
はじめに
この実験 (lab) では、PostgreSQL でのデータフィルタリングと簡単なクエリの実行方法を学びます。まず、PostgreSQL データベースに接続し、サンプル employees テーブルを作成してデータを投入します。
次に、WHERE 句を使用して特定の条件に基づいてデータをフィルタリングする方法、LIKE を使用してパターンマッチングを行う方法、ORDER BY で結果をソートする方法、LIMIT と OFFSET を使用して返される行数を制限する方法を説明します。
WHERE 句を使用したデータのフィルタリング
このステップでは、PostgreSQL で WHERE 句を使用して、特定の条件に基づいてデータをフィルタリングする方法を学びます。WHERE 句は、条件を満たす行のみを取得できる強力なツールです。
始める前に、PostgreSQL データベースに接続しましょう。LabEx VM でターミナルを開きます。デフォルトの Xfce ターミナルを使用できます。
まず、psql コマンドを使用して PostgreSQL データベースに接続します。postgres ユーザーで postgres データベースに接続します。コマンドを実行するには sudo が必要になる場合があります。
sudo -u postgres psql
PostgreSQL のプロンプト (postgres=#) が表示されるはずです。
次に、employees という名前のサンプルテーブルを作成し、いくつかのデータを挿入します。このテーブルには、従業員の ID、名前、部署、給与などの従業員情報が格納されます。
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50),
salary INTEGER
);
INSERT INTO employees (name, department, salary) VALUES
('Alice Smith', 'Sales', 60000),
('Bob Johnson', 'Marketing', 75000),
('Charlie Brown', 'Sales', 55000),
('David Lee', 'Engineering', 90000),
('Eve Wilson', 'Marketing', 80000),
('Frank Miller', 'Engineering', 95000);
テーブルが正しく作成され、データが投入されたことを確認するには、次の SQL クエリを実行します。
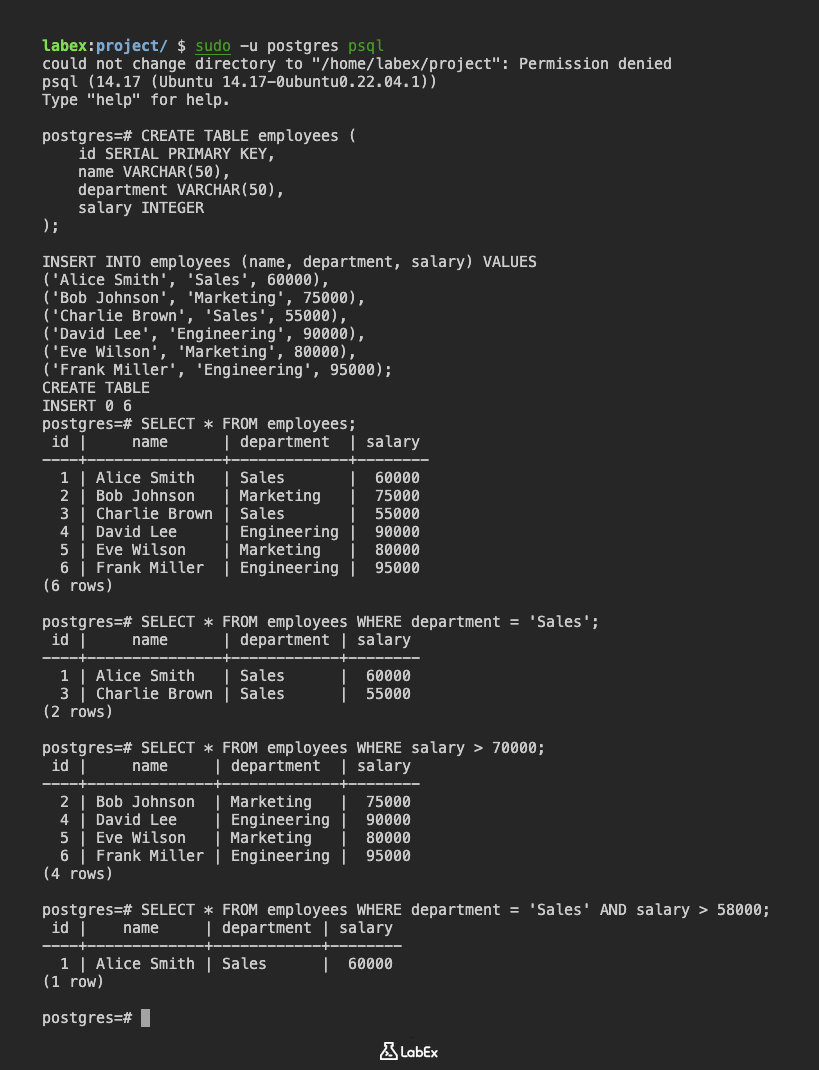
SELECT * FROM employees;
次のような出力が表示されるはずです。
id | name | department | salary
----+-----------------+-------------+--------
1 | Alice Smith | Sales | 60000
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
6 | Frank Miller | Engineering | 95000
(6 rows)
次に、WHERE 句を使用してデータをフィルタリングします。たとえば、「Sales」部署で働く従業員のみを取得するとします。次のクエリを使用できます。
SELECT * FROM employees WHERE department = 'Sales';
このクエリは、department 列が「Sales」と等しい行のみを返します。出力は次のようになります。
id | name | department | salary
----+-----------------+------------+--------
1 | Alice Smith | Sales | 60000
3 | Charlie Brown | Sales | 55000
(2 rows)
WHERE 句では、>、<、>=、<=、<> などの他の比較演算子も使用できます。たとえば、給与が 70000 を超える従業員を取得するには、次のクエリを使用できます。
SELECT * FROM employees WHERE salary > 70000;
出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
2 | Bob Johnson | Marketing | 75000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
6 | Frank Miller | Engineering | 95000
(4 rows)
AND や OR などの論理演算子を使用して、複数の条件を組み合わせることもできます。たとえば、「Sales」部署で働き、給与が 58000 を超える従業員を取得するには、次のクエリを使用できます。
SELECT * FROM employees WHERE department = 'Sales' AND salary > 58000;
出力は次のようになります。
id | name | department | salary
----+---------------+------------+--------
1 | Alice Smith | Sales | 60000
(1 row)
最後に、psql シェルを終了します。
\q
これにより、labex ユーザーのターミナルに戻ります。
LIKE を使用したパターンマッチング
このステップでは、PostgreSQL で LIKE 演算子を使用してパターンマッチングを行う方法を学びます。LIKE 演算子を使用すると、特定のパターンに一致するデータを検索できます。これは、探している正確な値がわからない場合に特に役立ちます。
まず、PostgreSQL データベースに接続しましょう。LabEx VM でターミナルを開きます。
psql コマンドを使用して PostgreSQL データベースに接続します。
sudo -u postgres psql
PostgreSQL のプロンプト (postgres=#) が表示されるはずです。
前のステップで作成した employees テーブルを引き続き使用します。まだ作成していない場合は、前のステップを参照してテーブルを作成し、データを挿入してください。
employees テーブルのデータを確認しましょう。
SELECT * FROM employees;
以前と同様に従業員データが表示されるはずです。
LIKE 演算子は、指定されたパターンに一致する行を検索するために WHERE 句で使用されます。パターンには、ワイルドカード文字を含めることができます。
%: 0 個以上の文字を表します。_: 1 つの文字を表します。
たとえば、名前が「A」で始まるすべての従業員を検索するには、次のクエリを使用できます。
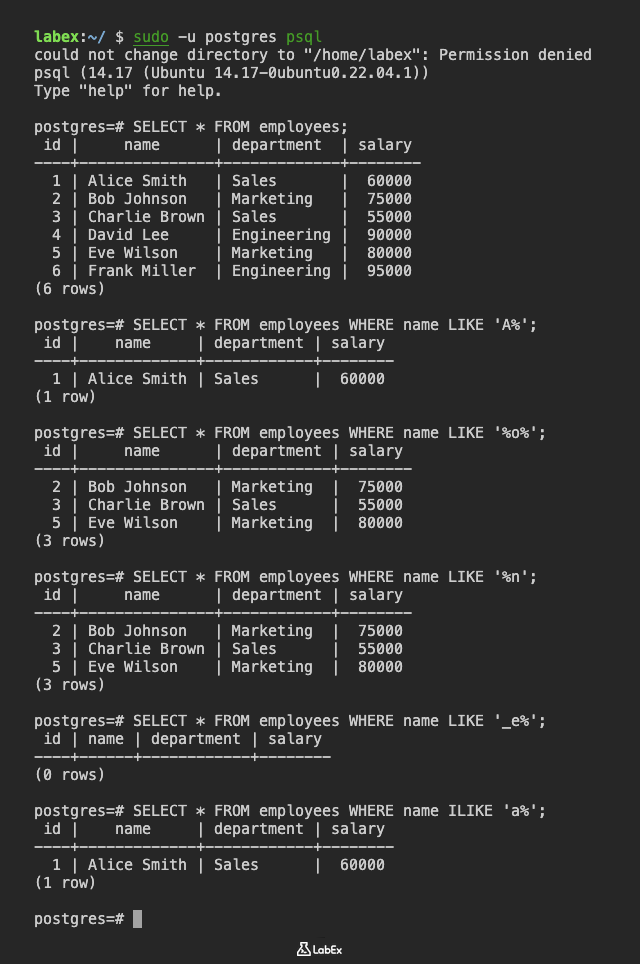
SELECT * FROM employees WHERE name LIKE 'A%';
このクエリは、name 列が「A」で始まるすべての行を返します。出力は次のようになります。
id | name | department | salary
----+---------------+------------+--------
1 | Alice Smith | Sales | 60000
(1 row)
名前の中に文字「o」が含まれているすべての従業員を検索するには、次のクエリを使用できます。
SELECT * FROM employees WHERE name LIKE '%o%';
このクエリは、name 列に文字「o」が含まれているすべての行を返します。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
5 | Eve Wilson | Marketing | 80000
(3 rows)
名前が「n」で終わるすべての従業員を検索するには、次のクエリを使用できます。
SELECT * FROM employees WHERE name LIKE '%n';
このクエリは、name 列が「n」で終わるすべての行を返します。出力は次のようになります。
id | name | department | salary
----+---------------+------------+--------
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
5 | Eve Wilson | Marketing | 80000
(3 rows)
_ ワイルドカードを使用して、1 つの文字に一致させることもできます。たとえば、名前の 2 番目と 3 番目の文字が「e」であるすべての従業員を検索するには、次のクエリを使用できます。
SELECT * FROM employees WHERE name LIKE '_e%';
このクエリは、name 列の 2 番目の文字が「e」であるすべての行を返します。出力は次のようになります。
id | name | department | salary
----+------+------------+--------
(0 rows)
LIKE 演算子は大文字と小文字を区別します。大文字と小文字を区別しない検索を実行する場合は、ILIKE 演算子を使用できます。例:
SELECT * FROM employees WHERE name ILIKE 'a%';
このクエリは、name 列が「a」または「A」で始まるすべての行を返します。
最後に、psql シェルを終了します。
\q
これにより、labex ユーザーのターミナルに戻ります。
ORDER BY を使用したデータのソート
このステップでは、PostgreSQL で ORDER BY 句を使用してデータをソートする方法を学びます。ORDER BY 句を使用すると、クエリの結果セットを 1 つまたは複数の列に基づいて、昇順または降順にソートできます。
まず、PostgreSQL データベースに接続しましょう。LabEx VM でターミナルを開きます。
psql コマンドを使用して PostgreSQL データベースに接続します。
sudo -u postgres psql
PostgreSQL のプロンプト (postgres=#) が表示されるはずです。
前のステップで作成した employees テーブルを引き続き使用します。まだ作成していない場合は、前のステップを参照してテーブルを作成し、データを挿入してください。
employees テーブルのデータを確認しましょう。
SELECT * FROM employees;
以前と同様に従業員データが表示されるはずです。
ORDER BY 句は、クエリの結果セットをソートするために使用されます。デフォルトでは、ORDER BY 句はデータを昇順にソートします。
たとえば、従業員を給与の昇順にソートするには、次のクエリを使用できます。
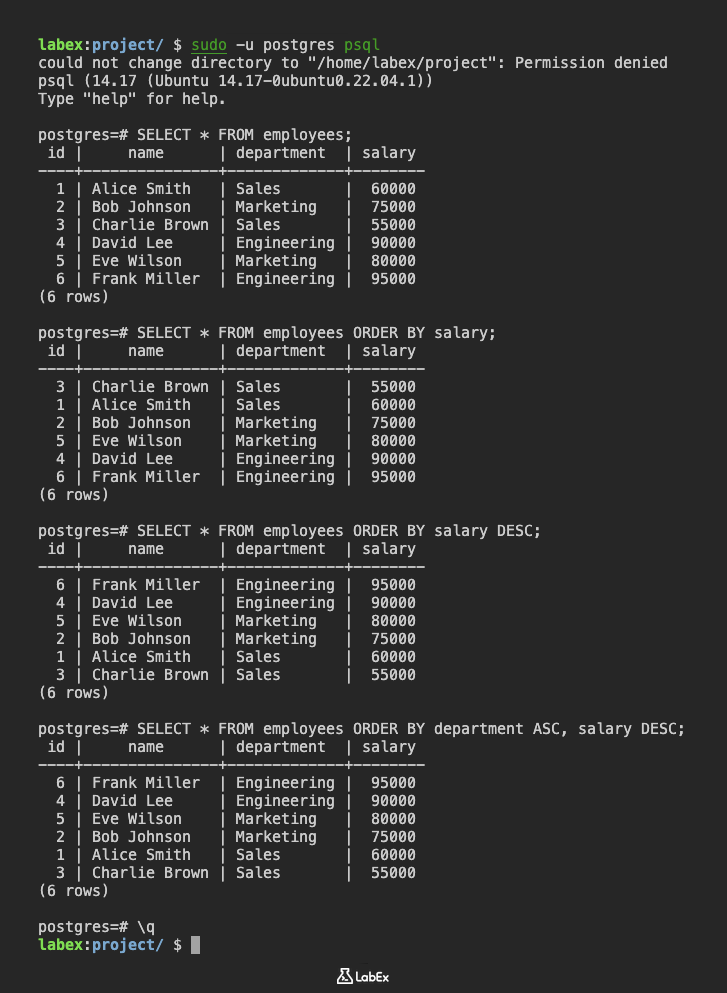
SELECT * FROM employees ORDER BY salary;
このクエリは、employees テーブルからすべての行を返し、salary 列で昇順にソートします。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
3 | Charlie Brown | Sales | 55000
1 | Alice Smith | Sales | 60000
2 | Bob Johnson | Marketing | 75000
5 | Eve Wilson | Marketing | 80000
4 | David Lee | Engineering | 90000
6 | Frank Miller | Engineering | 95000
(6 rows)
データを降順にソートするには、列名の後に DESC キーワードを使用します。たとえば、従業員を給与の降順にソートするには、次のクエリを使用できます。
SELECT * FROM employees ORDER BY salary DESC;
このクエリは、employees テーブルからすべての行を返し、salary 列で降順にソートします。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
6 | Frank Miller | Engineering | 95000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
2 | Bob Johnson | Marketing | 75000
1 | Alice Smith | Sales | 60000
3 | Charlie Brown | Sales | 55000
(6 rows)
複数の列でデータをソートすることもできます。たとえば、従業員を部署の昇順にソートし、次に給与の降順にソートするには、次のクエリを使用できます。
SELECT * FROM employees ORDER BY department ASC, salary DESC;
このクエリは、最初に department 列で昇順にデータをソートします。各部署内では、salary 列で降順にデータがソートされます。出力は次のようになります。
id | name | department | salary
----+---------------+-------------+--------
6 | Frank Miller | Engineering | 95000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
2 | Bob Johnson | Marketing | 75000
1 | Alice Smith | Sales | 60000
3 | Charlie Brown | Sales | 55000
(6 rows)
最後に、psql シェルを終了します。
\q
これにより、labex ユーザーのターミナルに戻ります。
LIMIT と OFFSET を使用した結果の制限
このステップでは、PostgreSQL で LIMIT 句と OFFSET 句を使用して、クエリによって返される行数を制限する方法と、特定の行数をスキップする方法をそれぞれ学びます。これらの句は、ページネーション (pagination) を実装したり、データの特定のサブセットを取得したりするのに役立ちます。
まず、PostgreSQL データベースに接続しましょう。LabEx VM でターミナルを開きます。
psql コマンドを使用して PostgreSQL データベースに接続します。
sudo -u postgres psql
PostgreSQL のプロンプト (postgres=#) が表示されるはずです。
前のステップで作成した employees テーブルを引き続き使用します。まだ作成していない場合は、前のステップを参照してテーブルを作成し、データを挿入してください。
employees テーブルのデータを確認しましょう。
SELECT * FROM employees;
以前と同様に従業員データが表示されるはずです。
LIMIT 句は、クエリによって返される行数を制限するために使用されます。たとえば、最初の 3 人の従業員のみを取得するには、次のクエリを使用できます。
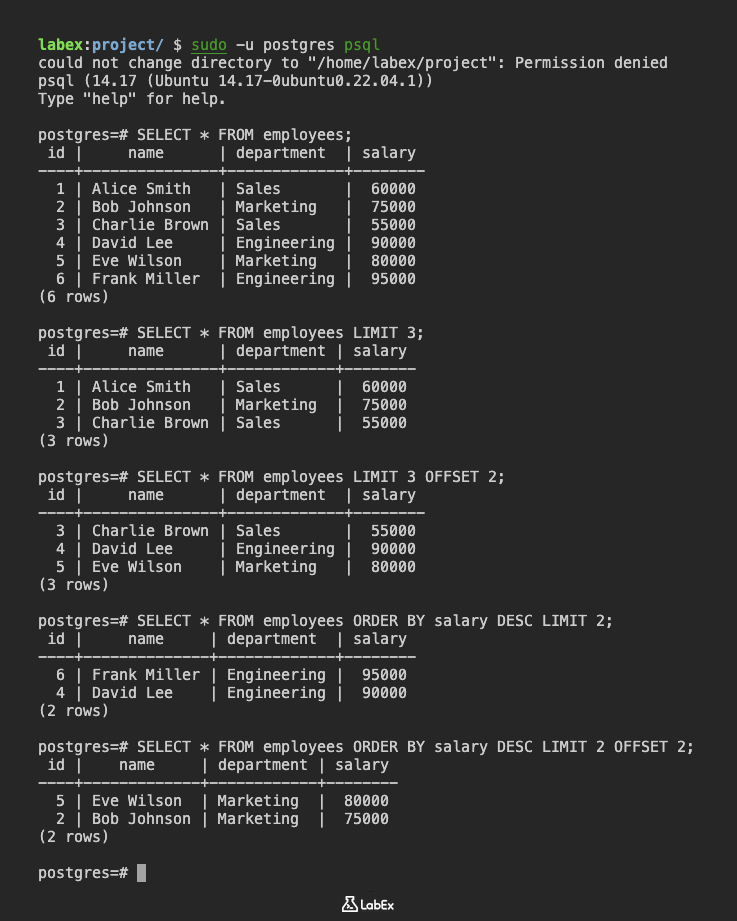
SELECT * FROM employees LIMIT 3;
このクエリは、employees テーブルから最初の 3 行を返します。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
1 | Alice Smith | Sales | 60000
2 | Bob Johnson | Marketing | 75000
3 | Charlie Brown | Sales | 55000
(3 rows)
OFFSET 句は、行の返却を開始する前に、特定の行数をスキップするために使用されます。これは、ページネーションを実装するために LIMIT 句と組み合わせて使用されることがよくあります。たとえば、最初の 2 人をスキップした後、次の 3 人の従業員を取得するには、次のクエリを使用できます。
SELECT * FROM employees LIMIT 3 OFFSET 2;
このクエリは、最初の 2 行をスキップし、employees テーブルから次の 3 行を返します。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
3 | Charlie Brown | Sales | 55000
4 | David Lee | Engineering | 90000
5 | Eve Wilson | Marketing | 80000
(3 rows)
LIMIT と OFFSET を ORDER BY 句と組み合わせることもできます。たとえば、給与が最も高い 2 人の従業員を取得するには、次のクエリを使用できます。
SELECT * FROM employees ORDER BY salary DESC LIMIT 2;
このクエリは、最初に従業員を給与の降順にソートし、次に最初の 2 行を返します。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
6 | Frank Miller | Engineering | 95000
4 | David Lee | Engineering | 90000
(2 rows)
3 番目と 4 番目に給与が高い従業員を取得するには、次のクエリを使用できます。
SELECT * FROM employees ORDER BY salary DESC LIMIT 2 OFFSET 2;
このクエリは、最初に従業員を給与の降順にソートし、最初の 2 行をスキップして、次の 2 行を返します。出力は次のようになります。
id | name | department | salary
----+-----------------+-------------+--------
5 | Eve Wilson | Marketing | 80000
2 | Bob Johnson | Marketing | 75000
(2 rows)
最後に、psql シェルを終了します。
\q
これにより、labex ユーザーのターミナルに戻ります。
まとめ
この実験 (Lab) では、まず psql コマンドを使用して PostgreSQL データベースに接続し、ID、名前、部署、給与の列を持つサンプル employees テーブルを作成しました。次に、従業員データをテーブルに入力し、SELECT クエリを使用してその内容を確認しました。
最初の焦点は、特定の条件に基づいてデータをフィルタリングするために WHERE 句を使用することでした。これにより、定義された基準を満たす行のみを取得でき、employees テーブルからターゲットを絞ったデータ検索が可能になります。

