
Einführung
In diesem Lab werden wir die Erstellung von PostgreSQL-Tabellen und Datentypen untersuchen. Ziel ist es, grundlegende Datentypen wie Integer (Ganzzahlen), Text, Datumsangaben und Boolesche Werte zu verstehen, die für die Definition von Tabellenstrukturen und die Sicherstellung der Datenintegrität entscheidend sind.
Wir werden uns mit psql mit der PostgreSQL-Datenbank verbinden, Tabellen mit Primärschlüsseln unter Verwendung von SERIAL erstellen und grundlegende Constraints (Beschränkungen) wie NOT NULL und UNIQUE hinzufügen. Anschließend werden wir die Tabellenstruktur inspizieren und Daten einfügen, um die Verwendung verschiedener Datentypen wie INTEGER, SMALLINT, TEXT, VARCHAR(n) und CHAR(n) zu demonstrieren.
PostgreSQL Datentypen erkunden
In diesem Schritt werden wir einige der grundlegenden Datentypen untersuchen, die in PostgreSQL verfügbar sind. Das Verständnis von Datentypen ist entscheidend für die Definition von Tabellenstrukturen und die Sicherstellung der Datenintegrität. Wir werden gängige Typen wie Integer (Ganzzahlen), Text, Datumsangaben und Boolesche Werte behandeln.
Zuerst verbinden wir uns mit der PostgreSQL-Datenbank. Öffnen Sie ein Terminal und verwenden Sie den Befehl psql, um sich als Benutzer postgres mit der Datenbank postgres zu verbinden. Da der Benutzer postgres der standardmäßige Superuser ist, müssen Sie möglicherweise zuerst sudo verwenden, um zu diesem Benutzer zu wechseln.
sudo -u postgres psql
Sie sollten sich nun im interaktiven PostgreSQL-Terminal befinden. Sie sehen eine Eingabeaufforderung wie postgres=#.
Lassen Sie uns nun einige grundlegende Datentypen erkunden.
1. Integer-Typen (Ganzzahltypen):
PostgreSQL bietet verschiedene Integer-Typen mit unterschiedlichen Bereichen. Die gebräuchlichsten sind INTEGER (oder INT) und SMALLINT.
INTEGER: Eine typische Wahl für die meisten ganzzahligen Werte.SMALLINT: Wird für kleinere ganzzahlige Werte verwendet, um Speicherplatz zu sparen.
Erstellen wir eine einfache Tabelle, um diese Typen zu demonstrieren:
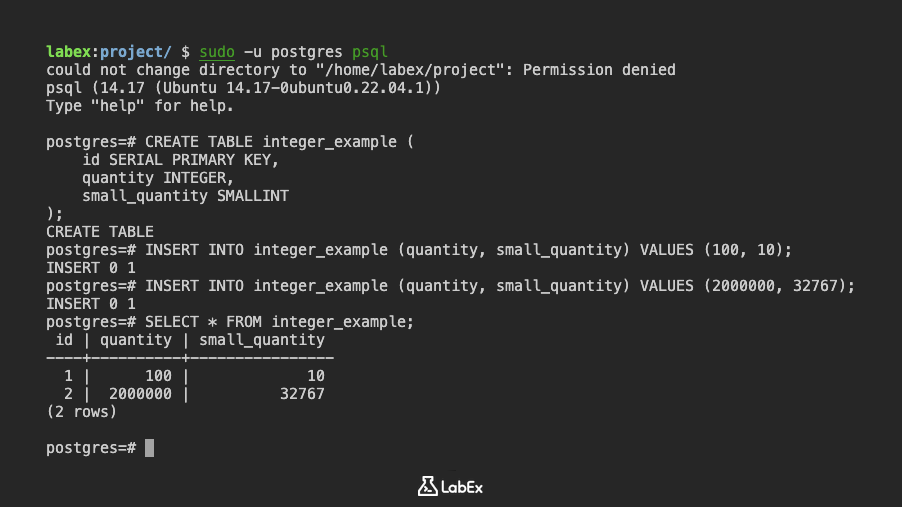
CREATE TABLE integer_example (
id SERIAL PRIMARY KEY,
quantity INTEGER,
small_quantity SMALLINT
);
Hier ist SERIAL ein spezieller Typ, der automatisch eine Folge von ganzen Zahlen generiert und sich daher für Primärschlüssel eignet.
Fügen wir nun einige Daten ein:
INSERT INTO integer_example (quantity, small_quantity) VALUES (100, 10);
INSERT INTO integer_example (quantity, small_quantity) VALUES (2000000, 32767);
Sie können die Daten mit folgendem Befehl anzeigen:
SELECT * FROM integer_example;
Ausgabe:
id | quantity | small_quantity
----+----------+----------------
1 | 100 | 10
2 | 2000000 | 32767
(2 rows)
2. Texttypen:
PostgreSQL bietet TEXT, VARCHAR(n) und CHAR(n) zum Speichern von Text.
TEXT: Speichert Zeichenketten variabler Länge mit unbegrenzter Länge.VARCHAR(n): Speichert Zeichenketten variabler Länge mit einer maximalen Länge vonn.CHAR(n): Speichert Zeichenketten fester Länge der Längen. Wenn die Zeichenkette kürzer ist, wird sie mit Leerzeichen aufgefüllt.
Erstellen wir eine weitere Tabelle:
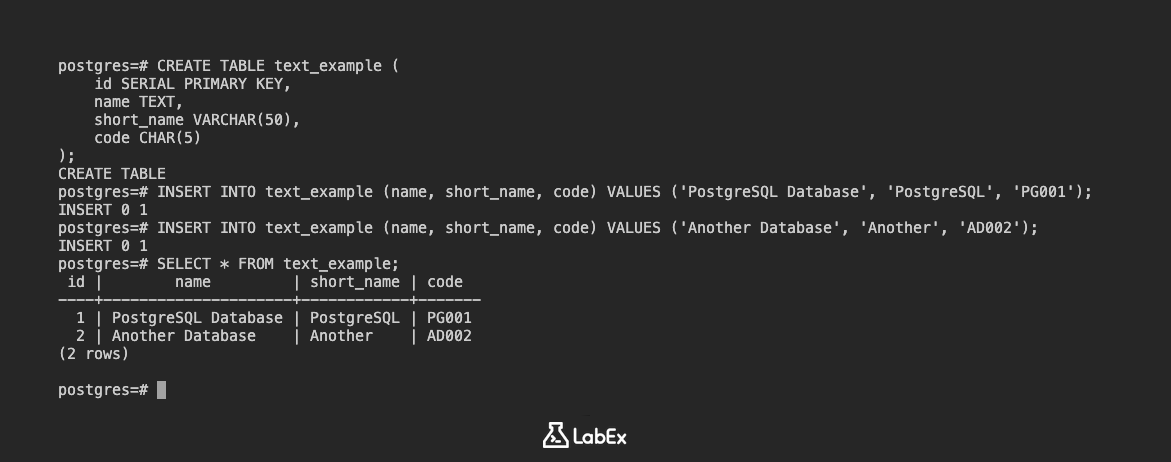
CREATE TABLE text_example (
id SERIAL PRIMARY KEY,
name TEXT,
short_name VARCHAR(50),
code CHAR(5)
);
Fügen Sie einige Daten ein:
INSERT INTO text_example (name, short_name, code) VALUES ('PostgreSQL Database', 'PostgreSQL', 'PG001');
INSERT INTO text_example (name, short_name, code) VALUES ('Another Database', 'Another', 'AD002');
Zeigen Sie die Daten an:
SELECT * FROM text_example;
Ausgabe:
id | name | short_name | code
----+--------------------+------------+-------
1 | PostgreSQL Database | PostgreSQL | PG001
2 | Another Database | Another | AD002
(2 rows)
3. Datums- und Uhrzeittypen:
PostgreSQL bietet DATE, TIME, TIMESTAMP und TIMESTAMPTZ für die Verarbeitung von Datums- und Zeitwerten.
DATE: Speichert nur das Datum (Jahr, Monat, Tag).TIME: Speichert nur die Uhrzeit (Stunde, Minute, Sekunde).TIMESTAMP: Speichert sowohl Datum als auch Uhrzeit ohne Zeitzoneninformationen.TIMESTAMPTZ: Speichert sowohl Datum als auch Uhrzeit mit Zeitzoneninformationen.
Erstellen Sie eine Tabelle:
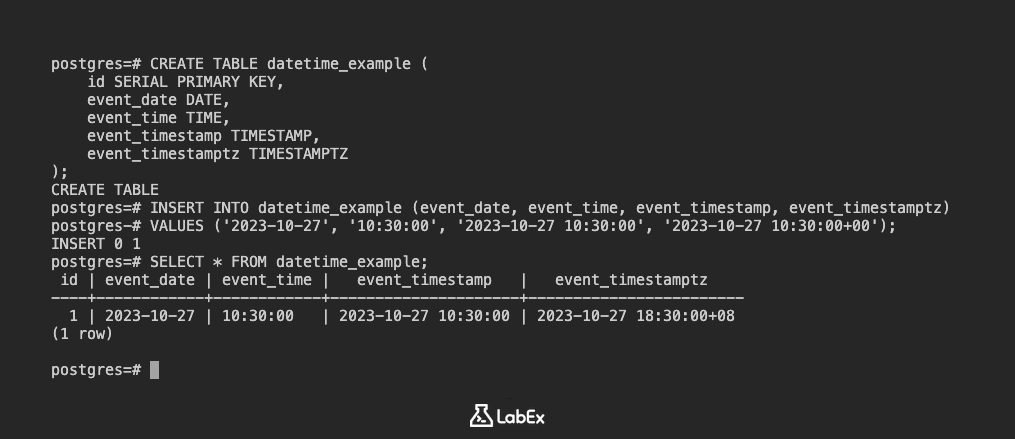
CREATE TABLE datetime_example (
id SERIAL PRIMARY KEY,
event_date DATE,
event_time TIME,
event_timestamp TIMESTAMP,
event_timestamptz TIMESTAMPTZ
);
Daten einfügen:
INSERT INTO datetime_example (event_date, event_time, event_timestamp, event_timestamptz)
VALUES ('2023-10-27', '10:30:00', '2023-10-27 10:30:00', '2023-10-27 10:30:00+00');
Zeigen Sie die Daten an:
SELECT * FROM datetime_example;
Ausgabe:
id | event_date | event_time | event_timestamp | event_timestamptz
----+------------+------------+---------------------+----------------------------
1 | 2023-10-27 | 10:30:00 | 2023-10-27 10:30:00 | 2023-10-27 10:30:00+00
(1 row)
4. Boolean-Typ (Boolescher Typ):
Der Typ BOOLEAN speichert Wahrheitswerte (true/false).
Erstellen Sie eine Tabelle:
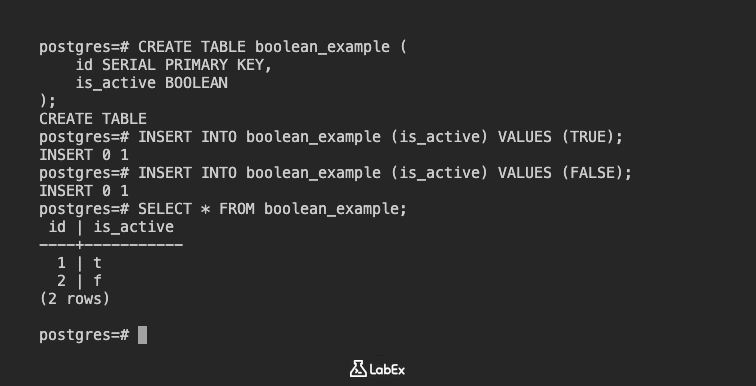
CREATE TABLE boolean_example (
id SERIAL PRIMARY KEY,
is_active BOOLEAN
);
Daten einfügen:
INSERT INTO boolean_example (is_active) VALUES (TRUE);
INSERT INTO boolean_example (is_active) VALUES (FALSE);
Zeigen Sie die Daten an:
SELECT * FROM boolean_example;
Ausgabe:
id | is_active
----+-----------
1 | t
2 | f
(2 rows)
Beenden Sie abschließend das psql-Terminal:
\q
Sie haben nun einige der grundlegenden Datentypen in PostgreSQL erkundet. Diese Datentypen bilden die Bausteine für die Erstellung robuster und wohldefinierter Datenbankschemata.
Tabellen mit Primärschlüsseln erstellen
In diesem Schritt lernen wir, wie man Tabellen mit Primärschlüsseln in PostgreSQL erstellt. Ein Primärschlüssel ist eine Spalte oder eine Menge von Spalten, die jede Zeile in einer Tabelle eindeutig identifiziert. Er erzwingt Eindeutigkeit und dient als entscheidendes Element für die Datenintegrität und die Beziehungen zwischen Tabellen.
Zuerst verbinden wir uns mit der PostgreSQL-Datenbank. Öffnen Sie ein Terminal und verwenden Sie den Befehl psql, um sich als Benutzer postgres mit der Datenbank postgres zu verbinden.
sudo -u postgres psql
Sie sollten sich nun im interaktiven PostgreSQL-Terminal befinden.
Grundlegendes zu Primärschlüsseln
Ein Primärschlüssel hat die folgenden Eigenschaften:
- Er muss eindeutige Werte enthalten.
- Er darf keine
NULL-Werte enthalten. - Eine Tabelle kann nur einen Primärschlüssel haben.
Erstellen einer Tabelle mit einem Primärschlüssel
Es gibt zwei gängige Möglichkeiten, einen Primärschlüssel beim Erstellen einer Tabelle zu definieren:
Verwenden des
PRIMARY KEY-Constraints (Beschränkung) innerhalb der Spaltendefinition:CREATE TABLE products ( product_id SERIAL PRIMARY KEY, product_name VARCHAR(100), price DECIMAL(10, 2) );In diesem Beispiel wird
product_idals Primärschlüssel mithilfe desPRIMARY KEY-Constraints definiert. Das SchlüsselwortSERIALerstellt automatisch eine Sequenz, um eindeutige ganzzahlige Werte für dieproduct_idzu generieren.Verwenden des
PRIMARY KEY-Constraints separat:CREATE TABLE customers ( customer_id INT, first_name VARCHAR(50), last_name VARCHAR(50), PRIMARY KEY (customer_id) );Hier wird der
PRIMARY KEY-Constraint separat definiert und gibt an, dass die Spaltecustomer_idder Primärschlüssel ist.
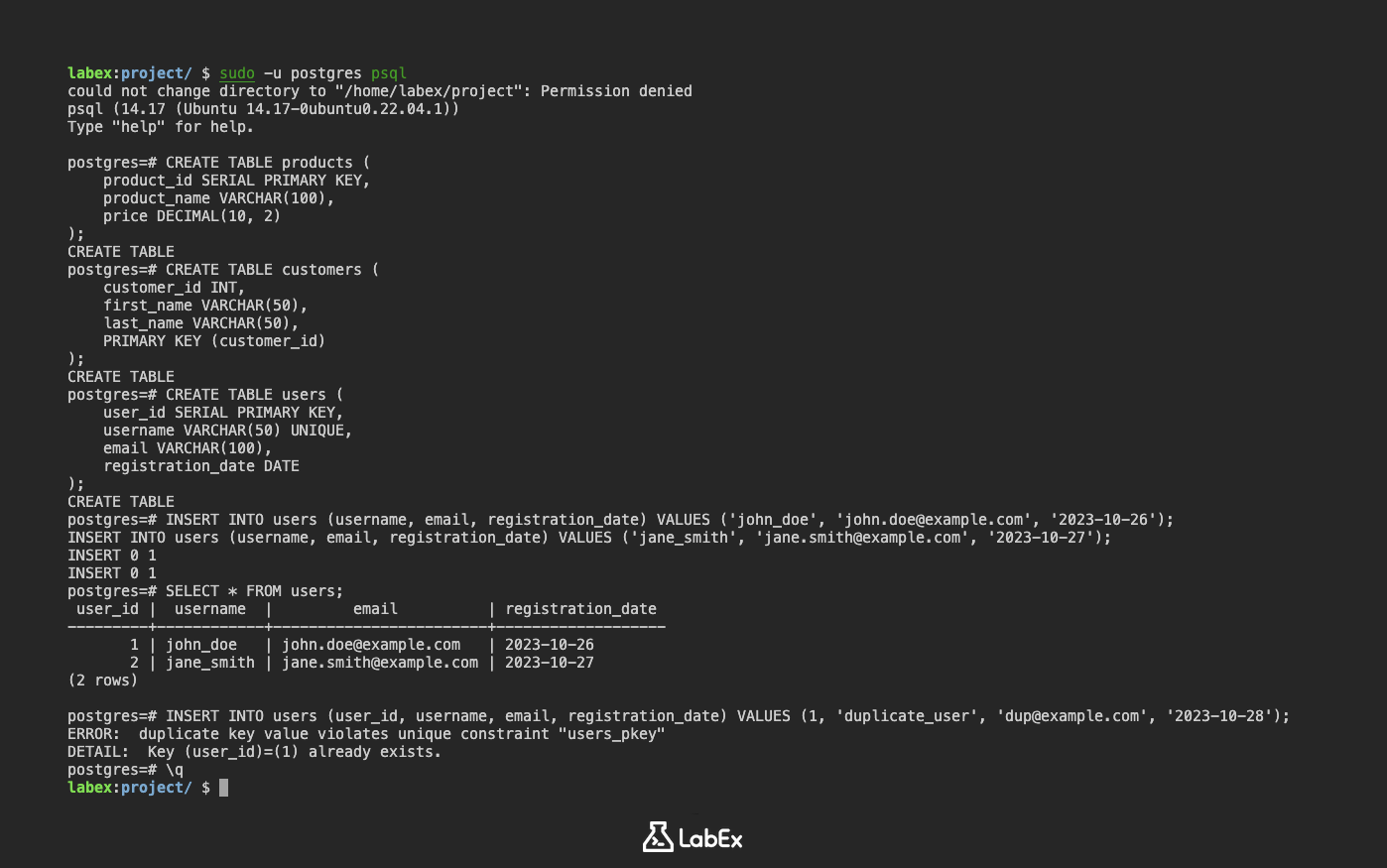
Beispiel: Erstellen einer users-Tabelle mit einem Primärschlüssel
Erstellen wir eine users-Tabelle mit einem Primärschlüssel unter Verwendung des Typs SERIAL für die automatische ID-Generierung:
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE,
email VARCHAR(100),
registration_date DATE
);
In dieser Tabelle:
user_idist der Primärschlüssel, der automatisch mitSERIALgeneriert wird.usernameist ein eindeutiger Benutzername für jeden Benutzer.emailist die E-Mail-Adresse des Benutzers.registration_dateist das Datum, an dem sich der Benutzer registriert hat.
Fügen wir nun einige Daten in die users-Tabelle ein:
INSERT INTO users (username, email, registration_date) VALUES ('john_doe', 'john.doe@example.com', '2023-10-26');
INSERT INTO users (username, email, registration_date) VALUES ('jane_smith', 'jane.smith@example.com', '2023-10-27');
Sie können die Daten mit folgendem Befehl anzeigen:
SELECT * FROM users;
Ausgabe:
user_id | username | email | registration_date
---------+------------+---------------------+---------------------
1 | john_doe | john.doe@example.com | 2023-10-26
2 | jane_smith | jane.smith@example.com | 2023-10-27
(2 rows)
Versuch, einen doppelten Primärschlüssel einzufügen
Wenn Sie versuchen, eine Zeile mit einem doppelten Primärschlüssel einzufügen, gibt PostgreSQL einen Fehler aus:
INSERT INTO users (user_id, username, email, registration_date) VALUES (1, 'duplicate_user', 'dup@example.com', '2023-10-28');
Ausgabe:
ERROR: duplicate key value violates unique constraint "users_pkey"
DETAIL: Key (user_id)=(1) already exists.
Dies demonstriert den PRIMARY KEY-Constraint in Aktion, der doppelte Werte verhindert.
Beenden Sie abschließend das psql-Terminal:
\q
Sie haben nun erfolgreich eine Tabelle mit einem Primärschlüssel erstellt und beobachtet, wie dieser die Eindeutigkeit erzwingt. Dies ist ein grundlegendes Konzept im Datenbankdesign.
Grundlegende Constraints hinzufügen (NOT NULL, UNIQUE)
In diesem Schritt lernen wir, wie man grundlegende Constraints zu Tabellen in PostgreSQL hinzufügt. Constraints (Beschränkungen) sind Regeln, die die Datenintegrität und -konsistenz erzwingen. Wir werden uns auf zwei grundlegende Constraints konzentrieren: NOT NULL und UNIQUE.
Zuerst verbinden wir uns mit der PostgreSQL-Datenbank. Öffnen Sie ein Terminal und verwenden Sie den Befehl psql, um sich als Benutzer postgres mit der Datenbank postgres zu verbinden.
sudo -u postgres psql
Sie sollten sich nun im interaktiven PostgreSQL-Terminal befinden.
Grundlegendes zu Constraints
Constraints werden verwendet, um die Art der Daten zu begrenzen, die in eine Tabelle eingefügt werden können. Dies gewährleistet die Genauigkeit und Zuverlässigkeit der Daten in der Datenbank.
1. NOT NULL Constraint
Der NOT NULL-Constraint stellt sicher, dass eine Spalte keine NULL-Werte enthalten kann. Dies ist nützlich, wenn eine bestimmte Information für jede Zeile in der Tabelle unerlässlich ist.
2. UNIQUE Constraint
Der UNIQUE-Constraint stellt sicher, dass alle Werte in einer Spalte unterschiedlich sind. Dies ist nützlich für Spalten, die eindeutige Kennungen oder Werte haben sollten, wie z. B. Benutzernamen oder E-Mail-Adressen (neben dem Primärschlüssel).
Hinzufügen von Constraints während der Tabellenerstellung
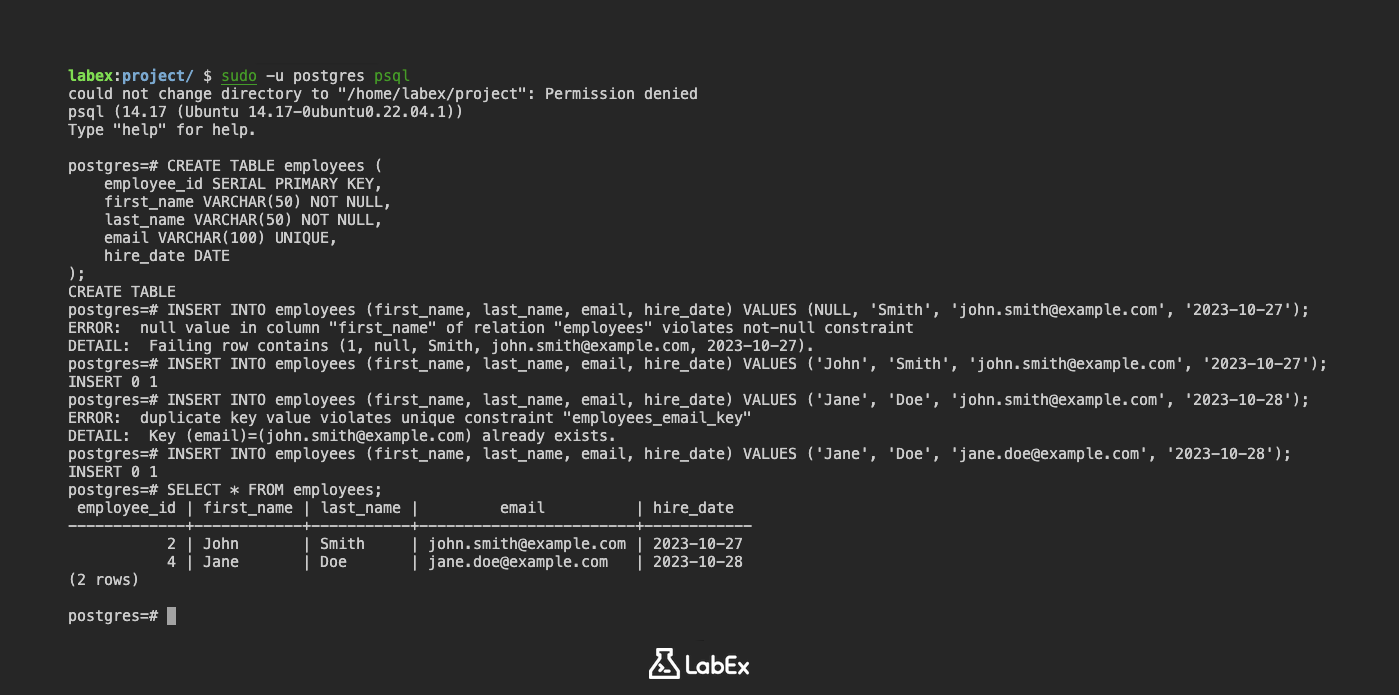
Sie können Constraints hinzufügen, wenn Sie eine Tabelle erstellen. Erstellen wir eine Tabelle namens employees mit NOT NULL- und UNIQUE-Constraints:
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE
);
In dieser Tabelle:
employee_idist der Primärschlüssel.first_nameundlast_namewerden alsNOT NULLdeklariert, was bedeutet, dass sie für jeden Mitarbeiter einen Wert haben müssen.emailwird alsUNIQUEdeklariert, wodurch sichergestellt wird, dass jeder Mitarbeiter eine eindeutige E-Mail-Adresse hat.
Versuchen wir nun, einige Daten einzufügen, die gegen diese Constraints verstoßen.
Versuch, einen NULL-Wert in eine NOT NULL-Spalte einzufügen:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES (NULL, 'Smith', 'john.smith@example.com', '2023-10-27');
Ausgabe:
ERROR: null value in column "first_name" of relation "employees" violates not-null constraint
DETAIL: Failing row contains (1, null, Smith, john.smith@example.com, 2023-10-27).
Dieser Fehler weist darauf hin, dass Sie aufgrund des NOT NULL-Constraints keinen NULL-Wert in die Spalte first_name einfügen können.
Versuch, einen doppelten Wert in eine UNIQUE-Spalte einzufügen:
Fügen Sie zuerst eine gültige Zeile ein:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('John', 'Smith', 'john.smith@example.com', '2023-10-27');
Versuchen Sie nun, eine weitere Zeile mit derselben E-Mail-Adresse einzufügen:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'john.smith@example.com', '2023-10-28');
Ausgabe:
ERROR: duplicate key value violates unique constraint "employees_email_key"
DETAIL: Key (email)=(john.smith@example.com) already exists.
Dieser Fehler weist darauf hin, dass Sie aufgrund des UNIQUE-Constraints keine doppelte E-Mail-Adresse einfügen können.
Einfügen gültiger Daten:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'jane.doe@example.com', '2023-10-28');
Zeigen Sie die Daten an:
SELECT * FROM employees;
Ausgabe:
employee_id | first_name | last_name | email | hire_date
-------------+------------+-----------+---------------------+------------
1 | John | Smith | john.smith@example.com | 2023-10-27
2 | Jane | Doe | jane.doe@example.com | 2023-10-28
(2 rows)
Beenden Sie abschließend das psql-Terminal:
\q
Sie haben nun erfolgreich eine Tabelle mit NOT NULL- und UNIQUE-Constraints erstellt und beobachtet, wie diese die Datenintegrität erzwingen.
Tabellenstruktur überprüfen
In diesem Schritt lernen wir, wie man die Struktur von Tabellen in PostgreSQL untersucht. Das Verständnis der Struktur einer Tabelle, einschließlich Spaltennamen, Datentypen, Constraints (Beschränkungen) und Indizes, ist für das effektive Abfragen und Bearbeiten von Daten unerlässlich.
Zuerst verbinden wir uns mit der PostgreSQL-Datenbank. Öffnen Sie ein Terminal und verwenden Sie den Befehl psql, um sich als Benutzer postgres mit der Datenbank postgres zu verbinden.
sudo -u postgres psql
Sie sollten sich nun im interaktiven PostgreSQL-Terminal befinden.
Der Befehl \d
Das wichtigste Werkzeug zum Untersuchen der Tabellenstruktur in psql ist der Befehl \d (describe - beschreiben). Dieser Befehl liefert detaillierte Informationen über eine Tabelle, einschließlich:
- Spaltennamen und Datentypen
- Constraints (Primärschlüssel, Unique Constraints, Not-Null-Constraints)
- Indizes
Untersuchen der Tabelle employees
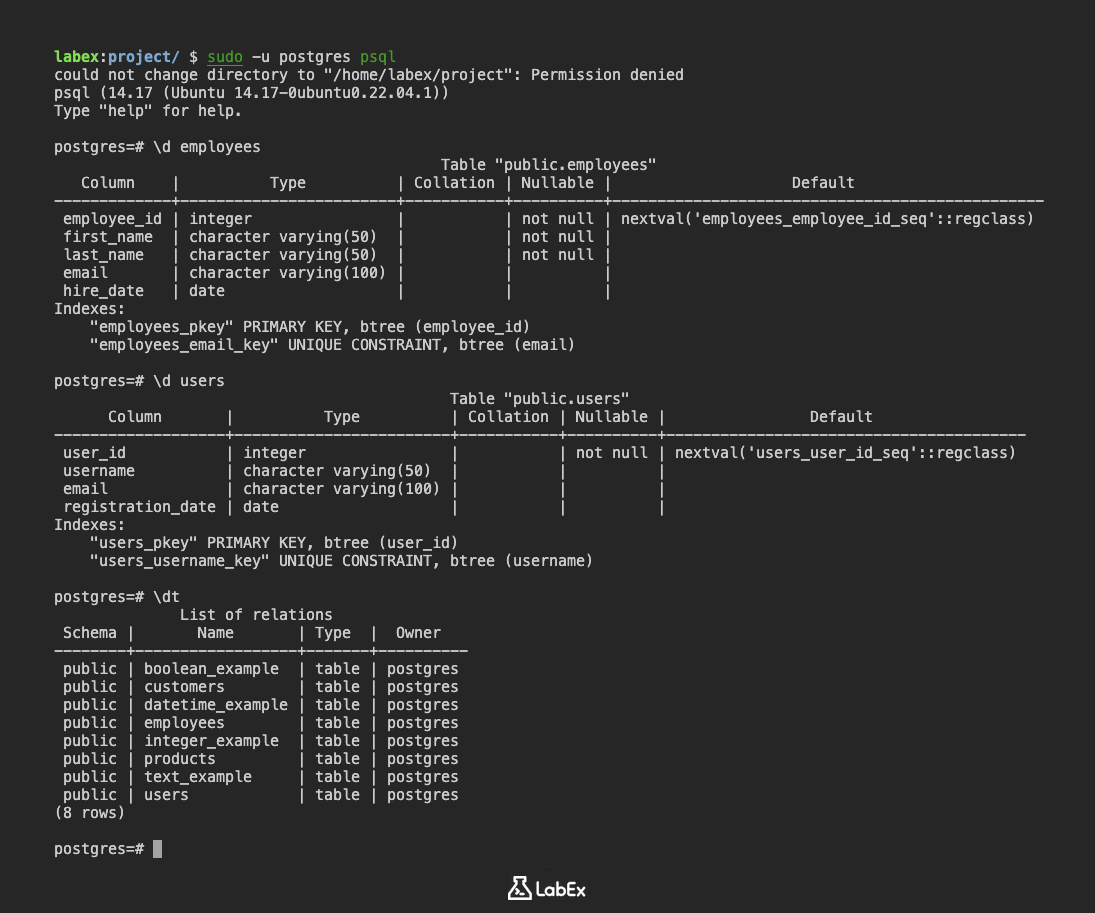
Untersuchen wir die Struktur der Tabelle employees, die wir im vorherigen Schritt erstellt haben:
\d employees
Ausgabe:
Table "public.employees"
Column | Type | Collation | Nullable | Default
-------------+------------------------+-----------+----------+------------------------------------------------
employee_id | integer | | not null | nextval('employees_employee_id_seq'::regclass)
first_name | character varying(50) | | not null |
last_name | character varying(50) | | not null |
email | character varying(100) | | |
hire_date | date | | |
Indexes:
"employees_pkey" PRIMARY KEY, btree (employee_id)
"employees_email_key" UNIQUE CONSTRAINT, btree (email)
Die Ausgabe liefert die folgenden Informationen:
- Table "public.employees": Gibt den Tabellennamen und das Schema an.
- Column: Listet die Spaltennamen auf (
employee_id,first_name,last_name,email,hire_date). - Type: Zeigt den Datentyp jeder Spalte an (
integer,character varying,date). - Nullable: Gibt an, ob eine Spalte
NULL-Werte enthalten kann (not nulloder leer). - Default: Zeigt den Standardwert für eine Spalte an (falls vorhanden).
- Indexes: Listet die für die Tabelle definierten Indizes auf, einschließlich des Primärschlüssels (
employees_pkey) und des Unique Constraints für die Spalteemail(employees_email_key).
Untersuchen anderer Tabellen
Sie können den Befehl \d verwenden, um jede Tabelle in der Datenbank zu untersuchen. Um beispielsweise die Tabelle users zu untersuchen, die in Schritt 2 erstellt wurde:
\d users
Ausgabe:
Table "public.users"
Column | Type | Collation | Nullable | Default
-------------------+------------------------+-----------+----------+----------------------------------------
user_id | integer | | not null | nextval('users_user_id_seq'::regclass)
username | character varying(50) | | |
email | character varying(100) | | |
registration_date | date | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (user_id)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
Auflisten aller Tabellen
Um alle Tabellen in der aktuellen Datenbank aufzulisten, können Sie den Befehl \dt verwenden:
\dt
Ausgabe (variiert je nach den von Ihnen erstellten Tabellen):
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | boolean_example | table | postgres
public | customers | table | postgres
public | datetime_example | table | postgres
public | employees | table | postgres
public | integer_example | table | postgres
public | products | table | postgres
public | text_example | table | postgres
public | users | table | postgres
(8 rows)
Beenden Sie abschließend das psql-Terminal:
\q
Sie haben nun gelernt, wie man die Struktur von Tabellen in PostgreSQL mit den Befehlen \d und \dt untersucht. Dies ist eine grundlegende Fähigkeit, um Datenbanken zu verstehen und mit ihnen zu arbeiten.
Zusammenfassung
In diesem Lab haben wir grundlegende PostgreSQL-Datentypen untersucht, wobei wir uns auf Ganzzahlen und Text konzentriert haben. Wir haben INTEGER und SMALLINT zum Speichern von ganzzahligen Werten kennengelernt und ihre unterschiedlichen Bereiche und Anwendungsfälle verstanden. Wir haben auch TEXT, VARCHAR(n) und CHAR(n) für die Handhabung von Textdaten untersucht und die Unterschiede zwischen Zeichenketten variabler Länge und fester Länge festgestellt.
Darüber hinaus haben wir das Erstellen von Tabellen mit diesen Datentypen geübt, einschließlich der Verwendung von SERIAL zur automatischen Generierung von Primärschlüsselsequenzen. Wir haben Beispieldaten in die Tabellen eingefügt und die Daten mit SELECT-Anweisungen verifiziert, wodurch wir unser Verständnis des Verhaltens dieser Datentypen in einem praktischen Datenbankkontext gefestigt haben.

