
はじめに
この実験では、C++ の関数について学びます。関数を定義して呼び出す方法、および関数に引数を渡す方法を学びます。
コンテンツプレビュー
時には、特定のコードの一部を何度も使用する必要があります。それらを「サブルーチン」(関数)に入れ、この関数を何度も「呼び出す」方が、保守や理解がしやすくなります。
関数を使用する際には、2 つの当事者が関係します。関数を呼び出す「呼び出し元」と、呼び出される「関数」です。呼び出し元は関数に「引数」を渡します。関数はこれらの引数を受け取り、関数の本体でプログラムされた操作を実行し、1 つの結果を呼び出し元に返します。
関数の使用
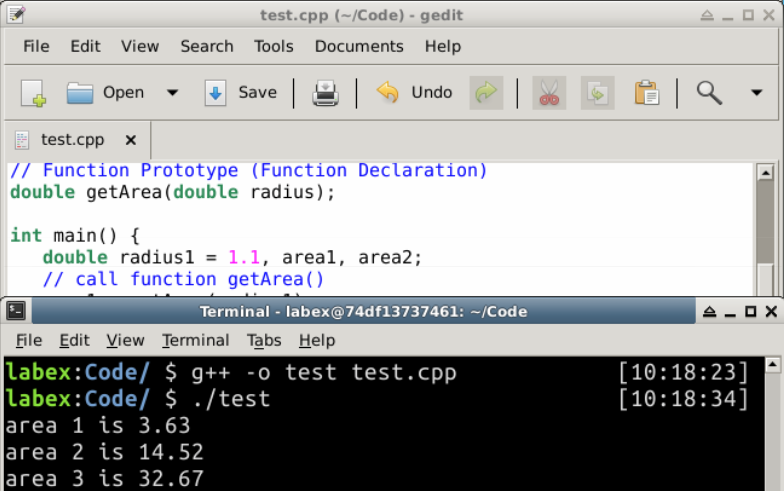
何度も円の面積を評価する必要がある場合、getArea() と呼ばれる関数を書き、必要に応じて再利用する方が良いでしょう。
/* テスト関数 */
#include <iostream>
using namespace std;
const int PI = 3.14159265;
// 関数プロトタイプ(関数宣言)
double getArea(double radius);
int main() {
double radius1 = 1.1, area1, area2;
// 関数 getArea() を呼び出す
area1 = getArea(radius1);
cout << "面積 1 は " << area1 << endl;
// 関数 getArea() を呼び出す
area2 = getArea(2.2);
cout << "面積 2 は " << area2 << endl;
// 関数 getArea() を呼び出す
cout << "面積 3 は " << getArea(3.3) << endl;
}
// 関数定義
// 半径を指定して円の面積を返す
double getArea(double radius) {
return radius * radius * PI;
}
出力:
面積1は 3.63
面積2は 14.52
面積3は 32.67
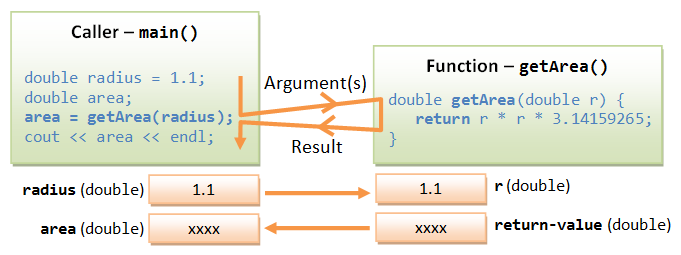
C++ では、関数を使用する前に関数プロトタイプを宣言し、関数定義を提供する必要があります。関数定義の本体には、プログラムされた操作が含まれます。
関数定義の構文は次のとおりです。
returnValueType functionName ( parameterList ) {
functionBody ;
}
関数プロトタイプは、コンパイラに関数のインターフェイス、つまり戻り値の型、関数名、およびパラメータ型リスト(パラメータの数と型)を伝えます。この関数は、ファイル内のどこで定義しても構いません。たとえば、
// 関数プロトタイプ - 関数を使用する前に配置します。
double getArea(double); // パラメータ名なし
double getArea(double radius); // パラメータ名は無視されますが、ドキュメントとして役立ちます
「void」戻り値の型
呼び出し元に値を返す必要がない場合、戻り値の型を void と宣言できます。関数の本体では、戻り値なしの "return;" 文を使用して、制御を呼び出し元に戻すことができます。
実引数と仮引数
上の例では、getArea(double radius) のシグネチャで宣言された変数 (double radius) は、仮引数 と呼ばれます。そのスコープは関数の本体の中です。関数が呼び出し元によって呼び出されるとき、呼び出し元はいわゆる 実引数(または 引数)を提供する必要があります。その値は、実際の計算に使用されます。たとえば、"area1 = getArea(radius1)" を介して関数が呼び出されるとき、radius1 は実引数であり、値は 1.1 です。
関数のローカル変数とパラメータのスコープ
関数内で宣言されたすべての変数、関数のパラメータを含めて、関数だけが利用できます。それらは関数が呼び出されたときに作成され、関数が返った後に解放(破棄)されます。それらは ローカル変数 と呼ばれます。なぜなら、それらは関数に固有であり、関数の外では利用できないからです。
デフォルト引数
C++ では、関数に対していわゆる デフォルト引数 が導入されています。これらのデフォルト値は、呼び出し元が関数を呼び出す際に対応する実引数を省略した場合に使用されます。デフォルト引数は関数プロトタイプで指定され、関数定義では繰り返し指定できません。デフォルト引数はその位置に基づいて解決されます。したがって、曖昧さを避けるために、末尾の 引数の代わりにのみ使用できます。たとえば、
/* テスト関数のデフォルト引数 */
#include <iostream>
using namespace std;
// 関数プロトタイプ - ここでデフォルト引数を指定する
int fun1(int = 1, int = 2, int = 3);
int fun2(int, int, int = 3);
int main() {
cout << fun1(4, 5, 6) << endl; // デフォルトなし
cout << fun1(4, 5) << endl; // 4, 5, 3(デフォルト)
cout << fun1(4) << endl; // 4, 2(デフォルト), 3(デフォルト)
cout << fun1() << endl; // 1(デフォルト), 2(デフォルト), 3(デフォルト)
cout << fun2(4, 5, 6) << endl; // デフォルトなし
cout << fun2(4, 5) << endl; // 4, 5, 3(デフォルト)
// cout << fun2(4) << endl;
// エラー: 関数 'int fun2(int, int, int)' に対する引数が不十分
}
int fun1(int n1, int n2, int n3) {
// 関数定義でデフォルト引数を繰り返してはならない
return n1 + n2 + n3;
}
int fun2(int n1, int n2, int n3) {
return n1 + n2 + n3;
}
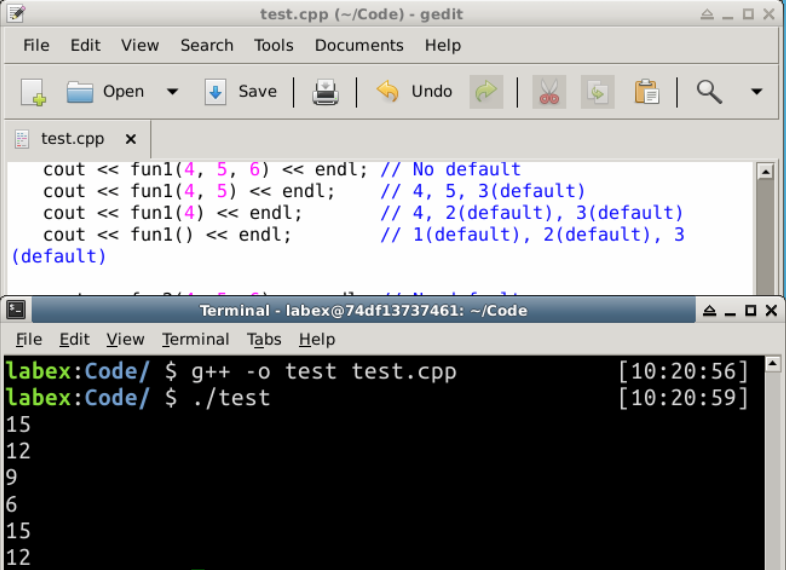
出力:
15
12
9
6
15
12
関数のオーバーロード
C++ では、関数のオーバーロード(または 関数のポリモーフィズム)が導入されており、これにより、同じ関数名の複数のバージョンをパラメータリスト(パラメータの数、型または順序)で区別することができます。オーバーロードされた関数は、戻り値の型では区別できません(コンパイルエラー)。呼び出し元の引数リストに一致するバージョンが選択されて実行されます。たとえば、
/* テスト関数のオーバーロード */
#include <iostream>
using namespace std;
void fun(int, int, int); // バージョン 1
void fun(double, int); // バージョン 2
void fun(int, double); // バージョン 3
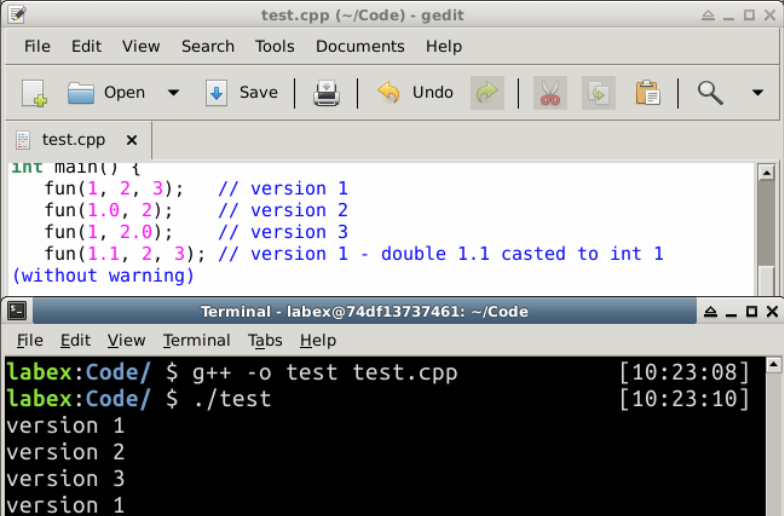
int main() {
fun(1, 2, 3); // バージョン 1
fun(1.0, 2); // バージョン 2
fun(1, 2.0); // バージョン 3
fun(1.1, 2, 3); // バージョン 1 - double 型の 1.1 が int 型の 1 にキャストされます(警告なし)
// fun(1, 2, 3, 4);
// エラー: 'fun(int, int, int, int)' への呼び出しに対応する関数が見つかりません
// fun(1, 2);
// エラー: オーバーロードされた 'fun(int, int)' の呼び出しが曖昧です
// 注:候補は次の通りです。
// void fun(double, int)
// void fun(int, double)
// fun(1.0, 2.0);
// エラー: オーバーロードされた 'fun(double, double)' の呼び出しが曖昧です
}
void fun(int n1, int n2, int n3) { // バージョン 1
cout << "バージョン 1" << endl;
}
void fun(double n1, int n2) { // バージョン 2
cout << "バージョン 2" << endl;
}
void fun(int n1, double n2) { // バージョン 3
cout << "バージョン 3" << endl;
}
出力:
バージョン1
バージョン2
バージョン3
バージョン1
関数と配列
配列を関数に渡すこともできます。ただし、配列のサイズも関数に渡す必要があります。これは、呼び出された関数内の配列引数から配列のサイズを判断する方法がないためです。たとえば、
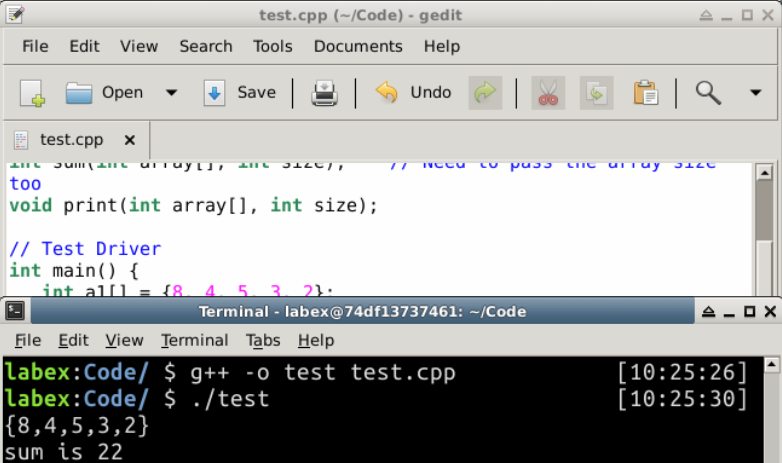
/* 配列の合計を計算する関数 */
#include <iostream>
using namespace std;
// 関数プロトタイプ
int sum(int array[], int size); // 配列のサイズも渡す必要があります
void print(int array[], int size);
// テストドライバ
int main() {
int a1[] = {8, 4, 5, 3, 2};
print(a1, 5); // {8,4,5,3,2}
cout << "合計は " << sum(a1, 5) << endl; // 合計は 22
}
// 関数定義
// 与えられた配列の合計を返す
int sum(int array[], int size) {
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += array[i];
}
return sum;
}
// 与えられた配列の内容を表示する
void print(int array[], int size) {
cout << "{";
for (int i = 0; i < size; ++i) {
cout << array[i];
if (i < size - 1) {
cout << ",";
}
}
cout << "}" << endl;
}
出力:
{8,4,5,3,2}
合計は 22
値渡しと参照渡しの違い
パラメータを関数に渡す方法は 2 通りあります。値渡し と 参照渡し です。
値渡し
値渡しでは、引数の「コピー」が作成されて関数に渡されます。呼び出された関数はこの「クローン」に対して動作し、元のコピーを変更することはできません。C/C++ では、基本型(たとえば int や double)は値渡しで渡されます。
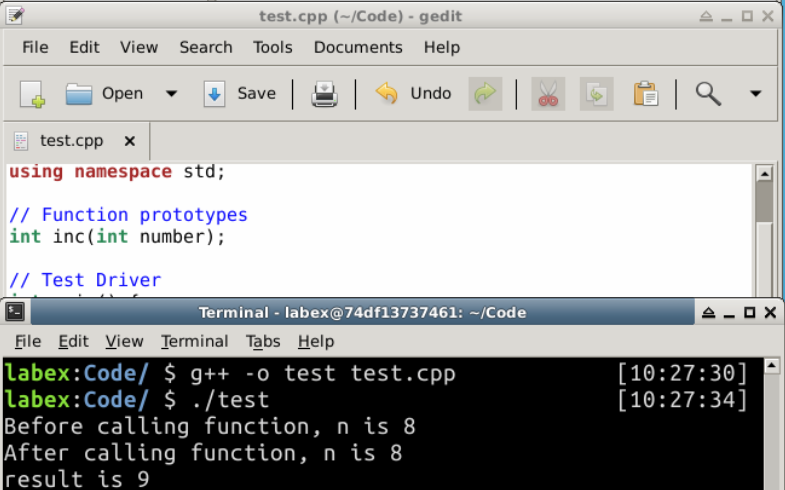
/* 基本型は値渡しで関数に渡されます */
#include <iostream>
using namespace std;
// 関数プロトタイプ
int inc(int number);
// テストドライバ
int main() {
int n = 8;
cout << "関数を呼び出す前、n は " << n << endl; // 8
int result = inc(n);
cout << "関数を呼び出した後、n は " << n << endl; // 8
cout << "result は " << result << endl; // 9
}
// 関数定義
// number+1 を返す
int inc(int number) {
++number; // パラメータを変更しますが、呼び出し元には影響しません
return number;
}
出力:
関数を呼び出す前、nは 8
関数を呼び出した後、nは 8
resultは 9
参照渡し
一方、参照渡しでは、呼び出し元の変数の 参照 が関数に渡されます。言い換えると、呼び出された関数は同じデータに対して動作します。呼び出された関数がパラメータを変更する場合、同じ呼び出し元のコピーも変更されます。C/C++ では、配列は参照渡しで渡されます。C/C++ では関数から配列を返すことはできません。
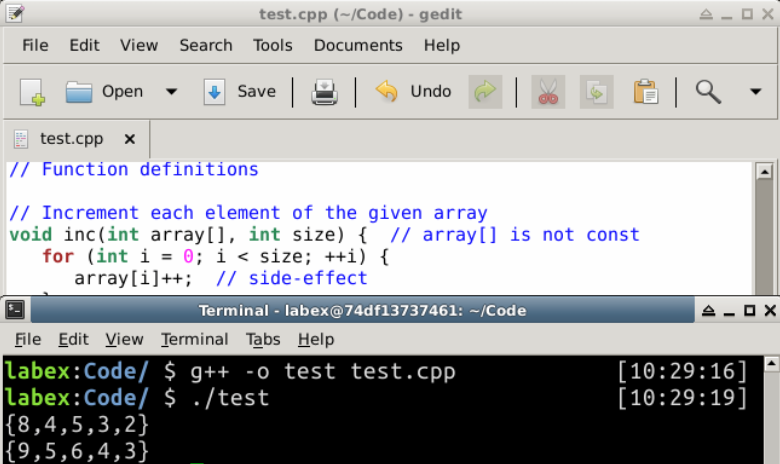
/* 配列の各要素をインクリメントする関数 */
#include <iostream>
using namespace std;
// 関数プロトタイプ
void inc(int array[], int size);
void print(int array[], int size);
// テストドライバ
int main() {
int a1[] = {8, 4, 5, 3, 2};
// インクリメント前
print(a1, 5); // {8,4,5,3,2}
// インクリメントする
inc(a1, 5); // 配列は参照渡しで渡されます(副作用があります)
// インクリメント後
print(a1, 5); // {9,5,6,4,3}
}
// 関数定義
// 与えられた配列の各要素をインクリメントする
void inc(int array[], int size) { // array[] は const ではありません
for (int i = 0; i < size; ++i) {
array[i]++; // 副作用
}
}
// 与えられた配列の内容を表示する
void print(int array[], int size) {
cout << "{";
for (int i = 0; i < size; ++i) {
cout << array[i];
if (i < size - 1) {
cout << ",";
}
}
cout << "}" << endl;
}
出力:
{8,4,5,3,2}
{9,5,6,4,3}
const 関数パラメータ
参照を渡す際にはできる限り const を使用します。これにより、不注意にパラメータを変更することを防ぎ、多くのプログラミングエラーから守ることができます。
線形探索では、探索キーを配列の各要素と線形に比較します。一致が見つかれば、一致した要素のインデックスを返します。そうでなければ、-1 を返します。線形探索の計算量は O(n) です。
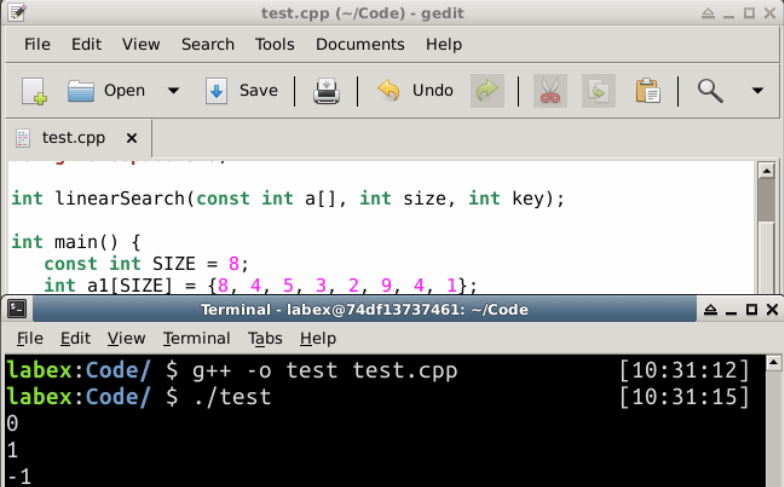
/* 線形探索を使って配列内の指定されたキーを検索する */
#include <iostream>
using namespace std;
int linearSearch(const int a[], int size, int key);
int main() {
const int SIZE = 8;
int a1[SIZE] = {8, 4, 5, 3, 2, 9, 4, 1};
cout << linearSearch(a1, SIZE, 8) << endl; // 0
cout << linearSearch(a1, SIZE, 4) << endl; // 1
cout << linearSearch(a1, SIZE, 99) << endl; // 8 (見つかりません)
}
// 配列内の指定されたキーを検索する
// 見つかれば、配列インデックス [0, size-1] を返します。そうでなければ、size を返します
int linearSearch(const int a[], int size, int key) {
for (int i = 0; i < size; ++i) {
if (a[i] == key) return i;
}
// a[0] = 1;
// エラーになります。a[] は const なので、読み取り専用です
return -1;
}
出力:
0
1
-1
参照パラメータを通じた参照渡し
& で表される 参照パラメータ を使って、基本型のパラメータを参照渡しすることができます。
/* 基本型のパラメータの参照渡しをテストする
参照宣言を通じて */
#include <iostream>
using namespace std;
int squareByValue (int number); // 値渡し
void squareByReference (int &number); // 参照渡し
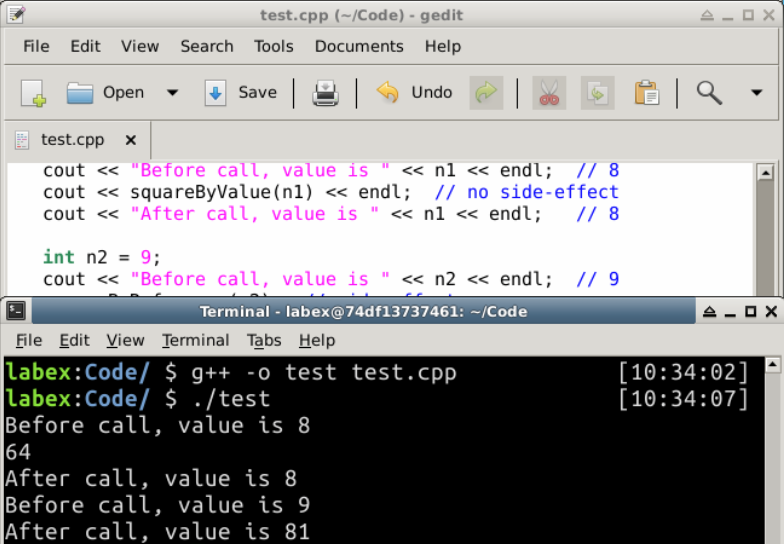
int main() {
int n1 = 8;
cout << "呼び出し前、値は " << n1 << endl; // 8
cout << squareByValue(n1) << endl; // 副作用なし
cout << "呼び出し後、値は " << n1 << endl; // 8
int n2 = 9;
cout << "呼び出し前、値は " << n2 << endl; // 9
squareByReference(n2); // 副作用
cout << "呼び出し後、値は " << n2 << endl; // 81
}
// パラメータを値渡し - 副作用なし
int squareByValue (int number) {
return number * number;
}
// 参照 (&) として宣言することでパラメータを参照渡し
// - 呼び出し元に副作用があります
void squareByReference (int &number) {
number = number * number;
}
出力:
呼び出し前、値は 8
64
呼び出し後、値は 8
呼び出し前、値は 9
呼び出し後、値は 81
2.8 数学関数
C++ は、<cmath> ライブラリに多くの一般的な数学関数を提供しています。
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x):
引数の型と戻り値の型は float、double、long double です。
sinh(x), cosh(x), tanh(x):
双曲線関数です。
pow(x, y), sqrt(x):
べき乗と平方根です。
ceil(x), floor(x):
浮動小数点数の切り上げと切り捨て整数を返します。
fabs(x), fmod(x, y):
浮動小数点数の絶対値と剰余です。
exp(x), log(x), log10(x):
指数関数と対数関数です。
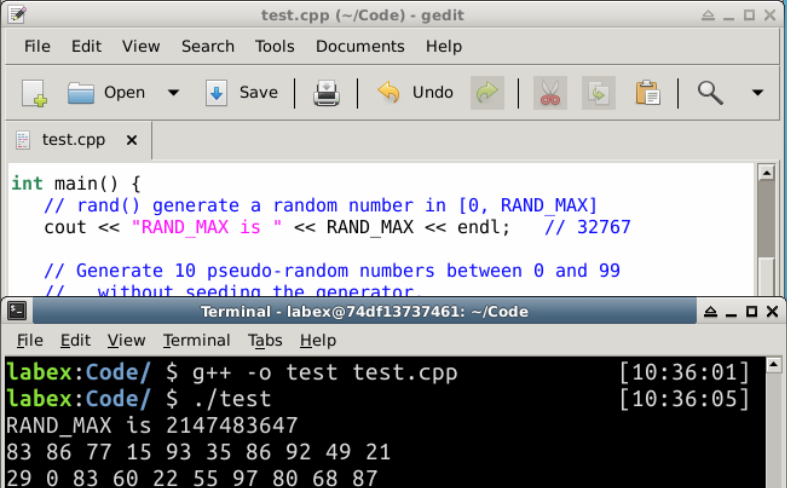
cstdlib ヘッダー(C の stdlib.h から移植)は、0 から RAND_MAX(範囲含む)までの擬似乱数整数を生成する rand() 関数を提供しています。
/* 乱数生成をテストする */
#include <iostream>
#include <cstdlib> // rand()、srand() のため
#include <ctime> // time() のため
using namespace std;
int main() {
// rand() は [0, RAND_MAX] の範囲で乱数を生成します
cout << "RAND_MAX は " << RAND_MAX << endl; // 32767
// 生成器にシードを与えずに、0 から 99 までの 10 個の擬似乱数を生成します
// このプログラムを実行するたびに同じシーケンスが得られます
for (int i = 0; i < 10; ++i) {
cout << rand() % 100 << " "; // <cstdlib> ヘッダーが必要です
}
cout << endl;
// 現在の時刻で乱数生成器にシードを与えます
srand(time(0)); // <cstdlib> と <ctime> ヘッダーが必要です
// 10 個の擬似乱数を生成します
// 現在の時刻が異なるため、異なる実行では異なるシーケンスが得られます
for (int i = 0; i < 10; ++i) {
cout << rand() % 100 << " "; // <cstdlib> ヘッダーが必要です
}
cout << endl;
}
出力:
RAND_MAX は 2147483647
83 86 77 15 93 35 86 92 49 21
29 0 83 60 22 55 97 80 68 87
- name: check if keyword exist
script: |
#!/bin/bash
grep -i 'rand' /home/labex/Code/test.cpp
error: Oops! We find that you didn't use "rand()" method in "test.cpp".
timeout: 3
まとめ
関数を使用する利点は以下の通りです。
- 分割統治法:シンプルで小さなピースやコンポーネントからプログラムを構築します。プログラムを独立したタスクにモジュール化します。
- コードの重複を避ける:コピー&ペーストは簡単ですが、すべてのコピーを維持して同期させるのは難しいです。
- ソフトウェアの再利用:関数をライブラリコードにパッケージ化することで、他のプログラムで再利用できます。


