das HDFS-Dateisystem formatieren. Sie müssen das HDFS-Datverzeichnis löschen, bevor Sie den Befehl ausführen.
Sie müssen daher die Dienste rund um Hadoop stoppen und die Hadoop-Daten löschen.
stop-all.sh
rm -rf ~/hadoopdata
Wenn Sie die folgende Nachricht sehen, ist die Initialisierung abgeschlossen:
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Dateien importieren
Da HDFS ein auf lokalen Festplatten aufgebautes geschichtetes verteiltes Speichersystem ist, müssen Sie Daten in es importieren, bevor Sie HDFS verwenden.
Der erste und bequemste Weg, um einige Dateien vorzubereiten, ist es, die Hadoop-Konfigurationsdatei als Beispiel zu verwenden.
Zunächst müssen Sie den HDFS-Dämon starten:
/home/hadoop/hadoop/sbin/start-dfs.sh
Überprüfen Sie die Dienste:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
Erstellen Sie ein Verzeichnis und kopieren Sie die Daten, indem Sie den folgenden Befehl im Terminal eingeben:
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
Listieren Sie den Inhalt des Verzeichnisses:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
Jede Operation auf HDFS beginnt mit hdfs dfs und wird durch die entsprechenden Betriebsparameter ergänzt. Der am häufigsten verwendete Parameter ist put, der wie folgt verwendet wird und im Terminal eingegeben werden kann:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
Listieren Sie den Inhalt des Verzeichnisses:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
Das letzte /policy.xml des Befehls bedeutet, dass der Dateiname, der in HDFS gespeichert wird, policy.xml ist und der Pfad / (Wurzelverzeichnis) ist. Wenn Sie den vorherigen Dateinamen fortsetzen verwenden möchten, können Sie den Pfad / direkt angeben.
Wenn Sie mehrere Dateien hochladen müssen, können Sie den Dateipfad des lokalen Verzeichnisses kontinuierlich angeben und mit dem HDFS-Zielspeicherpfad beenden:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
Listieren Sie den Inhalt des Verzeichnisses:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
Für die Angabe von pfadbezogenen Parametern gelten die gleichen Regeln wie in einem Linux-System. Sie können Platzhalter (z. B. *.sh) verwenden, um die Operation zu vereinfachen.
Dateioperationen
Ähnlich können Sie den Parameter -ls verwenden, um die Dateien im angegebenen Verzeichnis aufzulisten:
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
Die hier aufgelisteten Dateien können je nach Experimentumgebung variieren.
Wenn Sie den Inhalt einer Datei anzeigen möchten, können Sie den Parameter cat verwenden. Das einfachste ist, direkt einen Dateipfad auf HDFS anzugeben. Wenn Sie lokale Verzeichnisse mit Dateien auf HDFS vergleichen möchten, können Sie ihre Pfade separat angeben. Es sollte jedoch bemerkt werden, dass das lokale Verzeichnis mit dem Indikator file:// beginnen muss, ergänzt durch den Dateipfad (z. B. /home/hadoop/.bashrc, vergessen Sie nicht das / vorne). Andernfalls wird jeder hier angegebene Pfad standardmäßig als Pfad auf HDFS erkannt:
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
Die Ausgabe lautet wie folgt:
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
Wenn Sie eine Datei an einen anderen Pfad kopieren müssen, können Sie den Parameter cp verwenden:
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
Ähnlich können Sie den Parameter mv verwenden, um eine Datei zu verschieben. Dies entspricht im Wesentlichen dem Befehlsformat des Linux-Dateisystems:
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
Verwenden Sie den Parameter lsr, um den Inhalt des aktuellen Verzeichnisses, einschließlich der Inhalte von Unterverzeichnissen, aufzulisten. Die Ausgabe lautet wie folgt:
hdfs dfs -lsr /
Wenn Sie neuen Inhalt an eine Datei auf HDFS anhängen möchten, können Sie den Parameter appendToFile verwenden. Und wenn Sie den lokalen Dateipfad angeben, der angehängt werden soll, können Sie mehrere davon angeben. Der letzte Parameter wird das Objekt sein, das angehängt werden soll. Die Datei muss auf HDFS existieren, andernfalls wird ein Fehler gemeldet:
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
Sie können den Parameter tail verwenden, um den Inhalt des Dateiende (den Endteil der Datei) anzuzeigen, um zu bestätigen, ob das Anhängen erfolgreich war:
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
Zeigen Sie die Ausgabe des tail-Befehls an:
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
Wenn Sie eine Datei oder ein Verzeichnis löschen müssen, verwenden Sie den Parameter rm. Dieser Parameter kann auch mit -r und -f versehen werden, was die gleichen Bedeutungen hat wie bei dem Linux-Dateisystembefehl rm:
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
Der Inhalt der Datei moved_file.txt wird gelöscht, und der Befehl gibt die folgende Ausgabe zurück: 'Deleted /moved_file.txt'
Verzeichnisoperationen
In den vorherigen Abschnitten haben wir gelernt, wie man ein Verzeichnis in HDFS erstellt. Tatsächlich können Sie, wenn Sie mehrere Verzeichnisse gleichzeitig erstellen möchten, direkt die Pfade mehrerer Verzeichnisse als Parameter angeben. Der Parameter -p gibt an, dass das übergeordnete Verzeichnis automatisch erstellt wird, wenn es nicht existiert:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
Wenn Sie wissen möchten, wie viel Speicherplatz eine bestimmte Datei oder ein Verzeichnis einnimmt, können Sie den Parameter du verwenden:
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
Die Ausgabe lautet wie folgt:
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
Dateien exportieren
Im vorherigen Abschnitt haben wir hauptsächlich die Datei- und Verzeichnisoperationen in HDFS vorgestellt. Wenn eine Anwendung wie MapReduce berechnet und die Datei, in der das Ergebnis aufgezeichnet ist, erzeugt wird, können Sie den Parameter get verwenden, um sie in das lokale Verzeichnis des Linux-Systems zu exportieren.
Der erste Pfadparameter hier bezieht sich auf den Pfad in HDFS, und der letzte Pfad bezieht sich auf den Pfad, der im lokalen Verzeichnis gespeichert wird:
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
Wenn der Export erfolgreich ist, können Sie die Datei im lokalen Verzeichnis finden:
cd ~
ls
Die Ausgabe lautet wie folgt:
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Hadoop-Web-Operation
Web-Verwaltungschnittstelle
Jeder NameNode oder DataNode führt intern einen Webserver aus, der grundlegende Informationen wie den aktuellen Zustand des Clusters anzeigt. In der Standardkonfiguration ist die Startseite des NameNodes http://localhost:9870/. Sie listet grundlegende Statistiken für DataNodes und Cluster auf.
Öffnen Sie einen Webbrowser und geben Sie im Adressleisten Folgendes ein:
http://localhost:9870/
In Zusammenfassung können Sie die Anzahl der aktiven DataNode-Knoten im aktuellen "Cluster" sehen:
Die Weboberfläche kann auch verwendet werden, um Verzeichnisse und Dateien in HDFS zu durchsuchen. Klicken Sie im oberen Menüband auf den Link "Dateisystem durchsuchen" unter "Werkzeuge":
Ein Hadoop-Cluster schließen
Jetzt haben wir die Einführung einiger grundlegender Operationen von WebHDFS abgeschlossen. Weitere Anweisungen finden Sie in der Dokumentation zu WebHDFS. Dieser Lab-Session ist nun zu Ende. Als Gewohnheit sollten wir dennoch den Hadoop-Cluster schließen:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
Zusammenfassung
In diesem Lab wurde die Architektur von HDFS vorgestellt. Außerdem haben wir die grundlegenden HDFS-Befehlszeilenbefehle gelernt und anschließend den Web-Zugang zu HDFS aktiviert, was es HDFS ermöglicht, als ein realer Speicherdienst für externe Anwendungen zu fungieren.
In diesem Lab wird kein Szenario zum Löschen von Dateien in WebHDFS aufgeführt. Sie können die Dokumentation selbst überprüfen. Es verstecken sich weitere Funktionen in der offiziellen Dokumentation, daher sollten Sie sich daran halten, die Dokumentation zu lesen.
Das folgende ist das Material für das erweitertes Lesen:


