
Einführung
In den Hadoop-Versionen 2.0 und höher wurde das neue Ressourcenverwaltungsmuster von YARN eingeführt, das die Cluster in Bezug auf die Nutzung, die einheitliche Ressourcenverwaltung und die Datenfreigabe erleichtert. Auf der Grundlage des Aufbaus des Hadoop-Pseudo-Distributed-Clusters wird Ihnen in diesem Abschnitt die Architektur, das Arbeitsverfahren, die Konfiguration sowie die Entwicklung und Überwachungstechniken des YARN-Frameworks vermittelt.
Dieses Lab erfordert eine gewisse Java-Programmierkenntnis.
Bitte geben Sie den gesamten Beispielcode im Dokument selbst ein; vermeiden Sie möglichst das bloße Kopieren und Einfügen. Auf diese Weise können Sie sich besser mit dem Code vertraut machen. Wenn Sie Probleme haben, überprüfen Sie die Dokumentation gründlich oder Sie können sich auf das Forum für Hilfe und Kommunikation wenden.
YARN Architektur und Komponenten
YARN, das in Hadoop 0.23 als Teil von MapReduce 2.0 (MRv2) eingeführt wurde, hat die Ressourcenverwaltung und die Auftragsplanung in Hadoop-Clustern revolutioniert:
- Zerlegung von JobTracker:
MRv2zerlegt die Funktionen vonJobTrackerin separate Demons -ResourceManagerfür die Ressourcenverwaltung undApplicationMasterfür die Auftragsplanung und -überwachung. - Globaler ResourceManager: Jede Anwendung hat einen entsprechenden
ApplicationMaster, der ein MapReduce-Auftrag oder ein DAG sein kann, der den Auftrag beschreibt. - Datenberechnung-Framework: Der
ResourceManager,SlaveundNodeManagerbilden ein Framework, in dem der ResourceManager alle Anwendungsressourcen regiert. - ResourceManager-Komponenten: Der
Schedulerverteilt Ressourcen basierend auf Einschränkungen wie Kapazität und Warteschlangen, während derApplicationsManagerdie Auftragsübermittlungen und die Ausführung von ApplicationMaster behandelt. - Ressourcenallokation: Die Ressourcenanforderungen werden mithilfe von Ressourcencontainern definiert, die Elemente wie Arbeitsspeicher, CPU, Festplatte und Netzwerk enthalten.
- Rolle von NodeManager: NodeManager überwacht die Ressourcenverwendung von Containern und meldet sich an ResourceManager und Scheduler.
- Aufgaben von ApplicationMaster: ApplicationMaster verhandelt Ressourcencontainer mit Scheduler, verfolgt den Status und überwacht den Fortschritt.
Die folgende Abbildung zeigt die Beziehung:

YARN gewährleistet die API-Kompatibilität mit früheren Versionen, was einen nahtlosen Übergang für das Ausführen von MapReduce-Aufträgen ermöglicht. Ein Verständnis der Architektur und der Komponenten von YARN ist essentiell für eine effiziente Ressourcenverwaltung und Auftragsplanung in Hadoop-Clustern.
Starten des Hadoop-Daemons
Bevor wir uns mit den relevanten Konfigurationsparametern und den YARN-Anwendungsentwicklungstechniken befassen, müssen wir den Hadoop-Daemon starten, damit er jederzeit verwendet werden kann.
Doppelklicken Sie zunächst auf die Xfce-Konsole auf dem Desktop und geben Sie den folgenden Befehl ein, um zum Benutzer hadoop zu wechseln:
su - hadoop
Hinweis: Das Passwort ist 'hadoop' für den Benutzer 'hadoop'.
Sobald der Wechsel abgeschlossen ist, können Sie die mit Hadoop verbundenen Demons starten, einschließlich der HDFS- und YARN-Frameworks.
Geben Sie bitte die folgenden Befehle in der Konsole ein, um die Demons zu starten:
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
Nachdem der Start abgeschlossen ist, können Sie die jps-Befehl verwenden, um zu überprüfen, ob die zugehörigen Demons laufen.
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
Vorbereiten der Konfigurationsdatei
In diesem Abschnitt lernen wir uns yarn-site.xml ansehen, eine der wichtigsten Konfigurationsdateien von Hadoop, um zu sehen, welche Einstellungen für den YARN-Cluster in dieser Datei möglich sind.
Um das Missbrauchen von Änderungen an der Konfigurationsdatei zu vermeiden, ist es am besten, die Hadoop-Konfigurationsdatei in einem anderen Verzeichnis zu kopieren und dann zu öffnen.
Um dies zu tun, geben Sie bitte folgenden Befehl in der Konsole ein, um ein neues Verzeichnis für die Konfigurationsdatei zu erstellen:
mkdir /home/hadoop/hadoop_conf
Kopieren Sie dann die Hauptkonfigurationsdatei yarn-site.xml von YARN aus dem Installationsverzeichnis in das neu erstellte Verzeichnis.
Geben Sie bitte folgenden Befehl in der Konsole ein, um die Operation durchzuführen:
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
Öffnen Sie dann die Datei mit dem vim-Editor, um ihren Inhalt anzuzeigen:
vim /home/hadoop/hadoop_conf/yarn-site.xml
Wie die Konfigurationsdatei funktioniert
Wir wissen, dass es in dem YARN-Framework zwei wichtige Rollen gibt: ResourceManager und NodeManager. Daher ist jeder Konfigurationsparameter in der Datei eine Einstellung für die obigen beiden Komponenten.
Es gibt viele Konfigurationsparameter, die in dieser Datei eingestellt werden können. Standardmäßig enthält diese Datei jedoch keine benutzerdefinierten Konfigurationsparameter. Beispielsweise hat die Datei, die wir gerade geöffnet haben, nur das Attribut aux-services, das beim vorherigen Konfigurieren des Pseudo-Distributed-Hadoop-Clusters angegeben wurde, wie in der folgenden Abbildung zu sehen:
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Dieser Konfigurationsparameter wird verwendet, um die abhängigen Dienste festzulegen, die auf dem NodeManager ausgeführt werden müssen. Der von uns angegebene Konfigurationswert lautet mapreduce_shuffle, was bedeutet, dass der Standardwert des MapReduce-Programms auf YARN ausgeführt werden muss.
Funktionieren die nicht in der Datei angegebenen Konfigurationsparameter nicht? Nicht ganz. Wenn die Konfigurationsparameter in der Datei nicht explizit angegeben werden, liest der YARN-Framework von Hadoop die Standardwerte aus internen Dateien. Alle in der yarn-site.xml-Datei explizit angegebenen Konfigurationsparameter überschreiben die Standardwerte. Dies ist eine effektive Methode, um das Hadoop-System an verschiedene Anwendungsfälle anzupassen.
ResourceManager-Konfigurationsparameter
Das Verständnis und die korrekte Konfiguration der ResourceManager-Einstellungen in der yarn-site.xml-Datei ist essentiell für eine effiziente Ressourcenverwaltung und Auftragsausführung in einem Hadoop-Cluster. Hier ist eine Zusammenfassung der wichtigsten Konfigurationsparameter, die mit dem ResourceManager zusammenhängen:
yarn.resourcemanager.address: Gibt die Adresse für die Clients zum Übermitteln von Anwendungen und zum Beenden von Anwendungen preis. Standardport ist 8032.yarn.resourcemanager.scheduler.address: Gibt die Adresse für den ApplicationMaster zum Anfordern und Freigeben von Ressourcen preis. Standardport ist 8030.yarn.resourcemanager.resource-tracker.address: Gibt die Adresse für den NodeManager zum Senden von Heartbeats und zum Abholen von Aufgaben preis. Standardport ist 8031.yarn.resourcemanager.admin.address: Gibt die Adresse für Administratoren für Verwaltungsbefehle preis. Standardport ist 8033.yarn.resourcemanager.webapp.address: WebUI-Adresse zum Anzeigen von Clusterinformationen. Standardport ist 8088.yarn.resourcemanager.scheduler.class: Gibt den Hauptklassennamen des Schedulers an (z.B. FIFO, CapacityScheduler, FairScheduler).- Thread-Konfiguration:
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- Ressourcenallokation:
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- NodeManager-Verwaltung:
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- Heartbeat-Konfiguration:
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
Die Konfiguration dieser Parameter ermöglicht die Feinabstimmung des ResourceManager-Verhaltens, der Ressourcenallokation, der Threadbehandlung, der NodeManager-Verwaltung und der Heartbeat-Intervalle in einem Hadoop-Cluster. Das Verständnis dieser Konfigurationsparameter hilft, Probleme zu vermeiden und gewährleistet den reibungslosen Betrieb des Clusters.
NodeManager-Konfigurationsparameter
Die Konfiguration der NodeManager-Einstellungen in der yarn-site.xml-Datei ist entscheidend für die effiziente Verwaltung von Ressourcen und Aufgaben in einem Hadoop-Cluster. Hier ist eine Zusammenfassung der wichtigsten Konfigurationsparameter, die mit dem NodeManager zusammenhängen:
yarn.nodemanager.resource.memory-mb: Gibt die gesamte physische Arbeitsspeichergröße an, die dem NodeManager zur Verfügung steht. Dieser Wert bleibt während der gesamten YARN-Laufzeit konstant.yarn.nodemanager.vmem-pmem-ratio: Legt das Verhältnis zwischen der virtuellen Arbeitsspeicher- und der physischen Arbeitsspeicherallokation fest. Standardverhältnis ist2.1.yarn.nodemanager.resource.cpu-vcores: Definiert die Gesamtzahl der virtuellen CPU-Kerne, die für den NodeManager verfügbar sind. Standardwert ist8.yarn.nodemanager.local-dirs: Pfad zum Speichern von Zwischenergebnissen auf dem NodeManager, ermöglicht die Konfiguration mehrerer Verzeichnisse.yarn.nodemanager.log-dirs: Pfad zum Log-Verzeichnis des NodeManagers, unterstützt die Konfiguration mehrerer Verzeichnisse.yarn.nodemanager.log.retain-seconds: Maximale Aufbewahrungszeit für die NodeManager-Logs, Standard ist 10800 Sekunden (3 Stunden).
Die Konfiguration dieser Parameter ermöglicht die Feinabstimmung der Ressourcenallokation, der Arbeitsspeicherverwaltung, der Verzeichnispfade und der Log-Aufbewahrungs-Einstellungen für optimale Leistung und Ressourcennutzung durch den NodeManager in einem Hadoop-Cluster. Das Verständnis dieser Konfigurationsparameter hilft, den reibungslosen Betrieb und die effiziente Aufgabenausführung innerhalb des Clusters zu gewährleisten.
Abfrage von Konfigurationsparametern und Verweise auf Standardwerte
Um alle verfügbaren Konfigurationsparameter in YARN und anderen üblichen Hadoop-Komponenten zu erkunden, können Sie sich auf die Standard-Konfigurationsdateien von Apache Hadoop beziehen. Hier sind die Links, um auf die Standard-Konfigurationen zuzugreifen:
YARN-Konfigurationsparameter:
Allgemeine Konfigurationsdateien:
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
Das Erkunden dieser Standard-Konfigurationen liefert detaillierte Beschreibungen jedes Konfigurationsparameters und ihrer Zwecke und hilft Ihnen, die Rolle jedes Parameters in der Hadoop-Architektur-Design zu verstehen.
Nachdem Sie die Konfigurationen überprüft haben, können Sie den vim-Editor schließen, um Ihre Untersuchung der Hadoop-Konfigurations-Einstellungen abzuschließen.
Erstellen von Projektverzeichnissen und -dateien
Lassen Sie uns den Entwicklungsprozess der YARN-Anwendung durch Nachahmung einer offiziellen YARN-Instanz-Anwendung lernen.
Erstellen Sie zunächst ein Projektverzeichnis. Geben Sie bitte folgenden Befehl in der Konsole ein, um das Verzeichnis zu erstellen:
mkdir /home/hadoop/yarn_app
Erstellen Sie dann in dem Projekt separat zwei Quellcode-Dateien.
Die erste ist Client.java. Verwenden Sie den touch-Befehl in der Konsole, um die Datei zu erstellen:
touch /home/hadoop/yarn_app/Client.java
Erstellen Sie dann die Datei ApplicationMaster.java:
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directories, 2 files
Schreiben des Client-Codes
Durch das Schreiben des Codes für den Client können Sie die APIs und ihre Rollen verstehen, die zur Entwicklung des Client im YARN-Framework erforderlich sind.
Der Codeinhalt ist etwas lang. Ein effizienterer Weg als das Zeilenweise Lesen ist, ihn Zeile für Zeile in die zuvor erstellte Quellcode-Datei einzugeben.
Öffnen Sie zunächst die gerade erstellte Datei Client.java mit dem vim-Editor (oder einem anderen Texteditor):
vim /home/hadoop/yarn_app/Client.java
Fügen Sie dann den Hauptteil des Programms hinzu, um den Klassennamen und den Paketnamen für die Klasse anzugeben:
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: Edit code here.
}
}
Der folgende Code ist in segmentierter Form. Beim Schreiben schreiben Sie folgenden Code in die Client-Klasse (d.h. den Codeblock, in dem der Kommentar //TODO: Edit your code here steht).
Der erste Schritt, den der Client ausführen muss, ist es, das YarnClient-Objekt zu erstellen und zu initialisieren und dann zu starten:
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
Nachdem der Client erstellt wurde, müssen wir ein Objekt der YARN-Anwendung und ihre Anwendungs-ID erstellen:
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
Das appResponse-Objekt enthält Informationen über den Cluster, wie die minimale und maximale Ressourcenkapazität des Clusters. Die Informationen sind erforderlich, um sicherzustellen, dass wir die Parameter richtig einstellen können, wenn der ApplicationMaster die relevanten Container startet.
Eine der Hauptaufgaben im Client ist es, den ApplicationSubmissionContext festzulegen. Er definiert alle Informationen, die der RM benötigt, um den AM zu starten.
Im Allgemeinen muss der Client im Kontext Folgendes einstellen:
- Anwendungsinformationen: Enthält die App-ID und -Name.
- Warteschlangen- und Prioritätsinformationen: Enthält Warteschlangen und zugewiesene Prioritäten für die Anwendungsübermittlung.
- Benutzer: Wer der Benutzer ist, der die App übermittelt hat.
- ContainerLaunchContext: Definiert die Informationen des Containers, in dem der AM gestartet und ausgeführt werden soll. Alle erforderlichen Informationen, die zum Ausführen der Anwendung benötigt werden, werden im
ContainerLaunchContextdefiniert, einschließlich lokaler Ressourcen (Binärdateien, Jar-Dateien etc.), Umgebungsvariablen (CLASSPATHetc.), auszuführende Befehle und sichere Token (RECT):
// Set the application to submit the context
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// The following code is used to set the local resources of ApplicationMaster
/ / Local resources need to be local files or compressed packages etc.
// In this scenario, the jar package is in the form of a file as one of AM's local resources.
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("Copy AppMaster jar from local filesystem and add to local environment.");
// Copy the jar package of ApplicationMaster into the file system
FileSystem fs = FileSystem.get(conf);
// Create a local resource that points to the jar package path
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// Set the parameters of logs, you can skip it
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// The shell script will be available in the container that will eventually execute it
// So first copy it to the file system so that the YARN framework can find it
// You don't need to set it to the local resource of AM here because the latter doesn't need it
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// Set the environment parameters that AM requires
LOG.info("Set the environment for the application master");
Map<String, String> env = new HashMap<String, String>();
// Add the path to the shell script to the environment variable
// AM will create the correct local resource for the final container accordingly
// and the above container will execute the shell script at startup
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// Add the path to AppMaster.jar to the classpath
// Note that there is no need to provide a Hadoop-related classpath here, as we have an annotation in the external configuration file.
// The following code adds all the classpath-related path settings required by AM to the current directory
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// Set the command to execute AM
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// Set the executable command for Java
LOG.info("Setting up app master command");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// Set the memory numbers assigned by Xmx parameters under JVM
vargs.add("-Xmx" + amMemory + "m");
// Set class names
vargs.add(appMasterMainClass);
// Set the parameter of ApplicationMaster
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// Generate the final parameter and configure
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("Completed setting up app master command " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Set container for AM to start context
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// The requirement of setting resource types, including memory and virtual CPU cores.
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// If needed, the data of YARN service is passed to the applications in binary format. But it's not needed in this example.
// amContainer.setServiceData(serviceData);
// Set the Token
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"Can't get Master Kerberos principal for the RM to use as renewer");
}
// Get the token of the default file system
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens!= null) {
for (Token<?> token : tokens) {
LOG.info("Got dt for " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
Sobald der Einrichtungsvorgang abgeschlossen ist, kann der Client die Anwendung mit der angegebenen Priorität und Warteschlange übermitteln:
/ / Set the priority of AM
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// Set the queue where the application submits to RM
appContext.setQueue(amQueue);
// Submit the app to AM
yarnClient.submitApplication(appContext);
Zu diesem Zeitpunkt wird der RM die Anwendung akzeptieren und den AM im Hintergrund auf dem zugewiesenen Container einrichten und starten.
Clients können den Fortschritt der tatsächlichen Aufgaben auf verschiedene Weise verfolgen.
(1) Einer davon ist, dass Sie mit dem RM über die getApplicationReport()-Methode des YarnClient-Objekts kommunizieren und einen Anwendungsbericht anfordern können:
// Use the app ID to get its report
ApplicationReport report = yarnClient.getApplicationReport(appId);
Die von RM empfangenen Berichte umfassen Folgendes:
- Allgemeine Informationen: Enthält die Anzahl (Position) der Anwendung, die Warteschlange für die Anwendungsübermittlung, den Benutzer, der die Anwendung übermittelt hat, und die Startzeit der Anwendung.
- Details des ApplicationMaster: Der Host, auf dem der AM ausgeführt wird, der RPC-Port, der auf Anfragen von Clients lauscht, und die Token, die Client und AM zur Kommunikation benötigen.
- Anwendungsnachverfolgungsinformationen: Wenn die Anwendung eine gewisse Form der Fortschrittsverfolgung unterstützt, kann sie die zu verfolgende URL über die
getTrackingUrl()-Methode, die vom Anwendungsbericht gemeldet wird, festlegen, und der Client kann den Fortschritt mit dieser Methode überwachen. - Anwendungsstatus: Sie können den Anwendungsstatus des
ResourceManageringetYarnApplicationStatesehen. WennYarnApplicationStateaufcompletegesetzt ist, sollte der ClientgetFinalApplicationStatusreferenzieren, um zu überprüfen, ob die Aufgabe der Anwendung tatsächlich erfolgreich ausgeführt wurde. Im Falle eines Fehlers können weitere Informationen über den Fehler mitgetDiagnosticsgefunden werden.
(2) Wenn der ApplicationMaster dies unterstützt, kann der Client den Fortschritt des AM selbst direkt abfragen, indem er die hostname:rpcport-Informationen aus dem Anwendungsbericht verwendet.
In einigen Fällen, wenn die Anwendung zu lange läuft, kann der Client die Anwendung beenden möchten. YarnClient unterstützt das Aufrufen von killApplication. Es ermöglicht es dem Client, ein Beendigungssignal an den AM über den ResourceManager zu senden. Wenn so konzipiert, kann der Anwendungsmanager auch den Aufruf durch seine RPC-Schichtunterstützung beenden, wofür der Client Gebrauch machen kann.
Der konkrete Code ist wie folgt, aber der Code ist nur zur Referenz und muss nicht in Client.java geschrieben werden:
yarnClient.killApplication(appId);
Nachdem Sie den obigen Inhalt bearbeitet haben, speichern Sie den Inhalt und verlassen Sie den vim-Editor.
Schreiben des ApplicationMaster-Codes
Ähnlich wie zuvor wird der vim-Editor verwendet, um die Datei ApplicationMaster.java zu öffnen und den Code zu schreiben:
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO:Edit code here.
}
}
Die Codeerklärung ist ebenfalls in segmentierter Form. Aller im Folgenden erwähnte Code sollte in der ApplicationMaster-Klasse geschrieben werden (d.h. im Codeblock, in dem der Kommentar //TODO:Edit code here. steht).
Der AM ist der tatsächliche Besitzer der Aufgabe, der von RM gestartet wird und alle erforderlichen Informationen und Ressourcen über den Client bereitstellt, um die Aufgabe zu überwachen und abzuschließen.
Da der AM in einem einzelnen Container gestartet wird, ist es wahrscheinlich, dass der Container denselben physischen Host mit anderen Containern teilt. Angesichts der Mehrbieterschaftseigenschaften der Cloud-Computing-Plattform und anderer Probleme ist es möglich, am Anfang nicht die voreingestellten Ports zu kennen, auf die gewartet werden soll.
Wenn der AM also startet, können ihm mehrere Parameter über die Umgebung gegeben werden. Diese Parameter umfassen die ContainerId des AM-Containers, die Übermittlungszeit der Anwendung und Details über den NodeManager-Host, auf dem der AM ausgeführt wird.
Alle Interaktionen mit dem RM erfordern eine Planung der Anwendung. Wenn dieser Prozess fehlschlägt, kann jede Anwendung erneut versuchen. Sie können die ApplicationAttemptId aus der Container-ID des AM erhalten. Es gibt verwandte APIs, die Werte, die aus der Umgebung erhalten werden, in Objekte umwandeln können.
Schreiben Sie folgenden Code:
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// The container ID should be set in the environment variable of the framework
Throw new IllegalArgumentException(
"Container ID not set in the environment");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
Nachdem der AM vollständig initialisiert wurde, können wir zwei Clients starten: Einen Client für den ResourceManager und einen anderen für den NodeManager. Wir verwenden einen benutzerdefinierten Ereignishandler, um dies einzurichten, und die Details werden später besprochen:
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
Der AM muss regelmäßig Heartbeats an den RM senden, damit dieser weiß, dass der AM noch läuft. Der Ablaufzeitintervall auf dem RM wird von YarnConfiguration definiert, und sein Standardwert wird von der Konfigurationsdatei durch das Konfigurationsitem YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS definiert. Der AM muss sich im ResourceManager registrieren, um die Heartbeats zu beginnen zu senden:
// Register yourself with RM and start sending heartbeats to RM
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
Die Antwortinformationen des Registrierungsprozesses können die maximale Ressourcenkapazität des Clusters umfassen. Wir können diese Informationen verwenden, um die Anfrage der Anwendung zu überprüfen:
// Temporarily save information about cluster resource capabilities in RM
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("Max mem capability of resources in this cluster " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("Max vcores capability of resources in this cluster " + maxVCores);
// Use the maximum memory limit to constrain the container's memory capacity request value
if (containerMemory > maxMem) {
LOG.info("Container memory specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerMemory + ", max="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("Container virtual cores specified above max threshold of cluster."
+ " Using max value." + ", specified=" + containerVirtualCores + ", max="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("Received " + previousAMRunningContainers.size()
+ " previous AM's running containers on AM registration.");
Je nach Aufgabenanforderungen kann der AM eine Reihe von Containern planen, um Aufgaben auszuführen. Wir verwenden diese Anforderungen, um zu berechnen, wie viele Container wir benötigen, und bitten um eine entsprechende Anzahl von Containern:
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
//Set the request object to the RM request container
ContainerRequest containerAsk = setupContainerAskForRM();
//Send container request to RM
amRMClient.addContainerRequest(containerAsk);
// This loop means polling RM for containers after getting fully allocated quotas
}
Die obige Schleife wird so lange laufen, bis alle Container gestartet und das Shell-Skript ausgeführt wurde (egal, ob es erfolgreich oder fehlschlägt).
In setupContainerAskForRM() müssen Sie Folgendes einstellen:
- Ressourcenkapazitäten: Derzeit unterstützt YARN ressourcenbasierte Anforderungen auf der Grundlage von Arbeitsspeicher. Daher sollte die Anfrage definieren, wie viel Arbeitsspeicher benötigt wird. Dieser Wert wird in Megabyte definiert und muss kleiner als das exakte Vielfache der maximalen und minimalen Kapazitäten des Clusters sein. Diese Arbeitsspeicherressource entspricht der physischen Arbeitsspeicherbegrenzung, die für den Task-Container festgelegt wird. Ressourcenkapazitäten umfassen auch rechenbasierte Ressourcen (vCore).
- Priorität: Wenn ein Container-Set angefordert wird, kann der AM unterschiedliche Prioritäten für die Sammlungen definieren. Beispielsweise kann der MapReduce-AM höhere Prioritäten für die von der Map-Aufgabe benötigten Container zuweisen, während der Reduce-Aufgabe-Container eine niedrigere Priorität hat:
Private ContainerRequest setupContainerAskForRM() {
/ / Set the priority of the request
Priority pri = Priority.newInstance(requestPriority);
/ / Set the request for the resource type, including memory and CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("Requested container allocation: " + request.toString());
Return request;
}
Nachdem der AM einen Container-Zuweisungsantrag gesendet hat, wird der Container asynchron von dem Ereignishandler des AMRMClientAsync-Clients gestartet. Programme, die diese Logik verarbeiten, sollten die Schnittstelle AMRMClientAsync.CallbackHandler implementieren.
(1) Wenn an einen Container verteilt wird, muss der Handler einen Thread starten. Der Thread führt den relevanten Code aus, um den Container zu starten. Hier verwenden wir LaunchContainerRunnable zur Demonstration. Wir werden diese Klasse später besprechen:
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("Got response from RM for container allocation, allocatedCnt=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// Start and run the container with different threads, which prevents the main thread from blocking when all the containers cannot be allocated resources
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) Wenn ein Heartbeat gesendet wird, sollte der Ereignishandler den Fortschritt der Anwendung melden:
@Override
public float getProgress() {
// Set the progress information and report it to RM the next time you send a heartbeat
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
Der Startthread des Containers startet tatsächlich den Container auf dem NM. Nachdem einem AM ein Container zugewiesen wurde, muss er einem ähnlichen Prozess folgen, den der Client bei der Einrichtung des ContainerLaunchContext für die endgültige Aufgabe auf dem zugewiesenen Container folgt. Nachdem der ContainerLaunchContext definiert wurde, kann der AM ihn über NMClientAsync starten:
// Set the necessary commands to execute on the allocated container
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// Set the executable command
vargs.add(shellCommand);
// Set the path of the shell script
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS? ExecBatScripStringtPath
: ExecShellStringPath);
}
// Set parameters for shell commands
vargs.add(shellArgs);
// Add log redirection parameters
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// Get the final command
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Set ContainerLaunchContext to set local resources, environment variables, commands and tokens for the constructor.
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
Das NMClientAsync-Objekt und sein Ereignishandler sind für die Behandlung von Containerereignissen verantwortlich. Dies umfasst das Starten, Stoppen, Aktualisieren des Status und Fehler für den Container.
Nachdem der ApplicationMaster festgestellt hat, dass er fertig ist, muss er sich vom Client des AM-RM abmelden und dann den Client stoppen:
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("Failed to unregister application", ex);
} catch (IOException e) {
LOG.error("Failed to unregister application", e);
}
amRMClient.stop();
Der obige Inhalt ist der Hauptcode von ApplicationMaster. Nachdem Sie ihn bearbeitet haben, speichern Sie den Inhalt und verlassen Sie den vim-Editor.
Der Prozess der Anwendungsstart
Der Prozess des Startens einer Anwendung in einem Hadoop-Cluster ist wie folgt:
Kompilieren und Starten der Anwendung
Nachdem der Code im vorherigen Abschnitt abgeschlossen ist, können Sie ihn in eine Jar-Paket kompilieren und mithilfe eines Buildtools wie Maven und Gradle an den Hadoop-Cluster übermitteln.
Da der Kompilierungsprozess Netzwerkzugang benötigt, um die relevanten Abhängigkeiten herunterzuladen, dauert er lange (ca. 1 Stunde Spitze). Wir überspringen daher hier den Kompilierungsprozess und verwenden das bereits kompilierte Jar-Paket im Hadoop-Installationsverzeichnis für die nachfolgenden Experimente.
In diesem Schritt verwenden wir das einfache Beispiel-Jar, um die YARN-Anwendung auszuführen, anstatt das von Maven angegebene Jar zu erstellen.
Geben Sie bitte im Terminal den Befehl yarn jar ein, um die Ausführung zu übermitteln. Die Parameter, die in den folgenden Befehlen beteiligt sind, sind der Pfad zum auszuführenden Jar-Paket, der Name der Hauptklasse, der Pfad zum an den YARN-Framework übermittelten Jar-Paket, die Anzahl der auszuführenden Shell-Befehle und die Anzahl der Container:
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Schauen Sie sich die Ausgabe im Terminal an, und Sie können den Fortschritt der Anwendungsausführung sehen.
Estimated value of Pi is 3.55555555555555555556
Während der Ausführung der Aufgabe können Sie die Hinweise für jede Stufe aus der Ausgabe des Terminals sehen, wie z.B. Initialisierung des Clients, Verbindung zum RM und Abrufen der Clusterinformationen.
Anzeigen der Anwendungsausführungsergebnisse
Doppelklicken Sie, um den Firefox-Webbrowser auf dem Desktop zu öffnen, und geben Sie die folgende URL in die Adressleiste ein, um die Ressourceninformationen der Knoten im YARN-Muster des Hadoop-Clusters anzuzeigen:
http://localhost:8088
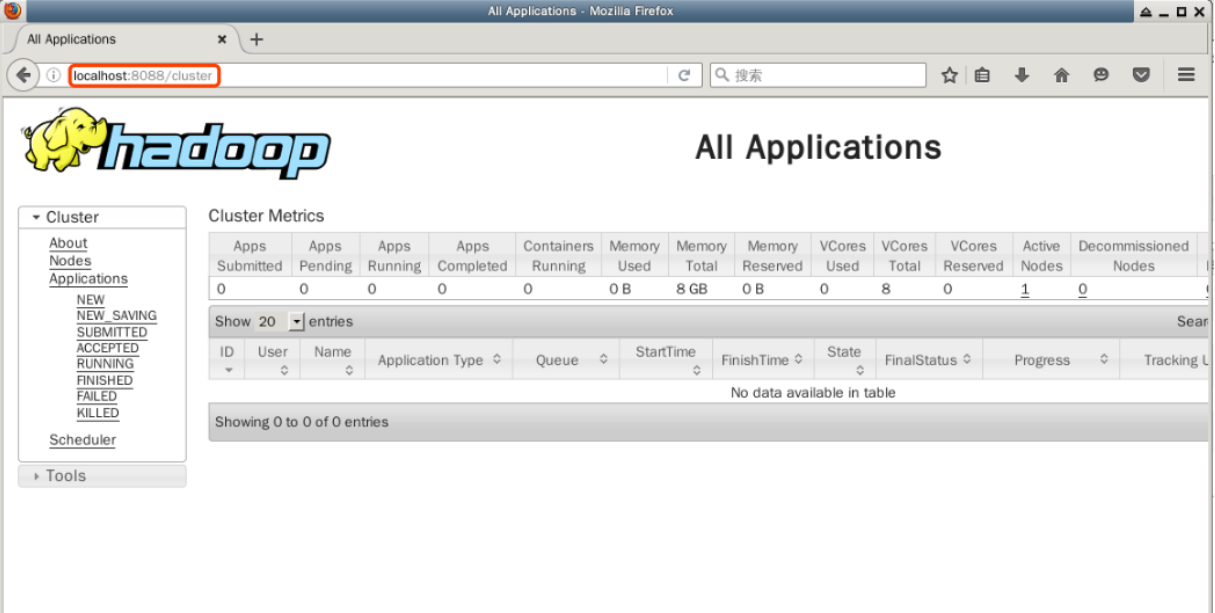
Auf dieser Seite werden alle Informationen über den Hadoop-Cluster angezeigt, einschließlich des Status der Knoten, Anwendungen und Scheduler.
Das Wichtigste hiervon ist die Verwaltung der Anwendung, und wir können hier später den Ausführungsstatus der übermittelten Anwendung sehen. Schließen Sie den Firefox-Browser für jetzt bitte nicht.
Zusammenfassung
Auf der Grundlage der Fertigstellung des Hadoop-Pseudo-Distributed-Clusters lehrt uns dieser Lab weiter über die Architektur, das Arbeitsprinzip, die Konfiguration sowie die Entwicklung und Überwachungstechniken des YARN-Frameworks. Im Kurs werden viele Code- und Konfigurationsdateien bereitgestellt, lesen Sie sie daher bitte sorgfältig.


