
はじめに
この実験 (Lab) では、MySQL のインデックスとパフォーマンス最適化技術について学びます。この実験は、データベースクエリのパフォーマンスを向上させるためのインデックスの作成と管理に焦点を当てています。
まず、users テーブルを作成し、サンプルデータを挿入します。次に、username カラムに単一カラムインデックスを作成し、その作成方法を確認する方法を学びます。この実験では、EXPLAIN を使用したクエリプランの分析、複数カラムクエリのための複合インデックスの追加、およびデータベースの効率を維持するための未使用インデックスの削除についても扱います。
テーブルに単一カラムインデックスを作成する
このステップでは、MySQL で単一カラムインデックスを作成する方法を学びます。インデックスは、データベースクエリのパフォーマンスを向上させるために非常に重要です。特に、大規模なテーブルを扱う場合にはその効果を発揮します。カラムにインデックスを作成することで、データベースはテーブル全体をスキャンすることなく、そのカラムの特定の値に一致する行を迅速に見つけることができます。
インデックスの理解
インデックスを本の索引のように考えてください。特定のトピックを見つけるために本全体を読む代わりに、索引を使って関連するページを素早く見つけることができます。同様に、データベースインデックスは、データベースエンジンが特定の行を素早く見つけるのに役立ちます。
テーブルの作成
まず、インデックス作成を実演するために、users という名前のシンプルなテーブルを作成しましょう。LabEx VM でターミナルを開きます。デスクトップ上の Xfce Terminal ショートカットを使用できます。
root ユーザーとして MySQL サーバーに接続します。
sudo mysql -u root
まず、この実験用のデータベースを作成し、それを選択します。
CREATE DATABASE lab_db;
USE lab_db;
次に、users テーブルを作成します。
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
この SQL ステートメントは、id、username、email、created_at のカラムを持つ users という名前のテーブルを作成します。id カラムはプライマリキーとして設定され、自動インクリメントされます。
users テーブルにサンプルデータを挿入しましょう。
INSERT INTO users (username, email) VALUES
('john_doe', 'john.doe@example.com'),
('jane_smith', 'jane.smith@example.com'),
('peter_jones', 'peter.jones@example.com');
単一カラムインデックスの作成
次に、username カラムにインデックスを作成します。これにより、ユーザー名を指定してユーザーを検索するクエリの速度が向上します。
CREATE INDEX idx_username ON users (username);
このステートメントは、users テーブルの username カラムに idx_username という名前のインデックスを作成します。
インデックスの検証
SHOW INDEXES コマンドを使用して、インデックスが作成されたことを確認できます。
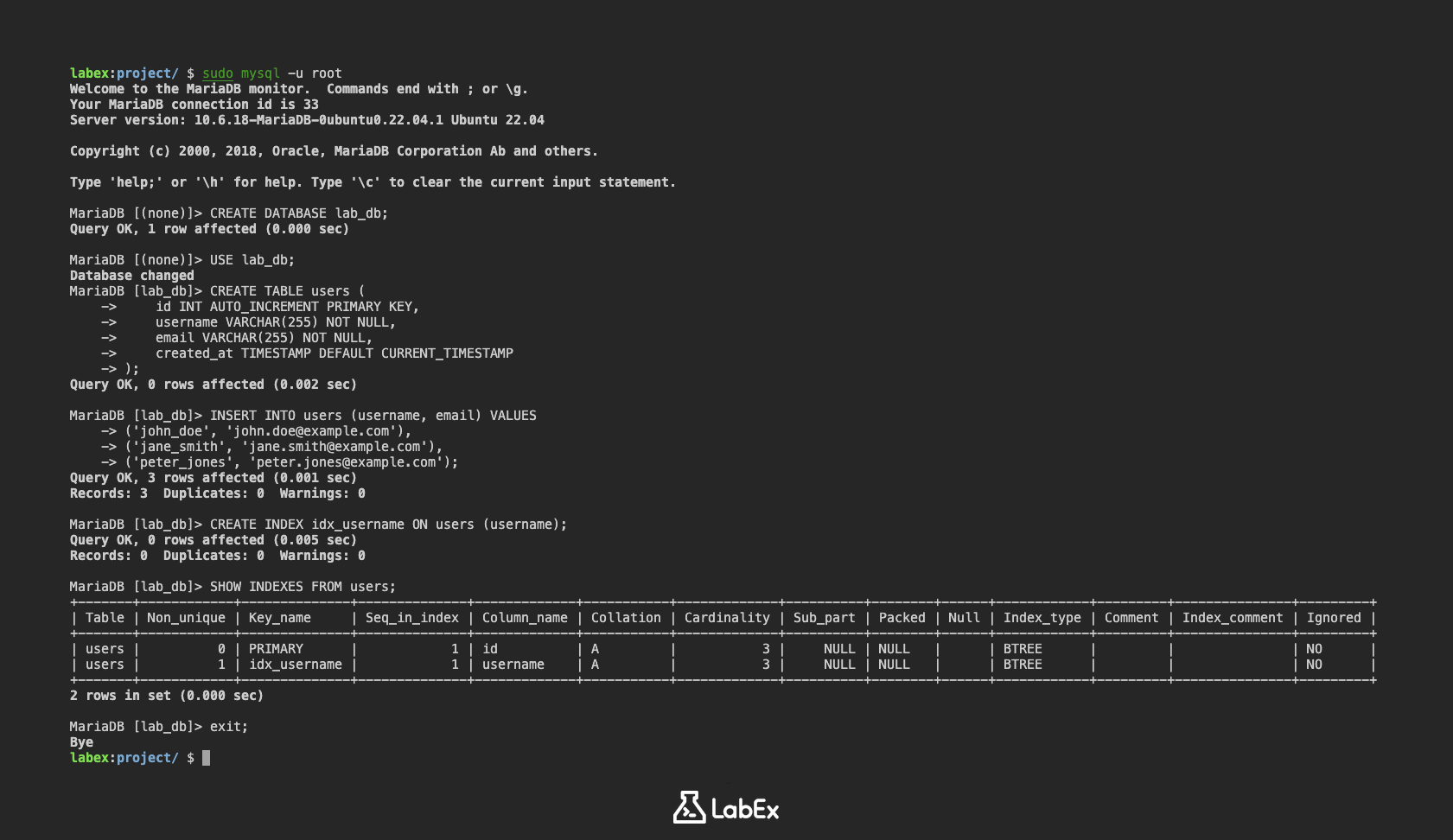
SHOW INDEXES FROM users;
出力には、users テーブルのインデックスの詳細が表示され、作成したばかりの idx_username インデックスも含まれます。Key_name が idx_username で Column_name が username である行が表示されるはずです。
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 3 | NULL | NULL | | BTREE | | | NO |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
これで、テーブルに単一カラムインデックスを正常に作成できました。これにより、インデックス付きカラムに基づいてデータをフィルタリングするクエリのパフォーマンスが向上します。
EXPLAIN を使用してクエリプランを分析する
このステップでは、MySQL の EXPLAIN ステートメントを使用してクエリ実行プランを分析する方法を学びます。クエリプランを理解することは、パフォーマンスのボトルネックを特定し、クエリを最適化するために不可欠です。
クエリプランとは?
クエリプランとは、データベースエンジンがクエリを実行するために使用するロードマップです。テーブルへのアクセス順序、使用されるインデックス、およびデータを取得するために適用されるアルゴリズムを記述します。クエリプランを分析することで、データベースがどのようにクエリを実行しているかを理解し、改善の余地がある箇所を特定できます。
EXPLAIN ステートメントの使用
EXPLAIN ステートメントは、MySQL がクエリをどのように実行するかについての情報を提供します。関連するテーブル、使用されるインデックス、結合順序、およびクエリのパフォーマンスを理解するのに役立つその他の詳細が表示されます。
それでは、EXPLAIN を使用して簡単なクエリを分析してみましょう。
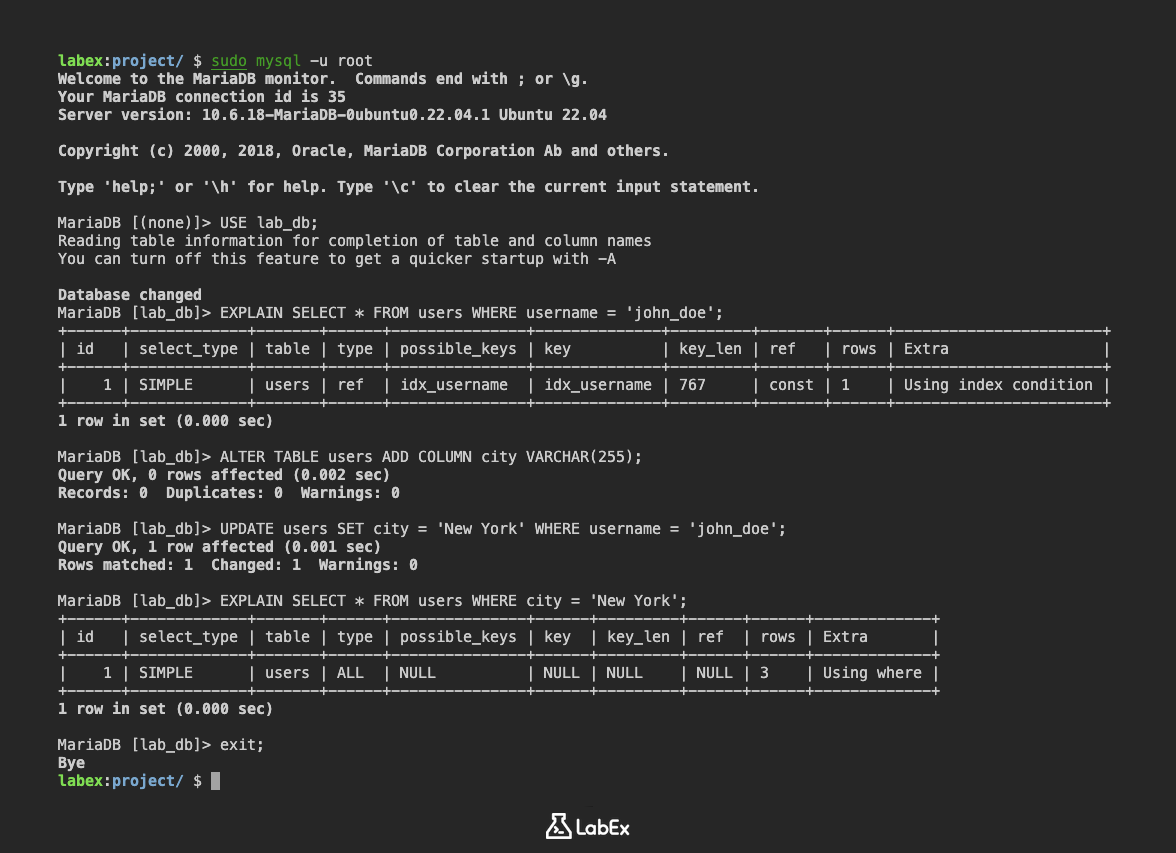
EXPLAIN SELECT * FROM users WHERE username = 'john_doe';
EXPLAIN ステートメントの出力は、いくつかのカラムを持つテーブルになります。以下に、最も重要なカラムのいくつかを説明します。
id: SELECT ステートメントの ID です。select_type: SELECT クエリのタイプです(例:SIMPLE、PRIMARY、SUBQUERY)。table: アクセスされているテーブルです。type: 結合タイプです。これは最も重要なカラムの 1 つです。一般的な値には以下のようなものがあります。system: テーブルには 1 行しかありません。const: テーブルには最大で 1 つの一致する行があり、クエリの開始時に読み取られます。eq_ref: 前のテーブルの行の各組み合わせに対して、このテーブルから 1 行が読み取られます。これは、インデックス付きカラムで結合する場合に使用されます。ref: 前のテーブルの行の各組み合わせに対して、このテーブルからすべての一致する行が読み取られます。これは、インデックス付きカラムで結合する場合に使用されます。range: インデックスを使用して、指定された範囲内の行のみが取得されます。index: フルインデックススキャンが実行されます。ALL: フルテーブルスキャンが実行されます。これは最も効率の悪いタイプです。
possible_keys: MySQL がテーブル内の行を見つけるために使用できるインデックスです。key: MySQL が実際に使用したインデックスです。key_len: MySQL が使用したキーの長さです。ref: インデックスと比較されるカラムまたは定数です。rows: MySQL がクエリを実行するために検査する必要があると推定する行数です。Extra: MySQL がクエリをどのように実行しているかに関する追加情報です。一般的な値には以下のようなものがあります。Using index: クエリはインデックスのみを使用して満たすことができます。Using where: MySQL はテーブルにアクセスした後、行をフィルタリングする必要があります。Using temporary: MySQL はクエリを実行するために一時テーブルを作成する必要があります。Using filesort: MySQL はテーブルにアクセスした後、行をソートする必要があります。
EXPLAIN 出力の解釈
SELECT * FROM users WHERE username = 'john_doe' クエリの場合、EXPLAIN の出力は次のようになります。
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | users | ref | idx_username | idx_username | 767 | const | 1 | Using index condition |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
この例では:
typeはrefであり、MySQL がインデックスを使用して一致する行を見つけていることを意味します。possible_keysとkeyの両方がidx_usernameを示しており、これは前のステップで作成したidx_usernameインデックスを MySQL が使用していることを意味します。rowsは1であり、MySQL はクエリを実行するために 1 行のみを検査する必要があると推定していることを意味します。
インデックスがないクエリの分析
次に、インデックスを使用しないクエリを分析してみましょう。まず、users テーブルに city という名前の新しいカラムを追加します。
ALTER TABLE users ADD COLUMN city VARCHAR(255);
次に、city で検索するクエリに対して EXPLAIN を実行します。まだ city カラムにデータを追加していないので、行の 1 つを更新しましょう。
UPDATE users SET city = 'New York' WHERE username = 'john_doe';
ここで、再度 EXPLAIN ステートメントを実行します。
EXPLAIN SELECT * FROM users WHERE city = 'New York';
出力は次のようになる場合があります。
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
この例では:
typeはALLであり、MySQL がフルテーブルスキャンを実行していることを意味します。possible_keysとkeyは両方ともNULLであり、MySQL がインデックスを使用していないことを意味します。rowsは3であり、MySQL はクエリを実行するためにテーブル内のすべての 3 行を検査する必要があると推定していることを意味します。ExtraはUsing whereを示しており、MySQL はテーブルにアクセスした後、行をフィルタリングする必要があることを意味します。
これは、クエリが最適化されておらず、city カラムのインデックスからメリットを得られる可能性があることを示しています。
複数カラムクエリ用の複合インデックスを追加する
このステップでは、MySQL で複合インデックスを作成する方法を学びます。複合インデックスは、テーブル内の 2 つ以上のカラムに対するインデックスです。これは、複数のカラムに基づいてデータをフィルタリングするクエリのパフォーマンスを大幅に向上させることができます。
複合インデックスとは?
複合インデックスは、複数のカラムをカバーするインデックスです。クエリで WHERE 句に複数のカラムが頻繁に使用される場合に役立ちます。複合インデックス内のカラムの順序は重要です。クエリの WHERE 句でカラムが同じ順序で指定されている場合に、インデックスは最も効果的です。
users テーブルに、さまざまな都市を含むデータをさらに追加しましょう。
INSERT INTO users (username, email, city) VALUES
('alice_brown', 'alice.brown@example.com', 'Los Angeles'),
('bob_davis', 'bob.davis@example.com', 'Chicago'),
('charlie_wilson', 'charlie.wilson@example.com', 'New York'),
('david_garcia', 'david.garcia@example.com', 'Los Angeles');
複合インデックスの作成
例えば、city と username の両方でユーザーをフィルタリングするクエリを頻繁に実行するとします。この場合、city および username カラムに複合インデックスを作成できます。
CREATE INDEX idx_city_username ON users (city, username);
このステートメントは、users テーブルの city および username カラムに idx_city_username という名前のインデックスを作成します。
インデックスの検証
SHOW INDEXES コマンドを使用して、インデックスが作成されたことを確認できます。
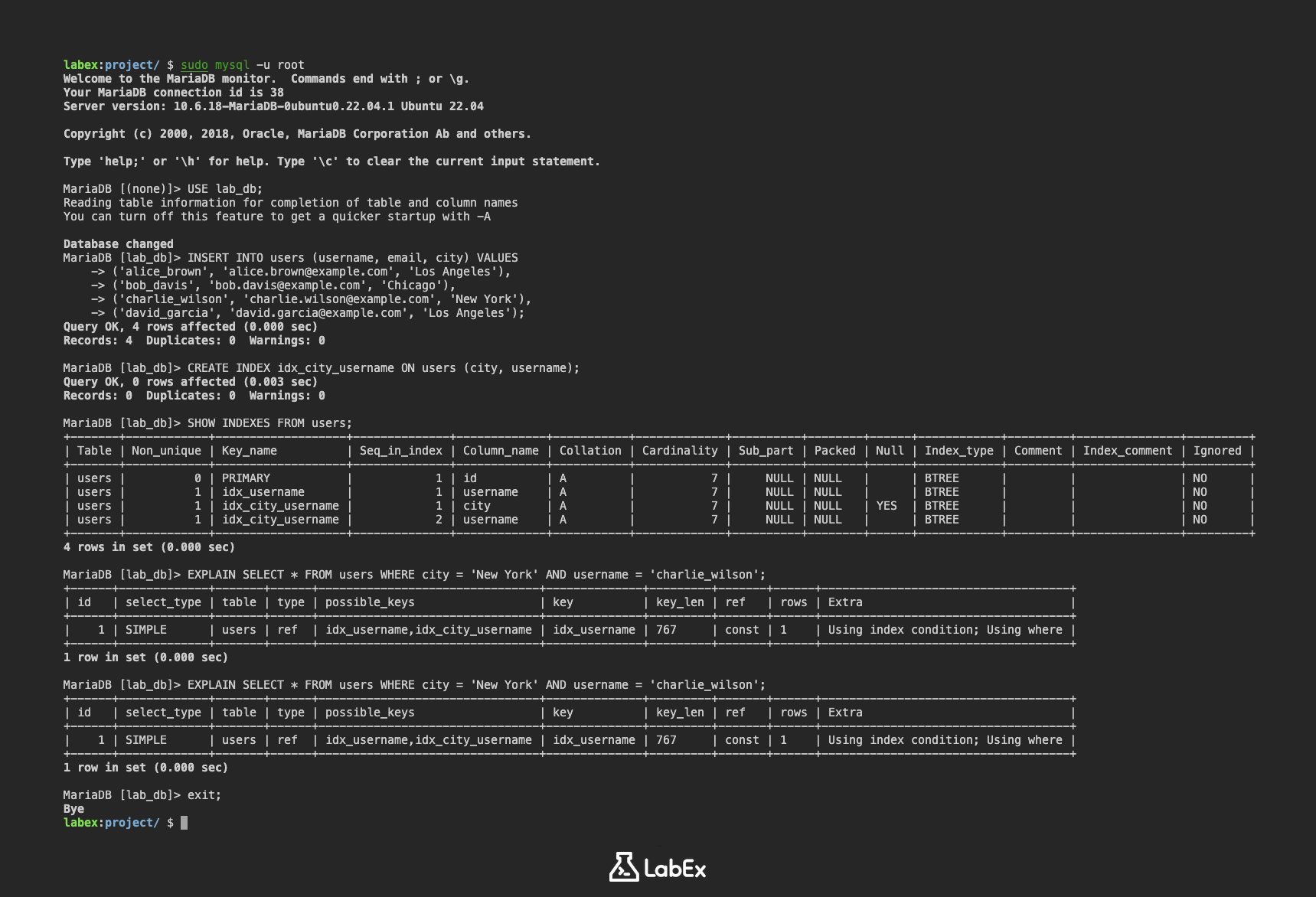
SHOW INDEXES FROM users;
出力には、users テーブルのインデックスの詳細が表示され、作成したばかりの idx_city_username インデックスも含まれます。idx_city_username に対して、city カラム用と username カラム用の 2 つの行が表示されるはずです。
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
複合インデックスの使用
複合インデックスの利点を確認するために、EXPLAIN コマンドを使用して、WHERE 句で city と username の両方のカラムを使用するクエリを分析できます。
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
EXPLAIN の出力は、クエリが idx_city_username インデックスを使用していることを示します。これは、データベースがテーブル全体をスキャンすることなく、一致する行を迅速に見つけることができることを意味します。出力の possible_keys および key カラムを確認してください。インデックスが使用されている場合、これらのカラムに idx_city_username が表示されます。
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | users | ref | idx_username,idx_city_username | idx_username | 767 | const | 1 | Using index condition; Using where |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
インデックス内のカラムの順序
複合インデックス内のカラムの順序は重要です。(city, username) の代わりに (username, city) にインデックスを作成した場合、city でフィルタリングし、次に username でフィルタリングするクエリでは、インデックスの効果が低下します。
例えば、(username, city) にインデックスがあり、次のクエリを実行した場合:
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
MySQL はインデックスを使用しないか、部分的にしか使用しない可能性があります。なぜなら、city カラムがインデックスの先頭カラムではないからです。
未使用インデックスを削除する
このステップでは、MySQL で未使用のインデックスを削除する方法を学びます。インデックスはクエリのパフォーマンスを大幅に向上させることができますが、書き込み操作(挿入、更新、削除)にもオーバーヘッドを追加します。したがって、使用されなくなったインデックスを特定して削除することが重要です。
未使用のインデックスを削除する理由
未使用のインデックスはディスク容量を消費し、書き込み操作を遅くする可能性があります。テーブルのデータが変更されると、データベースエンジンはテーブル上のすべてのインデックスも更新する必要があります。インデックスがどのクエリにも使用されていない場合、それは単に不要なオーバーヘッドを追加しているだけです。
前のステップで、username カラムに idx_username という名前のインデックスを作成しました。クエリパターンを分析した後、このインデックスがもはや使用されていないと判断したと仮定しましょう。
インデックスの削除
idx_username インデックスを削除するには、DROP INDEX ステートメントを使用できます。
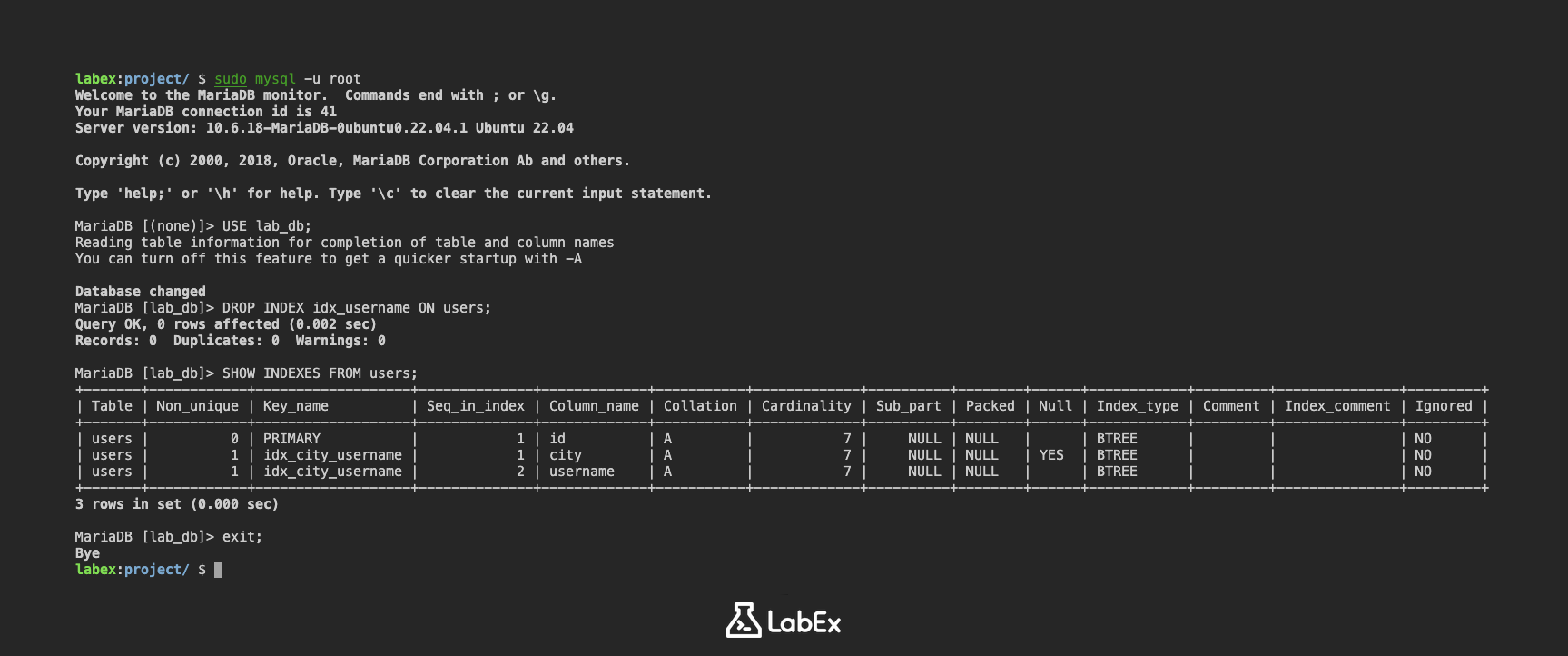
DROP INDEX idx_username ON users;
このステートメントは、users テーブルから idx_username インデックスを削除します。
インデックス削除の検証
SHOW INDEXES コマンドを使用して、インデックスが削除されたことを確認できます。
SHOW INDEXES FROM users;
出力には、users テーブルのインデックスの詳細が表示されます。出力に idx_username インデックスが表示されなくなっているはずです。
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
未使用のインデックスの特定
実際のシナリオでは、未使用のインデックスを特定することは困難な場合があります。MySQL は、このタスクを支援するためのいくつかのツールとテクニックを提供しています。
- MySQL Enterprise Audit: この機能を使用すると、サーバーで実行されたすべてのクエリをログに記録できます。その後、クエリログを分析して、どのインデックスが使用されているかを特定できます。
- Performance Schema: Performance Schema は、インデックスの使用状況を含む、サーバーのパフォーマンスに関する詳細情報を提供します。
- サードパーティ製ツール: いくつかのサードパーティ製ツールは、インデックスの使用状況を監視し、未使用のインデックスを特定するのに役立ちます。
インデックスの使用状況を定期的に監視し、未使用のインデックスを削除することで、データベース全体のパフォーマンスを向上させることができます。
すべてのステップが完了したので、MySQL コンソールを終了しましょう。
exit;
まとめ
この実験では、MySQL でクエリパフォーマンスを向上させるために単一カラムインデックスを作成する方法を学びました。また、EXPLAIN ステートメントを使用してクエリ実行計画を分析し、パフォーマンスのボトルネックを特定する方法も学びました。さらに、マルチカラムクエリのための複合インデックスの作成や、データベースの効率を維持するための未使用インデックスの削除を実践しました。インデックスを効果的に理解し活用することは、データベースパフォーマンスを最適化するための基本的なスキルです。


