
Introduction
Bienvenue dans le monde de l'apprentissage automatique (machine learning) avec scikit-learn ! L'une des premières et des plus cruciales étapes de tout projet d'apprentissage automatique consiste à charger et à comprendre vos données. Scikit-learn, une bibliothèque puissante et conviviale pour l'apprentissage automatique en Python, fournit plusieurs jeux de données intégrés pour vous aider à démarrer.
Dans ce laboratoire, vous travaillerez avec le célèbre jeu de données des fleurs Iris. Vous apprendrez à charger ce jeu de données, à inspecter sa structure, à accéder aux données des caractéristiques (features) et aux étiquettes cibles (target labels), et enfin, à créer une visualisation simple pour avoir un premier aperçu de la distribution des données. Ces connaissances fondamentales sont essentielles pour tout aspirant scientifique des données (data scientist) ou ingénieur en apprentissage automatique (machine learning engineer).
Charger le jeu de données Iris avec datasets.load_iris()
Dans cette étape, vous apprendrez à charger l'un des jeux de données intégrés de scikit-learn. Nous utiliserons la fonction load_iris() du module sklearn.datasets. Cette fonction renvoie un objet "Bunch", qui est similaire à un dictionnaire Python et contient le jeu de données ainsi que ses métadonnées.
Tout d'abord, ouvrez le fichier main.py depuis l'explorateur de fichiers sur le côté gauche de votre écran. Nous écrirons tout notre code dans ce fichier.
Maintenant, ajoutez le code suivant à main.py pour importer le module nécessaire et charger le jeu de données.
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
Ce code importe le module datasets et appelle la fonction load_iris(), stockant l'objet du jeu de données résultant dans une variable nommée iris.
Pour exécuter votre script, ouvrez un terminal dans le WebIDE (vous pouvez utiliser le menu "Terminal" -> "New Terminal") et exécutez la commande suivante. Votre répertoire actuel est déjà ~/project.
python3 main.py
Vous ne verrez aucune sortie, et c'est normal. Nous avons chargé les données dans la variable iris, mais nous n'avons pas encore demandé à notre script d'afficher quoi que ce soit. Dans les étapes suivantes, nous explorerons le contenu de cet objet iris.
Accéder au tableau de données via iris.data
Dans cette étape, vous accéderez au cœur du jeu de données : les données des caractéristiques (features). L'objet iris que nous avons créé contient un attribut appelé data, qui détient un tableau NumPy des mesures pour chaque fleur. Chaque ligne représente un échantillon (une fleur), et chaque colonne représente une caractéristique (une mesure).
Modifions le fichier main.py pour imprimer ce tableau de données et voir à quoi il ressemble.
Mettez à jour votre fichier main.py avec le code suivant :
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
## Print the data array
print(iris.data)
Exécutez maintenant à nouveau le script depuis votre terminal :
python3 main.py
Vous devriez voir un grand tableau de nombres s'afficher dans le terminal. Ce sont les données des caractéristiques pour les 150 échantillons de fleurs du jeu de données. Chaque échantillon possède 4 caractéristiques.
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
...
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
Accéder au tableau cible en utilisant iris.target
Dans cette étape, vous accéderez aux étiquettes (labels) de chaque échantillon du jeu de données. En apprentissage automatique supervisé, ces étiquettes sont appelées la "cible" (target). L'objet iris les stocke dans l'attribut target. Pour le jeu de données Iris, les cibles représentent les espèces de chaque fleur.
Les espèces sont encodées sous forme d'entiers : 0 pour setosa, 1 pour versicolor, et 2 pour virginica. L'attribut iris.target est un tableau NumPy contenant l'entier correspondant pour chaque échantillon dans iris.data.
Modifions main.py pour imprimer le tableau cible.
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
## Print the target array
print(iris.target)
Exécutez le script depuis votre terminal :
python3 main.py
La sortie sera un tableau de 0, 1 et 2, représentant l'espèce de chacune des 150 fleurs.
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Explorer les noms des caractéristiques avec iris.feature_names
Dans cette étape, vous apprendrez comment découvrir ce que représentent réellement les colonnes du tableau iris.data. Bien que nous sachions qu'il y a quatre caractéristiques, leurs noms ne sont pas immédiatement évidents à partir du tableau de données lui-même. L'objet iris stocke commodément ces noms dans l'attribut feature_names.
Ceci est très utile pour comprendre et interpréter vos données. Modifions main.py pour imprimer ces noms de caractéristiques.
Mettez à jour votre fichier main.py :
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
## Print the feature names
print(iris.feature_names)
Exécutez maintenant le script depuis votre terminal :
python3 main.py
La sortie sera une liste de chaînes de caractères, vous donnant le nom de chacune des quatre colonnes dans iris.data.
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Vous savez maintenant que les quatre caractéristiques correspondent à la longueur du sépale, à la largeur du sépale, à la longueur du pétale et à la largeur du pétale, le tout en centimètres.
Visualiser les données avec matplotlib.pyplot.scatter(iris.data[:, 0], iris.data[:, 1])
Dans cette dernière étape, vous effectuerez une visualisation simple des données pour observer la relation entre deux des caractéristiques. La visualisation est un élément clé de l'exploration des données. Nous utiliserons la bibliothèque matplotlib, un outil de traçage populaire en Python, pour créer un nuage de points (scatter plot).
Nous allons tracer la première caractéristique (longueur du sépale) par rapport à la seconde caractéristique (largeur du sépale). Pour sélectionner ces colonnes de nos données, nous utilisons le découpage (slicing) NumPy :
iris.data[:, 0]sélectionne toutes les lignes (:) et la première colonne (0).iris.data[:, 1]sélectionne toutes les lignes (:) et la seconde colonne (1).
Au lieu d'afficher le graphique à l'écran, ce qui n'est pas idéal pour cet environnement, nous allons l'enregistrer dans un fichier image nommé iris_plot.png.
Mettez à jour votre fichier main.py avec le code suivant :
from sklearn import datasets
import matplotlib.pyplot as plt
## Load the Iris dataset
iris = datasets.load_iris()
## We will plot the first two features: Sepal Length vs Sepal Width
X = iris.data[:, :2]
y = iris.target
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('Sepal Length vs Sepal Width')
## Save the plot to a file
plt.savefig('iris_plot.png')
print("Plot saved to iris_plot.png")
Exécutez le script depuis votre terminal :
python3 main.py
Vous verrez un message de confirmation.
Plot saved to iris_plot.png
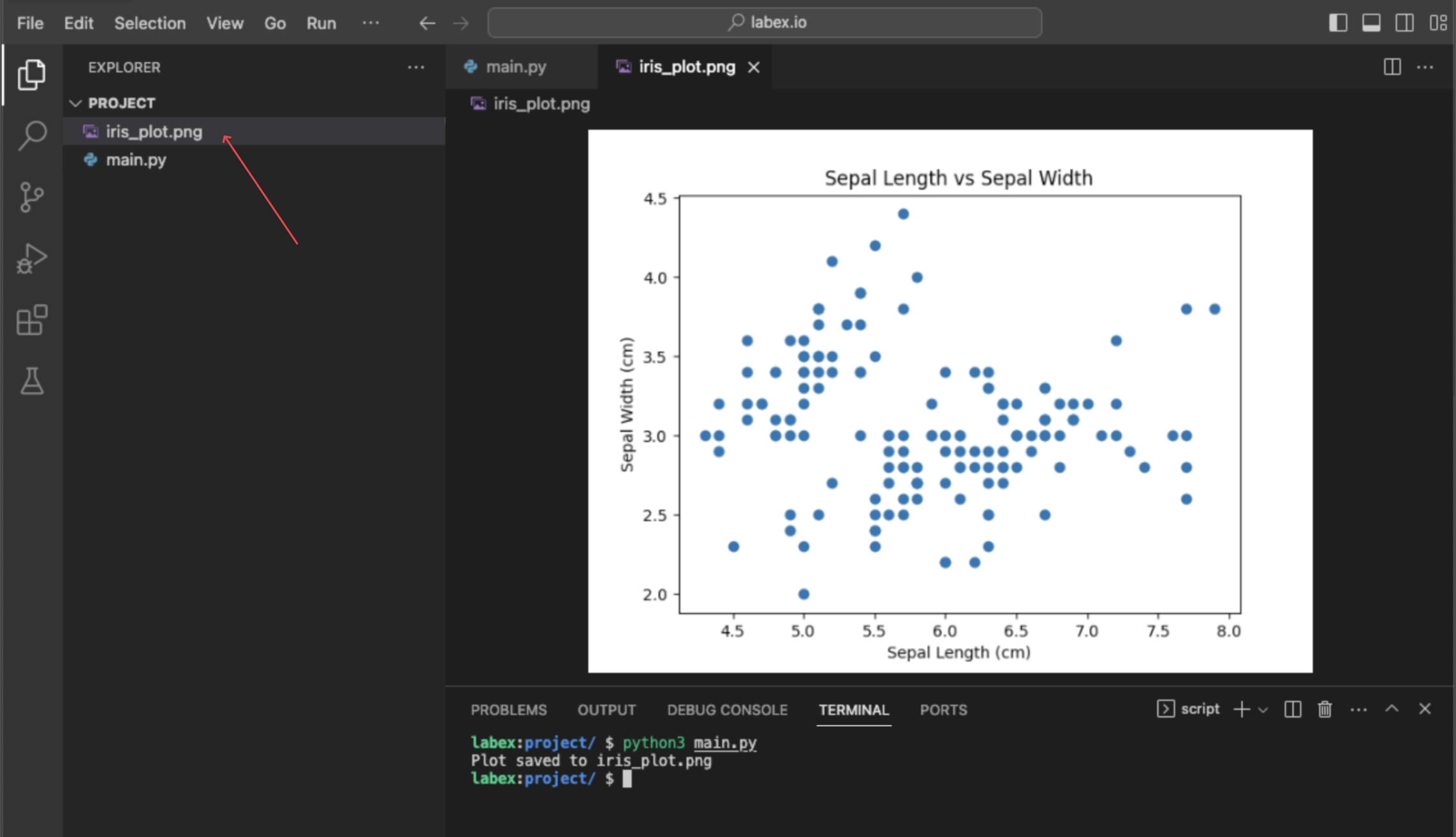
Cette commande n'affichera pas de graphique directement, mais elle créera un nouveau fichier nommé iris_plot.png dans votre répertoire ~/project. Vous pouvez double-cliquer sur ce fichier dans l'explorateur de fichiers à gauche pour visualiser votre nuage de points.
Résumé
Félicitations pour avoir terminé ce laboratoire ! Vous avez franchi avec succès vos premiers pas dans la manipulation de données avec scikit-learn.
Dans ce laboratoire, vous avez appris à :
- Charger un jeu de données intégré à l'aide de
sklearn.datasets.load_iris(). - Accéder à la matrice des caractéristiques à l'aide de l'attribut
.data. - Accéder aux étiquettes cibles à l'aide de l'attribut
.target. - Comprendre la signification des caractéristiques en inspectant l'attribut
.feature_names. - Effectuer une visualisation de données de base en créant un nuage de points avec
matplotlibet en l'enregistrant dans un fichier.
Ces compétences fondamentales sont les éléments constitutifs de tâches d'apprentissage automatique plus avancées. Vous êtes maintenant prêt à explorer d'autres jeux de données et à commencer à construire vos propres modèles d'apprentissage automatique.


