
Introduction
Bienvenue dans ce laboratoire pratique sur la classification K-Nearest Neighbors (KNN) avec scikit-learn ! Scikit-learn est une bibliothèque Python puissante et populaire pour l'apprentissage automatique. L'algorithme KNN est l'un des algorithmes de classification les plus simples mais les plus efficaces. Il classe un nouveau point de données en fonction de la classe majoritaire de ses 'k' voisins les plus proches dans l'espace des caractéristiques. Dans ce laboratoire, vous parcourrez le processus complet de construction d'un modèle d'apprentissage automatique : chargement du célèbre jeu de données Iris, division en ensembles d'entraînement et de test, initialisation et entraînement d'un classifieur KNN, et enfin, utilisation du modèle entraîné pour faire des prédictions sur de nouvelles données inédites. À la fin de ce laboratoire, vous aurez une solide compréhension du flux de travail fondamental pour l'apprentissage supervisé dans scikit-learn.
Charger l'ensemble de données Iris avec datasets.load_iris()
Dans cette étape, vous commencerez par charger le jeu de données nécessaire. Nous utiliserons le jeu de données classique Iris, qui est commodément inclus avec scikit-learn. Tout d'abord, vous devez importer le module datasets de sklearn. Ensuite, vous appellerez la fonction load_iris() pour obtenir les données.
Comprendre load_iris() :
- Type de retour : Renvoie un objet
Bunch(similaire à un dictionnaire) contenant :.data: Matrice des caractéristiques (150 échantillons × 4 caractéristiques : longueur du sépale, largeur du sépale, longueur du pétale, largeur du pétale).target: Tableau des étiquettes (espèces : 0=setosa, 1=versicolor, 2=virginica).feature_names: Noms des 4 caractéristiques.target_names: Noms des 3 espèces
- Objectif : Fournit un jeu de données propre et prêt à l'emploi pour la pratique de la classification
Nous assignerons ceux-ci aux variables X et y, respectivement, ce qui est une convention courante en apprentissage automatique (X pour les caractéristiques, y pour les étiquettes).
Ouvrez le fichier main.py dans l'éditeur à gauche et ajoutez le code suivant.
from sklearn import datasets
## Load the iris dataset
iris = datasets.load_iris()
## Assign features to X and labels to y
X = iris.data
y = iris.target
## You can print the shape to see the dimensions
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
Maintenant, exécutez le script depuis le terminal pour voir la sortie.
python3 main.py
Vous devriez voir les dimensions de la matrice des caractéristiques et du vecteur d'étiquettes.
Features shape: (150, 4)
Labels shape: (150,)
Cela nous indique que nous avons 150 échantillons (fleurs) et 4 caractéristiques pour chaque échantillon.
Diviser les données en ensembles d'entraînement et de test avec train_test_split de sklearn.model_selection
Dans cette étape, vous diviserez le jeu de données en deux parties : un ensemble d'entraînement et un ensemble de test. C'est une étape cruciale en apprentissage automatique pour évaluer les performances d'un modèle sur des données inédites.
Comprendre les paramètres de train_test_split() :
test_size=0.3: Réserve 30 % des données pour le test, 70 % pour l'entraînementrandom_state=42: Assure des divisions reproductibles (même graine aléatoire à chaque exécution)- Objectif : Empêche le surapprentissage en évaluant le modèle sur des données inédites
- Sortie : Renvoie quatre tableaux : X_train, X_test, y_train, y_test
Nous entraînons le modèle sur l'ensemble d'entraînement, puis nous testons sa capacité prédictive sur l'ensemble de test. Scikit-learn fournit une fonction pratique appelée train_test_split à cet effet. Vous devez l'importer depuis sklearn.model_selection.
Ajoutez le code suivant à la fin de votre fichier main.py.
from sklearn.model_selection import train_test_split
## Split data into training and testing sets
## test_size=0.3 means 30% of the data will be used for testing
## random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Print the shapes of the new sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
Maintenant, exécutez à nouveau le script.
python3 main.py
La sortie inclura désormais les formes de vos ensembles d'entraînement et de test.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Initialiser KNeighborsClassifier avec n_neighbors=3 depuis sklearn.neighbors
Dans cette étape, vous initialiserez le classificateur K-Nearest Neighbors (Voisins les plus proches). L'idée principale du KNN est de prédire la classe d'un point de données en examinant les classes de ses 'k' voisins les plus proches.
Comprendre les paramètres de KNeighborsClassifier() :
n_neighbors=3: Nombre de voisins les plus proches à considérer pour la prédiction- Valeurs plus petites (par exemple, 1-3) : Plus sensible au bruit, peut surapprendre (overfit)
- Valeurs plus grandes (par exemple, 5-7) : Limites de décision plus lisses, plus robustes
- Comportement de l'algorithme : Pour la prédiction, trouve les k points d'entraînement les plus proches et utilise le vote majoritaire
- Pas de phase d'entraînement : Le KNN est un "apprenant paresseux" (lazy learner) – il stocke les données d'entraînement et effectue les calculs lors de la prédiction
KNeighborsClassifier est la classe dans scikit-learn qui implémente cet algorithme. Vous devez l'importer depuis sklearn.neighbors. Créons un objet classificateur et nommons-le clf.
Ajoutez le code suivant à la fin de votre fichier main.py.
from sklearn.neighbors import KNeighborsClassifier
## Initialize the KNN classifier with n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
Ce code ne produit aucune sortie, mais il crée l'objet classificateur en mémoire, prêt à être entraîné à l'étape suivante.
Entraîner le classifieur avec clf.fit(X_train, y_train)
Dans cette étape, vous allez entraîner, ou "ajuster" (fit), le classificateur en utilisant vos données d'entraînement. Pour l'algorithme KNN, la phase d'entraînement est très simple : elle consiste simplement à stocker l'ensemble du jeu de données d'entraînement (X_train et y_train).
Comprendre la méthode .fit() :
- Paramètres d'entrée :
X_train(matrice des caractéristiques),y_train(étiquettes cibles) - Ce qu'elle fait : Stocke les données d'entraînement en mémoire pour une utilisation ultérieure lors de la prédiction
- Spécificité du KNN : Contrairement à d'autres algorithmes, le KNN n'apprend pas de paramètres lors de l'ajustement (fit)
- Objectif : Prépare le modèle à faire des prédictions sur de nouvelles données
Lorsqu'une prédiction est requise pour un nouveau point, l'algorithme trouve les 'k' points les plus proches dans cet ensemble de données stocké et prend une décision. Pour entraîner le modèle dans scikit-learn, vous utilisez la méthode .fit() de l'objet classificateur. La méthode prend les caractéristiques d'entraînement (X_train) et les étiquettes d'entraînement correspondantes (y_train) comme arguments.
Ajoutez la ligne de code suivante à la fin de main.py.
## Train the classifier using the training data
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
Après avoir ajouté le code, exécutez le script.
python3 main.py
Vous verrez un message de confirmation indiquant que le classificateur a été entraîné.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
Prédire les classes avec clf.predict(X_test)
Dans cette dernière étape, vous utiliserez le classificateur entraîné pour faire des prédictions sur les données de test. Maintenant que le modèle a "appris" à partir des données d'entraînement, nous pouvons lui fournir les caractéristiques de l'ensemble de test (X_test), qu'il n'a jamais vues auparavant, et lui demander de prédire la classe pour chaque échantillon.
Comprendre la méthode .predict() :
- Paramètre d'entrée :
X_test(matrice des caractéristiques des données non vues) - Processus de l'algorithme : Pour chaque échantillon de test, trouve les k voisins les plus proches dans les données d'entraînement et utilise le vote majoritaire
- Sortie : Tableau des étiquettes de classe prédites (même longueur que les échantillons d'entrée)
- Métrique de distance : Utilise la distance euclidienne par défaut pour mesurer la similarité entre les points
- Objectif : Évalue les performances du modèle sur de nouvelles données non vues
Ceci est réalisé à l'aide de la méthode .predict(). La méthode prend les caractéristiques de test (X_test) en entrée et renvoie un tableau des étiquettes prédites. Nous stockerons ces prédictions dans une variable appelée predictions et les afficherons dans la console. Vous pouvez également afficher les étiquettes réelles (y_test) pour voir à quel point le modèle a bien performé.
Ajoutez le dernier morceau de code à votre fichier main.py.
## Make predictions on the test data
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
Maintenant, exécutez le script complet.
python3 main.py
Vous verrez le tableau des étiquettes de classe prédites pour l'ensemble de test, suivi du tableau des étiquettes réelles.
... (previous output) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Note : Les tableaux de sortie sont affichés en entier ici. En comparant les deux tableaux, vous pouvez constater que les prédictions correspondent parfaitement aux étiquettes réelles, ce qui indique d'excellentes performances du modèle sur cet ensemble de test.
Visualiser les résultats de la classification KNN
Dans cette étape bonus, vous allez créer des visualisations pour mieux comprendre vos résultats de classification KNN. La visualisation vous aide à voir à quel point votre modèle a bien performé et à comprendre les frontières de décision créées par l'algorithme KNN.
Comprendre la visualisation des données en classification :
- Diagrammes de dispersion (Scatter plots) : Montrent les relations entre les caractéristiques et la distribution des classes
- Codage couleur : Différentes couleurs représentent différentes classes (espèces)
- Données d'entraînement vs. données de test : Aide à comprendre la généralisation du modèle
- Précision des prédictions : Comparaison visuelle des étiquettes prédites par rapport aux étiquettes réelles
Ajoutez le code suivant à la fin de votre fichier main.py pour créer les visualisations :
import matplotlib.pyplot as plt
import numpy as np
## Create subplots for multiple visualizations
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## Plot 1: Training data with different colors for each class
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## Plot 2: Test data predictions vs actual labels
## Create a comparison: correct predictions vs incorrect ones
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Plot correct predictions
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Plot incorrect predictions with different marker
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## Create legend
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## Additional: Show prediction accuracy
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
Exécutez le script mis à jour :
python3 main.py
Vous devriez voir une sortie incluant :
... (previous output) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
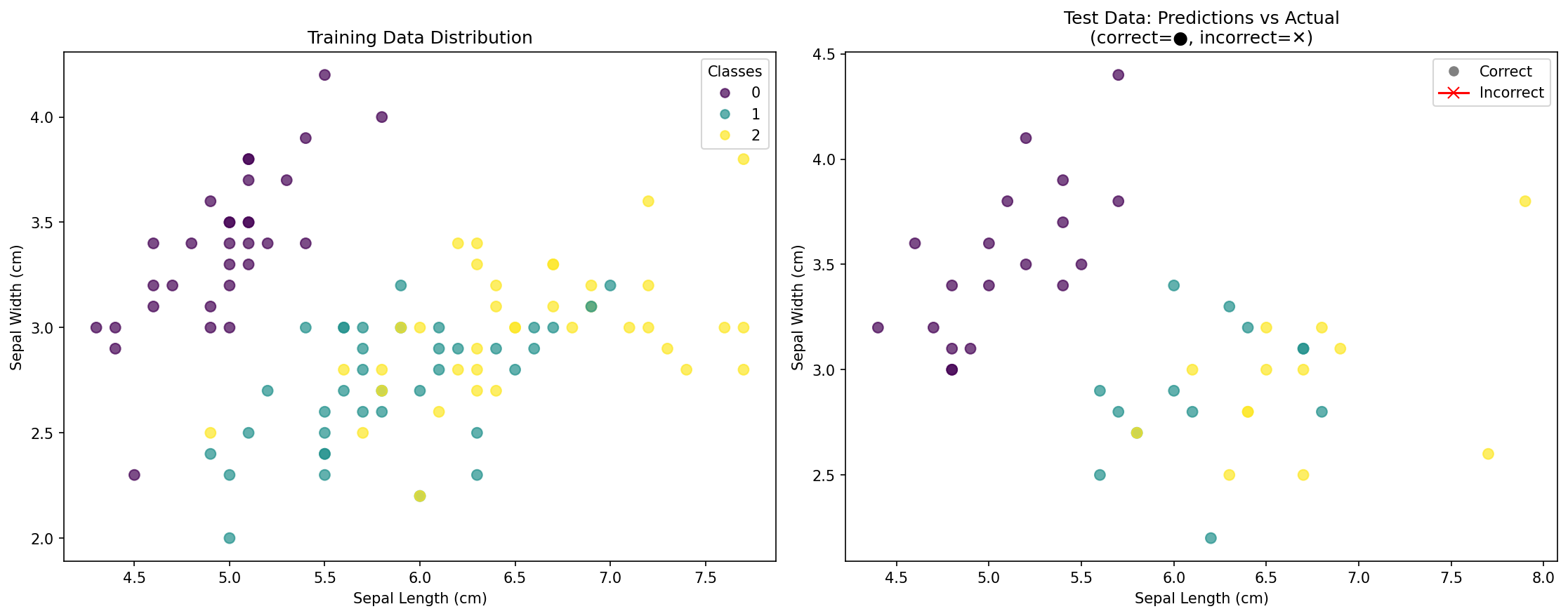
Ce que montre la visualisation :
- Graphique de gauche : Distribution des points de données d'entraînement, colorés par leur espèce réelle
- Graphique de droite : Points de données de test montrant :
- Cercles (●) : Points correctement classifiés
- Croix (✕) : Points incorrectement classifiés (s'il y en a)
- Score de précision : Pourcentage global des prédictions correctes
Cette visualisation vous aide à comprendre :
- Comment les classes sont distribuées dans l'espace des caractéristiques
- Si votre modèle sur-apprend (overfitting) ou généralise bien
- Les zones qui pourraient être difficiles pour la classification
- L'efficacité de votre modèle KNN visuellement
Résumé
Félicitations pour avoir terminé ce laboratoire ! Vous avez construit et entraîné avec succès un modèle de classification K-Nearest Neighbors (KNN) en utilisant scikit-learn. Vous avez appris le flux de travail fondamental d'un projet d'apprentissage automatique supervisé, qui comprend :
- Le chargement d'un ensemble de données à l'aide de
sklearn.datasets. - La division des données en ensembles d'entraînement et de test avec
train_test_split. - L'initialisation d'un classificateur, dans ce cas,
KNeighborsClassifier. - L'entraînement du modèle sur les données d'entraînement à l'aide de la méthode
.fit(). - La réalisation de prédictions sur de nouvelles données non vues à l'aide de la méthode
.predict(). - La visualisation des résultats pour comprendre les performances du modèle et les modèles de décision.
Ce processus constitue la base de nombreuses tâches d'apprentissage automatique. À partir de là, vous pourriez explorer comment évaluer plus formellement les performances de votre modèle à l'aide de métriques telles que la précision (accuracy), la précision (precision) et le rappel (recall), ou expérimenter différentes valeurs pour n_neighbors pour voir comment cela affecte le résultat. Vous pourriez également essayer de visualiser les frontières de décision ou d'utiliser différentes métriques de distance dans votre classificateur KNN.


