
はじめに
scikit-learn を使用した K 最近傍法 (KNN) 分類に関する実践的なラボへようこそ!scikit-learn は、機械学習のための強力で人気のある Python ライブラリです。KNN アルゴリズムは、最もシンプルでありながら効果的な分類アルゴリズムの 1 つです。これは、特徴空間における 'k' 個の最も近い近傍の多数決クラスに基づいて新しいデータ点を分類します。このラボでは、機械学習モデルを構築する完全なプロセスを順を追って説明します。有名なアヤメ (Iris) データセットの読み込み、トレーニングセットとテストセットへの分割、KNN 分類器の初期化とトレーニング、そして最後に、トレーニング済みのモデルを使用して新しい未知のデータに対する予測を行います。このラボの終わりには、scikit-learn における教師あり学習の基本的なワークフローをしっかりと理解できるようになります。
datasets.load_iris() で Iris データセットを読み込む
このステップでは、まず必要なデータセットを読み込みます。ここでは、scikit-learn に便利に含まれている古典的なアヤメ (Iris) データセットを使用します。まず、sklearn から datasets モジュールをインポートする必要があります。次に、load_iris() 関数を呼び出してデータを取得します。
load_iris() の理解:
- 戻り値: 以下の情報を含む
Bunchオブジェクト(辞書に似ています)を返します。.data: 特徴行列 (150 サンプル × 4 特徴:がく片長、がく片幅、花弁長、花弁幅).target: ラベル配列 (種:0=setosa、1=versicolor、2=virginica).feature_names: 4 つの特徴の名前.target_names: 3 つの種のの名前
- 目的: 分類練習のために、クリーンでそのまま使用できるデータセットを提供します。
これらをそれぞれ変数 X と y に代入します。これは機械学習における一般的な慣習です (X は特徴、y はラベル)。
左側のエディタで main.py ファイルを開き、以下のコードを追加してください。
from sklearn import datasets
## アヤメデータセットを読み込む
iris = datasets.load_iris()
## 特徴を X に、ラベルを y に代入する
X = iris.data
y = iris.target
## 次元を確認するために形状をプリントすることもできます
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
次に、ターミナルからスクリプトを実行して出力を確認します。
python3 main.py
特徴行列とラベルベクトルの次元が表示されるはずです。
Features shape: (150, 4)
Labels shape: (150,)
これは、各サンプルに対して 150 個のサンプル(花)と 4 つの特徴があることを示しています。
sklearn.model_selection の train_test_split を使用してデータを訓練用とテスト用に分割する
このステップでは、データセットを訓練セットとテストセットの 2 つの部分に分割します。これは、未知のデータに対するモデルのパフォーマンスを評価するために、機械学習において非常に重要なステップです。
train_test_split() パラメータの理解:
test_size=0.3: データの 30% をテスト用に、70% を訓練用に確保します。random_state=42: 再現性のある分割を保証します(実行ごとに同じ乱数シードを使用)。- 目的: 未知のデータでモデルを評価することにより、過学習を防ぎます。
- 出力: 4 つの配列を返します:X_train, X_test, y_train, y_test
モデルは訓練セットで学習させ、その後、テストセットでその予測能力をテストします。Scikit-learn は、この目的のために train_test_split という便利な関数を提供しています。これは sklearn.model_selection からインポートする必要があります。
main.py ファイルの末尾に以下のコードを追加してください。
from sklearn.model_selection import train_test_split
## データを訓練セットとテストセットに分割する
## test_size=0.3 は、データの 30% がテストに使用されることを意味します
## random_state は再現性を保証します
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## 新しいセットの形状をプリントする
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
スクリプトを再度実行してください。
python3 main.py
出力には、訓練セットとテストセットの形状が含まれるようになります。
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
sklearn.neighbors の KNeighborsClassifier を n_neighbors=3 で初期化する
このステップでは、K 近傍法 (K-Nearest Neighbors) 分類器を初期化します。KNN の中心的な考え方は、データポイントのクラスを、その「k」個の最も近い近傍のクラスを見て予測することです。
KNeighborsClassifier() パラメータの理解:
n_neighbors=3: 予測を考慮する最も近い近傍の数- 小さい値(例:1-3): ノイズに敏感で、過学習する可能性があります。
- 大きい値(例:5-7): より滑らかな決定境界、より堅牢になります。
- アルゴリズムの動作: 予測のために、k 個の最も近い訓練ポイントを見つけ、多数決を使用します。
- 訓練フェーズなし: KNN は「遅延学習 (lazy learner)」です。訓練データを格納し、予測時に計算を行います。
KNeighborsClassifier は、このアルゴリズムを実装する scikit-learn のクラスです。これは sklearn.neighbors からインポートする必要があります。分類器オブジェクトを作成し、clf という名前を付けましょう。
main.py ファイルの末尾に以下のコードを追加してください。
from sklearn.neighbors import KNeighborsClassifier
## n_neighbors=3 で KNN 分類器を初期化する
clf = KNeighborsClassifier(n_neighbors=3)
このコードは何も出力を生成しませんが、分類器オブジェクトをメモリ内に作成し、次のステップで訓練する準備が整います。
clf.fit(X_train, y_train) で分類器を適合させる
このステップでは、訓練データを使用して分類器を訓練、つまり「適合 (fit)」させます。KNN アルゴリズムの場合、「訓練」フェーズは非常にシンプルです。訓練データセット全体 (X_train および y_train) を格納するだけです。
.fit() メソッドの理解:
- 入力パラメータ:
X_train(特徴量行列)、y_train(ターゲットラベル) - 機能: 予測時に後で使用するために、訓練データをメモリに格納します。
- KNN の特異性: 他のアルゴリズムとは異なり、KNN は fit 中にパラメータを学習しません。
- 目的: 新しいデータに対する予測のためにモデルを準備します。
新しいポイントに対して予測が必要な場合、アルゴリズムはこの格納されたデータセット内で最も近い 'k' 個のポイントを見つけ、決定を下します。scikit-learn でモデルを訓練するには、分類器オブジェクトの .fit() メソッドを使用します。このメソッドは、訓練特徴量 (X_train) と対応する訓練ラベル (y_train) を引数として取ります。
main.py の末尾に以下のコード行を追加してください。
## 訓練データを使用して分類器を訓練する
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
コードを追加した後、スクリプトを実行してください。
python3 main.py
分類器が訓練されたことを示す確認メッセージが表示されます。
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
clf.predict(X_test) でクラスを予測する
この最終ステップでは、訓練済み分類器を使用してテストデータに対する予測を行います。モデルは訓練データから「学習」したので、これまで見たことのないテストセットの特徴量 (X_test) を与え、各サンプルに対するクラスを予測するように依頼できます。
.predict() メソッドの理解:
- 入力パラメータ:
X_test(未知データの特徴量行列) - アルゴリズムのプロセス: 各テストサンプルについて、訓練データ内で k 個の最も近い近傍を見つけ、多数決を使用します。
- 出力: 予測されたクラスラベルの配列 (入力サンプルと同じ長さ)
- 距離メトリック: ポイント間の類似性を測定するために、デフォルトでユークリッド距離を使用します。
- 目的: 新しい未知のデータに対するモデルのパフォーマンスを評価します。
これは .predict() メソッドを使用して行われます。このメソッドはテスト特徴量 (X_test) を入力として受け取り、予測されたラベルの配列を返します。これらの予測を predictions という変数に格納し、コンソールに出力します。実際のラベル (y_test) を出力して、モデルがどの程度うまく機能したかを確認することもできます。
最後のコード片を main.py ファイルに追加してください。
## テストデータに対する予測を行う
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
これで、完全なスクリプトを実行します。
python3 main.py
テストセットに対する予測されたクラスラベルの配列が表示され、その後に実際のラベルの配列が表示されます。
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
注:ここでは出力配列がすべて表示されています。2 つの配列を比較すると、予測が実際のラベルと完全に一致していることがわかります。これは、このテストセットに対するモデルの優れたパフォーマンスを示しています。
KNN 分類結果の可視化
このボーナスステップでは、KNN 分類結果をより深く理解するために可視化を作成します。可視化により、モデルのパフォーマンスがどの程度であったかを確認し、KNN アルゴリズムによって作成された決定境界を理解することができます。
分類におけるデータ可視化の理解:
- 散布図: 特徴量間の関係とクラスの分布を示します。
- 色分け: 異なる色は異なるクラス (種) を表します。
- 訓練データ vs テストデータ: モデルの汎化を理解するのに役立ちます。
- 予測精度: 予測ラベルと実際のラベルの視覚的な比較。
可視化を作成するために、以下のコードを main.py ファイルの末尾に追加してください。
import matplotlib.pyplot as plt
import numpy as np
## 複数の可視化のためのサブプロットを作成
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## プロット 1: 各クラスに異なる色を付けた訓練データの分布
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## プロット 2: テストデータの予測 vs 実際のラベル
## 比較を作成:正しい予測 vs 不正解な予測
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## 正しい予測をプロット
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## 不正解な予測を異なるマーカーでプロット
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## 凡例を作成
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## 追加:予測精度を表示
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
更新されたスクリプトを実行します。
python3 main.py
以下のような出力が表示されるはずです。
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
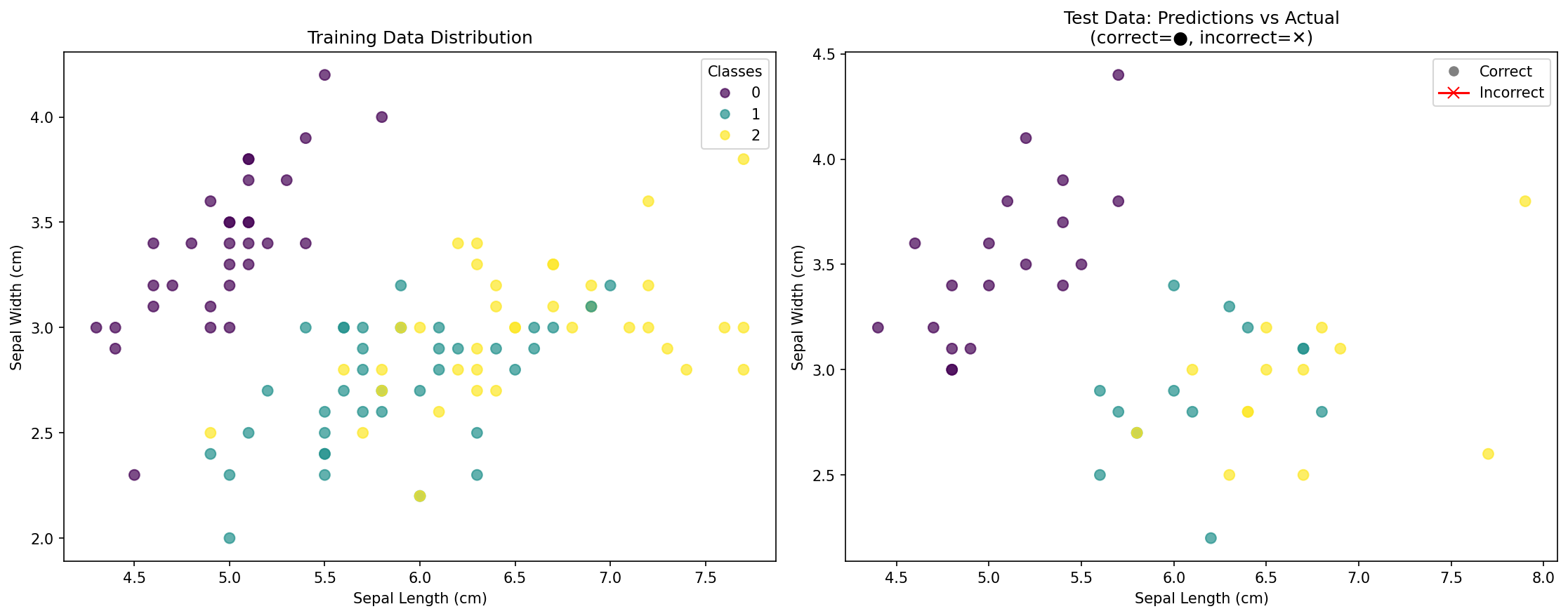
可視化が示すもの:
- 左側のプロット: 実際の種ごとに色分けされた訓練データの分布。
- 右側のプロット: テストデータのポイントを示します。
- 円 (●): 正しく分類されたポイント。
- バツ (✕): 不正解に分類されたポイント (もしあれば)。
- 精度スコア: 正しい予測の全体的なパーセンテージ。
この可視化は、以下のことを理解するのに役立ちます。
- 特徴空間におけるクラスの分布。
- モデルが過学習しているか、うまく汎化しているか。
- 分類にとってどの領域が難しい可能性があるか。
- KNN モデルの効果を視覚的に。
まとめ
この実験の完了、おめでとうございます!scikit-learn を使用して、K 近傍法 (K-Nearest Neighbors) 分類モデルを正常に構築および訓練しました。教師あり機械学習プロジェクトの基本的なワークフローを学びました。これには以下が含まれます。
sklearn.datasetsを使用したデータセットの読み込み。train_test_splitを使用したデータの訓練セットとテストセットへの分割。- 分類器の初期化、この場合は
KNeighborsClassifier。 .fit()メソッドを使用した訓練データでのモデルの訓練。.predict()メソッドを使用した新しい未知のデータに対する予測。- モデルのパフォーマンスと決定パターンを理解するための結果の可視化。
このプロセスは、多くの機械学習タスクの基礎となります。ここから、精度 (accuracy)、適合率 (precision)、再現率 (recall) などのメトリックを使用してモデルのパフォーマンスをより正式に評価する方法を調べたり、n_neighbors の異なる値を試して結果にどのように影響するかを確認したりできます。また、決定境界を可視化したり、KNN 分類器で異なる距離メトリックを使用したりすることもできます。


