はじめに
データビジュアライゼーションを作成する際、注釈を追加することで、閲覧者がグラフを理解しやすくなります。テキストボックスは、ビジュアライゼーション内に直接追加情報を含める効果的な方法です。静的、アニメーション、インタラクティブなビジュアライゼーションを作成するための人気のある Python ライブラリである Matplotlib は、グラフにカスタマイズ可能なテキストボックスを追加するための強力なツールを提供しています。
この実験では、Python を使用して Matplotlib のグラフにテキストボックスを配置する方法を学びます。データスケールが変更されても、グラフに対して固定位置にテキストを配置する軸座標でテキストを配置する方法を学びます。さらに、bbox プロパティを使用して、異なるスタイル、色、透明度でテキストボックスをカスタマイズする方法も学びます。
この実験の終了時には、データビジュアライゼーションプロジェクトで、戦略的に配置された注釈を持つ、情報量が多く視覚的に魅力的なグラフを作成できるようになります。
VM のヒント
VM の起動が完了したら、左上隅をクリックして Notebook タブに切り替え、Jupyter Notebook を開いて練習を行ってください。
Jupyter Notebook の読み込みが完了するまで数秒待つ必要がある場合があります。Jupyter Notebook の制限により、操作の検証を自動化することはできません。
実験中に問題が発生した場合は、いつでも Labby に支援を求めてください。セッション終了後のフィードバックをいただけると、実験体験の向上に役立ちます。
Jupyter Notebook の作成とデータの準備
最初のステップでは、新しい Jupyter Notebook を作成し、データビジュアライゼーションのためのデータを準備します。
新しい Notebook の作成
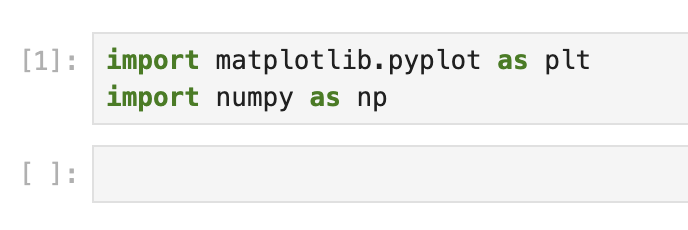
Notebook の最初のセルで、必要なライブラリをインポートしましょう。以下のコードを入力し、「Run」ボタンをクリックするか、Shift+Enter キーを押して実行します。
import matplotlib.pyplot as plt
import numpy as np
このコードは、2 つの重要なライブラリをインポートします。
matplotlib.pyplot:matplotlib を MATLAB のように動作させる関数のコレクションnumpy:Python における科学計算のための基本的なパッケージ
サンプルデータの作成
次に、ビジュアライズするサンプルデータを作成しましょう。新しいセルに以下のコードを入力して実行します。
## Set a random seed for reproducibility
np.random.seed(19680801)
## Generate 10,000 random numbers from a normal distribution
x = 30 * np.random.randn(10000)
## Calculate basic statistics
mu = x.mean()
median = np.median(x)
sigma = x.std()
## Display the statistics
print(f"Mean (μ): {mu:.2f}")
print(f"Median: {median:.2f}")
print(f"Standard Deviation (σ): {sigma:.2f}")
このセルを実行すると、以下のような出力が表示されます。
Mean (μ): -0.31
Median: -0.28
Standard Deviation (σ): 29.86
正確な値は多少異なる場合があります。私たちは、正規分布から生成された 10,000 個の乱数を含むデータセットを作成し、3 つの重要な統計量を計算しました。
- 平均 (μ):すべてのデータポイントの平均値
- 中央値:データを順番に並べたときの中央の値
- 標準偏差 (σ):データの分散の尺度
これらの統計量は、後でビジュアライゼーションに注釈を付けるために使用されます。
基本的なヒストグラムの作成
データが用意できたので、その分布を可視化するためのヒストグラムを作成しましょう。ヒストグラムはデータをビン(範囲)に分割し、各ビン内のデータポイントの頻度を示します。
ヒストグラムの作成
Jupyter Notebook の新しいセルに以下のコードを入力して実行します。
## Create a figure and axes
fig, ax = plt.subplots(figsize=(10, 6))
## Create a histogram with 50 bins
histogram = ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Add title and labels
ax.set_title('Distribution of Random Data', fontsize=16)
ax.set_xlabel('Value', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
## Display the plot
plt.tight_layout()
plt.show()
このセルを実行すると、ランダムデータの分布を示すヒストグラムが表示されます。出力はゼロ付近を中心とした釣鐘型の曲線(正規分布)のように見えます。
コードの理解
コードの各行が何をするかを分解してみましょう。
fig, ax = plt.subplots(figsize=(10, 6)):グラフと軸のオブジェクトを作成します。figsizeパラメータはグラフのサイズをインチ(幅、高さ)で設定します。histogram = ax.hist(x, bins=50, color='skyblue', edgecolor='black'):データxのヒストグラムを 50 のビンで作成します。ビンは黒い枠線の水色に着色されます。ax.set_title('Distribution of Random Data', fontsize=16):フォントサイズ 16 のタイトルをグラフに追加します。ax.set_xlabel('Value', fontsize=12)とax.set_ylabel('Frequency', fontsize=12):フォントサイズ 12 のラベルを x 軸と y 軸に追加します。plt.tight_layout():グラフを自動的に調整して図の領域に収めます。plt.show():グラフを表示します。
ヒストグラムはデータの分布を示しています。np.random.randn() を使用して正規分布からデータを生成したため、ヒストグラムは 0 を中心とした釣鐘型になっています。各棒の高さはその範囲内に含まれるデータポイントの数を表しています。
統計情報を含むテキストボックスの追加
基本的なヒストグラムができたので、データの統計情報を表示するテキストボックスを追加して、ビジュアライゼーションを充実させましょう。これにより、閲覧者にとってビジュアライゼーションがより有益なものになります。
テキスト内容の作成
まず、テキストボックス内に表示するテキスト内容を準備する必要があります。新しいセルに以下のコードを入力して実行します。
## Create a string with the statistics
textstr = '\n'.join((
r'$\mu=%.2f$' % (mu,), ## Mean
r'$\mathrm{median}=%.2f$' % (median,), ## Median
r'$\sigma=%.2f$' % (sigma,) ## Standard deviation
))
print("Text content for our box:")
print(textstr)
以下のような出力が表示されるはずです。
Text content for our box:
$\mu=-0.31$
$\mathrm{median}=-0.28$
$\sigma=29.86$
このコードは、データの平均、中央値、標準偏差を含む複数行の文字列を作成します。このコードの興味深い点を見てみましょう。
\n'.join(...)メソッドは、複数の文字列を改行文字で結合します。- 各文字列の前の
rは、その文字列を「生の」文字列にします。これは特殊文字を含む場合に便利です。 $...$表記は、matplotlib で LaTeX スタイルの数式を書式設定するために使用されます。\muと\sigmaは、ギリシャ文字の μ(ミュー)と σ(シグマ)の LaTeX 記号です。%.2fは、浮動小数点数を小数点以下 2 桁で表示する書式指定子です。
テキストボックスの作成と追加
次に、ヒストグラムを再作成し、テキストボックスを追加しましょう。新しいセルに以下のコードを入力して実行します。
## Create a new figure and axes
fig, ax = plt.subplots(figsize=(10, 6))
## Create a histogram with 50 bins
histogram = ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Add title and labels
ax.set_title('Distribution of Random Data with Statistics', fontsize=16)
ax.set_xlabel('Value', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
## Define the properties of the text box
properties = dict(boxstyle='round', facecolor='wheat', alpha=0.5)
## Add the text box to the plot
## Position the box in the top left corner (0.05, 0.95) in axes coordinates
ax.text(0.05, 0.95, textstr, transform=ax.transAxes, fontsize=14,
verticalalignment='top', bbox=properties)
## Display the plot
plt.tight_layout()
plt.show()
このセルを実行すると、左上隅に統計情報を表示するテキストボックスが付いたヒストグラムが表示されます。
テキストボックスのコードの理解
テキストボックスを作成するコードの重要な部分を分解してみましょう。
properties = dict(boxstyle='round', facecolor='wheat', alpha=0.5):- これは、テキストボックスのプロパティを持つ辞書を作成します。
boxstyle='round':ボックスの角を丸くします。facecolor='wheat':ボックスの背景色を小麦色に設定します。alpha=0.5:ボックスを半透明にします(不透明度 50%)。
ax.text(0.05, 0.95, textstr, transform=ax.transAxes, fontsize=14, verticalalignment='top', bbox=properties):- これは、位置 (0.05, 0.95) にテキストを軸に追加します。
transform=ax.transAxes:これは重要です。座標がデータ単位ではなく軸単位(0 - 1)であることを意味します。したがって、(0.05, 0.95) は「グラフの左端から 5%、下端から 95%」を意味します。fontsize=14:フォントサイズを設定します。verticalalignment='top':テキストの上部が指定された y 座標に位置するようにテキストを配置します。bbox=properties:テキストボックスのプロパティを適用します。
テキストボックスは、グラフを拡大したりデータ範囲を変更したりしても、グラフの軸に対して同じ位置に留まります。これは、transform=ax.transAxes を使用して軸座標を使用したためです。
テキストボックスのカスタマイズ
グラフにテキストボックスを成功に追加したので、様々なカスタマイズオプションを探索して、視覚的に魅力的で様々なコンテキストに適したものにしましょう。
異なるスタイルの試行
異なるテキストボックスのスタイルを簡単に試すための関数を作成しましょう。新しいセルに以下のコードを入力して実行します。
def plot_with_textbox(boxstyle, facecolor, alpha, position=(0.05, 0.95)):
"""
Create a histogram with a custom text box.
Parameters:
boxstyle (str): Style of the box ('round', 'square', 'round4', etc.)
facecolor (str): Background color of the box
alpha (float): Transparency of the box (0-1)
position (tuple): Position of the box in axes coordinates (x, y)
"""
## Create figure and plot
fig, ax = plt.subplots(figsize=(8, 5))
ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Set title and labels
ax.set_title(f'Text Box Style: {boxstyle}', fontsize=16)
ax.set_xlabel('Value', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
## Create text box properties
box_props = dict(boxstyle=boxstyle, facecolor=facecolor, alpha=alpha)
## Add text box
ax.text(position[0], position[1], textstr, transform=ax.transAxes,
fontsize=14, verticalalignment='top', bbox=box_props)
plt.tight_layout()
plt.show()
この関数を使って、異なるボックススタイルを試してみましょう。新しいセルに以下を入力して実行します。
## Try a square box with light green color
plot_with_textbox('square', 'lightgreen', 0.7)
## Try a rounded box with light blue color
plot_with_textbox('round', 'lightblue', 0.5)
## Try a box with extra rounded corners
plot_with_textbox('round4', 'lightyellow', 0.6)
## Try a sawtooth style box
plot_with_textbox('sawtooth', 'lightcoral', 0.4)
このセルを実行すると、それぞれ異なるテキストボックスのスタイルが適用された 4 つのグラフが表示されます。
テキストボックスの位置変更
テキストボックスの位置は、ビジュアライゼーションにとって重要な要素です。グラフの異なる角にテキストボックスを配置してみましょう。新しいセルに以下を入力して実行します。
## Create a figure with a 2x2 grid of subplots
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten() ## Flatten to easily iterate
## Define positions for the four corners
positions = [
(0.05, 0.95), ## Top left
(0.95, 0.95), ## Top right
(0.05, 0.05), ## Bottom left
(0.95, 0.05) ## Bottom right
]
## Define alignments for each position
alignments = [
('top', 'left'), ## Top left
('top', 'right'), ## Top right
('bottom', 'left'), ## Bottom left
('bottom', 'right') ## Bottom right
]
## Corner labels
corner_labels = ['Top Left', 'Top Right', 'Bottom Left', 'Bottom Right']
## Create four plots with text boxes in different corners
for i, ax in enumerate(axes):
## Plot histogram
ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Set title
ax.set_title(f'Text Box in {corner_labels[i]}', fontsize=14)
## Create text box properties
box_props = dict(boxstyle='round', facecolor='wheat', alpha=0.5)
## Add text box
ax.text(positions[i][0], positions[i][1], textstr,
transform=ax.transAxes, fontsize=12,
verticalalignment=alignments[i][0],
horizontalalignment=alignments[i][1],
bbox=box_props)
plt.tight_layout()
plt.show()
このコードは、それぞれ異なる角にテキストボックスが配置された 2x2 のヒストグラムのグリッドを作成します。
テキストボックスの位置決めの理解
テキストボックスの位置決めを制御するいくつかの重要なパラメータがあります。
位置座標:
(x, y)座標は、テキストボックスが配置される場所を決定します。transform=ax.transAxesを使用する場合、これらは軸座標であり、(0, 0)は左下隅、(1, 1)は右上隅を表します。垂直方向の配置:
verticalalignmentパラメータは、テキストが y 座標に対して垂直方向にどのように配置されるかを制御します。'top':テキストの上部が指定された y 座標に位置します。'center':テキストの中央が指定された y 座標に位置します。'bottom':テキストの下部が指定された y 座標に位置します。
水平方向の配置:
horizontalalignmentパラメータは、テキストが x 座標に対して水平方向にどのように配置されるかを制御します。'left':テキストの左側の端が指定された x 座標に位置します。'center':テキストの中央が指定された x 座標に位置します。'right':テキストの右側の端が指定された x 座標に位置します。
これらの配置オプションは、テキストを角に配置する場合に特に重要です。たとえば、右上隅にテキストを配置する場合は、horizontalalignment='right' を使用して、テキストの右側の端をグラフの右側の端に合わせることができます。
複数のテキスト要素を持つ最終的なビジュアライゼーションの作成
この最後のステップでは、これまで学んだことをすべて組み合わせて、異なるスタイルの複数のテキスト要素を含む包括的なビジュアライゼーションを作成します。これにより、テキストボックスがデータストーリーテリングを強化するためにどのように使用できるかを示します。
高度なビジュアライゼーションの作成
ヒストグラムといくつかの追加の視覚要素を含む、より洗練されたグラフを作成しましょう。新しいセルに以下のコードを入力して実行します。
## Create a figure with a larger size for our final visualization
fig, ax = plt.subplots(figsize=(12, 8))
## Plot the histogram with more bins and a different color
n, bins, patches = ax.hist(x, bins=75, color='lightblue',
edgecolor='darkblue', alpha=0.7)
## Add title and labels with improved styling
ax.set_title('Distribution of Random Data with Statistical Annotations',
fontsize=18, fontweight='bold', pad=20)
ax.set_xlabel('Value', fontsize=14)
ax.set_ylabel('Frequency', fontsize=14)
## Add grid for better readability
ax.grid(True, linestyle='--', alpha=0.7)
## Mark the mean with a vertical line
ax.axvline(x=mu, color='red', linestyle='-', linewidth=2,
label=f'Mean: {mu:.2f}')
## Mark one standard deviation range
ax.axvline(x=mu + sigma, color='green', linestyle='--', linewidth=1.5,
label=f'Mean + 1σ: {mu+sigma:.2f}')
ax.axvline(x=mu - sigma, color='green', linestyle='--', linewidth=1.5,
label=f'Mean - 1σ: {mu-sigma:.2f}')
## Create a text box with statistics in the top left
stats_box_props = dict(boxstyle='round', facecolor='lightyellow',
alpha=0.8, edgecolor='gold', linewidth=2)
stats_text = '\n'.join((
r'$\mathbf{Statistics:}$',
r'$\mu=%.2f$ (mean)' % (mu,),
r'$\mathrm{median}=%.2f$' % (median,),
r'$\sigma=%.2f$ (std. dev.)' % (sigma,)
))
ax.text(0.05, 0.95, stats_text, transform=ax.transAxes, fontsize=14,
verticalalignment='top', bbox=stats_box_props)
## Add an informational text box in the top right
info_box_props = dict(boxstyle='round4', facecolor='lightcyan',
alpha=0.8, edgecolor='deepskyblue', linewidth=2)
info_text = '\n'.join((
r'$\mathbf{About\ Normal\ Distributions:}$',
r'$\bullet\ 68\%\ of\ data\ within\ 1\sigma$',
r'$\bullet\ 95\%\ of\ data\ within\ 2\sigma$',
r'$\bullet\ 99.7\%\ of\ data\ within\ 3\sigma$'
))
ax.text(0.95, 0.95, info_text, transform=ax.transAxes, fontsize=14,
verticalalignment='top', horizontalalignment='right',
bbox=info_box_props)
## Add a legend
ax.legend(fontsize=12)
## Tighten the layout and show the plot
plt.tight_layout()
plt.show()
このセルを実行すると、以下の要素を含む包括的なビジュアライゼーションが表示されます。
- スタイルが改善されたデータのヒストグラム
- 平均と 1 標準偏差の範囲を示す垂直線
- 左上隅にある統計情報のテキストボックス
- 右上隅にある正規分布に関する情報のテキストボックス
- 垂直線の意味を説明する凡例
高度な要素の理解
追加した新しい要素のいくつかを見てみましょう。
axvline()を使用した垂直線:- これらの線は、グラフ上に重要な統計情報を直接示します。
labelパラメータにより、これらの線を凡例に含めることができます。
異なるスタイルの複数のテキストボックス:
- 各テキストボックスは異なる目的を持ち、独特のスタイルを使用しています。
- 統計情報のボックスは、データから計算された値を表示します。
- 情報ボックスは、正規分布に関するコンテキストを提供します。
強化された書式設定:
- LaTeX の書式設定を使用して、
\mathbf{}で太字のテキストを作成します。 \bulletで箇条書きを作成します。\(バックスラッシュの後にスペース)で間隔を制御します。
- LaTeX の書式設定を使用して、
グリッドと凡例:
- グリッドは、閲覧者がチャートから値をより正確に読み取るのに役立ちます。
- 凡例は、色付きの線の意味を説明します。
テキストボックス配置に関する最後の注意点
ビジュアライゼーションに複数のテキスト要素を配置する際には、以下の点を考慮してください。
- 視覚的な階層:最も重要な情報は最も目立つようにする必要があります。
- 配置:関連する情報をビジュアライゼーションの関連部分の近くに配置します。
- コントラスト:テキストが背景に対して読みやすいことを確認します。
- 一貫性:同じ種類の情報には一貫したスタイルを使用します。
- 混雑:ビジュアライゼーションに過度に多くのテキスト要素を配置しないようにします。
テキストボックスを慎重に配置し、スタイルを設定することで、情報が豊富で視覚的に魅力的なビジュアライゼーションを作成し、閲覧者がデータから重要な洞察を理解するのを導くことができます。
まとめ
この実験では、Matplotlib でテキストボックスを効果的に使用してデータビジュアライゼーションを強化する方法を学びました。要点を振り返ってみましょう。
学んだ主要な概念
基本的なテキストボックスの作成:
matplotlib.pyplot.text()関数とbboxパラメータを使用して、グラフにテキストボックスを追加する方法を学びました。テキストボックスの位置決め:
transform=ax.transAxesを使用して軸座標でテキストボックスを配置する方法を学びました。これにより、データのスケーリングに関係なくテキストを固定位置に配置できます。テキストボックスのスタイル設定:異なるスタイル (
boxstyle)、色 (facecolor)、透明度レベル (alpha)、およびボーダープロパティでテキストボックスをカスタマイズする方法を探索しました。テキストの配置:
verticalalignmentとhorizontalalignmentを使用して、ビジュアライゼーションの異なる部分にテキストを適切に配置する方法を練習しました。LaTeX 書式設定:LaTeX 表記を使用して、テキストに数学記号や書式を追加する方法を学びました。
包括的なビジュアライゼーション:異なるスタイルの複数のテキスト要素を組み合わせて、一貫したデータストーリーを伝える完全なビジュアライゼーションを作成しました。
実用的な応用
この実験で学んだ技術は、以下の用途に適用できます。
- グラフに統計的な要約を追加する
- データの重要な特徴にラベルを付ける
- ビジュアライゼーション内にコンテキストや説明を提供する
- カスタム書式の凡例やキーを作成する
- 重要な発見や洞察を強調する
次のステップ
Matplotlib を使ったデータビジュアライゼーションスキルをさらに向上させるために、以下の内容を探索することを検討してください。
- 矢印や注釈ボックスなどの高度な注釈技術
- Matplotlib のイベントハンドリングを使用したインタラクティブなテキスト要素
- 異なるフォントやスタイルでテキストをカスタマイズする
- 調整された注釈を持つサブプロットを作成する
- テキスト要素付きのビジュアライゼーションを出版用に保存する
Matplotlib でのテキスト注釈の技術を習得することで、より情報量が多く、プロフェッショナルなデータビジュアライゼーションを作成し、洞察を効果的に聴衆に伝えることができます。