
Introduction
Ce laboratoire continuera de parler de HDFS, l'un des principaux composants de Hadoop. L'étude de ce laboratoire vous aidera à comprendre les principes de fonctionnement et les opérations de base de HDFS, ainsi que les méthodes d'accès à WebHDFS dans l'architecture logicielle de Hadoop.
Présentation de HDFS
Comme son nom l'indique, HDFS (Hadoop Distributed File System) est un composant de stockage distribué dans le cadre de Hadoop, et il est tolérant aux pannes et évolutif.
HDFS peut être utilisé comme partie d'un cluster Hadoop ou comme un système de fichiers distribué universel autonome. Par exemple, HBase est construit sur la base de HDFS et Spark peut également utiliser HDFS comme l'une de ses sources de données. L'étude de l'architecture et des opérations de base de HDFS sera d'un grand secours pour la configuration, l'amélioration et le diagnostic de clusters particuliers.
HDFS est le stockage distribué utilisé par les applications Hadoop, la source de données et la destination des données. Les clusters HDFS sont principalement composés de NameNodes qui gèrent les métadonnées du système de fichiers et de DataNodes qui stockent les données réelles. L'architecture est représentée dans la figure suivante qui montre les modèles d'interaction entre les NameNodes, les DataNodes et les Clients :
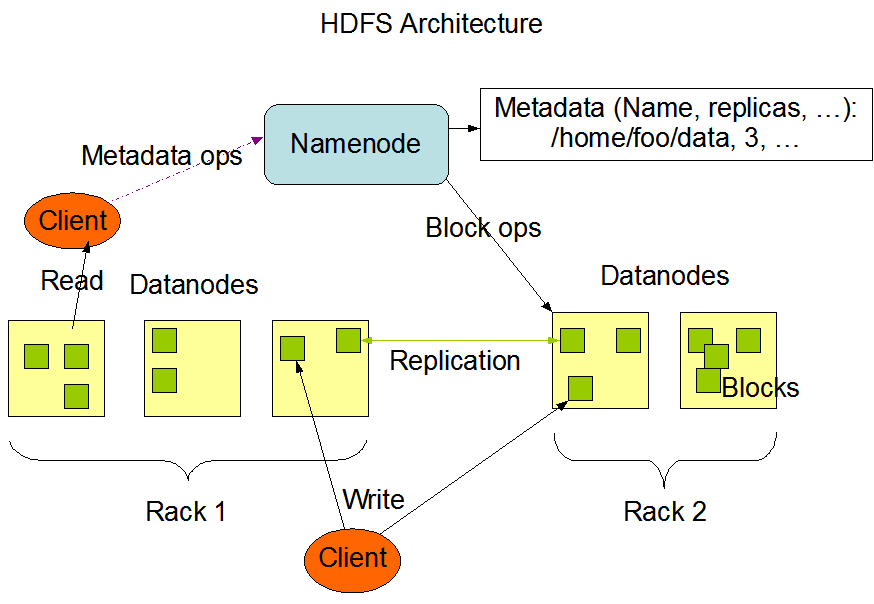 Cette figure est extraite du site web officiel de Hadoop.
Cette figure est extraite du site web officiel de Hadoop.
Résumé de l'introduction à HDFS :
- Vue d'ensemble de HDFS : HDFS (Hadoop Distributed File System) est un composant de stockage distribué tolérant aux pannes et évolutif dans le cadre de Hadoop.
- Architecture : Les clusters HDFS sont composés de NameNodes pour gérer les métadonnées et de DataNodes pour stocker les données réelles. L'architecture suit un modèle Maître/Espion avec un seul NameNode et plusieurs DataNodes.
- Stockage de fichiers : Les fichiers dans HDFS sont divisés en blocs stockés sur différents DataNodes, avec une taille de bloc par défaut de 64 Mo.
- Opérations : Le NameNode gère les opérations d'espace de noms du système de fichiers, tandis que les DataNodes gèrent les requêtes de lecture et d'écriture des clients.
- Interactions : Les clients communiquent avec le NameNode pour les métadonnées et interagissent directement avec les DataNodes pour les données de fichiers.
- Déploiement : En général, un seul nœud dédié exécute le NameNode, tandis que chaque autre nœud exécute une instance de DataNode. HDFS est construit à l'aide de Java, offrant une portabilité entre différents environnements.
La compréhension de ces points clés sur HDFS aidera à configurer, optimiser et diagnostiquer efficacement les clusters Hadoop.
Le résumé du système de fichiers
Espace de noms du système de fichiers
- Organisation hiérarchique : Tant HDFS que les systèmes de fichiers traditionnels Linux prennent en charge l'organisation hiérarchique des fichiers avec une structure d'arborescence de dossiers, permettant aux utilisateurs et aux applications de créer des dossiers et de stocker des fichiers.
- Accès et opérations : Les utilisateurs peuvent interagir avec HDFS grâce à diverses interfaces d'accès telles que les lignes de commande et les API, permettant des opérations telles que la création, la suppression, le déplacement et le renommage de fichiers.
- Prise en charge des fonctionnalités : À partir de la version 3.3.6, HDFS ne met pas en œuvre de quotas utilisateur, de droits d'accès, de liens durs ou de liens symboliques. Cependant, des versions futures peuvent prendre en charge ces fonctionnalités, car l'architecture permet leur implémentation.
- Gestion du NameNode : Le NameNode dans HDFS gère toutes les modifications de l'espace de noms du système de fichiers et des propriétés, y compris la gestion du facteur de réplication des fichiers, qui spécifie le nombre de copies d'un fichier à maintenir sur HDFS.
Copie de données
Au début du développement, HDFS a été conçu pour stocker des fichiers très volumineux dans un grand cluster de manière transnœud et hautement fiable. Comme mentionné précédemment, HDFS stocke les fichiers en blocs. Plus précisément, il stocke chaque fichier comme une séquence de blocs. Sauf le dernier bloc, tous les blocs dans le fichier sont de la même taille.
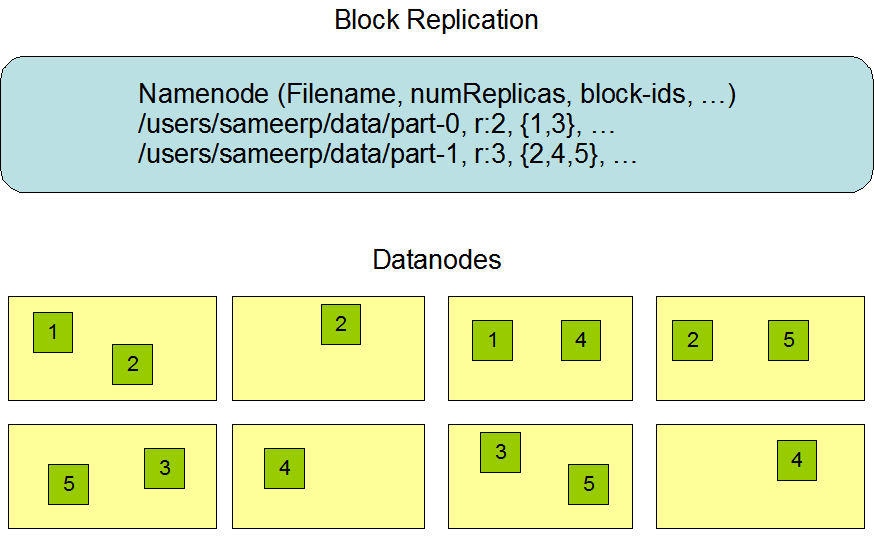 Cette figure est extraite du site web officiel de Hadoop.
Cette figure est extraite du site web officiel de Hadoop.
La réplication de données et la haute disponibilité d'HDFS :
- Réplication de données : Dans HDFS, les fichiers sont divisés en blocs qui sont répliqués sur plusieurs DataNodes pour assurer la tolérance aux pannes. Le facteur de réplication peut être spécifié lors de la création ou de la modification du fichier, chaque fichier ayant un seul écrivain à un moment donné.
- Gestion de la réplication : Le NameNode gère la manière dont les blocs de fichiers sont copiés en recevant des rapports de battement de cœur et d'état de bloc des DataNodes. Les DataNodes rapportent leur état de fonctionnement via des battements de cœur, et les rapports d'état de bloc contiennent des informations sur tous les blocs stockés sur le DataNode.
- Haute disponibilité : HDFS offre un certain degré de haute disponibilité en restaurant automatiquement des copies de fichiers perdues à partir d'autres parties du cluster en cas de corruption de disque ou d'autres pannes. Ce mécanisme aide à maintenir l'intégrité et la fiabilité des données dans le système de stockage distribué.
Persistance des métadonnées du système de fichiers
- Gestion de l'espace de noms : L'espace de noms d'HDFS, contenant les métadonnées du système de fichiers, est stocké dans le NameNode. Chaque modification des métadonnées du système de fichiers est enregistrée dans un EditLog, qui persiste les transactions telles que la création de fichiers. L'EditLog est stocké dans le système de fichiers local.
- FsImage : L'ensemble de l'espace de noms du système de fichiers, y compris la correspondance entre blocs et fichiers et les attributs, est stocké dans un fichier appelé FsImage. Ce fichier est également enregistré dans le système de fichiers local où réside le NameNode.
- Processus de point de contrôle : Le processus de point de contrôle consiste à lire l'FsImage et l'EditLog à partir du disque au démarrage du NameNode. Toutes les transactions dans l'EditLog sont appliquées à l'FsImage en mémoire, qui est ensuite enregistré à nouveau sur le disque pour la persistance. Après ce processus, l'ancien EditLog peut être tronqué. Dans la version actuelle (3.3.6), les points de contrôle ne se produisent que lors du démarrage du NameNode, mais des versions futures peuvent introduire des points de contrôle périodiques pour améliorer la fiabilité et la cohérence des données.
Autres fonctionnalités
- Fondé sur TCP/IP : Tous les protocoles de communication dans HDFS sont construits sur le protocole TCP/IP, assurant un échange de données fiable entre les nœuds dans le système de fichiers distribué.
- Protocole client : La communication entre le client et le NameNode est facilitée grâce au Protocole client. Le client initie une connexion à des ports TCP configurables sur le NameNode pour interagir avec les métadonnées du système de fichiers.
- Protocole DataNode : La communication entre les DataNodes et le NameNode repose sur le Protocole DataNode. Les DataNodes communiquent avec le NameNode pour rapporter leur état, envoyer des signaux de battement de cœur et transférer des blocs de données en tant que partie du système de stockage distribué.
- Appel de procédure distante (RPC) : Le Protocole client et le Protocole DataNode sont tous deux abstraits à l'aide de mécanismes d'appel de procédure distante (RPC). Le NameNode répond aux requêtes RPC initiées par les DataNodes ou les clients, jouant un rôle passif dans le processus de communication.
Voici quelques documents pour une lecture approfondie :
Changer d'utilisateur
Avant d'écrire le code de la tâche, vous devriez d'abord basculer sur l'utilisateur hadoop. Double-cliquez pour ouvrir le terminal Xfce sur votre bureau et entrez la commande suivante. Le mot de passe de l'utilisateur hadoop est hadoop ; il sera nécessaire lors du changement d'utilisateur :
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
Astuce : le mot de passe de l'utilisateur hadoop est hadoop
Initialisation de HDFS
Le Namenode doit être initialisé avant d'utiliser HDFS pour la première fois. Cette opération peut être comparée au formatage d'un disque, donc utilisez cette commande avec prudence lorsque vous stockez des données sur HDFS.
Sinon, redémarrez l'expérience dans cette section. Utilisez l'"Environnement par défaut" et initialisez HDFS avec la commande suivante :
/home/hadoop/hadoop/bin/hdfs namenode -format
Astuce : La commande ci-dessus va formater le système de fichiers HDFS, vous devez supprimer le répertoire de données HDFS avant d'exécuter la commande.
Donc, vous devez arrêter les services relatifs à Hadoop et supprimer les données Hadoop.
stop-all.sh
rm -rf ~/hadoopdata
Lorsque vous voyez le message suivant, l'initialisation est terminée :
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Importation de fichiers
Puisque HDFS est un système de stockage distribué hiérarchisé ( distributed storage system ) construit sur des disques locaux, vous devez importer des données dans celui-ci avant de l'utiliser.
La première et la manière la plus pratique de préparer quelques fichiers est d'utiliser le fichier de configuration d'Hadoop comme exemple.
Tout d'abord, vous devez démarrer le démon HDFS :
/home/hadoop/hadoop/sbin/start-dfs.sh
Vérifiez les services :
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
Créez un répertoire et copiez les données en entrant la commande suivante dans le terminal :
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
Liste le contenu du répertoire :
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
Toute opération sur HDFS commence par hdfs dfs et est complétée par les paramètres d'opération correspondants. Le paramètre le plus couramment utilisé est put, qui est utilisé comme suit et peut être entré dans le terminal :
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
Liste le contenu du répertoire :
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
Le dernier /policy.xml de la commande signifie que le nom de fichier stocké dans HDFS est policy.xml et le chemin est / (répertoire racine). Si vous voulez continuer à utiliser le nom de fichier précédent, vous pouvez spécifier directement le chemin /.
Si vous devez télécharger plusieurs fichiers, vous pouvez spécifier continuellement le chemin d'accès au répertoire local et terminer avec le chemin de stockage cible HDFS :
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
Liste le contenu du répertoire :
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
Pour spécifier les paramètres liés au chemin, les règles sont les mêmes que celles du système Linux. Vous pouvez utiliser des caractères joker (tels que *.sh) pour simplifier l'opération.
Opérations sur les fichiers
De manière similaire, vous pouvez utiliser le paramètre -ls pour lister les fichiers dans le répertoire spécifié :
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
Les fichiers listés ici peuvent varier selon l'environnement d'expérience.
Si vous avez besoin de voir le contenu d'un fichier, vous pouvez utiliser le paramètre cat. La chose la plus simple à imaginer est de spécifier directement un chemin de fichier sur HDFS. Si vous avez besoin de comparer des répertoires locaux avec des fichiers sur HDFS, vous pouvez spécifier leurs chemins séparément. Cependant, il est important de noter que le répertoire local doit commencer par l'indicateur file://, suivi du chemin du fichier (par exemple /home/hadoop/.bashrc, n'oubliez pas le / au début). Sinon, tout chemin spécifié ici sera considéré par défaut comme un chemin sur HDFS :
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
La sortie est la suivante :
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
Si vous avez besoin de copier un fichier dans un autre chemin, vous pouvez utiliser le paramètre cp :
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
De manière similaire, si vous avez besoin de déplacer un fichier, utilisez le paramètre mv. Cela est globalement identique au format de commande du système de fichiers Linux :
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
Utilisez le paramètre lsr pour lister le contenu du répertoire actuel, y compris le contenu des sous-répertoires. La sortie est la suivante :
hdfs dfs -lsr /
Si vous voulez ajouter du nouveau contenu à un fichier sur HDFS, vous pouvez utiliser le paramètre appendToFile. Et, lorsqu'il s'agit de spécifier le chemin du fichier local à ajouter, vous pouvez en spécifier plusieurs. Le dernier paramètre sera l'objet auquel ajouter le contenu. Le fichier doit exister sur HDFS, sinon une erreur sera signalée :
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
Vous pouvez utiliser le paramètre tail pour voir le contenu de la fin du fichier (la partie finale du fichier) pour confirmer si l'ajout a été réussi :
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
Voyez la sortie de la commande tail :
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
Si vous avez besoin de supprimer un fichier ou un répertoire, utilisez le paramètre rm. Ce paramètre peut également être accompagné de -r et -f, qui ont les mêmes significations qu'ils ont pour la commande rm du système de fichiers Linux :
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
Le contenu du fichier moved_file.txt sera supprimé, et la commande retournera la sortie suivante 'Supprimé /moved_file.txt'
Opérations sur les répertoires
Dans le contenu précédent, nous avons appris comment créer un répertoire dans HDFS. En fait, si vous avez besoin de créer plusieurs répertoires d'un coup, vous pouvez directement spécifier les chemins de plusieurs répertoires en tant que paramètres. Le paramètre -p indique que son répertoire parent sera créé automatiquement s'il n'existe pas :
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
Si vous voulez voir combien d'espace occupe un certain fichier ou répertoire, vous pouvez utiliser le paramètre du :
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
La sortie est la suivante :
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
Exportation de fichiers
Dans la section précédente, nous avons principalement présenté les opérations sur les fichiers et les répertoires dans HDFS. Si une application telle que MapReduce est exécutée et que le fichier enregistrant le résultat est généré, vous pouvez utiliser le paramètre get pour l'exporter dans le répertoire local du système Linux.
Le premier paramètre de chemin ici fait référence au chemin dans HDFS, et le dernier chemin fait référence au chemin enregistré dans le répertoire local :
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
Si l'exportation est réussie, vous pouvez trouver le fichier dans votre répertoire local :
cd ~
ls
La sortie est la suivante :
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Opération Web Hadoop
Interface de gestion Web
Chaque NameNode ou DataNode exécute un serveur Web interne qui affiche des informations de base telles que l'état actuel du cluster. Dans la configuration par défaut, la page d'accueil du NameNode est http://localhost:9870/. Elle liste les statistiques de base pour les DataNodes et le cluster.
Ouvrez un navigateur Web et entrez le suivant dans la barre d'adresse :
http://localhost:9870/
Vous pouvez voir le nombre de nœuds DataNode actifs dans le "cluster" actuel dans Résumé :
L'interface Web peut également être utilisée pour explorer les répertoires et les fichiers à l'intérieur de HDFS. Dans la barre de menu en haut, cliquez sur le lien “Explorer le système de fichiers” sous “Outils” :
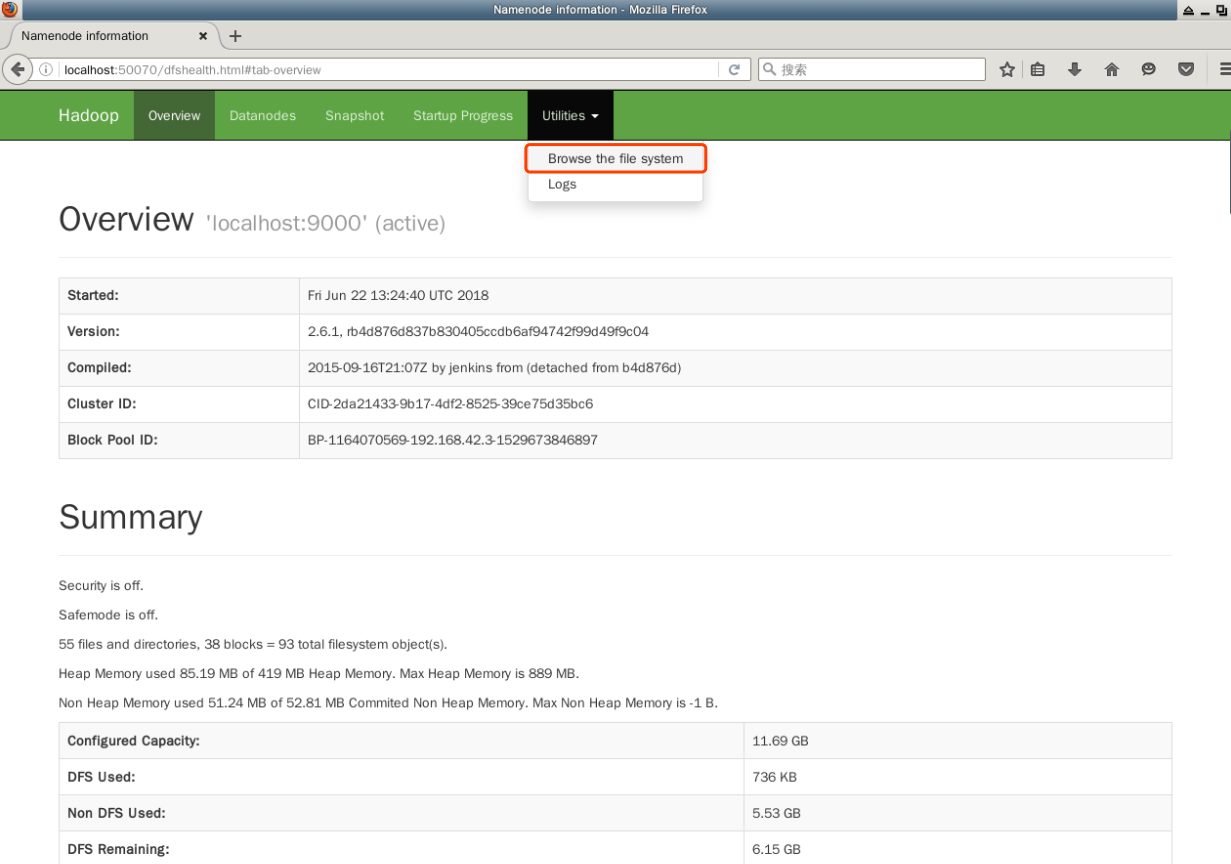
Fermer un cluster Hadoop
Maintenant, nous avons terminé l'introduction de certaines des opérations de base de WebHDFS. Plus d'instructions peuvent être trouvées dans la documentation de WebHDFS. Ce laboratoire est maintenant terminé. Par habitude, nous devons toujours arrêter le cluster Hadoop :
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
Résumé
Ce laboratoire a présenté l'architecture de HDFS. De plus, nous avons appris les commandes de base d'opération de HDFS à partir de la ligne de commande puis avons passé à la modalité d'accès Web à HDFS, ce qui aidera HDFS à fonctionner comme un véritable service de stockage pour les applications externes.
Ce laboratoire ne liste aucun scénario de suppression de fichiers dans WebHDFS. Vous pouvez vérifier la documentation vous-même. Plus de fonctionnalités sont cachées dans la documentation officielle, assurez-vous donc de garder l'habitude de lire la documentation.
Voici le matériel pour la lecture supplémentaire :


