
はじめに
Python によるデータ分析の世界へようこそ!この実験では、Python における最も人気があり強力なオープンソースのデータ操作・分析ライブラリである Pandas をご紹介します。
このコースを開始する前に、基本的な Python プログラミングスキルを持っていること、およびシステム PATH に Python が正しく設定されていることを確認してください。まだ Python を学習していない場合は、当社の Python 学習パス から始めることができます。さらに、Pandas の操作には NumPy が不可欠な前提条件であるため、NumPy がインストールされている必要があります。NumPy を学習する必要がある場合は、当社の NumPy 学習パス を参照してください。
Pandas は、高性能で使いやすいデータ構造とデータ分析ツールを提供します。Pandas の 2 つの主要なデータ構造は、Series(1 次元)と DataFrame(2 次元)です。
この実験では、すぐに始められるようにするための絶対的な基本を学びます。以下のことを行います。
- 環境に Pandas がインストールされていることを確認します。
- Python スクリプトに Pandas ライブラリをインポートします。
- 最初の Pandas
Seriesオブジェクトを作成します。 Series内のデータにアクセスします。Seriesの基本的なプロパティを検査します。
この実験は初心者向けに設計されており、Pandas に関する事前の知識は必要ありません。さあ、始めましょう!
pip を使用して Pandas をインストールする
このステップでは、環境に pandas が正しくインストールされていることを確認します。LabEx 環境には、時間の節約のために Python と Pandas がプリインストールされています。これを自分で確認し、バージョンをチェックすることができます。
インストールされている Python パッケージの詳細を確認するには、pip show コマンドを使用できます。pip は Python のパッケージインストーラーです。
ターミナルを開き、インストールされている pandas パッケージに関する情報を表示するために、次のコマンドを実行してください。
pip show pandas
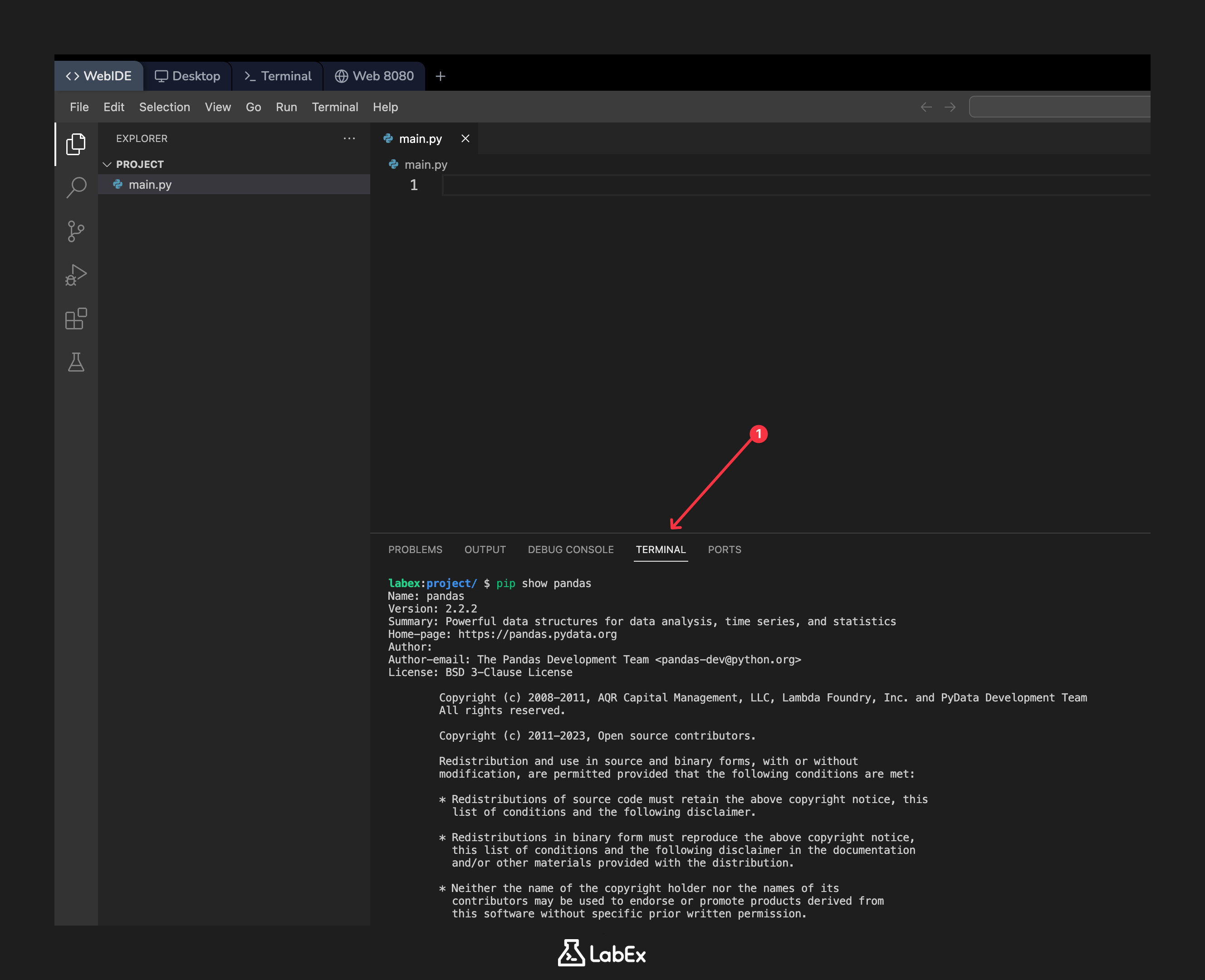
パッケージの名前、バージョン、概要、および場所の詳細が表示されるはずです。バージョンは 2.2.2 またはそれに類似したものであるべきです。
Name: pandas
Version: 2.2.2
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author: The Pandas Development Team
Author-email: pandas-dev@python.org
License: BSD-3-Clause
Location: /usr/local/lib/python3.10/dist-packages
Requires: numpy, python-dateutil, pytz, tzdata
Required-by:
これにより、Python スクリプトで pandas を使用する準備が整ったことが確認できます。
Pandas を pd としてインポートする
このステップでは、Pandas ライブラリをインポートするための最初の Python コードを記述します。慣例として、Pandas はエイリアス pd でインポートされます。これにより、コードが短く、より読みやすくなります。
WebIDE の左側のファイルエクスプローラーには、main.py という名前のファイルが表示されます。このファイルはあなたのために作成されました。それをクリックしてエディタで開いてください。
次に、pandas をインポートして確認メッセージを表示するために、main.py に次のコードを追加します。
import pandas as pd
print("Pandas imported successfully!")
import pandas as pd: この行は、Python に Pandas ライブラリをロードし、エイリアスpdを与えるように指示します。今後、Pandas の関数やオブジェクトにはpd.を使用してアクセスできます。print(...): これは、ターミナルに出力を表示するための標準的な Python 関数です。
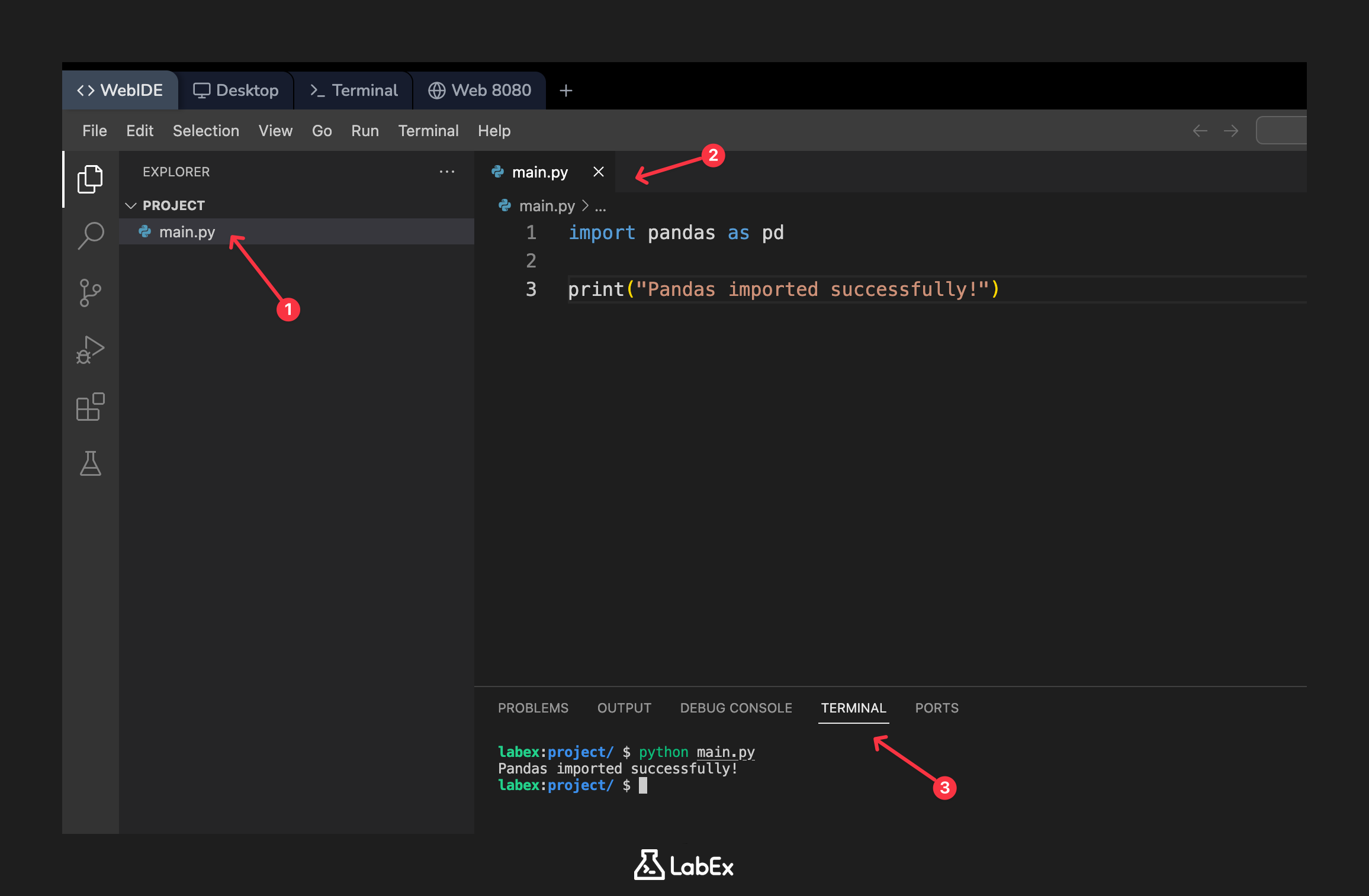
スクリプトを実行するには、ターミナルに移動し、次のコマンドを実行します。
python main.py
ターミナルに確認メッセージが表示されるはずです。
Pandas imported successfully!
これにより、Python スクリプトが Pandas ライブラリを正常にインポートして使用できることが確認できます。
リストからシンプルな Series を作成する
このステップでは、最初の Pandas Series を作成します。Series は、整数、文字列、浮動小数点数などの任意のデータ型を保持できる、一次元のアレイのようなオブジェクトです。これは Pandas におけるデータの基本的な構成要素です。
Python のリストを pd.Series() コンストラクタに渡すことで Series を作成できます。
main.py ファイルを変更します。前の print ステートメントを、Series を作成して表示するための次のコードに置き換えてください。
import pandas as pd
## A Python list of numbers
data = [10, 20, 30, 40, 50]
## Create a Pandas Series from the list
s = pd.Series(data)
## Print the Series
print(s)
提案: 上記のコードをコードエディタにコピーし、各コード行を注意深く読んでその機能を理解してください。さらに詳しい説明が必要な場合は、「コードの説明」ボタン 👆 をクリックできます。Labby と対話して、パーソナライズされたヘルプを得ることができます。
data = [...]: まず、整数のシンプルな Python リストを定義します。s = pd.Series(data):pd(Pandas) ライブラリからSeriesコンストラクタを呼び出し、リストを渡します。これによりSeriesオブジェクトが作成されます。
次に、ターミナルからスクリプトを再度実行します。
python main.py
出力には、作成した Series が表示されます。左側のインデックス(0〜4)と右側の値(10〜50)の 2 つの列があることに注意してください。インデックスが指定されていない場合、Pandas はデフォルトの整数インデックスを自動的に作成します。
0 10
1 20
2 30
3 40
4 50
dtype: int64
インデックスで Series の要素にアクセスする
このステップでは、作成した Series から個々の要素または要素のサブセットにアクセスする方法を学びます。データのアクセスは、データ分析における基本的な操作です。Python のリストと同様に、インデックスを使用して Series の要素にアクセスできます。
main.py を変更して、特定の要素にアクセスし、それらを表示してみましょう。最初の要素(インデックス 0)と要素のスライスにアクセスします。
main.py ファイルを次のコードで更新してください。シリーズ全体を表示する行の後に、新しい print ステートメントを追加します。
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
print("The full Series:")
print(s)
## Access the first element (at index 0)
print("\nFirst element:", s[0])
## Access a slice of elements (from index 1 up to, but not including, 3)
print("\nElements from index 1 to 2:")
print(s[1:3])
s[0]: これはインデックス0の値、つまり10を取得します。s[1:3]: これはスライシングと呼ばれます。インデックス1から始まり、インデックス3の直前までの要素を取得します。これにより、インデックス1と2の要素が得られます。
スクリプトを実行して結果を確認します。
python main.py
出力には、完全な Series の後に、アクセスした特定の要素が表示されるはずです。
The full Series:
0 10
1 20
2 30
3 40
4 50
dtype: int64
First element: 10
Elements from index 1 to 2:
1 20
2 30
dtype: int64
Series のデータ型と形状を表示する
このステップでは、Series の 2 つの重要なプロパティ、データ型 (dtype) と形状 (shape) を確認する方法を学びます。これらの属性を理解することは、デバッグやデータ検証において非常に重要です。
dtype: この属性は、Seriesに格納されている値のデータ型(例:整数ならint64、浮動小数点数ならfloat64、文字列ならobject)を示します。shape: この属性は、Seriesの次元を表すタプルを返します。一次元であるSeriesの場合、要素数nを持つ単一の値(n,)のタプルになります。
main.py を更新して、これらの 2 つの属性を表示してみましょう。スクリプトの末尾に次の行を追加してください。
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
## ... (以前の print ステートメントは削除または保持できます)
## Print the data type of the Series
print("\nData type:", s.dtype)
## Print the shape of the Series
print("Shape:", s.shape)
これで、スクリプトを最後に実行します。
python main.py
出力には、Series のデータ型と形状が含まれるようになります。
Data type: int64
Shape: (5,)
これにより、Series が 64 ビット整数を含み、5 つの要素を持つことがわかります。
まとめ
おめでとうございます!Pandas に関するこの入門ラボを無事に完了しました。
このラボでは、この強力なライブラリを扱うための基本的な最初のステップを学びました。以下のことを行いました。
- 環境での
pandasのインストールを確認しました。 - 標準的なエイリアス
pdを使用して、Python スクリプトにpandasライブラリをインポートしました。 - Python リストから基本的な一次元
Seriesを作成しました。 - インデックス作成とスライシングを使用して
Seriesから要素にアクセスしました。 dtypeおよびshape属性を検査して、Seriesの構造とデータ型を理解しました。
これらは、DataFrame のようなより複雑なデータ構造に進み、より高度なデータ分析タスクを実行する際に必要となる基本的な構成要素です。引き続き練習しましょう!


