
はじめに
scikit-learn を用いた機械学習の世界へようこそ!あらゆる機械学習プロジェクトにおいて、最初で最も重要なステップの 1 つは、データの読み込みと理解です。Python の強力で使いやすい機械学習ライブラリである scikit-learn は、学習開始に役立ついくつかの組み込みデータセットを提供しています。
この実験では、有名なアヤメの花のデータセットを扱います。このデータセットの読み込み方法、構造の確認方法、特徴量データとターゲットラベルへのアクセス方法、そして最後に、データの分布を最初に把握するための簡単な可視化を作成する方法を学びます。この基礎知識は、将来のデータサイエンティストや機械学習エンジニアにとって不可欠です。
datasets.load_iris() で Iris データセットを読み込む
このステップでは、scikit-learn の組み込みデータセットの 1 つを読み込む方法を学びます。sklearn.datasets モジュールから load_iris() 関数を使用します。この関数は、Python の辞書に似た「Bunch」オブジェクトを返します。このオブジェクトには、データセットとそのメタデータが含まれています。
まず、画面左側のファイルエクスプローラーから main.py ファイルを開きます。すべてのコードはこのファイルに記述します。
次に、必要なモジュールをインポートし、データセットを読み込むために、以下のコードを main.py に追加します。
from sklearn import datasets
## Iris データセットを読み込む
iris = datasets.load_iris()
このコードは datasets モジュールをインポートし、load_iris() 関数を呼び出して、結果のデータセットオブジェクトを iris という名前の変数に格納します。
スクリプトを実行するには、WebIDE でターミナルを開き(「Terminal」->「New Terminal」メニューを使用できます)、以下のコマンドを実行します。現在のディレクトリはすでに ~/project になっています。
python3 main.py
何も出力されませんが、これは想定通りです。データは iris 変数に読み込まれましたが、まだスクリプトに何も表示するように指示していません。次のステップで、この iris オブジェクトの内容を探求します。
iris.data を使用してデータ配列にアクセスする
このステップでは、データセットの核心である特徴量データにアクセスします。作成した iris オブジェクトには data という属性があり、これには各花の測定値の NumPy 配列が格納されています。各行はサンプル(花)を表し、各列は特徴量(測定値)を表します。
main.py ファイルを編集して、このデータ配列を印刷し、どのようなものか見てみましょう。
main.py ファイルを以下のコードで更新してください。
from sklearn import datasets
## Iris データセットを読み込む
iris = datasets.load_iris()
## データ配列を印刷する
print(iris.data)
ターミナルから再度スクリプトを実行します。
python3 main.py
ターミナルに数値の大きな配列が表示されるはずです。これが、データセット内のすべての 150 個の花のサンプルの特徴量データです。各サンプルには 4 つの特徴量があります。
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
...
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
iris.target を使用してターゲット配列にアクセスする
このステップでは、データセット内の各サンプルのラベルにアクセスします。教師あり機械学習では、これらのラベルは「ターゲット」と呼ばれます。iris オブジェクトは、これらを target 属性に格納しています。Iris データセットの場合、ターゲットは各花の種を表します。
種は整数でエンコードされています。セトサは 0、バーシカラーは 1、バージニカは 2 です。iris.target 属性は、iris.data 内の各サンプルに対応する整数を含む NumPy 配列です。
main.py を編集してターゲット配列を印刷しましょう。
from sklearn import datasets
## Iris データセットを読み込む
iris = datasets.load_iris()
## ターゲット配列を印刷する
print(iris.target)
ターミナルからスクリプトを実行します。
python3 main.py
出力は、150 個の花のそれぞれに対応する種を表す 0、1、2 の配列になります。
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
iris.feature_names で特徴量名を確認する
このステップでは、iris.data 配列の列が実際には何を表しているのかを知る方法を学びます。4 つの特徴量があることはわかっていますが、データ配列自体からはその名前はすぐにはわかりません。iris オブジェクトは、これらの名前を feature_names 属性に便利に格納しています。
これは、データを理解し解釈する上で非常に役立ちます。main.py を編集して、これらの特徴量の名前を印刷しましょう。
main.py ファイルを更新してください。
from sklearn import datasets
## Iris データセットを読み込む
iris = datasets.load_iris()
## 特徴量の名前を印刷する
print(iris.feature_names)
ターミナルからスクリプトを実行します。
python3 main.py
出力は文字列のリストになり、iris.data の 4 つの列それぞれに名前が付けられます。
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
これで、4 つの特徴量が、すべてセンチメートル単位の、がく片の長さ、がく片の幅、花びらの長さ、花びらの幅に対応していることがわかりました。
matplotlib.pyplot.scatter(iris.data[:, 0], iris.data[:, 1]) を使用してデータを可視化する
この最終ステップでは、2 つの特徴量の関係を見るための簡単なデータ可視化を行います。可視化はデータ探索の重要な部分です。ここでは、Python で人気のプロットツールである matplotlib ライブラリを使用して散布図を作成します。
最初の特徴量(がく片の長さ)と 2 番目の特徴量(がく片の幅)をプロットします。データからこれらの列を選択するには、NumPy のスライシングを使用します。
iris.data[:, 0]は、すべての行(:)と最初の列(0)を選択します。iris.data[:, 1]は、すべての行(:)と 2 番目の列(1)を選択します。
この環境では画面にプロットを表示するのは理想的ではないため、代わりに iris_plot.png という名前の画像ファイルに保存します。
main.py ファイルを以下のコードで更新してください。
from sklearn import datasets
import matplotlib.pyplot as plt
## Iris データセットを読み込む
iris = datasets.load_iris()
## 最初の 2 つの特徴量をプロットします:がく片の長さ vs がく片の幅
X = iris.data[:, :2]
y = iris.target
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('Sepal Length vs Sepal Width')
## プロットをファイルに保存する
plt.savefig('iris_plot.png')
print("Plot saved to iris_plot.png")
ターミナルからスクリプトを実行します。
python3 main.py
確認メッセージが表示されます。
Plot saved to iris_plot.png
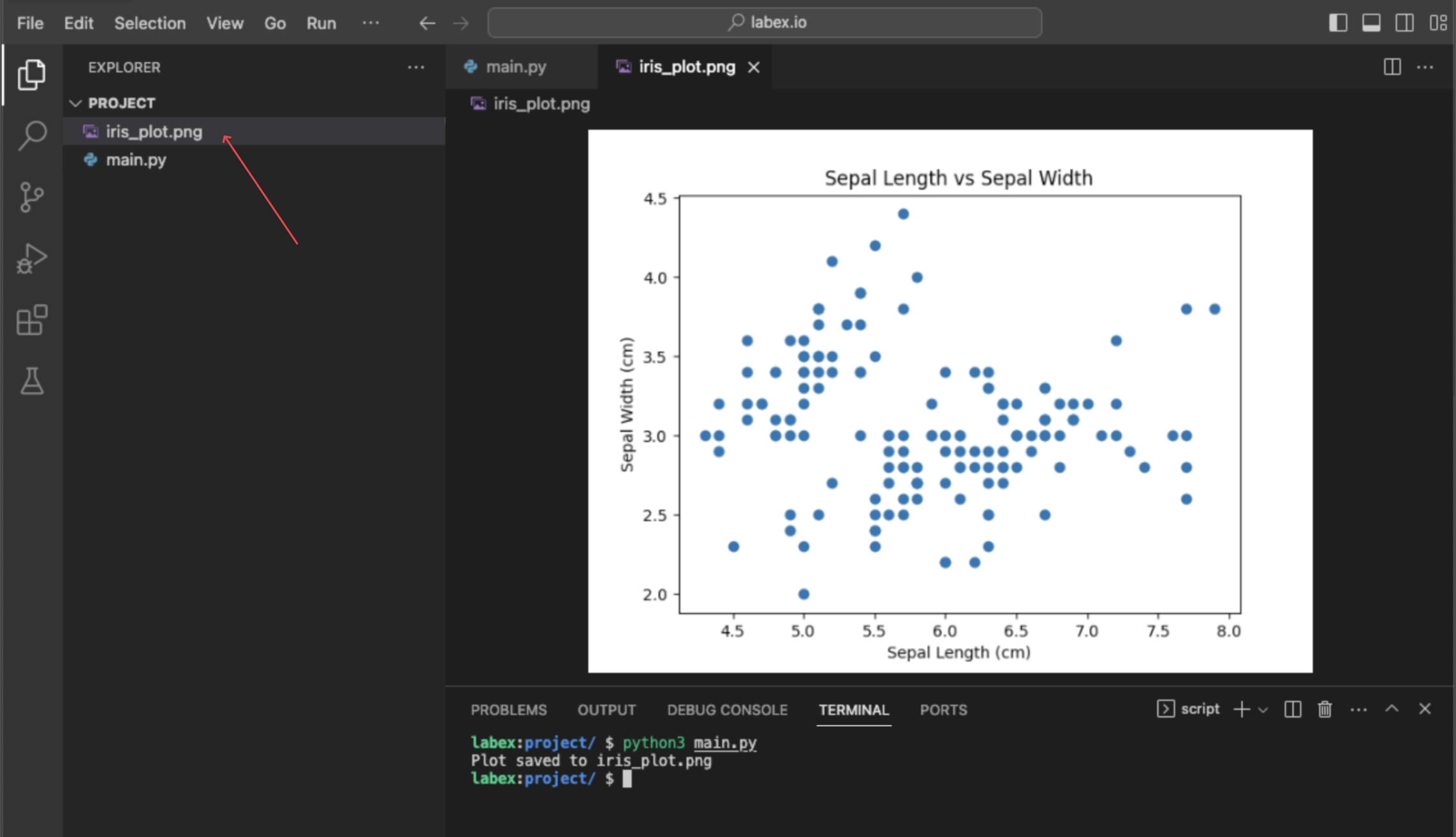
このコマンドはプロットを直接表示しませんが、~/project ディレクトリに iris_plot.png という名前の新しいファイルが作成されます。左側のファイルエクスプローラーでこのファイルをダブルクリックすると、散布図を表示できます。
まとめ
この実験の完了、おめでとうございます!scikit-learn を使ったデータハンドリングの最初のステップを無事に完了しました。
この実験では、以下の方法を学びました。
sklearn.datasets.load_iris()を使用して組み込みデータセットを読み込む方法。.data属性を使用して特徴量行列にアクセスする方法。.target属性を使用してターゲットラベルにアクセスする方法。.feature_names属性を調べることで、特徴量の意味を理解する方法。matplotlibで散布図を作成し、ファイルに保存することで、基本的なデータ可視化を実行する方法。
これらの基本的なスキルは、より高度な機械学習タスクの構成要素となります。これで、他のデータセットを探索し、独自の機械学習モデルの構築を開始する準備が整いました。


