
はじめに
この実験(Lab)では、PostgreSQL のテーブル作成とデータ型について学びます。目標は、整数型、テキスト型、日付型、ブール型などの基本的なデータ型を理解することです。これらのデータ型は、テーブル構造を定義し、データの整合性を確保するために非常に重要です。
psql を使用して PostgreSQL データベースに接続し、SERIAL を使用して主キーを持つテーブルを作成し、NOT NULL や UNIQUE などの基本的な制約を追加します。その後、テーブル構造を調べ、INTEGER、SMALLINT、TEXT、VARCHAR(n)、CHAR(n) などのさまざまなデータ型の使用法を示すためにデータを挿入します。
PostgreSQL のデータ型を調査する
このステップでは、PostgreSQL で利用可能な基本的なデータ型をいくつか探ります。データ型を理解することは、テーブル構造を定義し、データの整合性を確保するために非常に重要です。整数型、テキスト型、日付型、ブール型などの一般的な型について説明します。
まず、PostgreSQL データベースに接続しましょう。ターミナルを開き、psql コマンドを使用して、postgres ユーザーとして postgres データベースに接続します。postgres ユーザーはデフォルトのスーパーユーザーであるため、最初に sudo を使用してそのユーザーに切り替える必要がある場合があります。
sudo -u postgres psql
これで、PostgreSQL のインタラクティブターミナルに入ります。postgres=# のようなプロンプトが表示されます。
次に、いくつかの基本的なデータ型を探ります。
1. 整数型 (Integer Types):
PostgreSQL は、さまざまな範囲の整数型を提供します。最も一般的なのは、INTEGER (または INT) と SMALLINT です。
INTEGER: ほとんどの整数値の典型的な選択肢です。SMALLINT: より小さい整数値を格納してスペースを節約するために使用されます。
これらの型を示す簡単なテーブルを作成しましょう。
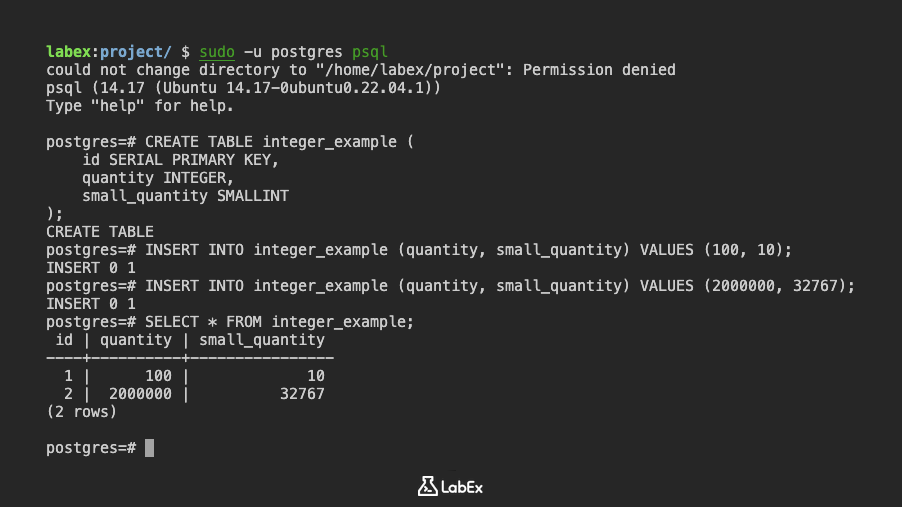
CREATE TABLE integer_example (
id SERIAL PRIMARY KEY,
quantity INTEGER,
small_quantity SMALLINT
);
ここで、SERIAL は整数のシーケンスを自動的に生成する特別な型であり、主キーに適しています。
次に、いくつかのデータを挿入します。
INSERT INTO integer_example (quantity, small_quantity) VALUES (100, 10);
INSERT INTO integer_example (quantity, small_quantity) VALUES (2000000, 32767);
次のコマンドを使用してデータを表示できます。
SELECT * FROM integer_example;
出力:
id | quantity | small_quantity
----+----------+----------------
1 | 100 | 10
2 | 2000000 | 32767
(2 rows)
2. テキスト型 (Text Types):
PostgreSQL は、テキストを格納するために TEXT、VARCHAR(n)、および CHAR(n) を提供します。
TEXT: 無制限の長さの可変長文字列を格納します。VARCHAR(n): 最大長がnの可変長文字列を格納します。CHAR(n): 長さnの固定長文字列を格納します。文字列が短い場合は、スペースで埋められます。
別のテーブルを作成しましょう。
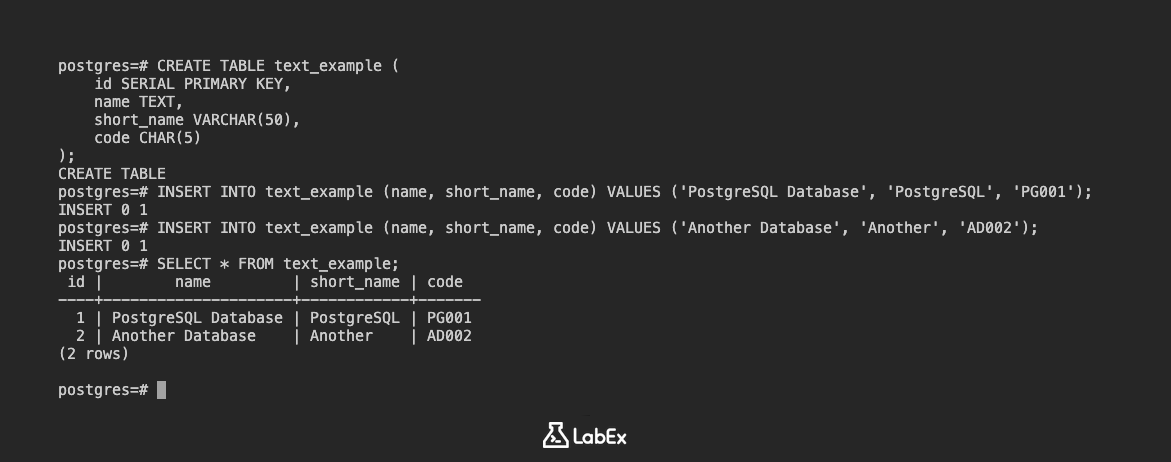
CREATE TABLE text_example (
id SERIAL PRIMARY KEY,
name TEXT,
short_name VARCHAR(50),
code CHAR(5)
);
いくつかのデータを挿入します。
INSERT INTO text_example (name, short_name, code) VALUES ('PostgreSQL Database', 'PostgreSQL', 'PG001');
INSERT INTO text_example (name, short_name, code) VALUES ('Another Database', 'Another', 'AD002');
データを表示します。
SELECT * FROM text_example;
出力:
id | name | short_name | code
----+--------------------+------------+-------
1 | PostgreSQL Database | PostgreSQL | PG001
2 | Another Database | Another | AD002
(2 rows)
3. 日付と時刻型 (Date and Time Types):
PostgreSQL は、日付と時刻の値を処理するために DATE、TIME、TIMESTAMP、および TIMESTAMPTZ を提供します。
DATE: 日付 (年、月、日) のみを格納します。TIME: 時刻 (時、分、秒) のみを格納します。TIMESTAMP: タイムゾーン情報なしで日付と時刻の両方を格納します。TIMESTAMPTZ: タイムゾーン情報付きで日付と時刻の両方を格納します。
テーブルを作成します。
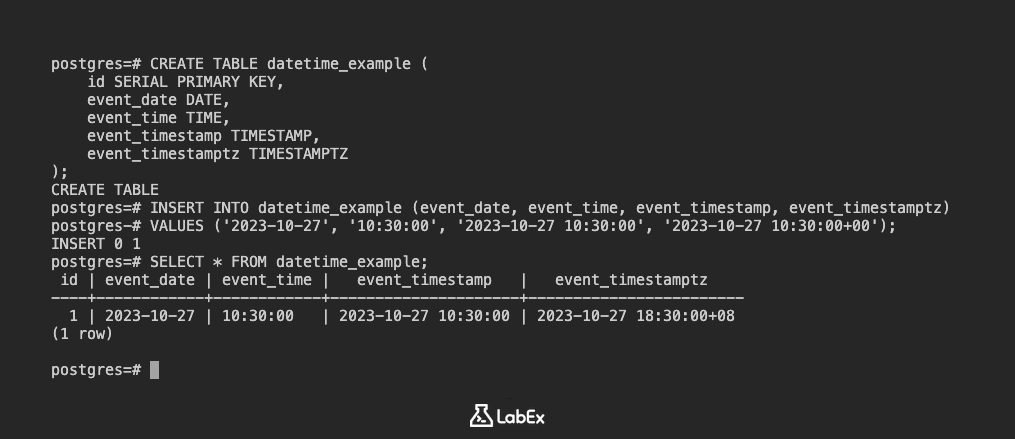
CREATE TABLE datetime_example (
id SERIAL PRIMARY KEY,
event_date DATE,
event_time TIME,
event_timestamp TIMESTAMP,
event_timestamptz TIMESTAMPTZ
);
データを挿入します。
INSERT INTO datetime_example (event_date, event_time, event_timestamp, event_timestamptz)
VALUES ('2023-10-27', '10:30:00', '2023-10-27 10:30:00', '2023-10-27 10:30:00+00');
データを表示します。
SELECT * FROM datetime_example;
出力:
id | event_date | event_time | event_timestamp | event_timestamptz
----+------------+------------+---------------------+----------------------------
1 | 2023-10-27 | 10:30:00 | 2023-10-27 10:30:00 | 2023-10-27 10:30:00+00
(1 row)
4. ブール型 (Boolean Type):
BOOLEAN 型は、true/false の値を格納します。
テーブルを作成します。
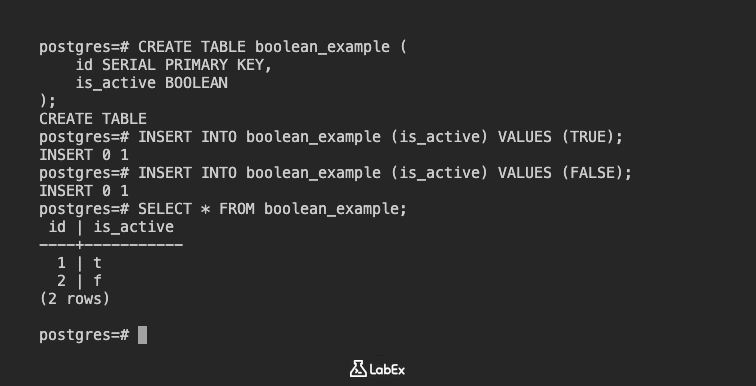
CREATE TABLE boolean_example (
id SERIAL PRIMARY KEY,
is_active BOOLEAN
);
データを挿入します。
INSERT INTO boolean_example (is_active) VALUES (TRUE);
INSERT INTO boolean_example (is_active) VALUES (FALSE);
データを表示します。
SELECT * FROM boolean_example;
出力:
id | is_active
----+-----------
1 | t
2 | f
(2 rows)
最後に、psql ターミナルを終了します。
\q
これで、PostgreSQL の基本的なデータ型をいくつか調べました。これらのデータ型は、堅牢で適切に定義されたデータベーススキーマを作成するための構成要素となります。
主キーを持つテーブルの作成
このステップでは、PostgreSQL で主キーを持つテーブルを作成する方法を学びます。主キーは、テーブル内の各行を一意に識別する列または列のセットです。一意性を強制し、データの整合性およびテーブル間のリレーションシップにとって重要な要素として機能します。
まず、PostgreSQL データベースに接続しましょう。ターミナルを開き、psql コマンドを使用して、postgres ユーザーとして postgres データベースに接続します。
sudo -u postgres psql
これで、PostgreSQL のインタラクティブターミナルに入ります。
主キーの理解
主キーには、次の特性があります。
- 一意の値を含める必要があります。
NULL値を含めることはできません。- テーブルには 1 つの主キーのみを設定できます。
主キーを持つテーブルの作成
テーブルを作成するときに主キーを定義するには、次の 2 つの一般的な方法があります。
列定義内で
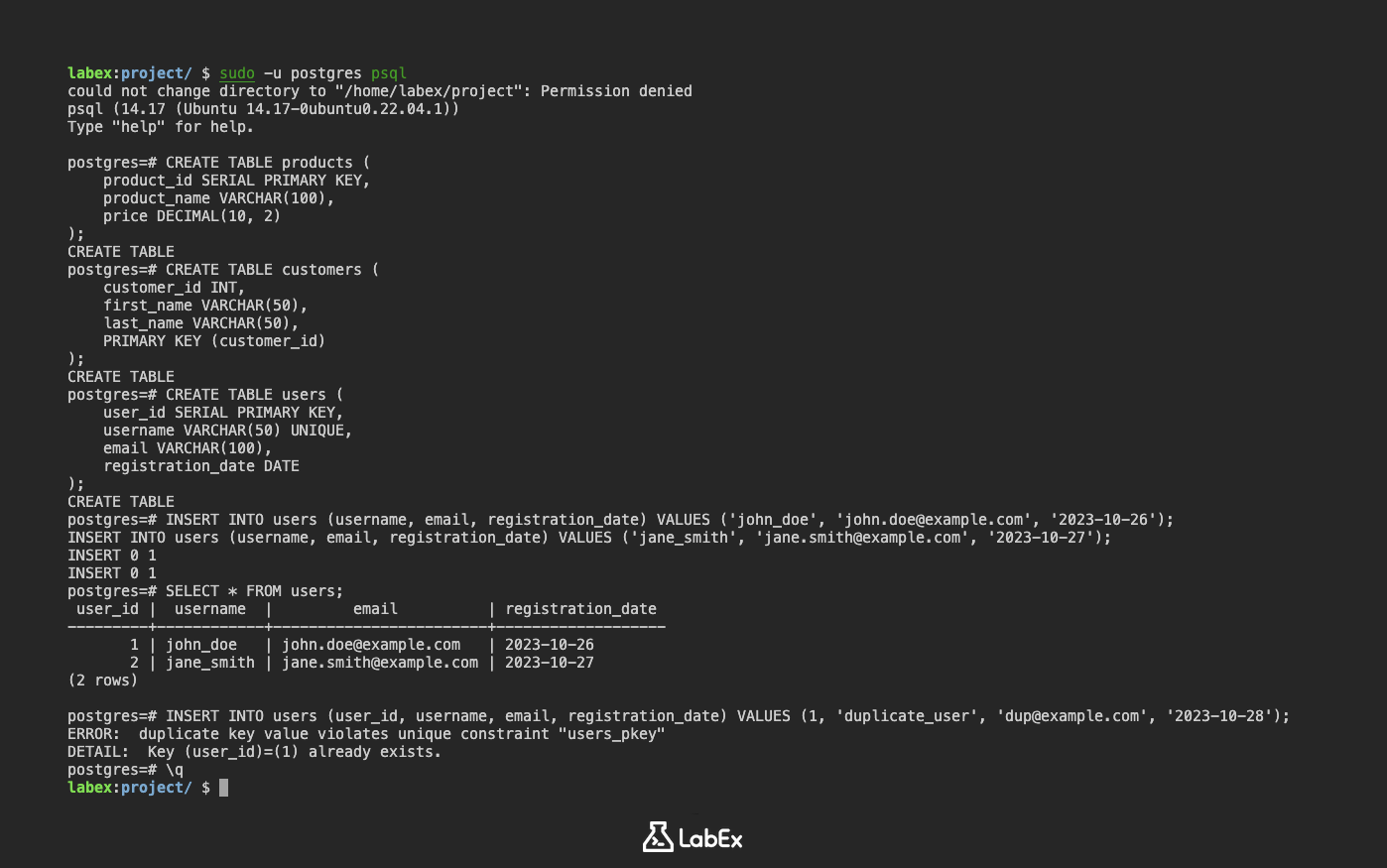
PRIMARY KEY制約を使用する:CREATE TABLE products ( product_id SERIAL PRIMARY KEY, product_name VARCHAR(100), price DECIMAL(10, 2) );この例では、
product_idはPRIMARY KEY制約を使用して主キーとして定義されています。SERIALキーワードは、product_idの一意の整数値を生成するためのシーケンスを自動的に作成します。PRIMARY KEY制約を個別に使用する:CREATE TABLE customers ( customer_id INT, first_name VARCHAR(50), last_name VARCHAR(50), PRIMARY KEY (customer_id) );ここでは、
PRIMARY KEY制約が個別に定義されており、customer_id列が主キーであることを指定しています。
例:主キーを持つ users テーブルの作成
自動 ID 生成のために SERIAL 型を使用して、主キーを持つ users テーブルを作成しましょう。
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE,
email VARCHAR(100),
registration_date DATE
);
このテーブルでは:
user_idは主キーであり、SERIALを使用して自動的に生成されます。usernameは、各ユーザーの一意のユーザー名です。emailは、ユーザーのメールアドレスです。registration_dateは、ユーザーが登録した日付です。
次に、users テーブルにいくつかのデータを挿入しましょう。
INSERT INTO users (username, email, registration_date) VALUES ('john_doe', 'john.doe@example.com', '2023-10-26');
INSERT INTO users (username, email, registration_date) VALUES ('jane_smith', 'jane.smith@example.com', '2023-10-27');
次のコマンドを使用してデータを表示できます。
SELECT * FROM users;
出力:
user_id | username | email | registration_date
---------+------------+---------------------+---------------------
1 | john_doe | john.doe@example.com | 2023-10-26
2 | jane_smith | jane.smith@example.com | 2023-10-27
(2 rows)
重複する主キーを挿入しようとする
重複する主キーを持つ行を挿入しようとすると、PostgreSQL はエラーを発生させます。
INSERT INTO users (user_id, username, email, registration_date) VALUES (1, 'duplicate_user', 'dup@example.com', '2023-10-28');
出力:
ERROR: duplicate key value violates unique constraint "users_pkey"
DETAIL: Key (user_id)=(1) already exists.
これは、主キー制約が実際に機能し、重複した値を防いでいることを示しています。
最後に、psql ターミナルを終了します。
\q
これで、主キーを持つテーブルを作成し、それが一意性をどのように強制するかを観察しました。これは、データベース設計の基本的な概念です。
基本的な制約(NOT NULL、UNIQUE)の追加
このステップでは、PostgreSQL でテーブルに基本的な制約を追加する方法を学びます。制約は、データの整合性と一貫性を強制するルールです。ここでは、NOT NULL と UNIQUE という 2 つの基本的な制約に焦点を当てます。
まず、PostgreSQL データベースに接続しましょう。ターミナルを開き、psql コマンドを使用して、postgres ユーザーとして postgres データベースに接続します。
sudo -u postgres psql
これで、PostgreSQL のインタラクティブターミナルに入ります。
制約の理解
制約は、テーブルに挿入できるデータの種類を制限するために使用されます。これにより、データベース内のデータの正確性と信頼性が保証されます。
1. NOT NULL 制約
NOT NULL 制約は、列に NULL 値を含めることができないようにします。これは、特定の情報がテーブル内のすべての行に不可欠な場合に役立ちます。
2. UNIQUE 制約
UNIQUE 制約は、列内のすべての値が異なることを保証します。これは、ユーザー名やメールアドレスなど、一意の識別子または値を持つ必要がある列に役立ちます (主キーに加えて)。
テーブル作成時の制約の追加
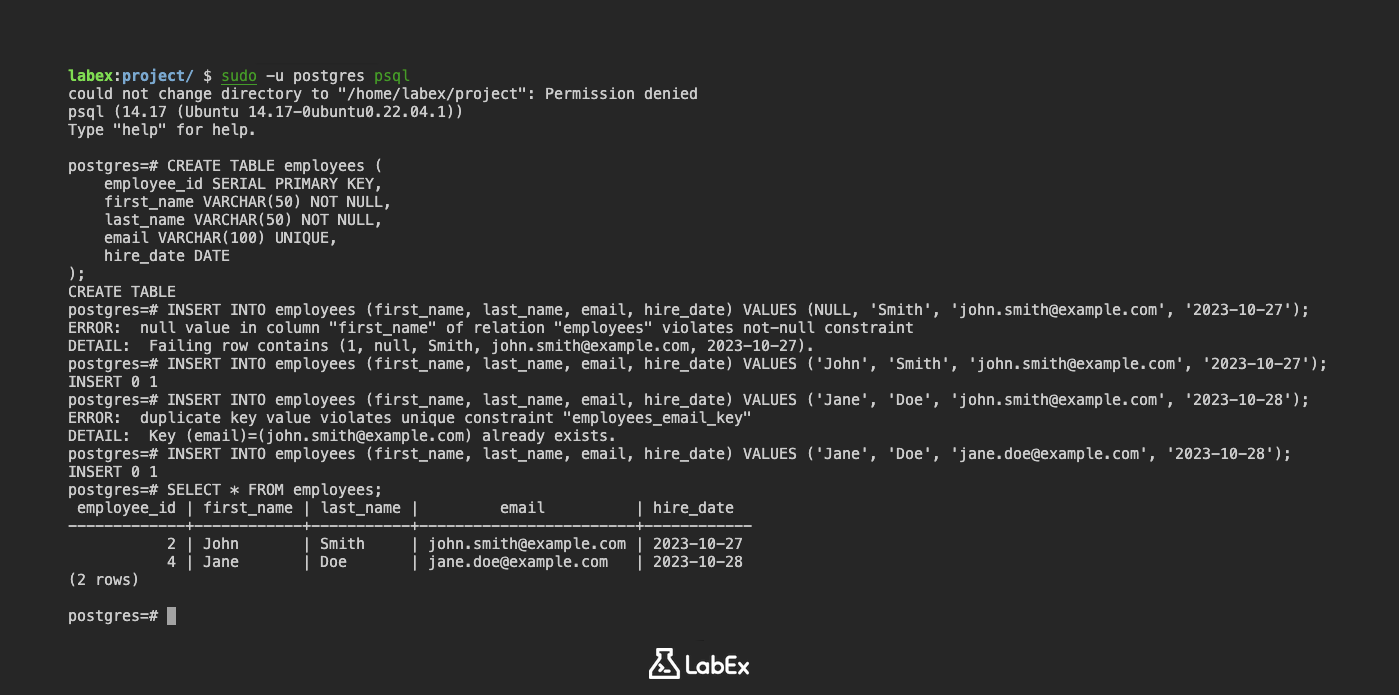
テーブルを作成するときに制約を追加できます。NOT NULL および UNIQUE 制約を持つ employees というテーブルを作成しましょう。
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE
);
このテーブルでは:
employee_idは主キーです。first_nameとlast_nameはNOT NULLとして宣言されています。つまり、すべての従業員に対して値が必要です。emailはUNIQUEとして宣言されており、各従業員が一意のメールアドレスを持つことが保証されます。
次に、これらの制約に違反するデータを挿入してみましょう。
NOT NULL 列に NULL 値を挿入しようとする:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES (NULL, 'Smith', 'john.smith@example.com', '2023-10-27');
出力:
ERROR: null value in column "first_name" of relation "employees" violates not-null constraint
DETAIL: Failing row contains (1, null, Smith, john.smith@example.com, 2023-10-27).
このエラーは、NOT NULL 制約のために、first_name 列に NULL 値を挿入できないことを示しています。
UNIQUE 列に重複した値を挿入しようとする:
まず、有効な行を挿入します。
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('John', 'Smith', 'john.smith@example.com', '2023-10-27');
次に、同じメールアドレスを持つ別の行を挿入しようとします。
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'john.smith@example.com', '2023-10-28');
出力:
ERROR: duplicate key value violates unique constraint "employees_email_key"
DETAIL: Key (email)=(john.smith@example.com) already exists.
このエラーは、UNIQUE 制約のために、重複したメールアドレスを挿入できないことを示しています。
有効なデータの挿入:
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'jane.doe@example.com', '2023-10-28');
データを表示します。
SELECT * FROM employees;
出力:
employee_id | first_name | last_name | email | hire_date
-------------+------------+-----------+---------------------+------------
1 | John | Smith | john.smith@example.com | 2023-10-27
2 | Jane | Doe | jane.doe@example.com | 2023-10-28
(2 rows)
最後に、psql ターミナルを終了します。
\q
これで、NOT NULL および UNIQUE 制約を持つテーブルを作成し、それらがデータの整合性をどのように強制するかを観察しました。
テーブル構造の確認
このステップでは、PostgreSQL でテーブルの構造を検査する方法を学びます。テーブルの構造 (列名、データ型、制約、インデックスなど) を理解することは、データを効果的にクエリおよび操作するために不可欠です。
まず、PostgreSQL データベースに接続しましょう。ターミナルを開き、psql コマンドを使用して、postgres ユーザーとして postgres データベースに接続します。
sudo -u postgres psql
これで、PostgreSQL のインタラクティブターミナルに入ります。
\d コマンド
psql でテーブル構造を検査するための主要なツールは、\d (describe) コマンドです。このコマンドは、テーブルに関する詳細な情報を提供します。
- 列名とデータ型
- 制約 (主キー、一意制約、非 NULL 制約)
- インデックス
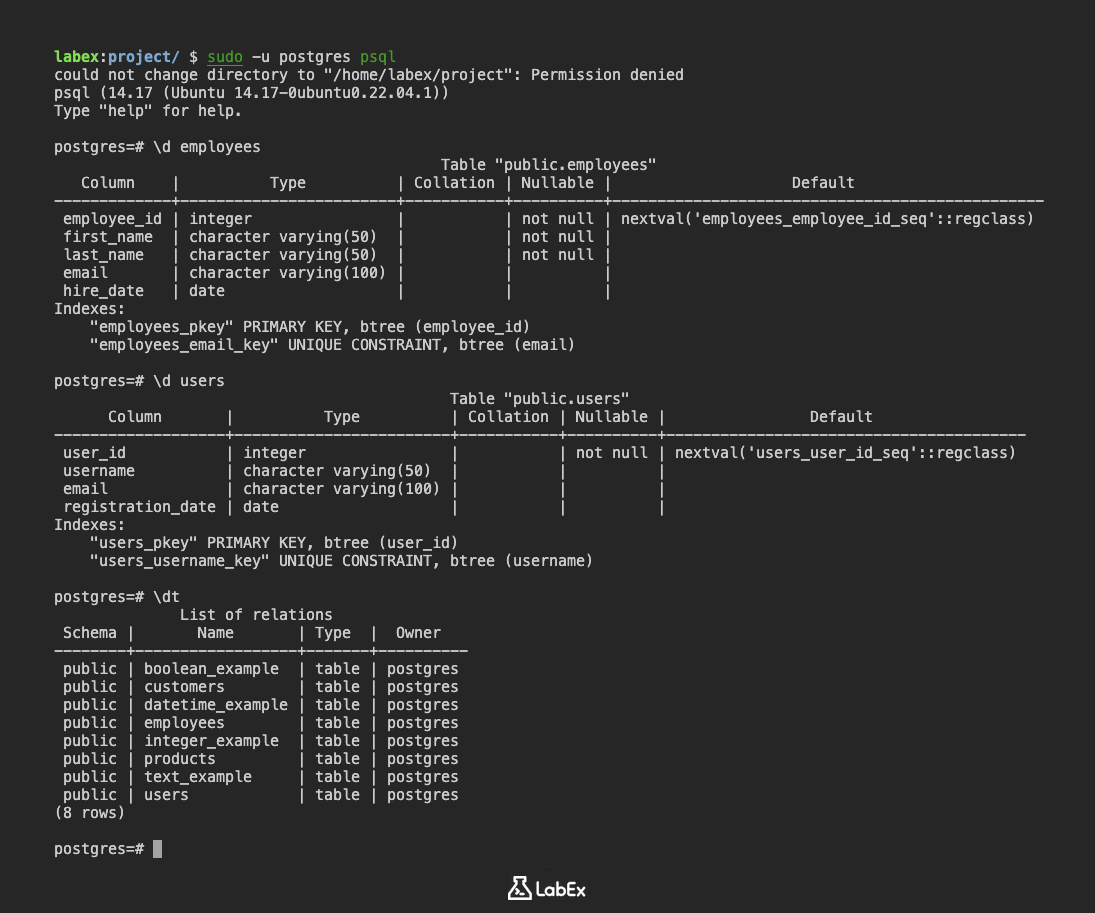
employees テーブルの検査
前のステップで作成した employees テーブルの構造を検査しましょう。
\d employees
出力:
Table "public.employees"
Column | Type | Collation | Nullable | Default
-------------+------------------------+-----------+----------+------------------------------------------------
employee_id | integer | | not null | nextval('employees_employee_id_seq'::regclass)
first_name | character varying(50) | | not null |
last_name | character varying(50) | | not null |
email | character varying(100) | | |
hire_date | date | | |
Indexes:
"employees_pkey" PRIMARY KEY, btree (employee_id)
"employees_email_key" UNIQUE CONSTRAINT, btree (email)
出力は、次の情報を提供します。
- Table "public.employees": テーブル名とスキーマを示します。
- Column: 列名 (
employee_id、first_name、last_name、email、hire_date) を一覧表示します。 - Type: 各列のデータ型 (
integer、character varying、date) を示します。 - Nullable: 列が
NULL値を含むことができるかどうかを示します (not nullまたは空白)。 - Default: 列のデフォルト値 (存在する場合) を示します。
- Indexes: テーブルに定義されたインデックスを一覧表示します。これには、主キー (
employees_pkey) とemail列の一意制約 (employees_email_key) が含まれます。
他のテーブルの検査
\d コマンドを使用して、データベース内の任意のテーブルを検査できます。たとえば、ステップ 2 で作成した users テーブルを検査するには:
\d users
出力:
Table "public.users"
Column | Type | Collation | Nullable | Default
-------------------+------------------------+-----------+----------+----------------------------------------
user_id | integer | | not null | nextval('users_user_id_seq'::regclass)
username | character varying(50) | | |
email | character varying(100) | | |
registration_date | date | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (user_id)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
すべてのテーブルの一覧表示
現在のデータベース内のすべてのテーブルを一覧表示するには、\dt コマンドを使用できます。
\dt
出力 (作成したテーブルによって異なります):
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | boolean_example | table | postgres
public | customers | table | postgres
public | datetime_example | table | postgres
public | employees | table | postgres
public | integer_example | table | postgres
public | products | table | postgres
public | text_example | table | postgres
public | users | table | postgres
(8 rows)
最後に、psql ターミナルを終了します。
\q
これで、\d および \dt コマンドを使用して、PostgreSQL でテーブルの構造を検査する方法を学びました。これは、データベースを理解し、操作するための基本的なスキルです。
まとめ
この実験(Lab)では、基本的な PostgreSQL のデータ型、特に整数とテキストについて探求しました。整数値を格納するための INTEGER と SMALLINT について学び、それぞれの範囲とユースケースを理解しました。また、テキストデータを扱うための TEXT、VARCHAR(n)、CHAR(n) についても調べ、可変長文字列と固定長文字列の違いに注目しました。
さらに、これらのデータ型を使用してテーブルを作成する練習を行い、主キーシーケンスを自動的に生成するための SERIAL の使用法も学びました。サンプルデータをテーブルに挿入し、SELECT ステートメントを使用してデータを確認することで、これらのデータ型が実際のデータベースコンテキストでどのように動作するかについての理解を深めました。

