
Einführung
Willkommen zu Ihrem ersten Lab zu scikit-learn! Scikit-learn ist eine der beliebtesten und leistungsfähigsten Open-Source-Bibliotheken für maschinelles Lernen in Python. Sie bietet eine breite Palette von Werkzeugen für Data Mining und Datenanalyse, die auf NumPy, SciPy und matplotlib aufbauen.
Bevor Sie mit diesem Kurs beginnen, sollten Sie über grundlegende Python-Programmierkenntnisse verfügen und sicherstellen, dass Python korrekt in Ihrem System-PATH konfiguriert ist. Wenn Sie Python noch nicht gelernt haben, können Sie mit unserem Python Learning Path beginnen. Zusätzlich sollten Sie NumPy und Pandas installiert haben, da diese wesentliche Voraussetzungen für scikit-learn-Operationen sind. Wenn Sie diese Bibliotheken lernen müssen, können Sie unseren NumPy Learning Path und Pandas Learning Path erkunden.
In diesem Lab lernen Sie die grundlegenden Schritte, um mit scikit-learn in der LabEx-Umgebung zu beginnen. Wir werden die Installation überprüfen, Module importieren und einen der integrierten Datensätze von scikit-learn laden. Dies bestätigt, dass Ihre Umgebung für zukünftige Machine-Learning-Experimente korrekt konfiguriert ist.
Installieren Sie scikit-learn mit pip install scikit-learn
In diesem Schritt besprechen wir, wie die scikit-learn-Bibliothek installiert wird. In einer typischen Python-Umgebung auf Ihrem lokalen Rechner würden Sie pip, den Paketinstaller für Python, verwenden, um neue Bibliotheken zu installieren. Der Befehl zur Installation von scikit-learn lautet:
pip install scikit-learn
Um Ihre Lernerfahrung zu erleichtern, wird die LabEx-Umgebung jedoch mit vorinstalliertem scikit-learn und seinen Abhängigkeiten geliefert. Daher müssen Sie den Installationsbefehl hier nicht ausführen. Wir zeigen ihn zu Ihrer Information, damit Sie wissen, wie Sie scikit-learn auf Ihrem eigenen Computer einrichten können.
Fahren wir mit dem nächsten Schritt fort, um mit der Verwendung der Bibliothek zu beginnen.
Importieren Sie scikit-learn mit from sklearn import datasets
In diesem Schritt schreiben Sie Ihre erste Zeile Python-Code, um mit der scikit-learn-Bibliothek zu interagieren. Bevor Sie Funktionen oder Objekte aus einer Bibliothek in Python verwenden können, müssen Sie diese zuerst in Ihr Skript importieren.
Scikit-learn enthält ein Modul namens datasets, das Dienstprogramme zum Laden und Abrufen beliebter Referenzdatensätze enthält. Wir werden dieses Modul importieren, um es in einem späteren Schritt zu verwenden.
Suchen Sie zuerst die Datei main.py im Dateiexplorer auf der linken Seite Ihrer WebIDE. Klicken Sie darauf, um sie im Editor zu öffnen. Fügen Sie nun die folgende Codezeile zur Datei main.py hinzu:
from sklearn import datasets
Diese Zeile weist Python an, die Bibliothek sklearn zu finden und das Modul datasets daraus zu importieren, wodurch dessen Funktionen für uns nutzbar werden. Speichern Sie die Datei, nachdem Sie den Code hinzugefügt haben. In den kommenden Schritten werden wir weiteren Code hinzufügen und das Skript ausführen.
Überprüfen Sie die Installation mit sklearn.version
In diesem Schritt überprüfen wir, ob scikit-learn ordnungsgemäß installiert und zugänglich ist, indem wir seine Versionsnummer abfragen. Dies ist eine gängige Praxis, um sicherzustellen, dass eine Bibliothek in Ihrer Umgebung korrekt eingerichtet ist. Jede scikit-learn-Installation verfügt über ein spezielles Attribut __version__, das diese Informationen enthält.
Fügen wir unserem main.py-Datei Code hinzu, um die Version auszugeben. Wir müssen auch das Top-Level-Paket sklearn selbst importieren. Ändern Sie Ihre main.py-Datei wie folgt:
import sklearn
from sklearn import datasets
print(sklearn.__version__)
Lassen Sie uns nun dieses Skript ausführen. Öffnen Sie ein Terminal in Ihrer WebIDE (normalerweise finden Sie ein +-Symbol oder ein Menü "Terminal"). Führen Sie im Terminal, das sich im Verzeichnis /home/labex/project öffnen sollte, den folgenden Befehl aus:
python3 main.py
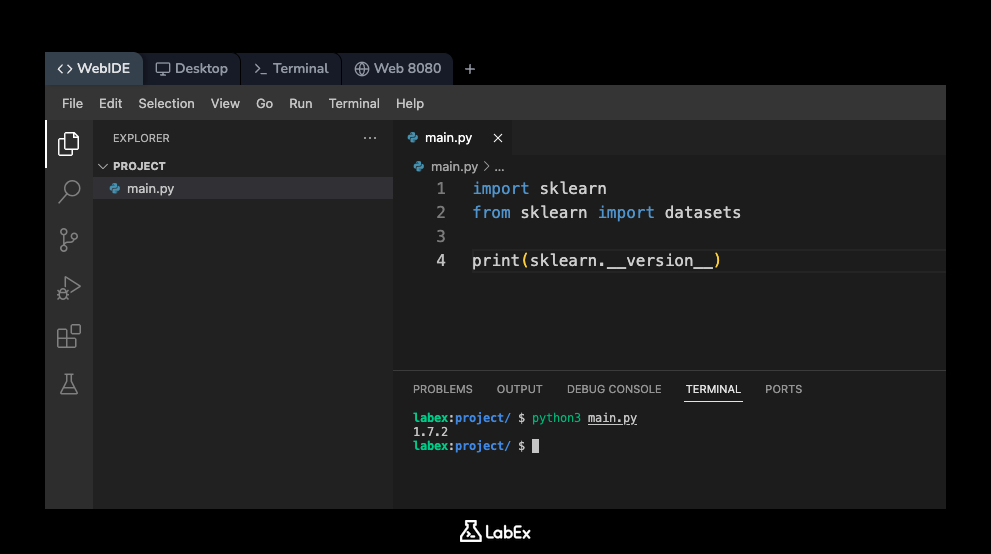
Sie sollten die installierte Version von scikit-learn auf der Konsole ausgegeben sehen. Die Ausgabe wird in etwa so aussehen (die genaue Versionsnummer kann variieren):
1.x.x
Dies bestätigt, dass Python die scikit-learn-Bibliothek erfolgreich importieren und verwenden kann.
Laden Sie den Beispieldatensatz mit datasets.load_iris()
In diesem Schritt verwenden wir das zuvor importierte datasets-Modul, um einen Beispiel-Datensatz zu laden. Scikit-learn enthält mehrere kleine, Standard-Datensätze, die nicht von einer externen Website heruntergeladen werden müssen. Diese sind nützlich für den Einstieg und das Testen von Algorithmen.
Wir werden den Iris-Datensatz laden, einen klassischen und sehr berühmten Datensatz im Bereich des maschinellen Lernens. Er enthält Messungen von 150 Irisblumen aus drei verschiedenen Arten.
Um ihn zu laden, verwenden wir die Funktion datasets.load_iris(). Modifizieren wir die Datei main.py, um den Datensatz zu laden und ihn in einer Variablen namens iris zu speichern. Wir fügen auch eine Print-Anweisung hinzu, um zu bestätigen, dass der Datensatz geladen wurde.
Aktualisieren Sie Ihre main.py-Datei mit folgendem Inhalt:
import sklearn
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
print("Iris dataset loaded successfully.")
Vorschlag: Sie können den obigen Code in Ihren Code-Editor kopieren und dann jede Codezeile sorgfältig lesen, um ihre Funktion zu verstehen. Wenn Sie weitere Erklärungen benötigen, können Sie auf die Schaltfläche "Code erklären" 👆 klicken. Sie können mit Labby für personalisierte Hilfe interagieren.
Speichern Sie die Datei und führen Sie sie erneut im Terminal aus:
python3 main.py
Die Ausgabe sollte nun lauten:
Iris dataset loaded successfully.
Dies zeigt an, dass die Funktion load_iris() ohne Fehler ausgeführt wurde und der Datensatz nun in der Variablen iris in unserem Skript verfügbar ist.
Geben Sie die Datensatzschlüssel mit print(iris.keys()) aus
In diesem Schritt werden wir die Struktur des gerade geladenen Iris-Datensatzes untersuchen. Das von load_iris() zurückgegebene Objekt ist ein Bunch-Objekt, das einer Python-Dictionary ähnelt. Es enthält Schlüssel und Werte, die den Datensatz beschreiben.
Um zu sehen, welche Informationen verfügbar sind, können wir seine Schlüssel mit der Methode .keys() ausgeben. Dies zeigt uns alle Komponenten des Datensatzes, wie die Daten selbst, die Ziel-Labels und beschreibende Namen.
Modifizieren Sie Ihre main.py-Datei, um die Schlüssel des iris-Objekts auszugeben. Ihr endgültiges Skript sollte wie folgt aussehen:
import sklearn
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Print the keys of the dataset
print(iris.keys())
Speichern Sie die Datei und führen Sie sie ein letztes Mal im Terminal aus:
python3 main.py
Die Ausgabe zeigt die verschiedenen Teile des Datensatzobjekts:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
Hier ist eine kurze Aufschlüsselung der wichtigsten Schlüssel:
data: Das Array, das die Feature-Daten (die Blumenmessungen) enthält.target: Das Array, das die Labels (die Arten jeder Blume) enthält.feature_names: Die Namen der Features (z. B. 'sepal length (cm)').target_names: Die Namen der Zielarten (z. B. 'setosa').DESCR: Eine vollständige Beschreibung des Datensatzes.
Durch die Ausgabe dieser Schlüssel haben Sie erfolgreich einen Datensatz geladen und inspiziert und damit den grundlegenden Einrichtungsprozess abgeschlossen.
Zusammenfassung
Herzlichen Glückwunsch! Sie haben dieses einführende Lab zur Einrichtung und Überprüfung Ihrer scikit-learn-Umgebung erfolgreich abgeschlossen.
In diesem Lab haben Sie gelernt, wie Sie:
- Den Installationsprozess für scikit-learn verstehen.
- Die Version der Bibliothek überprüfen, um eine erfolgreiche Einrichtung zu bestätigen.
- Module aus der scikit-learn-Bibliothek importieren.
- Einen integrierten Beispieldatensatz, den Iris-Datensatz, laden.
- Die grundlegende Struktur eines scikit-learn-Datensatzobjekts inspizieren.
Sie sind nun bereit, mit spannenderen Labs fortzufahren, in denen Sie Datenvorverarbeitung, Modelltraining und -bewertung mit den leistungsstarken Werkzeugen von scikit-learn erkunden werden.


