
Einführung
In diesem Lab lernen Sie die Grundlagen der Erstellung eines Modells für maschinelles Lernen mit einer der beliebtesten Python-Bibliotheken kennen: scikit-learn. Wir konzentrieren uns auf die lineare Regression, einen grundlegenden, aber leistungsstarken Algorithmus, der zur Vorhersage kontinuierlicher Werte wie Preise oder Temperaturen verwendet wird.
Unser Ziel ist es, ein Modell zu entwickeln, das die mittleren Immobilienpreise in kalifornischen Bezirken vorhersagen kann. Wir verwenden dazu den kalifornischen Immobilien-Datensatz, der praktischerweise bereits in scikit-learn enthalten ist.
Im Laufe dieses Labs lernen Sie:
- Einen Datensatz aus
scikit-learnzu laden. - Die Daten für das Training und den Test vorzubereiten und aufzuteilen.
- Ein Modell zur linearen Regression zu erstellen und zu trainieren.
- Das trainierte Modell für Vorhersagen zu nutzen.
- Die Ergebnisse zu visualisieren, um die Modellleistung zu verstehen.
Sie führen alle Aufgaben innerhalb der WebIDE aus. Fangen wir an!
Laden des kalifornischen Immobilien-Datensatzes mit datasets.fetch_california_housing()
In diesem Schritt beginnen wir mit dem Laden des Datensatzes für unser Modell. scikit-learn enthält mehrere integrierte Datensätze, die sich hervorragend zum Lernen und Üben eignen. Wir verwenden den kalifornischen Immobilien-Datensatz.
Zuerst müssen wir ein Python-Skript erstellen. Eine Datei namens main.py wurde bereits für Sie im Verzeichnis ~/project angelegt. Sie finden sie im Dateiexplorer auf der linken Seite der WebIDE.
Öffnen Sie main.py und fügen Sie den folgenden Code hinzu. Dieser Code importiert die notwendigen Bibliotheken (fetch_california_housing aus sklearn.datasets und pandas) und lädt den Datensatz. Wir verwenden pandas, um die Daten in einen DataFrame umzuwandeln – eine tabellarische Datenstruktur, die einfach zu betrachten und zu bearbeiten ist.
Bitte fügen Sie den folgenden Code in main.py ein:
import pandas as pd
from sklearn.datasets import fetch_california_housing
## Load the California housing dataset
california = fetch_california_housing()
## Create a DataFrame
california_df = pd.DataFrame(california.data, columns=california.feature_names)
california_df['MedHouseVal'] = california.target
## Print the first 5 rows of the DataFrame
print("California Housing Dataset:")
print(california_df.head())
Lassen Sie uns nun das Skript ausführen, um die Ausgabe zu sehen. Öffnen Sie ein Terminal in der WebIDE (Sie können das Menü "Terminal" -> "New Terminal" verwenden) und führen Sie den folgenden Befehl aus:
python3 main.py
Sie sollten die ersten fünf Zeilen des Datensatzes in der Konsole sehen. Die Spalte MedHouseVal ist unsere Zielvariable; sie repräsentiert den mittleren Immobilienwert für kalifornische Bezirke, ausgedrückt in Hunderttausenden von Dollar ($100,000).
California Housing Dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
Aufteilen der Daten in Trainings- und Testdaten mit train_test_split aus sklearn.model_selection
In diesem Schritt bereiten wir unsere Daten für den Trainingsprozess vor. Ein entscheidender Teil des maschinellen Lernens besteht darin, das Modell mit Daten zu bewerten, die es zuvor noch nie gesehen hat. Dazu teilen wir unseren Datensatz in zwei Teile auf: einen Trainingssatz und einen Testsatz. Das Modell lernt aus dem Trainingssatz, und wir verwenden den Testsatz, um zu prüfen, wie gut es funktioniert.
Zuerst müssen wir unsere Merkmale (die Eingabevariablen, X) von unserem Ziel (dem Wert, den wir vorhersagen wollen, y) trennen. In unserem Fall ist X alles außer der Spalte MedHouseVal, und y ist die Spalte MedHouseVal.
Anschließend verwenden wir die Funktion train_test_split aus sklearn.model_selection, um die Aufteilung durchzuführen.
Fügen Sie den folgenden Code an Ihre main.py-Datei an:
from sklearn.model_selection import train_test_split
## Prepare the data
X = california_df.drop('MedHouseVal', axis=1) ## Features (input variables)
y = california_df['MedHouseVal'] ## Target variable (what we want to predict)
## Split the data into training and testing sets
## test_size=0.2: Reserve 20% of data for testing, 80% for training
## random_state=42: Ensures reproducible splits (same result every run)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
## Print the shapes of the new datasets to confirm the split
print("\n--- Data Split ---")
print("X_train shape:", X_train.shape) ## Training features
print("X_test shape:", X_test.shape) ## Test features
print("y_train shape:", y_train.shape) ## Training target values
print("y_test shape:", y_test.shape) ## Test target values
Führen Sie das Skript nun erneut über das Terminal aus:
python3 main.py
Sie sehen nun die Formen der neu erstellten Trainings- und Testdatensätze unterhalb des DataFrames. Dies bestätigt, dass die Daten korrekt aufgeteilt wurden.
--- Data Split ---
X_train shape: (16512, 8)
X_test shape: (4128, 8)
y_train shape: (16512,)
y_test shape: (4128,)
Initialisierung des LinearRegression-Modells aus sklearn.linear_model
In diesem Schritt erstellen wir unser Modell zur linearen Regression. scikit-learn macht dies unglaublich einfach. Wir müssen lediglich die Klasse LinearRegression aus dem Modul sklearn.linear_model importieren und eine Instanz davon erstellen.
Diese Instanz ist ein Objekt, das den Algorithmus der linearen Regression enthält. Die lineare Regression findet die am besten passende Linie durch die Datenpunkte unter Verwendung der Formel y = mx + b, wobei m die Koeffizienten (Gewichte) für jedes Merkmal und b der Achsenabschnitt sind. Hier verwenden wir Standardparameter, die für die meisten grundlegenden Fälle gut funktionieren.
 Abbildung 1: Formel der linearen Regression y = mx + b, wobei m die Steigung und b der Achsenabschnitt ist
Abbildung 1: Formel der linearen Regression y = mx + b, wobei m die Steigung und b der Achsenabschnitt ist
Fügen Sie den folgenden Code an Ihre main.py-Datei an. Dies importiert die Klasse LinearRegression und erstellt ein Modellobjekt.
from sklearn.linear_model import LinearRegression
## Initialize the Linear Regression model
model = LinearRegression()
## Print the model to confirm it's created
print("\n--- Model Initialized ---")
print(model)
Führen Sie Ihr main.py-Skript erneut über das Terminal aus:
python3 main.py
Die Ausgabe enthält nun eine Zeile, die das LinearRegression-Objekt anzeigt. Dies bestätigt, dass das Modell erfolgreich initialisiert wurde.
--- Model Initialized ---
LinearRegression()
Anpassen des Modells mit model.fit(X_train, y_train)
In diesem Schritt trainieren wir unser Modell. Dieser Prozess wird oft als "Anpassen" (Fitting) des Modells an die Daten bezeichnet. Während des Anpassens lernt das Modell die Beziehungen zwischen den Merkmalen (X_train) und der Zielvariablen (y_train). Bei der linearen Regression bedeutet dies, die optimalen Koeffizienten für jedes Merkmal zu finden, um das Ziel bestmöglich vorherzusagen.
Wir verwenden die Methode fit() unseres Modellobjekts und übergeben unsere Trainingsdaten als Argumente.
Fügen Sie den folgenden Code an Ihre main.py-Datei an:
## Fit (train) the model on the training data
## The fit() method learns the relationship between features (X_train) and target (y_train)
## It calculates optimal coefficients for each feature and the intercept using least squares optimization
model.fit(X_train, y_train)
## After fitting, the model has learned the coefficients and intercept.
## The intercept represents the predicted value when all features are zero
print("\n--- Model Trained ---")
print("Intercept:", model.intercept_)
Führen Sie nun das Skript über das Terminal aus:
python3 main.py
Nachdem das Skript ausgeführt wurde, sehen Sie einen neuen Abschnitt in der Ausgabe, der den Achsenabschnitt (Intercept) des linearen Regressionsmodells zeigt. Der Achsenabschnitt ist der Wert der Vorhersage, wenn alle Merkmalswerte null sind. Das Erscheinen eines numerischen Wertes hier bestätigt, dass das Modell erfolgreich auf den Daten trainiert wurde.
--- Model Trained ---
Intercept: -37.023277706064185
Vorhersagen auf Testdaten mit model.predict(X_test)
In diesem letzten Schritt verwenden wir unser trainiertes Modell, um Vorhersagen zu treffen. Dies ist das ultimative Ziel der Erstellung eines Vorhersagemodells. Wir verwenden die Testdaten (X_test), die das Modell während des Trainings nicht gesehen hat, um seine Leistung zu bewerten.
Wir verwenden die Methode predict() unseres trainierten Modellobjekts und übergeben die Testmerkmale (X_test) als Argument. Die Methode gibt ein Array mit vorhergesagten Werten für die Zielvariable zurück.
Fügen Sie den folgenden Code an Ihre main.py-Datei an:
## Make predictions on the test data
## The predict() method uses the learned coefficients and intercept to calculate predictions
## Formula: prediction = intercept + (coeff1 * feature1) + (coeff2 * feature2) + ...
predictions = model.predict(X_test)
## Print the first 5 predictions (values are in $100,000 units)
print("\n--- Predictions ---")
print(predictions[:5])
Führen Sie nun das vollständige Skript ein letztes Mal über das Terminal aus:
python3 main.py
Die Ausgabe enthält nun die ersten fünf vorhergesagten Immobilienpreise für den Testsatz. Dies sind die Werte, von denen unser Modell annimmt, dass sie die mittleren Immobilienpreise basierend auf den Merkmalen in X_test sein sollten. Sie können diese Vorhersagen konzeptionell mit den tatsächlichen Werten in y_test vergleichen, um die Genauigkeit des Modells einzuschätzen.
--- Predictions ---
[0.71912284 1.76401657 2.70965883 2.83892593 2.60465725]
Herzlichen Glückwunsch! Sie haben erfolgreich ein Modell zur linearen Regression mit scikit-learn erstellt, trainiert und verwendet.
Visualisierung der Modellvorhersagen mit matplotlib.pyplot.scatter()
In diesem letzten Schritt erstellen wir eine Visualisierung, um die Leistung unseres Modells besser zu verstehen. Visualisierung ist beim maschinellen Lernen entscheidend, da sie uns hilft, Muster und Beziehungen zu erkennen, die aus reinen Zahlen nicht sofort ersichtlich sind.
Wir erstellen ein Streudiagramm (Scatter Plot), das die tatsächlichen Immobilienpreise (y_test) mit den Vorhersagen unseres Modells vergleicht. Diese Art von Diagramm wird als "Vorhersage vs. Tatsächlich"-Streudiagramm bezeichnet. Wäre unser Modell perfekt, würden alle Punkte auf einer diagonalen Linie (45-Grad-Linie) liegen, auf der die vorhergesagten Werte den tatsächlichen Werten entsprechen.
Wir verwenden matplotlib, um diese Visualisierung zu erstellen und als Bilddatei zu speichern.
Fügen Sie den folgenden Code an Ihre main.py-Datei an:
import matplotlib.pyplot as plt
## Create a scatter plot comparing actual vs predicted values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5, color='blue', edgecolors='black')
## Add a diagonal line showing perfect predictions (where predicted = actual)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', linewidth=2, label='Perfect Prediction')
## Add labels and title
plt.xlabel('Actual House Prices ($100,000)')
plt.ylabel('Predicted House Prices ($100,000)')
plt.title('Linear Regression: Actual vs Predicted House Prices')
plt.legend()
plt.grid(True, alpha=0.3)
## Save the plot to a file
plt.savefig('housing_predictions.png', dpi=300, bbox_inches='tight')
plt.close()
print("\n--- Visualization Complete ---")
print("Plot saved to housing_predictions.png")
Führen Sie nun das vollständige Skript über das Terminal aus:
python3 main.py
Sie sehen eine Bestätigungsmeldung, dass das Diagramm gespeichert wurde.
--- Visualization Complete ---
Plot saved to housing_predictions.png
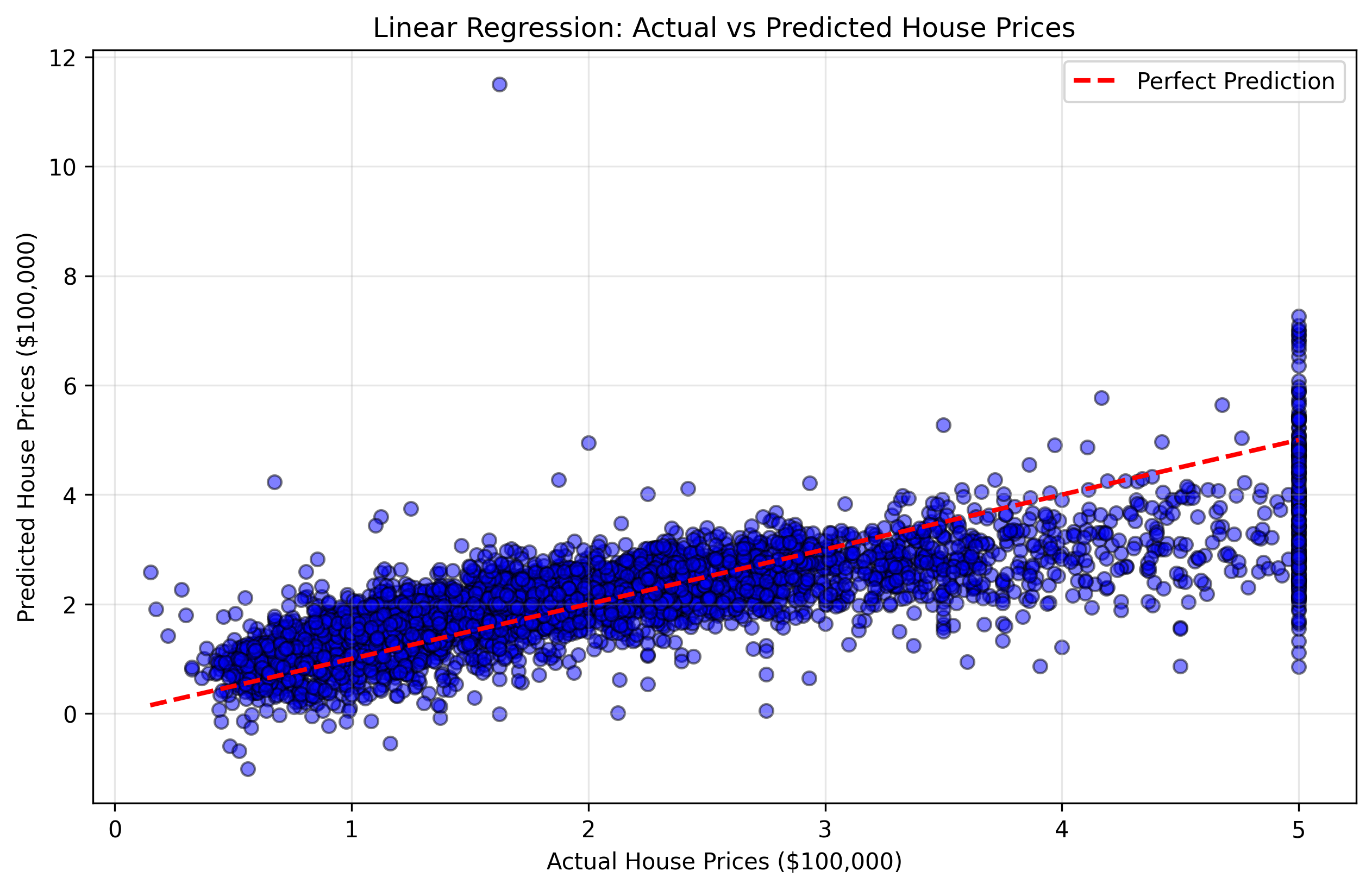 Abbildung 2: Streudiagramm, das die tatsächlichen vs. vorhergesagten Immobilienpreise zeigt. Punkte, die näher an der roten diagonalen Linie liegen, deuten auf bessere Vorhersagen hin.
Abbildung 2: Streudiagramm, das die tatsächlichen vs. vorhergesagten Immobilienpreise zeigt. Punkte, die näher an der roten diagonalen Linie liegen, deuten auf bessere Vorhersagen hin.
Diese Visualisierung hilft Ihnen zu verstehen:
- Punkte nahe der diagonalen Linie: Gute Vorhersagen, bei denen das Modell präzise war.
- Punkte weit entfernt von der diagonalen Linie: Schlechte Vorhersagen, bei denen das Modell größere Fehler gemacht hat.
- Gesamtmuster: Ob das Modell dazu neigt, bestimmte Preisbereiche zu über- oder unterbewerten.
Sie können die Datei housing_predictions.png im Dateiexplorer per Doppelklick öffnen, um Ihre Visualisierung zu betrachten.
Herzlichen Glückwunsch! Sie haben erfolgreich ein Modell zur linearen Regression mit scikit-learn erstellt, trainiert, getestet und visualisiert.
Zusammenfassung
In diesem Lab haben Sie den gesamten Arbeitsablauf zur Erstellung eines grundlegenden Modells für maschinelles Lernen mit scikit-learn durchlaufen.
Sie begannen mit dem Laden des kalifornischen Immobilien-Datensatzes und dessen Vorbereitung mit pandas. Dann lernten Sie, wie wichtig es ist, Ihre Daten in Trainings- und Testsets aufzuteilen, und führten diese Aufteilung mit train_test_split durch.
Anschließend initialisierten Sie ein LinearRegression-Modell, trainierten es mit der Methode fit() auf Ihren Trainingsdaten, nutzten das trainierte Modell für Vorhersagen auf ungesehenen Testdaten mit der Methode predict() und visualisierten schließlich die Ergebnisse, um die Leistung Ihres Modells zu verstehen.
Dieses Lab bietet eine solide Grundlage in scikit-learn. Von hier aus können Sie fortgeschrittenere Themen erkunden, wie zum Beispiel:
- Modellbewertung: Berechnung von Metriken wie dem mittleren quadratischen Fehler (MSE) oder R-Quadrat, um die Genauigkeit des Modells zu messen.
- Datenvisualisierung: Erstellung fortgeschrittenerer Diagramme wie Residuenplots, Diagramme zur Merkmalswichtigkeit oder Korrelationsmatrizen.
- Merkmals-Skalierung: Standardisierung oder Normalisierung von Merkmalen für eine bessere Leistung.
- Regularisierung: Verwendung von Ridge- oder Lasso-Regression, um Overfitting zu vermeiden.
- Kreuzvalidierung: Robustere Bewertung mittels k-facher Kreuzvalidierung.
- Andere Algorithmen: Ausprobieren von Random Forest, Support Vector Machines oder neuronalen Netzen.


