
Einführung
In diesem Lab erhalten Sie praktische Erfahrung in der Aufgabenplanung auf RHEL-Systemen mit verschiedenen Werkzeugen. Sie lernen, einmalige Jobs mit dem Befehl at zu planen, wiederkehrende, benutzerspezifische Aufgaben mit crontab zu verwalten und systemweite, wiederkehrende Jobs mit Cron-Verzeichnissen zu konfigurieren.
Darüber hinaus behandelt dieses Lab fortgeschrittene Planungs-Techniken mit systemd Timern für eine robustere und flexiblere Aufgabenautomatisierung und zeigt, wie Sie temporäre Dateien effizient mit systemd-tmpfiles verwalten. Am Ende dieses Labs werden Sie in der Lage sein, die geeignete Planungsmethode für verschiedene Szenarien auszuwählen und automatisierte Aufgaben in einer RHEL-Umgebung effektiv zu verwalten.
Einen einmaligen Job mit 'at' planen
In diesem Schritt lernen Sie, wie Sie einen Job mit dem Befehl at einmalig zu einem zukünftigen Zeitpunkt planen. Der Befehl at ist nützlich für die Ausführung von Befehlen, die nicht wiederholt ausgeführt werden müssen. Wir werden einen einfachen Job planen, seine Details überprüfen und ihn dann entfernen.
In diesem Lab arbeiten wir direkt auf dem lokalen System, um die Aufgabenplanung zu erlernen. Alle Befehle werden in Ihrer aktuellen Terminalumgebung ausgeführt.
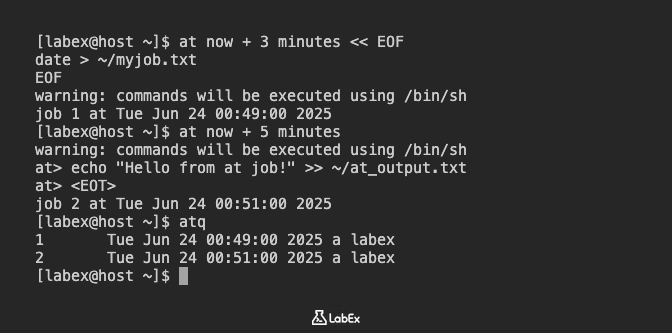
Planen wir einen Job, der das aktuelle Datum und die aktuelle Uhrzeit in eine Datei namens ~/myjob.txt in Ihrem Home-Verzeichnis schreibt. Wir planen ihn für die Ausführung in 3 Minuten:
at now + 3 minutes << EOF
date > ~/myjob.txt
EOF
Die Meldung warning: commands will be executed using /bin/sh ist normal. Die Ausgabe job N at ... zeigt die Job-Nummer und die geplante Ausführungszeit an. Notieren Sie sich die Job-Nummer, da Sie sie später benötigen werden.
Als Nächstes planen wir einen weiteren Job interaktiv. Diese Methode ist nützlich für die Eingabe mehrerer Befehle oder komplexerer Skripte. Wir planen einen Job, der "Hello from at job!" an ~/at_output.txt anhängt, in 5 Minuten:
at now + 5 minutes
Nachdem Sie den Befehl eingegeben und Enter gedrückt haben, sehen Sie eine at> Eingabeaufforderung. Geben Sie Ihren Befehl ein und drücken Sie dann Ctrl+d, um zu beenden:
at > echo "Hello from at job!" >> ~/at_output.txt
at > Ctrl+d
Um die Jobs anzuzeigen, die sich derzeit in der at-Warteschlange befinden, verwenden Sie den Befehl atq. Dieser Befehl listet alle ausstehenden at-Jobs für den aktuellen Benutzer auf.
atq
Die Ausgabe zeigt die Job-Nummer, die geplante Zeit, die Warteschlange und den Benutzer an, der ihn geplant hat.
Sie können die Befehle, die ein bestimmter at-Job ausführen wird, mit dem Befehl at -c gefolgt von der Job-Nummer überprüfen. Ersetzen Sie N durch eine der zuvor notierten Job-Nummern.
at -c N
Dieser Befehl zeigt das Shell-Skript an, das at für diesen Job ausführen wird. Sie sollten den Befehl date > ~/myjob.txt oder echo "Hello from at job!" >> ~/at_output.txt in der Ausgabe sehen.
Schließlich verwenden Sie den Befehl atrm gefolgt von der Job-Nummer, um einen geplanten at-Job zu entfernen. Entfernen wir den ersten Job, den wir geplant haben. Ersetzen Sie N durch die Job-Nummer Ihres ersten Jobs.
atrm N
Nachdem Sie den Job entfernt haben, können Sie atq erneut verwenden, um zu überprüfen, ob er nicht mehr in der Warteschlange ist.
atq
Sie sollten nun nur noch den zweiten Job sehen (falls er noch nicht ausgeführt wurde) oder eine leere Warteschlange, wenn beide Jobs entfernt oder ausgeführt wurden.
Damit ist der erste Schritt zur Planung einmaliger Jobs mit dem Befehl at abgeschlossen.
'at'-Jobs verwalten
In diesem Schritt werden wir uns eingehender mit der Verwaltung von at-Jobs befassen, einschließlich der Planung von Jobs mit verschiedenen Warteschlangen und der Überprüfung ihrer Ausführung. Das Verständnis von at-Warteschlangen kann nützlich sein, um Aufgaben zu priorisieren oder verschiedene Arten von einmaligen Jobs zu trennen.
Wir werden weiterhin auf dem lokalen System arbeiten, um fortgeschrittenere at-Jobverwaltungsfunktionen zu erkunden.
Der Befehl at ermöglicht es Ihnen, eine Warteschlange mit der Option -q anzugeben. Warteschlangen sind einzelne Buchstaben von a bis z. Die Warteschlange a ist die Standardwarteschlange, und Jobs in den Warteschlangen a bis z werden mit abnehmender Niceness (Priorität) ausgeführt. Warteschlange a hat die höchste Priorität und Warteschlange z die niedrigste. Warteschlange b ist für Batch-Jobs reserviert.
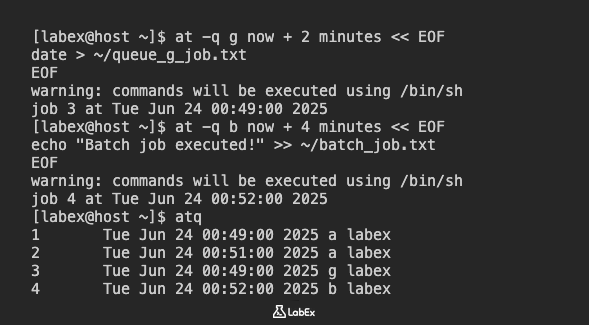
Lassen Sie uns einen Job in Warteschlange g (einer Warteschlange mit niedrigerer Priorität) planen, der in 2 Minuten ausgeführt werden soll. Dieser Job erstellt eine Datei namens ~/queue_g_job.txt mit einem Zeitstempel:
at -q g now + 2 minutes << EOF
date > ~/queue_g_job.txt
EOF
Sie sehen eine Ausgabe ähnlich wie job N at .... Notieren Sie sich diese Jobnummer.
Als Nächstes planen wir einen weiteren Job, diesmal in Warteschlange b (Batch-Warteschlange), die typischerweise für Jobs verwendet wird, die bei geringer Systemauslastung ausgeführt werden können. Dieser Job wird "Batch job executed!" an ~/batch_job.txt anhängen. Wir planen ihn für die Ausführung in 4 Minuten:
at -q b now + 4 minutes << EOF
echo "Batch job executed!" >> ~/batch_job.txt
EOF
Notieren Sie sich erneut die Jobnummer.
Um alle ausstehenden Jobs anzuzeigen, einschließlich derer in verschiedenen Warteschlangen, verwenden Sie atq.
atq
Sie sollten nun beide Jobs aufgelistet sehen, mit ihren jeweiligen Warteschlangenbuchstaben (g und b).
Warten Sie nun, bis Ihre geplanten Jobs ausgeführt werden. Warten Sie mindestens 5 Minuten, damit alle Jobs abgeschlossen werden können. Sie können überprüfen, ob die von Ihren at-Jobs erstellten Dateien vorhanden sind und den erwarteten Inhalt enthalten.
Überprüfen Sie ~/queue_g_job.txt:
cat ~/queue_g_job.txt
Sie sollten eine Datums- und Zeitzeichenfolge sehen.
Überprüfen Sie ~/batch_job.txt:
cat ~/batch_job.txt
Sie sollten "Batch job executed!" sehen.
Wenn die Dateien nicht vorhanden oder leer sind, bedeutet dies möglicherweise, dass die Jobs noch nicht ausgeführt wurden oder es ein Problem mit dem Befehl gab. Sie können atq erneut überprüfen, um zu sehen, ob sie noch ausstehen.
Damit ist der Schritt zur fortgeschrittenen at-Jobverwaltung abgeschlossen. Die verbleibenden at-Jobs werden automatisch bereinigt, wenn der Container zerstört wird.
Wiederkehrende Benutzer-Jobs mit 'crontab' planen
In diesem Schritt lernen Sie, wie Sie wiederkehrende Aufgaben für einen bestimmten Benutzer mit crontab planen. Im Gegensatz zu at-Jobs, die einmal ausgeführt werden, werden cron-Jobs wiederholt in festgelegten Intervallen ausgeführt. Dies ist ideal für routinemäßige Wartungsarbeiten, Datensicherungen oder die Erstellung von Berichten.
Wir werden weiterhin auf dem lokalen System arbeiten, um die Verwaltung von Benutzer-Crontabs zu erlernen.
Der Befehl crontab ermöglicht es Benutzern, ihre eigenen cron-Jobs zu erstellen, zu bearbeiten und anzuzeigen. Jeder Benutzer hat seine eigene crontab-Datei.
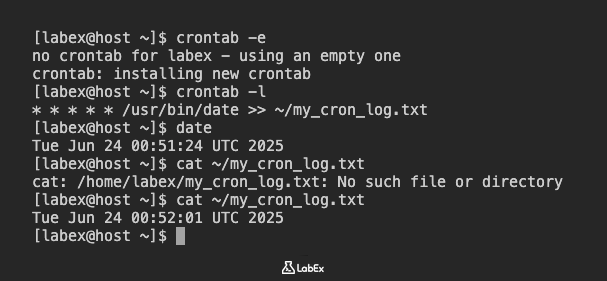
Um Ihre crontab-Datei zu bearbeiten, verwenden Sie den Befehl crontab -e. Dieser öffnet Ihre crontab-Datei im Standard-Texteditor (normalerweise vim).
crontab -e
Anweisungen für den Vim-Editor:
- Drücken Sie
i, um in den Einfügemodus zu gelangen (unten sehen Sie-- INSERT --). - Verwenden Sie die Pfeiltasten zur Navigation.
- Zum Speichern und Beenden: Drücken Sie
Esc, um den Einfügemodus zu verlassen, geben Sie dann:wqein und drücken SieEnter. - Zum Beenden ohne Speichern: Drücken Sie
Esc, geben Sie dann:q!ein und drücken SieEnter.
Innerhalb des Editors fügen Sie eine neue Zeile hinzu, um Ihren cron-Job zu definieren. Ein cron-Eintrag besteht aus fünf Zeit- und Datumsfeldern, gefolgt vom auszuführenden Befehl. Die Felder sind:
- Minute (0-59)
- Stunde (0-23)
- Tag des Monats (1-31)
- Monat (1-12)
- Tag der Woche (0-7, wobei 0 oder 7 Sonntag ist)
Sie können * als Platzhalter verwenden, um "jedes" für ein Feld zu bedeuten, oder /, um Schrittwerte anzugeben (z. B. */5 für alle 5 Minuten).
Lassen Sie uns einen Job planen, der die aktuelle Datum und Uhrzeit jede Minute an eine Datei namens ~/my_cron_log.txt anhängt. Dies ermöglicht es uns, den cron-Job schnell in Aktion zu beobachten.
Befolgen Sie diese Schritte in Vim:
- Drücken Sie
i, um in den Einfügemodus zu gelangen. - Fügen Sie die folgende Zeile zur
crontab-Datei hinzu:
* * * * * /usr/bin/date >> ~/my_cron_log.txt
- Drücken Sie
Esc, um den Einfügemodus zu verlassen. - Geben Sie
:wqein und drücken SieEnter, um zu speichern und zu beenden.
Sie sollten eine Meldung sehen, die anzeigt, dass eine neue crontab installiert wurde:
crontab: installing new crontab
Um zu überprüfen, ob Ihr cron-Job erfolgreich hinzugefügt wurde, können Sie Ihre crontab-Einträge mit dem Befehl crontab -l auflisten:
crontab -l
Sie sollten die gerade hinzugefügte Zeile sehen:
* * * * * /usr/bin/date >> ~/my_cron_log.txt
Warten Sie nun ein oder zwei Minuten, damit der cron-Job mindestens einmal ausgeführt werden kann. Sie können die aktuelle Uhrzeit überprüfen, um zu sehen, wann die nächste volle Minute erreicht wird:
date
Nachdem Sie mindestens zwei Minuten gewartet haben, damit der Cron-Job ein paar Mal ausgeführt werden kann, überprüfen Sie den Inhalt der Datei ~/my_cron_log.txt.
cat ~/my_cron_log.txt
Sie sollten eine oder mehrere Zeilen sehen, die jeweils ein Datum und eine Uhrzeit enthalten, was darauf hinweist, dass Ihr cron-Job ausgeführt wurde.
Mon Apr 8 10:30:01 AM EDT 2024
Mon Apr 8 10:31:01 AM EDT 2024
Damit ist der Schritt zur Verwaltung von Benutzer-Crontabs abgeschlossen. Der Cron-Job wird weiter ausgeführt, bis der Container zerstört wird.
Benutzer-'crontab'-Einträge verwalten
In diesem Schritt lernen Sie fortgeschrittenere Techniken zur Verwaltung von Benutzer-crontab-Einträgen kennen, einschließlich der Bearbeitung bestehender Jobs, des Hinzufügens mehrerer Jobs und des Verständnisses spezieller cron-Strings. Eine effektive crontab-Verwaltung ist entscheidend für die Automatisierung routinemäßiger Aufgaben.
Wir werden weiterhin auf dem lokalen System arbeiten, um fortgeschrittene Crontab-Verwaltungstechniken zu erkunden.
Beginnen wir damit, einen neuen cron-Job hinzuzufügen. Dieser Job hängt alle zwei Minuten "Hello from cron!" an ~/cron_messages.txt an.
Öffnen Sie Ihre crontab zur Bearbeitung:
crontab -e
In vim:
- Drücken Sie
i, um den Einfügemodus aufzurufen - Fügen Sie die folgende Zeile zur
crontab-Datei hinzu:
*/2 * * * * echo "Hello from cron!" >> ~/cron_messages.txt
- Drücken Sie
Esc, um den Einfügemodus zu verlassen - Geben Sie
:wqein und drücken Sie die Eingabetaste, um zu speichern und zu beenden
Überprüfen Sie, ob der Eintrag hinzugefügt wurde:
crontab -l
Sie sollten die neu hinzugefügte Zeile sehen.
Fügen wir nun einen weiteren cron-Job hinzu, der täglich um 08:00 Uhr morgens ausgeführt wird. Dieser Job zeichnet die Festplattennutzung Ihres Home-Verzeichnisses in ~/disk_usage.log auf.
Öffnen Sie Ihre crontab erneut zur Bearbeitung:
crontab -e
In vim:
- Drücken Sie
i, um den Einfügemodus aufzurufen - Fügen Sie die folgende Zeile unter der vorherigen hinzu:
0 8 * * * du -sh ~ >> ~/disk_usage.log
- Drücken Sie
Esc, um den Einfügemodus zu verlassen - Geben Sie
:wqein und drücken Sie die Eingabetaste, um zu speichern und zu beenden
Überprüfen Sie, ob beide Einträge vorhanden sind:
crontab -l
Sie sollten jetzt beide cron-Jobs aufgelistet sehen.
cron unterstützt auch spezielle Strings, die gängige Zeitpläne vereinfachen können. Dazu gehören @reboot, @yearly, @annually, @monthly, @weekly, @daily, @midnight und @hourly. Zum Beispiel ist @hourly äquivalent zu 0 * * * *.
Fügen wir einen Job hinzu, der stündlich ausgeführt wird und die System-Uptime in ~/uptime_log.txt aufzeichnet.
Öffnen Sie Ihre crontab zur Bearbeitung:
crontab -e
In vim:
- Drücken Sie
i, um den Einfügemodus aufzurufen - Fügen Sie die folgende Zeile hinzu:
@hourly uptime >> ~/uptime_log.txt
- Drücken Sie
Esc, um den Einfügemodus zu verlassen - Geben Sie
:wqein und drücken Sie die Eingabetaste, um zu speichern und zu beenden
Überprüfen Sie alle drei Einträge:
crontab -l
Sie sollten jetzt alle drei cron-Jobs sehen.
Um die Wirkung dieser Jobs zu demonstrieren, warten wir eine kurze Zeit. Da die Jobs in unterschiedlichen Intervallen geplant sind, werden wir nicht alle sofort ausführen sehen, aber wir können die Einrichtung überprüfen.
Warten Sie mindestens 3 Minuten, damit der */2-Job mindestens einmal ausgeführt wird.
Überprüfen Sie die Datei ~/cron_messages.txt:
cat ~/cron_messages.txt
Sie sollten mindestens eine "Hello from cron!"-Nachricht sehen.
Hello from cron!
Die Dateien ~/disk_usage.log und ~/uptime_log.txt werden möglicherweise noch nicht erstellt, abhängig von der aktuellen Uhrzeit, da sie für die tägliche bzw. stündliche Ausführung geplant sind. Der wichtige Teil ist, dass ihre Einträge in Ihrer crontab korrekt konfiguriert sind.
Dies schließt den Schritt der Benutzer-Crontab-Verwaltung ab. Alle Cron-Jobs werden weiterhin ausgeführt, bis der Container zerstört wird.
Wiederkehrende System-Jobs mit Cron-Verzeichnissen planen
In diesem Schritt lernen Sie, wie Sie wiederkehrende systemweite Aufgaben mithilfe von cron-Verzeichnissen planen. Im Gegensatz zu Benutzer-crontab-Einträgen, die benutzerspezifisch sind, werden System-cron-Jobs vom Root-Benutzer verwaltet und wirken sich auf das gesamte System aus. Diese werden typischerweise für die Systemwartung, Protokollrotation und andere administrative Aufgaben verwendet.
Wir werden weiterhin auf dem lokalen System arbeiten, um die systemweite Cron-Job-Konfiguration zu erkunden.
Systemweite cron-Jobs werden in /etc/crontab definiert oder durch Platzieren von Skripten in bestimmten Verzeichnissen:
/etc/cron.hourly/: Skripte in diesem Verzeichnis werden einmal pro Stunde ausgeführt./etc/cron.daily/: Skripte in diesem Verzeichnis werden einmal täglich ausgeführt./etc/cron.weekly/: Skripte in diesem Verzeichnis werden einmal pro Woche ausgeführt./etc/cron.monthly/: Skripte in diesem Verzeichnis werden einmal pro Monat ausgeführt.
Diese Verzeichnisse werden vom Dienstprogramm run-parts verarbeitet, das alle ausführbaren Dateien darin ausführt.
Um System-cron-Jobs zu verwalten, benötigen Sie Root-Rechte. Da der LabEx-Benutzer sudo-Zugriff hat, können wir sudo für die erforderlichen Befehle verwenden.
Lassen Sie uns ein einfaches Skript erstellen, das eine Nachricht in das Systemprotokoll schreibt. Wir werden dieses Skript in /etc/cron.hourly/ platzieren, damit es stündlich ausgeführt wird.
Erstellen Sie zuerst die Skriptdatei /etc/cron.hourly/my_hourly_script:
sudo nano /etc/cron.hourly/my_hourly_script
Fügen Sie den folgenden Inhalt zur Datei hinzu:
#!/bin/bash
logger "Hourly cron job executed at $(date)"
Speichern und beenden Sie den Editor (Ctrl+o, Enter, Ctrl+x in nano).
Als Nächstes müssen Sie das Skript ausführbar machen. Ohne Ausführungsberechtigungen ignoriert run-parts es.
sudo chmod +x /etc/cron.hourly/my_hourly_script
Überprüfen wir nun, ob das Skript ausführbar ist:
ls -l /etc/cron.hourly/my_hourly_script
Sie sollten ein x in den Berechtigungen sehen, z. B.: -rwxr-xr-x.
Da cron.hourly-Jobs einmal pro Stunde ausgeführt werden, können wir in diesem Lab nicht eine volle Stunde warten, um die Ausführung zu überprüfen. Wir können jedoch den Befehl run-parts für das stündliche Verzeichnis manuell auslösen, um die Ausführung zu simulieren.
sudo run-parts /etc/cron.hourly/
Dieser Befehl führt alle ausführbaren Skripte in /etc/cron.hourly/ aus. Das von uns erstellte Skript verwendet den Befehl logger, um Nachrichten in das Systemprotokoll zu schreiben. Obwohl wir die Protokollausgabe in dieser Containerumgebung nicht einfach überprüfen können, ist das wichtige Lernziel das Verständnis, wie man Skripte in den Cron-Verzeichnissen erstellt und verwaltet.
In einem realen RHEL-System könnten Sie die Systemprotokolle mit journalctl oder /var/log/messages überprüfen, um zu verifizieren, dass das Skript erfolgreich ausgeführt wurde.
Dies schließt den Schritt der System-Cron-Job-Verwaltung ab. Das Skript verbleibt an seinem Platz und würde in einer realen Systemumgebung stündlich ausgeführt werden.
Systemd-Timer für wiederkehrende Aufgaben konfigurieren
In diesem Schritt lernen Sie systemd-Timer kennen, eine moderne Alternative zu cron für die Planung von Aufgaben auf Linux-Systemen. systemd-Timer bieten mehr Flexibilität und eine bessere Integration in das systemd-Ökosystem. Während systemctl-Befehle typischerweise zur Verwaltung von systemd-Units verwendet werden, konzentrieren wir uns aufgrund der Docker-Containerumgebung auf das direkte Erstellen und Überprüfen der Timer- und Service-Unit-Dateien.
systemd-Timer arbeiten in Verbindung mit systemd-Service-Units. Eine Timer-Unit (.timer-Datei) definiert, wann eine Aufgabe ausgeführt werden soll, und eine Service-Unit (.service-Datei) definiert, welche Aufgabe ausgeführt werden soll.
Wir werden weiterhin auf dem lokalen System arbeiten, um die Konfiguration von systemd-Timern zu erkunden.
Sie benötigen Root-Rechte, um systemd-Unit-Dateien in Systemverzeichnissen zu erstellen. Da der LabEx-Benutzer sudo-Zugriff hat, können wir sudo für die erforderlichen Befehle verwenden.
Lassen Sie uns einen einfachen Service erstellen, der eine Nachricht in eine Datei protokolliert. Wir werden diese Service-Unit-Datei in /etc/systemd/system/ platzieren, wo benutzerdefinierte Service-Units typischerweise gespeichert werden.
Erstellen Sie die Service-Unit-Datei /etc/systemd/system/my-custom-task.service:
sudo nano /etc/systemd/system/my-custom-task.service
Fügen Sie den folgenden Inhalt zur Datei hinzu:
[Unit]
Description=My Custom Scheduled Task
[Service]
Type=oneshot
ExecStart=/bin/bash -c 'echo "My custom task executed at $(date)" >> /var/log/my-custom-task.log'
Speichern und beenden Sie den Editor (Ctrl+o, Enter, Ctrl+x in nano).
Erstellen Sie als Nächstes die Timer-Unit-Datei /etc/systemd/system/my-custom-task.timer. Dieser Timer aktiviert unseren Service alle 5 Minuten.
sudo nano /etc/systemd/system/my-custom-task.timer
Fügen Sie den folgenden Inhalt zur Datei hinzu:
[Unit]
Description=Run My Custom Scheduled Task every 5 minutes
[Timer]
Persistent=true
[Install]
WantedBy=timers.target
Speichern und beenden Sie den Editor.
Erläuterung von OnCalendar:
*:0/5bedeutet "alle 5 Minuten".*für Jahr, Monat, Tag, Stunde (beliebiger Wert).0/5für Minute, d. h. beginnend bei Minute 0, alle 5 Minuten (0, 5, 10, ..., 55).
In einer typischen systemd-Umgebung würden Sie jetzt systemctl daemon-reload ausführen, um systemd über die neuen Unit-Dateien zu informieren, und dann systemctl enable --now my-custom-task.timer, um den Timer zu starten. Aufgrund von Docker-Container-Einschränkungen ist systemctl jedoch nicht voll funktionsfähig.
Stattdessen werden wir die Erstellung der Dateien manuell überprüfen. Der systemd-Daemon im Container könnte diese Dateien irgendwann abrufen, aber wir können seine Timerausführung in diesem Lab-Setup nicht direkt steuern oder beobachten. Das Hauptziel hier ist es, zu verstehen, wie man diese Dateien konfiguriert.
Überprüfen wir die Existenz der erstellten Dateien:
ls -l /etc/systemd/system/my-custom-task.service
ls -l /etc/systemd/system/my-custom-task.timer
Sie sollten eine Ausgabe sehen, die anzeigt, dass beide Dateien existieren.
Um die Ausführung des Service zu simulieren, können Sie den in ExecStart definierten Befehl manuell ausführen:
sudo /bin/bash -c 'echo "My custom task executed at $(date)" >> /var/log/my-custom-task.log'
Überprüfen Sie nun die Protokolldatei, um die Ausgabe zu sehen:
sudo cat /var/log/my-custom-task.log
Sie sollten die soeben protokollierte Nachricht sehen:
My custom task executed at Tue Jun 10 06:54:40 UTC 2025
Dies schließt den Schritt der systemd-Timer-Konfiguration ab. Die Service- und Timer-Unit-Dateien verbleiben zur Referenz an ihrem Platz.
Temporäre Dateien mit systemd-tmpfiles verwalten
In diesem Schritt lernen Sie, wie Sie temporäre Dateien und Verzeichnisse mit systemd-tmpfiles verwalten. Dieses Dienstprogramm ist Teil von systemd und ist für das Erstellen, Löschen und Bereinigen von flüchtigen und temporären Dateien und Verzeichnissen zuständig. Es wird häufig verwendet, um /tmp, /var/tmp und andere temporäre Speicherorte zu verwalten und sicherzustellen, dass alte Dateien regelmäßig entfernt werden.
Wir werden weiterhin auf dem lokalen System arbeiten, um die Konfiguration von systemd-tmpfiles zu erkunden.
Sie benötigen Root-Rechte, um systemd-tmpfiles zu konfigurieren. Da der LabEx-Benutzer sudo-Zugriff hat, können wir sudo für die erforderlichen Befehle verwenden.
systemd-tmpfiles liest Konfigurationsdateien aus /etc/tmpfiles.d/ und /usr/lib/tmpfiles.d/. Diese Dateien definieren Regeln für das Erstellen, Löschen und Verwalten von Dateien und Verzeichnissen.
Lassen Sie uns eine benutzerdefinierte Konfigurationsdatei erstellen, um ein neues temporäres Verzeichnis zu verwalten. Wir erstellen ein Verzeichnis /run/my_temp_dir und konfigurieren systemd-tmpfiles, um Dateien, die älter als 1 Minute sind, daraus zu bereinigen.
Erstellen Sie die Konfigurationsdatei /etc/tmpfiles.d/my_temp_dir.conf:
sudo nano /etc/tmpfiles.d/my_temp_dir.conf
Fügen Sie den folgenden Inhalt zur Datei hinzu:
d /run/my_temp_dir 0755 labex labex 1m
Erläuterung der Zeile:
d: Gibt an, dass dieser Eintrag ein Verzeichnis definiert./run/my_temp_dir: Der Pfad zum Verzeichnis.0755: Die Berechtigungen für das Verzeichnis.labex labex: Der Eigentümer und die Gruppe für das Verzeichnis.1m: Das Alter, nach dem Dateien in diesem Verzeichnis gelöscht werden sollen (1 Minute).
Speichern und beenden Sie den Editor (Ctrl+o, Enter, Ctrl+x in nano).
Nun, lassen Sie uns systemd-tmpfiles anweisen, diese Konfiguration anzuwenden. Die Option --create erstellt das Verzeichnis, falls es nicht existiert.
sudo systemd-tmpfiles --create /etc/tmpfiles.d/my_temp_dir.conf
Überprüfen Sie, ob das Verzeichnis mit den korrekten Berechtigungen und dem korrekten Eigentümer erstellt wurde:
ls -ld /run/my_temp_dir
Sie sollten eine Ausgabe ähnlich der folgenden sehen:
drwxr-xr-x 2 labex labex 6 Jun 10 06:55 /run/my_temp_dir
Als Nächstes erstellen wir eine Testdatei in diesem neuen temporären Verzeichnis:
sudo touch /run/my_temp_dir/test_file.txt
Überprüfen Sie, ob die Datei existiert:
ls -l /run/my_temp_dir/test_file.txt
Nun müssen wir länger als 1 Minute warten, damit die Datei gemäß unserer Konfiguration "alt" wird. Warten Sie mindestens 70 Sekunden (1 Minute und 10 Sekunden).
Nachdem wir länger als 1 Minute gewartet haben, führen wir systemd-tmpfiles manuell mit der Option --clean aus, um den Bereinigungsprozess basierend auf unserer Konfiguration auszulösen.
sudo systemd-tmpfiles --clean /etc/tmpfiles.d/my_temp_dir.conf
Überprüfen Sie abschließend, ob test_file.txt entfernt wurde:
ls -l /run/my_temp_dir/test_file.txt
Sie sollten einen "No such file or directory"-Fehler erhalten, der anzeigt, dass systemd-tmpfiles die alte Datei erfolgreich bereinigt hat.
Dies schließt den Schritt der systemd-tmpfiles-Konfiguration ab. Die Konfigurationsdatei und das temporäre Verzeichnis verbleiben zur Referenz an ihrem Platz.
Zusammenfassung
In diesem Lab haben Sie gelernt, wie Sie einmalige Aufgaben mit dem Befehl at planen und verwalten, einschließlich der interaktiven und nicht-interaktiven Planung von Jobs, der Anzeige der at-Warteschlange mit atq und dem Löschen ausstehender Jobs mit atrm. Sie haben auch Kenntnisse in der Planung wiederkehrender, benutzerspezifischer Aufgaben mit crontab erworben und gelernt, wie man Cron-Jobs bearbeitet, auflistet und entfernt sowie die Cron-Syntax zum Festlegen von Ausführungszeiten versteht. Darüber hinaus hat das Lab gezeigt, wie man systemweite, wiederkehrende Aufgaben plant, indem man Skripte in Standard-Cron-Verzeichnissen (/etc/cron.hourly, /etc/cron.daily usw.) platziert und wie man benutzerdefinierte Cron-Jobs in /etc/cron.d erstellt.
Schließlich haben Sie die erweiterte Aufgabenplanung mit systemd-Timern erkundet und gelernt, wie man Service- und Timer-Units für wiederkehrende Aufgaben erstellt und aktiviert und wie man temporäre Dateien und Verzeichnisse mit systemd-tmpfiles für die automatische Bereinigung verwaltet. Dieses umfassende Lab bot praktische Erfahrung in der Verwaltung verschiedener Aufgabenplanungsanforderungen auf RHEL-Systemen, von einfachen Einmalbefehlen bis hin zu komplexen, wiederkehrenden Systemprozessen.


