
Einführung
Willkommen zu diesem praktischen Lab über K-Nearest Neighbors (KNN)-Klassifizierung mit scikit-learn! Scikit-learn ist eine leistungsstarke und beliebte Python-Bibliothek für maschinelles Lernen. Der KNN-Algorithmus ist einer der einfachsten, aber effektivsten Klassifizierungsalgorithmen. Er klassifiziert einen neuen Datenpunkt basierend auf der Mehrheitsklasse seiner 'k' nächsten Nachbarn im Merkmalsraum. In diesem Lab durchlaufen Sie den vollständigen Prozess des Aufbaus eines Modells für maschinelles Lernen: Laden des berühmten Iris-Datensatzes, Aufteilen in Trainings- und Testdatensätze, Initialisieren und Trainieren eines KNN-Klassifikators und schließlich die Verwendung des trainierten Modells zur Vorhersage auf neuen, ungesehenen Daten. Am Ende dieses Labs werden Sie ein solides Verständnis des grundlegenden Workflows für überwachtes Lernen in scikit-learn haben.
Iris-Datensatz mit datasets.load_iris() laden
In diesem Schritt laden Sie zunächst den notwendigen Datensatz. Wir verwenden den klassischen Iris-Datensatz, der bequem in scikit-learn enthalten ist. Zuerst müssen Sie das Modul datasets aus sklearn importieren. Dann rufen Sie die Funktion load_iris() auf, um die Daten zu erhalten.
Verständnis von load_iris():
- Rückgabetyp: Gibt ein
Bunch-Objekt zurück (ähnlich einem Wörterbuch), das Folgendes enthält:.data: Merkmalsmatrix (150 Stichproben × 4 Merkmale: Kelchblattlänge, Kelchblattbreite, Blütenblattlänge, Blütenblattbreite).target: Label-Array (Spezies: 0=setosa, 1=versicolor, 2=virginica).feature_names: Namen der 4 Merkmale.target_names: Namen der 3 Spezies
- Zweck: Stellt einen sauberen, gebrauchsfertigen Datensatz für Klassifizierungstraining bereit
Wir weisen diese Variablen X und y zu, was eine gängige Konvention im maschinellen Lernen ist (X für Merkmale, y für Labels).
Öffnen Sie die Datei main.py im Editor auf der linken Seite und fügen Sie den folgenden Code hinzu.
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Assign features to X and labels to y
X = iris.data
y = iris.target
## You can print the shape to see the dimensions
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
Führen Sie nun das Skript im Terminal aus, um die Ausgabe zu sehen.
python3 main.py
Sie sollten die Dimensionen der Merkmalsmatrix und des Label-Vektors sehen.
Features shape: (150, 4)
Labels shape: (150,)
Dies bedeutet, dass wir 150 Stichproben (Blumen) und 4 Merkmale für jede Stichprobe haben.
Daten mit train_test_split aus sklearn.model_selection in Trainings- und Testdaten aufteilen
In diesem Schritt teilen Sie den Datensatz in zwei Teile auf: ein Trainingsset und ein Testset. Dies ist ein entscheidender Schritt im maschinellen Lernen, um die Leistung eines Modells auf ungesehenen Daten zu bewerten.
Verständnis der Parameter von train_test_split():
test_size=0.3: Reserviert 30 % der Daten für Tests, 70 % für das Trainingrandom_state=42: Stellt reproduzierbare Aufteilungen sicher (gleicher Zufallsgenerator-Seed bei jedem Lauf)- Zweck: Verhindert Overfitting durch Bewertung des Modells auf ungesehenen Daten
- Ausgabe: Gibt vier Arrays zurück: X_train, X_test, y_train, y_test
Wir trainieren das Modell auf dem Trainingsset und testen dann seine Vorhersagekraft auf dem Testset. Scikit-learn bietet hierfür eine praktische Funktion namens train_test_split. Sie müssen sie aus sklearn.model_selection importieren.
Fügen Sie den folgenden Code am Ende Ihrer Datei main.py hinzu.
from sklearn.model_selection import train_test_split
## Split data into training and testing sets
## test_size=0.3 means 30% of the data will be used for testing
## random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Print the shapes of the new sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
Führen Sie das Skript nun erneut aus.
python3 main.py
Die Ausgabe enthält nun die Formen Ihrer Trainings- und Testsets.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
KNeighborsClassifier mit n_neighbors=3 aus sklearn.neighbors initialisieren
In diesem Schritt initialisieren Sie den K-Nearest Neighbors-Klassifikator. Die Kernidee von KNN ist die Vorhersage der Klasse eines Datenpunkts, indem die Klassen seiner 'k' nächsten Nachbarn betrachtet werden.
Verständnis der Parameter von KNeighborsClassifier():
n_neighbors=3: Anzahl der nächsten Nachbarn, die für die Vorhersage berücksichtigt werden- Kleinere Werte (z. B. 1-3): Empfindlicher gegenüber Rauschen, kann zu Overfitting führen
- Größere Werte (z. B. 5-7): Glattere Entscheidungsgrenzen, robuster
- Verhalten des Algorithmus: Für die Vorhersage werden die k nächsten Trainingspunkte gesucht und eine Mehrheitsabstimmung durchgeführt
- Keine Trainingsphase: KNN ist ein "Lazy Learner" – er speichert Trainingsdaten und berechnet während der Vorhersage
Der KNeighborsClassifier ist die Klasse in scikit-learn, die diesen Algorithmus implementiert. Sie müssen ihn aus sklearn.neighbors importieren. Erstellen wir ein Klassifikatorobjekt und nennen es clf.
Fügen Sie den folgenden Code am Ende Ihrer Datei main.py hinzu.
from sklearn.neighbors import KNeighborsClassifier
## Initialize the KNN classifier with n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
Dieser Code erzeugt keine Ausgabe, aber er erstellt das Klassifikatorobjekt im Speicher, bereit für das Training im nächsten Schritt.
Klassifikator mit clf.fit(X_train, y_train) trainieren
In diesem Schritt trainieren Sie den Klassifikator, auch "fit" genannt, anhand Ihrer Trainingsdaten. Für den KNN-Algorithmus ist die "Trainingsphase" sehr einfach: Sie besteht lediglich darin, den gesamten Trainingsdatensatz (X_train und y_train) zu speichern.
Verständnis der .fit()-Methode:
- Eingabeparameter:
X_train(Merkmalsmatrix),y_train(Ziel-Labels) - Was sie tut: Speichert die Trainingsdaten im Speicher zur späteren Verwendung während der Vorhersage
- KNN-Spezifität: Im Gegensatz zu anderen Algorithmen lernt KNN während des Fits keine Parameter
- Zweck: Bereitet das Modell auf Vorhersagen für neue Daten vor
Wenn für einen neuen Punkt eine Vorhersage erforderlich ist, findet der Algorithmus die 'k' nächsten Punkte in diesem gespeicherten Datensatz und trifft eine Entscheidung. Um das Modell in scikit-learn zu trainieren, verwenden Sie die .fit()-Methode des Klassifikatorobjekts. Die Methode nimmt die Trainingsmerkmale (X_train) und die entsprechenden Trainings-Labels (y_train) als Argumente entgegen.
Fügen Sie die folgende Codezeile am Ende von main.py hinzu.
## Train the classifier using the training data
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
Nachdem Sie den Code hinzugefügt haben, führen Sie das Skript aus.
python3 main.py
Sie sehen eine Bestätigungsnachricht, dass der Klassifikator trainiert wurde.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
Klassen mit clf.predict(X_test) vorhersagen
In diesem letzten Schritt verwenden Sie den trainierten Klassifikator, um Vorhersagen für die Testdaten zu treffen. Nachdem das Modell von den Trainingsdaten gelernt hat, können wir ihm die Merkmale des Testdatensatzes (X_test), die es noch nie zuvor gesehen hat, übergeben und es bitten, die Klasse für jede Stichprobe vorherzusagen.
Verständnis der .predict()-Methode:
- Eingabeparameter:
X_test(Merkmalsmatrix von ungesehenen Daten) - Algorithmus-Prozess: Findet für jede Teststichprobe die k nächsten Nachbarn in den Trainingsdaten und verwendet eine Mehrheitsabstimmung
- Ausgabe: Array von vorhergesagten Klassen-Labels (gleiche Länge wie die Eingabestichproben)
- Distanzmetrik: Verwendet standardmäßig die Euklidische Distanz, um die Ähnlichkeit zwischen Punkten zu messen
- Zweck: Bewertet die Modellleistung auf neuen, ungesehenen Daten
Dies geschieht mit der .predict()-Methode. Die Methode nimmt die Testmerkmale (X_test) als Eingabe und gibt ein Array von vorhergesagten Labels zurück. Wir speichern diese Vorhersagen in einer Variablen namens predictions und geben sie auf der Konsole aus. Sie können auch die tatsächlichen Labels (y_test) ausgeben, um zu sehen, wie gut das Modell abgeschnitten hat.
Fügen Sie das letzte Code-Fragment zu Ihrer Datei main.py hinzu.
## Make predictions on the test data
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
Führen Sie nun das vollständige Skript aus.
python3 main.py
Sie sehen das Array der vorhergesagten Klassen-Labels für den Testdatensatz, gefolgt von dem Array der tatsächlichen Labels.
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
KNN-Klassifizierungsergebnisse visualisieren
In diesem Bonus-Schritt erstellen Sie Visualisierungen, um Ihre KNN-Klassifizierungsergebnisse besser zu verstehen. Visualisierung hilft Ihnen zu sehen, wie gut Ihr Modell abgeschnitten hat, und die vom KNN-Algorithmus erzeugten Entscheidungsgrenzen zu verstehen.
Datenvisualisierung in der Klassifizierung verstehen:
- Streudiagramme (Scatter plots): Zeigen Beziehungen zwischen Merkmalen und wie Klassen verteilt sind
- Farbkodierung: Verschiedene Farben repräsentieren verschiedene Klassen (Arten)
- Trainings- vs. Testdaten: Hilft beim Verständnis der Modellverallgemeinerung
- Vorhersagegenauigkeit: Visueller Vergleich von vorhergesagten vs. tatsächlichen Labels
Fügen Sie den folgenden Code am Ende Ihrer main.py-Datei hinzu, um Visualisierungen zu erstellen:
import matplotlib.pyplot as plt
import numpy as np
## Erstellen von Subplots für mehrere Visualisierungen
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## Plot 1: Trainingsdaten mit unterschiedlichen Farben für jede Klasse
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Verteilung der Trainingsdaten')
axes[0].legend(*scatter1.legend_elements(), title="Klassen")
## Plot 2: Testdaten-Vorhersagen vs. tatsächliche Labels
## Erstellen eines Vergleichs: korrekte Vorhersagen vs. falsche
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Korrekte Vorhersagen plotten
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Falsche Vorhersagen mit anderem Marker plotten
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Testdaten: Vorhersagen vs. Tatsächlich\n(korrekt=●, falsch=✕)')
## Legende erstellen
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Korrekt'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Falsch')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualisierung wurde in knn_classification_results.png gespeichert")
## Zusätzlich: Vorhersagegenauigkeit anzeigen
accuracy = np.mean(correct_predictions) * 100
print(f"Modellgenauigkeit: {accuracy:.1f}%")
Führen Sie das aktualisierte Skript aus:
python3 main.py
Sie sollten eine Ausgabe sehen, die Folgendes enthält:
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
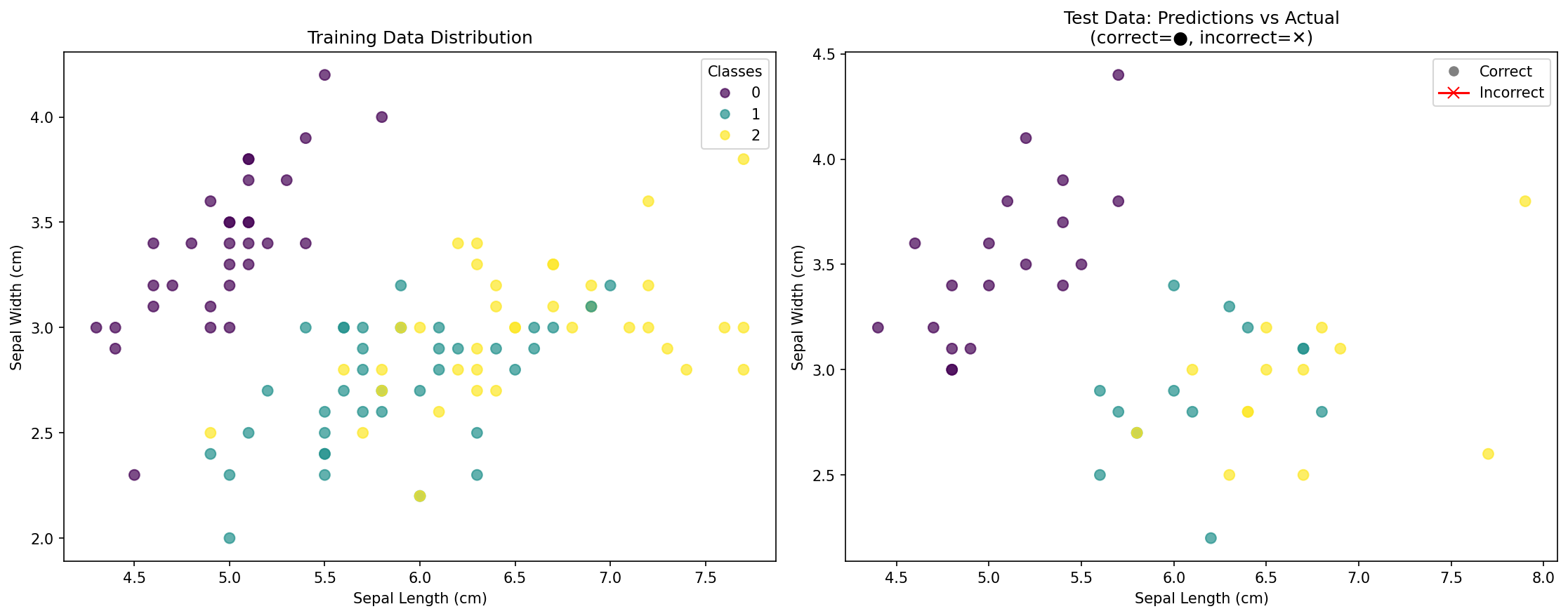
Was die Visualisierung zeigt:
- Linkes Diagramm: Verteilung der Trainingsdatenpunkte, farblich nach ihrer tatsächlichen Art kodiert
- Rechtes Diagramm: Testdatenpunkte, die Folgendes zeigen:
- Kreise (●): Korrekt klassifizierte Punkte
- Kreuze (✕): Falsch klassifizierte Punkte (falls vorhanden)
- Genauigkeitswert: Gesamtprozentsatz der korrekten Vorhersagen
Diese Visualisierung hilft Ihnen zu verstehen:
- Wie die Klassen im Merkmalsraum verteilt sind
- Ob Ihr Modell überanpasst oder gut verallgemeinert
- Welche Bereiche für die Klassifizierung schwierig sein könnten
- Die Wirksamkeit Ihres KNN-Modells visuell
Zusammenfassung
Herzlichen Glückwunsch zum Abschluss dieses Labs! Sie haben erfolgreich ein K-Nearest Neighbors-Klassifizierungsmodell mit scikit-learn erstellt und trainiert. Sie haben den grundlegenden Arbeitsablauf eines überwachten Machine-Learning-Projekts kennengelernt, der Folgendes umfasst:
- Laden eines Datensatzes mit
sklearn.datasets. - Aufteilen der Daten in Trainings- und Testsets mit
train_test_split. - Initialisieren eines Klassifikators, in diesem Fall
KNeighborsClassifier. - Trainieren des Modells auf den Trainingsdaten mit der
.fit()-Methode. - Erstellen von Vorhersagen auf neuen, ungesehenen Daten mit der
.predict()-Methode. - Visualisieren von Ergebnissen, um die Modellleistung und Entscheidungsmuster zu verstehen.
Dieser Prozess bildet die Grundlage für viele Machine-Learning-Aufgaben. Von hier aus könnten Sie untersuchen, wie Sie die Leistung Ihres Modells formeller mit Metriken wie Genauigkeit (accuracy), Präzision (precision) und Rückruf (recall) bewerten können, oder mit verschiedenen Werten für n_neighbors experimentieren, um zu sehen, wie sich dies auf das Ergebnis auswirkt. Sie könnten auch versuchen, Entscheidungsgrenzen zu visualisieren oder andere Distanzmetriken in Ihrem KNN-Klassifikator zu verwenden.


