
介绍
欢迎来到本次关于使用 scikit-learn 进行 K-近邻 (K-Nearest Neighbors, KNN) 分类的实践实验!Scikit-learn 是一个强大且流行的 Python 机器学习库。KNN 算法是最简单但有效的分类算法之一。它根据特征空间中“k”个最近邻居的多数类来对新的数据点进行分类。在本实验中,你将完成构建机器学习模型的完整流程:加载著名的 Iris 数据集,将其划分为训练集和测试集,初始化并训练 KNN 分类器,最后使用训练好的模型对新的、未见过的数据进行预测。完成本实验后,你将对 scikit-learn 中的监督学习基本工作流程有扎实的理解。
使用 datasets.load_iris() 加载 Iris 数据集
在此步骤中,你将开始加载所需的数据集。我们将使用经典的 Iris 数据集,该数据集方便地包含在 scikit-learn 中。首先,你需要从 sklearn 导入 datasets 模块。然后,调用 load_iris() 函数来获取数据。
理解 load_iris():
- 返回类型:返回一个
Bunch对象(类似于字典),其中包含:.data:特征矩阵(150 个样本 × 4 个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度).target:标签数组(物种:0=setosa、1=versicolor、2=virginica).feature_names:4 个特征的名称.target_names:3 个物种的名称
- 目的:提供一个干净、可直接使用的用于分类练习的数据集
我们将按照机器学习中的常见约定,将它们分别赋值给变量 X 和 y(X 代表特征,y 代表标签)。
在左侧编辑器中打开 main.py 文件,并添加以下代码。
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Assign features to X and labels to y
X = iris.data
y = iris.target
## You can print the shape to see the dimensions
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
现在,从终端运行脚本以查看输出。
python3 main.py
你应该会看到特征矩阵和标签向量的维度。
Features shape: (150, 4)
Labels shape: (150,)
这表明我们有 150 个样本(花朵),每个样本有 4 个特征。
使用 sklearn.model_selection 中的 train_test_split 将数据分割为训练集和测试集
在此步骤中,你将把数据集划分为两部分:训练集和测试集。这是机器学习中评估模型在未见过数据上性能的关键步骤。
理解 train_test_split() 参数:
- **
test_size=0.3**:预留 30% 的数据用于测试,70% 用于训练 - **
random_state=42**:确保可复现的划分(每次运行使用相同的随机种子) - 目的:通过在未见过的数据上评估模型来防止过拟合
- 输出:返回四个数组:X_train, X_test, y_train, y_test
我们使用训练集来训练模型,然后使用测试集来测试其预测能力。Scikit-learn 提供了一个名为 train_test_split 的便捷函数来实现此目的。你需要从 sklearn.model_selection 导入它。
将以下代码添加到你的 main.py 文件末尾。
from sklearn.model_selection import train_test_split
## Split data into training and testing sets
## test_size=0.3 means 30% of the data will be used for testing
## random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Print the shapes of the new sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
现在,再次运行脚本。
python3 main.py
输出现在将包含你的训练集和测试集的形状。
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
使用 sklearn.neighbors 中的 KNeighborsClassifier 初始化,设置 n_neighbors=3
在此步骤中,你将初始化 K-Nearest Neighbors 分类器。KNN 的核心思想是通过查看数据点的“k”个最近邻居的类别来预测其类别。
理解 KNeighborsClassifier() 参数:
- **
n_neighbors=3**:用于预测的最近邻居数量- 较小的值(例如 1-3):对噪声更敏感,可能导致过拟合
- 较大的值(例如 5-7):更平滑的决策边界,更鲁棒
- 算法行为:在预测时,找到 k 个最近的训练点并使用多数投票
- 无训练阶段:KNN 是一个“懒惰学习者”(lazy learner)——它存储训练数据并在预测时进行计算
KNeighborsClassifier 是 scikit-learn 中实现此算法的类。你需要从 sklearn.neighbors 导入它。让我们创建一个分类器对象并将其命名为 clf。
将以下代码添加到你的 main.py 文件末尾。
from sklearn.neighbors import KNeighborsClassifier
## Initialize the KNN classifier with n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
此代码不会产生任何输出,但它会在内存中创建分类器对象,为下一步的训练做好准备。
使用 clf.fit(X_train, y_train) 拟合分类器
在此步骤中,你将使用训练数据来训练或“拟合”分类器。对于 KNN 算法,其“训练”阶段非常简单:它只是存储整个训练数据集(X_train 和 y_train)。
理解 .fit() 方法:
- 输入参数:
X_train(特征矩阵),y_train(目标标签) - 作用:将训练数据存储在内存中,供后续预测使用
- KNN 特性:与其他算法不同,KNN 在拟合过程中不学习参数
- 目的:为模型在新数据上进行预测做好准备
当需要对新数据点进行预测时,算法会在存储的数据集中找到“k”个最近的点并做出决策。在 scikit-learn 中训练模型,你需要使用分类器对象的 .fit() 方法。该方法将训练特征(X_train)和相应的训练标签(y_train)作为参数。
将以下代码行添加到 main.py 的末尾。
## Train the classifier using the training data
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
添加代码后,运行脚本。
python3 main.py
你将看到一条确认消息,表明分类器已成功训练。
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
使用 clf.predict(X_test) 预测类别
在最后一步中,你将使用训练好的分类器对测试数据进行预测。现在模型已经从训练数据中“学习”了,我们可以将它从未见过的测试集特征(X_test)提供给它,并让它为每个样本预测类别。
理解 .predict() 方法:
- 输入参数:
X_test(未见过数据的特征矩阵) - 算法过程:对于每个测试样本,在训练数据中找到 k 个最近邻居并使用多数投票
- 输出:预测的类别标签数组(长度与输入样本相同)
- 距离度量:默认使用欧氏距离(Euclidean distance)来衡量点之间的相似性
- 目的:评估模型在新、未见过数据上的性能
这是通过 .predict() 方法完成的。该方法将测试特征(X_test)作为输入,并返回一个预测标签的数组。我们将这些预测存储在一个名为 predictions 的变量中,并将其打印到控制台。你也可以打印实际标签(y_test)来查看模型的表现如何。
将最后一段代码添加到你的 main.py 文件中。
## Make predictions on the test data
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
现在,运行完整的脚本。
python3 main.py
你将看到测试集的预测类别标签数组,后面跟着真实标签的数组。
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
注意:此处显示了完整的输出数组。通过比较这两个数组,你可以看到预测结果与实际标签完全匹配,这表明模型在此测试集上的性能非常出色。
可视化 KNN 分类结果
在此附加步骤中,你将创建可视化图表,以更好地理解你的 KNN 分类结果。可视化有助于你了解模型的性能如何以及 KNN 算法创建的决策边界。
理解分类中的数据可视化:
- 散点图:显示特征之间的关系以及类别的分布情况
- 颜色编码:不同的颜色代表不同的类别(物种)
- 训练数据 vs 测试数据:有助于理解模型的泛化能力
- 预测准确率:预测标签与实际标签的可视化比较
将以下代码添加到 main.py 文件的末尾以创建可视化图表:
import matplotlib.pyplot as plt
import numpy as np
## Create subplots for multiple visualizations
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## Plot 1: Training data with different colors for each class
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## Plot 2: Test data predictions vs actual labels
## Create a comparison: correct predictions vs incorrect ones
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Plot correct predictions
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Plot incorrect predictions with different marker
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## Create legend
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## Additional: Show prediction accuracy
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
运行更新后的脚本:
python3 main.py
你应该会看到包含以下内容的输出:
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
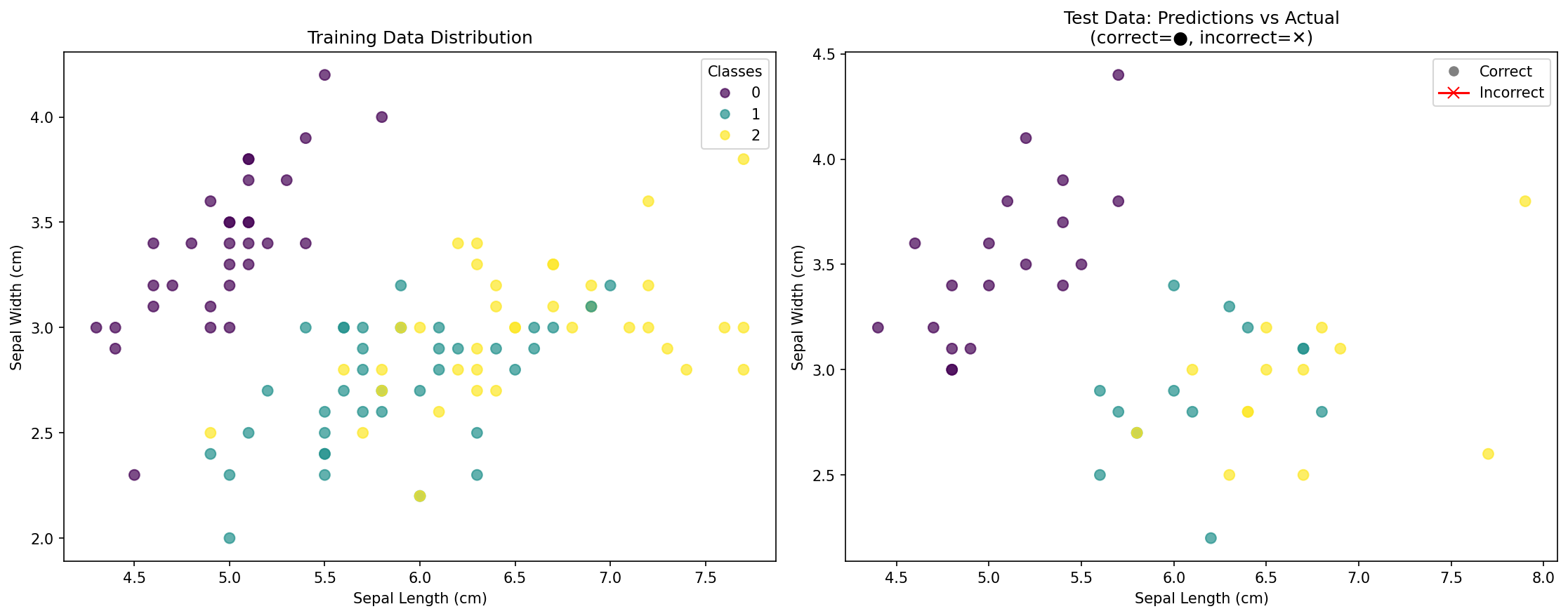
可视化图表显示的内容:
- 左侧图表:训练数据点的分布,按实际物种进行颜色编码
- 右侧图表:测试数据点显示:
- 圆圈(●):正确分类的点
- 叉号(✕):错误分类的点(如果有)
- 准确率分数:正确预测的总百分比
此可视化图表帮助你理解:
- 类别在特征空间中的分布情况
- 你的模型是否过拟合或泛化良好
- 哪些区域可能对分类构成挑战
- 你的 KNN 模型在视觉上的有效性
总结
恭喜你完成了这个实验!你已经成功使用 scikit-learn 构建并训练了一个 K-近邻(K-Nearest Neighbors)分类模型。你已经学习了监督式机器学习项目的基本工作流程,包括:
- 使用
sklearn.datasets加载数据集。 - 使用
train_test_split将数据分割成训练集和测试集。 - 初始化一个分类器,在本例中是
KNeighborsClassifier。 - 使用
.fit()方法在训练数据上训练模型。 - 使用
.predict()方法对新的、未见过的数据进行预测。 - 可视化结果以理解模型性能和决策模式。
这个过程构成了许多机器学习任务的基础。从这里开始,你可以探索如何使用准确率(accuracy)、精确率(precision)和召回率(recall)等指标来更正式地评估你的模型性能,或者尝试不同的 n_neighbors 值,看看它如何影响结果。你还可以尝试可视化决策边界,或者在你的 KNN 分类器中使用不同的距离度量。


