
はじめに
scikit-learn の最初の実験へようこそ!scikit-learn は、Python で最も人気があり強力なオープンソースの機械学習ライブラリの 1 つです。NumPy、SciPy、matplotlib を基盤として構築されており、データマイニングおよびデータ分析のための幅広いツールを提供します。
このコースを開始する前に、基本的な Python プログラミングスキルを持っていること、およびシステム PATH に Python が正しく設定されていることを確認してください。まだ Python を学習していない場合は、Python 学習パスから始めることができます。さらに、scikit-learn の操作には NumPy と Pandas が不可欠な前提条件であるため、これらがインストールされている必要があります。これらのライブラリを学習する必要がある場合は、NumPy 学習パスとPandas 学習パスをご覧ください。
この実験では、LabEx 環境で scikit-learn を使い始めるための基本的な手順を学びます。インストールの確認、モジュールのインポート、scikit-learn の組み込みデータセットの 1 つの読み込みについて説明します。これにより、将来の機械学習実験のために環境が正しく設定されていることを確認できます。
pip install scikit-learn を使用して scikit-learn をインストールする
このステップでは、scikit-learn ライブラリのインストール方法について説明します。ローカルマシンの典型的な Python 環境では、Python のパッケージインストーラである pip を使用して新しいライブラリをインストールします。scikit-learn をインストールするためのコマンドは次のとおりです。
pip install scikit-learn
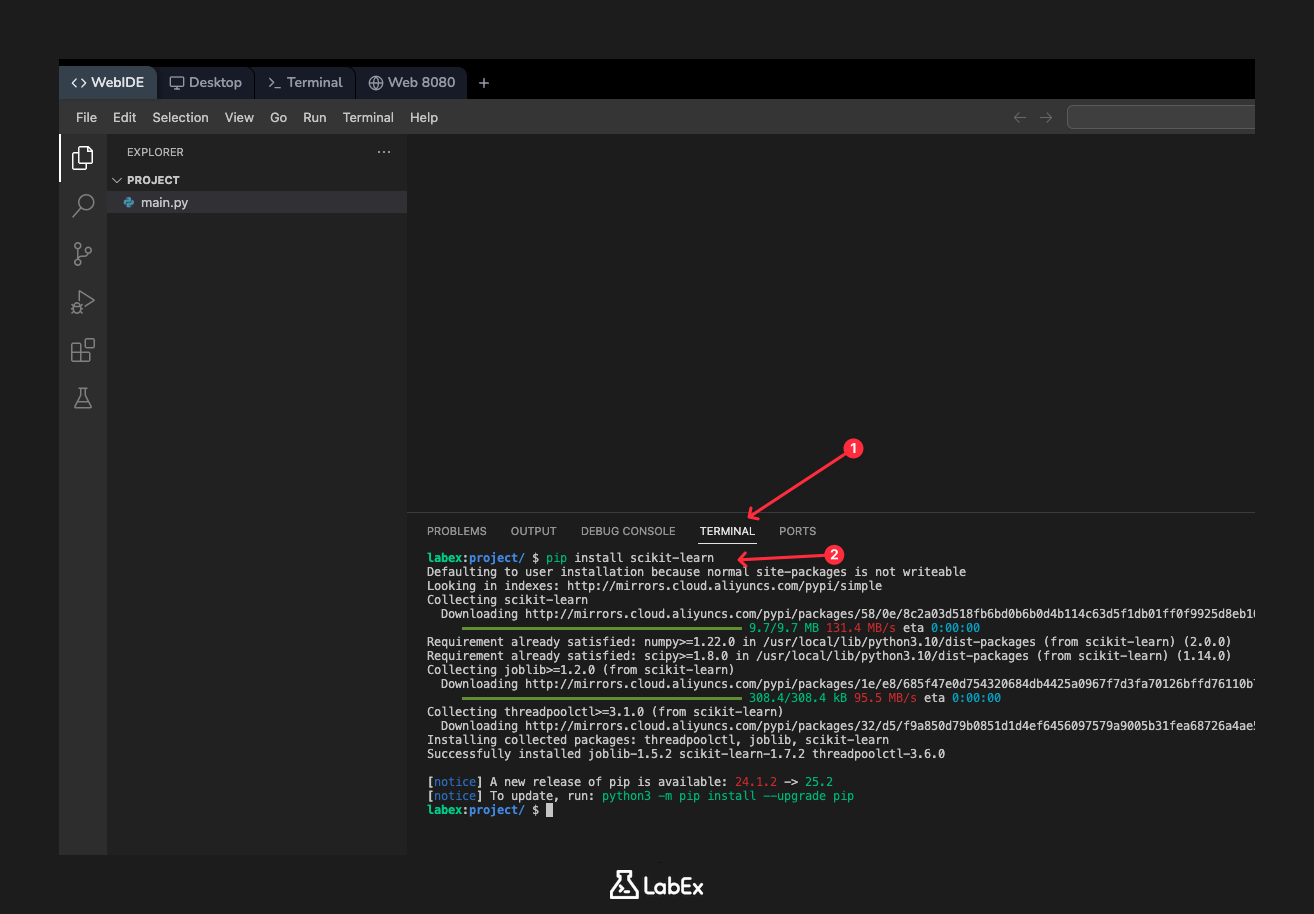
ただし、学習体験をよりスムーズにするために、LabEx 環境には scikit-learn とその依存関係がプリインストールされています。したがって、ここではインストールコマンドを実行する必要はありません。参考のために示していますので、ご自身のコンピューターに scikit-learn をセットアップする方法を把握しておいてください。
ライブラリの使用を開始するために、次のステップに進みましょう。
sklearn import datasets として scikit-learn をインポートする
このステップでは、scikit-learn ライブラリと対話するための最初の Python コードを記述します。ライブラリの関数やオブジェクトを Python スクリプトで使用するには、まずそれをインポートする必要があります。
Scikit-learn には datasets というモジュールが含まれており、人気の参照データセットをロードおよび取得するためのユーティリティが含まれています。このモジュールをインポートして、後続のステップで使用します。
まず、WebIDE の左側にあるファイルエクスプローラーで main.py ファイルを見つけます。それをクリックしてエディタで開きます。次に、main.py ファイルに次のコード行を追加します。
from sklearn import datasets
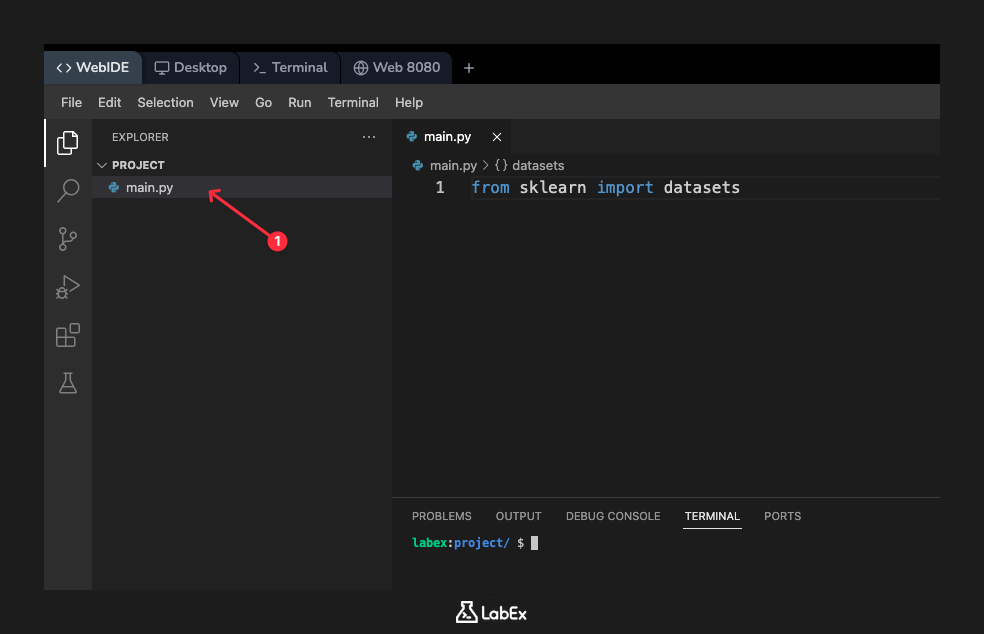
この行は、Python に対して sklearn ライブラリを見つけ、そこから datasets モジュールをインポートするように指示し、その関数を使用できるようにします。コードを追加したら、ファイルを保存します。次のステップでさらにコードを追加し、スクリプトを実行します。
sklearn.version でインストールを確認する
このステップでは、バージョン番号を確認することで、scikit-learn が正しくインストールされ、アクセス可能であることを検証します。これは、ライブラリが環境に正しくセットアップされていることを確認するための一般的なプラクティスです。すべての scikit-learn インストールには、この情報を持つ特別な属性 __version__ があります。
main.py ファイルにコードを追加してバージョンを印刷しましょう。トップレベルの sklearn パッケージ自体もインポートする必要があります。main.py ファイルを次のように変更してください。
import sklearn
from sklearn import datasets
print(sklearn.__version__)
次に、このスクリプトを実行しましょう。WebIDE でターミナルを開きます(通常、「+」アイコンまたは「Terminal」メニューで見つけることができます)。ターミナルは /home/labex/project ディレクトリで開かれるはずです。そこで、次のコマンドを実行します。
python3 main.py
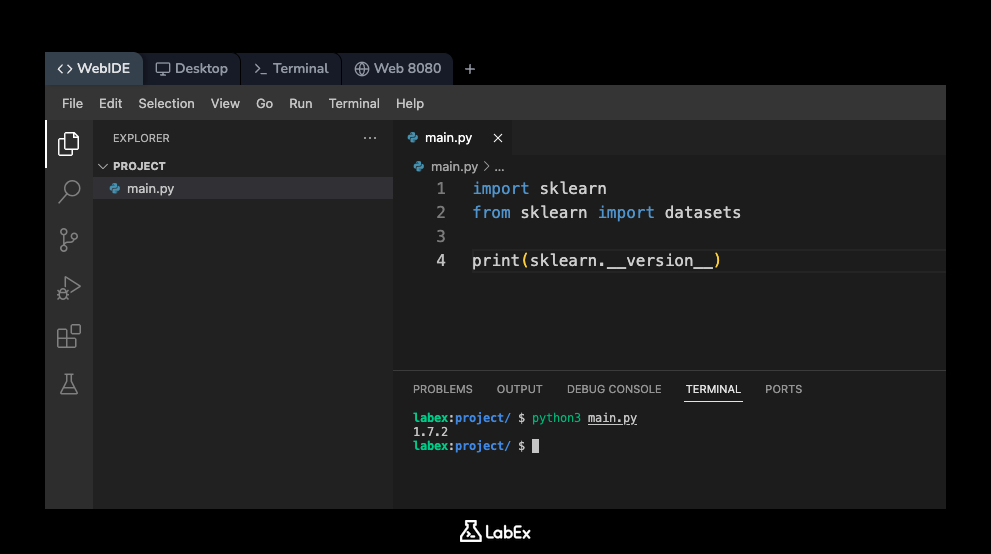
インストールされている scikit-learn のバージョンがコンソールに出力されるはずです。出力はこのようになります(正確なバージョン番号は異なる場合があります)。
1.x.x
これにより、Python が scikit-learn ライブラリを正常にインポートして使用できることが確認できます。
datasets.load_iris() を使用してサンプルデータセットをロードする
このステップでは、以前インポートした datasets モジュールを使用してサンプルデータセットをロードします。Scikit-learn には、外部ウェブサイトからダウンロードする必要のない、いくつかの小さくて標準的なデータセットが付属しています。これらは、開始やアルゴリズムのテストに役立ちます。
機械学習分野で古典的かつ非常に有名なデータセットである Iris データセットをロードします。このデータセットには、3 つの異なる種のアイリスの花 150 個の測定値が含まれています。
ロードするには、datasets.load_iris() 関数を使用します。main.py ファイルを変更してデータセットをロードし、iris という名前の変数に格納しましょう。また、データセットがロードされたことを確認するための print ステートメントも追加します。
main.py ファイルを以下の内容で更新してください。
import sklearn
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
print("Iris dataset loaded successfully.")
提案: 上記のコードをコードエディタにコピーし、各コード行を注意深く読んでその機能を理解してください。さらに詳しい説明が必要な場合は、「コードの説明」ボタン 👆 をクリックできます。Labby と対話して、パーソナライズされたヘルプを得ることができます。
ファイルを保存し、ターミナルから再度実行します。
python3 main.py
出力は次のようになります。
Iris dataset loaded successfully.
これは、load_iris() 関数がエラーなく実行され、データセットがスクリプト内の iris 変数で利用可能になったことを示しています。
print(iris.keys()) でデータセットのキーを表示する
このステップでは、先ほどロードした Iris データセットの構造を調べます。load_iris() によって返されるオブジェクトは Bunch オブジェクトであり、Python の辞書に似ています。データセットを説明するキーと値が含まれています。
どのような情報が利用可能かを確認するために、.keys() メソッドを使用してキーを表示します。これにより、データ自体、ターゲットラベル、説明的な名前など、データセットのすべてのコンポーネントが表示されます。
main.py ファイルを変更して、iris オブジェクトのキーを表示します。最終的なスクリプトは次のようになります。
import sklearn
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Print the keys of the dataset
print(iris.keys())
ファイルを保存し、ターミナルから最後にもう一度実行します。
python3 main.py
出力には、データセットオブジェクトのさまざまな部分が表示されます。
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
最も重要なキーの簡単な内訳は次のとおりです。
data: 特徴データ(花の測定値)を含む配列。target: ラベル(各花の種)を含む配列。feature_names: 特徴の名前(例:'sepal length (cm)')。target_names: ターゲット種の名前(例:'setosa')。DESCR: データセットの完全な説明。
これらのキーを表示することで、データセットを正常にロードおよび検査し、基本的なセットアッププロセスを完了しました。
まとめ
おめでとうございます!scikit-learn 環境のセットアップと検証に関するこの入門的な実験を無事に完了しました。
この実験では、以下の方法を学びました。
- scikit-learn のインストールプロセスを理解する。
- ライブラリのバージョンを確認し、セットアップが成功したことを確認する。
- scikit-learn ライブラリからモジュールをインポートする。
- 内蔵のサンプルデータセットである Iris データセットをロードする。
- scikit-learn データセットオブジェクトの基本的な構造を検査する。
これで、scikit-learn が提供する強力なツールを使用して、データの前処理、モデルのトレーニング、評価を探索する、よりエキサイティングな実験に進む準備が整いました。


