
Introduction
Dans ce laboratoire, nous explorerons la création de tables et les types de données dans PostgreSQL. L'objectif est de comprendre les types de données fondamentaux tels que les entiers, le texte, les dates et les booléens, qui sont essentiels pour définir les structures de table et garantir l'intégrité des données.
Nous nous connecterons à la base de données PostgreSQL en utilisant psql, créerons des tables avec des clés primaires en utilisant SERIAL, et ajouterons des contraintes de base telles que NOT NULL et UNIQUE. Nous inspecterons ensuite la structure de la table et insérerons des données pour démontrer l'utilisation de différents types de données comme INTEGER, SMALLINT, TEXT, VARCHAR(n), et CHAR(n).
Explorer les types de données PostgreSQL
Dans cette étape, nous explorerons certains des types de données fondamentaux disponibles dans PostgreSQL. Comprendre les types de données est crucial pour définir les structures de table et garantir l'intégrité des données. Nous aborderons les types courants tels que les entiers, le texte, les dates et les booléens.
Tout d'abord, connectons-nous à la base de données PostgreSQL. Ouvrez un terminal et utilisez la commande psql pour vous connecter à la base de données postgres en tant qu'utilisateur postgres. Étant donné que l'utilisateur postgres est le superutilisateur par défaut, vous devrez peut-être utiliser sudo pour passer à cet utilisateur en premier.
sudo -u postgres psql
Vous devriez maintenant être dans le terminal interactif PostgreSQL. Vous verrez une invite comme postgres=#.
Maintenant, explorons quelques types de données de base.
1. Types d'entiers (Integer Types) :
PostgreSQL offre plusieurs types d'entiers avec des plages variables. Les plus courants sont INTEGER (ou INT) et SMALLINT.
INTEGER: Un choix typique pour la plupart des valeurs entières.SMALLINT: Utilisé pour les petites valeurs entières afin d'économiser de l'espace.
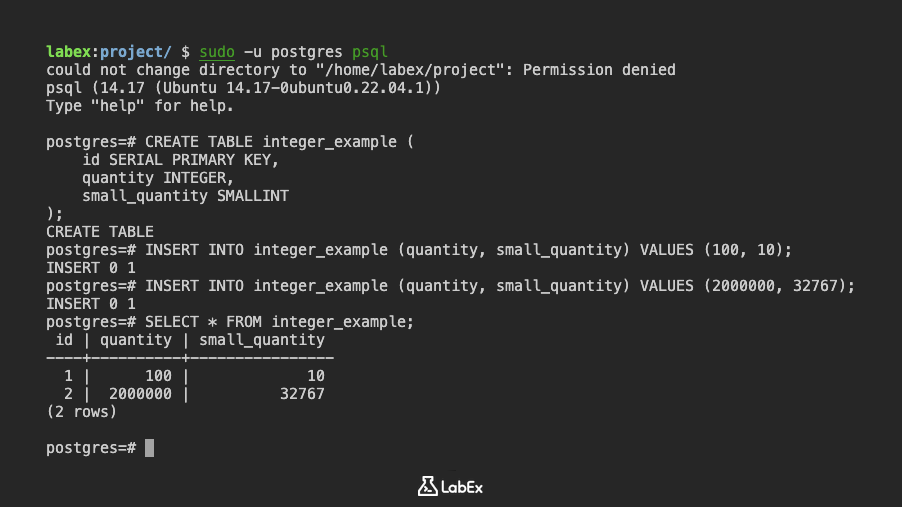
Créons une table simple pour démontrer ces types :
CREATE TABLE integer_example (
id SERIAL PRIMARY KEY,
quantity INTEGER,
small_quantity SMALLINT
);
Ici, SERIAL est un type spécial qui génère automatiquement une séquence d'entiers, ce qui le rend approprié pour les clés primaires.
Maintenant, insérez des données :
INSERT INTO integer_example (quantity, small_quantity) VALUES (100, 10);
INSERT INTO integer_example (quantity, small_quantity) VALUES (2000000, 32767);
Vous pouvez afficher les données en utilisant :
SELECT * FROM integer_example;
Sortie (Output) :
id | quantity | small_quantity
----+----------+----------------
1 | 100 | 10
2 | 2000000 | 32767
(2 rows)
2. Types de texte (Text Types) :
PostgreSQL fournit TEXT, VARCHAR(n), et CHAR(n) pour stocker du texte.
TEXT: Stocke des chaînes de longueur variable de longueur illimitée.VARCHAR(n): Stocke des chaînes de longueur variable avec une longueur maximale den.CHAR(n): Stocke des chaînes de longueur fixe de longueurn. Si la chaîne est plus courte, elle est complétée par des espaces.
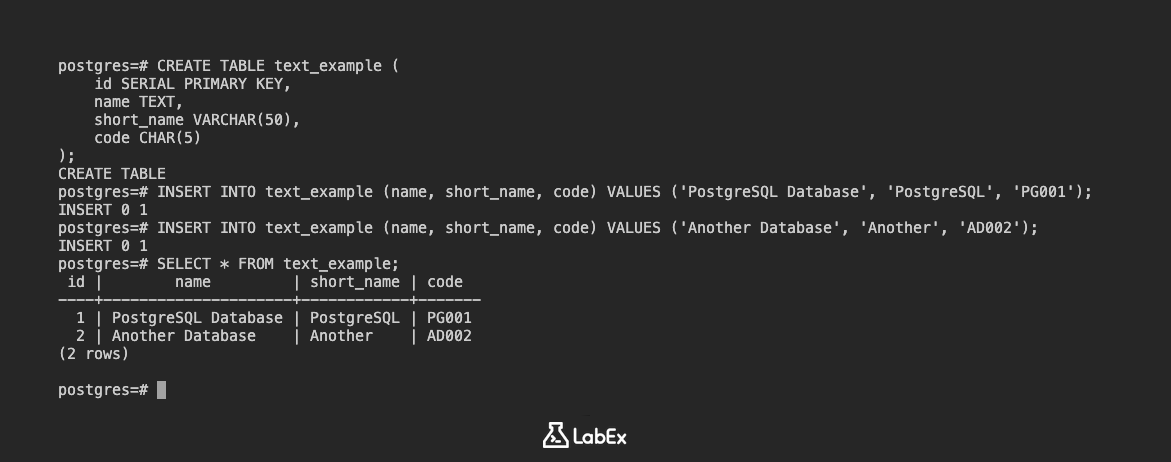
Créons une autre table :
CREATE TABLE text_example (
id SERIAL PRIMARY KEY,
name TEXT,
short_name VARCHAR(50),
code CHAR(5)
);
Insérez des données :
INSERT INTO text_example (name, short_name, code) VALUES ('PostgreSQL Database', 'PostgreSQL', 'PG001');
INSERT INTO text_example (name, short_name, code) VALUES ('Another Database', 'Another', 'AD002');
Affichez les données :
SELECT * FROM text_example;
Sortie (Output) :
id | name | short_name | code
----+--------------------+------------+-------
1 | PostgreSQL Database | PostgreSQL | PG001
2 | Another Database | Another | AD002
(2 rows)
3. Types de date et d'heure (Date and Time Types) :
PostgreSQL offre DATE, TIME, TIMESTAMP, et TIMESTAMPTZ pour gérer les valeurs de date et d'heure.
DATE: Stocke uniquement la date (année, mois, jour).TIME: Stocke uniquement l'heure (heure, minute, seconde).TIMESTAMP: Stocke à la fois la date et l'heure sans information de fuseau horaire.TIMESTAMPTZ: Stocke à la fois la date et l'heure avec des informations de fuseau horaire.
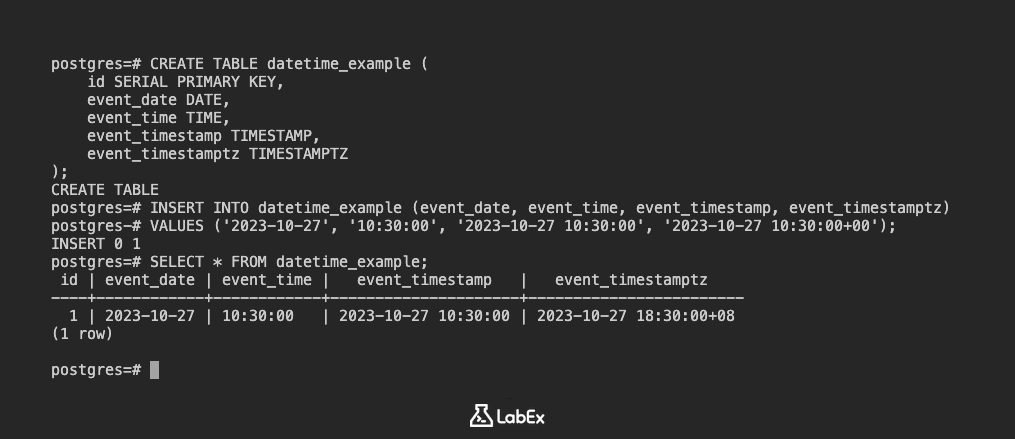
Créez une table :
CREATE TABLE datetime_example (
id SERIAL PRIMARY KEY,
event_date DATE,
event_time TIME,
event_timestamp TIMESTAMP,
event_timestamptz TIMESTAMPTZ
);
Insérez des données :
INSERT INTO datetime_example (event_date, event_time, event_timestamp, event_timestamptz)
VALUES ('2023-10-27', '10:30:00', '2023-10-27 10:30:00', '2023-10-27 10:30:00+00');
Affichez les données :
SELECT * FROM datetime_example;
Sortie (Output) :
id | event_date | event_time | event_timestamp | event_timestamptz
----+------------+------------+---------------------+----------------------------
1 | 2023-10-27 | 10:30:00 | 2023-10-27 10:30:00 | 2023-10-27 10:30:00+00
(1 row)
4. Type booléen (Boolean Type) :
Le type BOOLEAN stocke les valeurs vrai/faux.
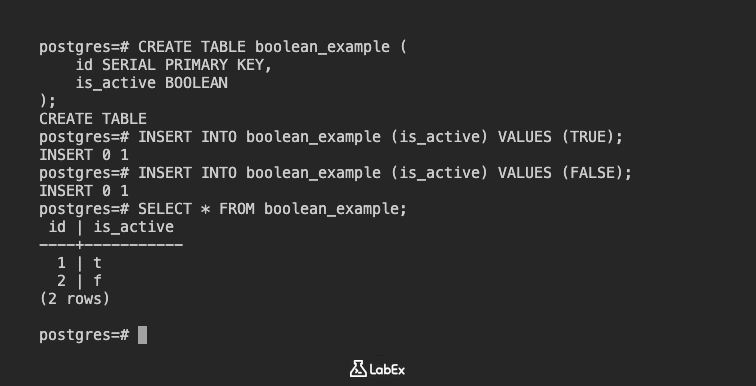
Créez une table :
CREATE TABLE boolean_example (
id SERIAL PRIMARY KEY,
is_active BOOLEAN
);
Insérez des données :
INSERT INTO boolean_example (is_active) VALUES (TRUE);
INSERT INTO boolean_example (is_active) VALUES (FALSE);
Affichez les données :
SELECT * FROM boolean_example;
Sortie (Output) :
id | is_active
----+-----------
1 | t
2 | f
(2 rows)
Enfin, quittez le terminal psql :
\q
Vous avez maintenant exploré certains des types de données fondamentaux dans PostgreSQL. Ces types de données constituent les éléments de base pour créer des schémas de base de données robustes et bien définis.
Créer des tables avec des clés primaires
Dans cette étape, nous apprendrons à créer des tables avec des clés primaires dans PostgreSQL. Une clé primaire est une colonne ou un ensemble de colonnes qui identifie de manière unique chaque ligne d'une table. Elle impose l'unicité et constitue un élément crucial pour l'intégrité des données et les relations entre les tables.
Tout d'abord, connectons-nous à la base de données PostgreSQL. Ouvrez un terminal et utilisez la commande psql pour vous connecter à la base de données postgres en tant qu'utilisateur postgres.
sudo -u postgres psql
Vous devriez maintenant être dans le terminal interactif PostgreSQL.
Comprendre les clés primaires (Understanding Primary Keys)
Une clé primaire a les caractéristiques suivantes :
- Elle doit contenir des valeurs uniques.
- Elle ne peut pas contenir de valeurs
NULL. - Une table ne peut avoir qu'une seule clé primaire.
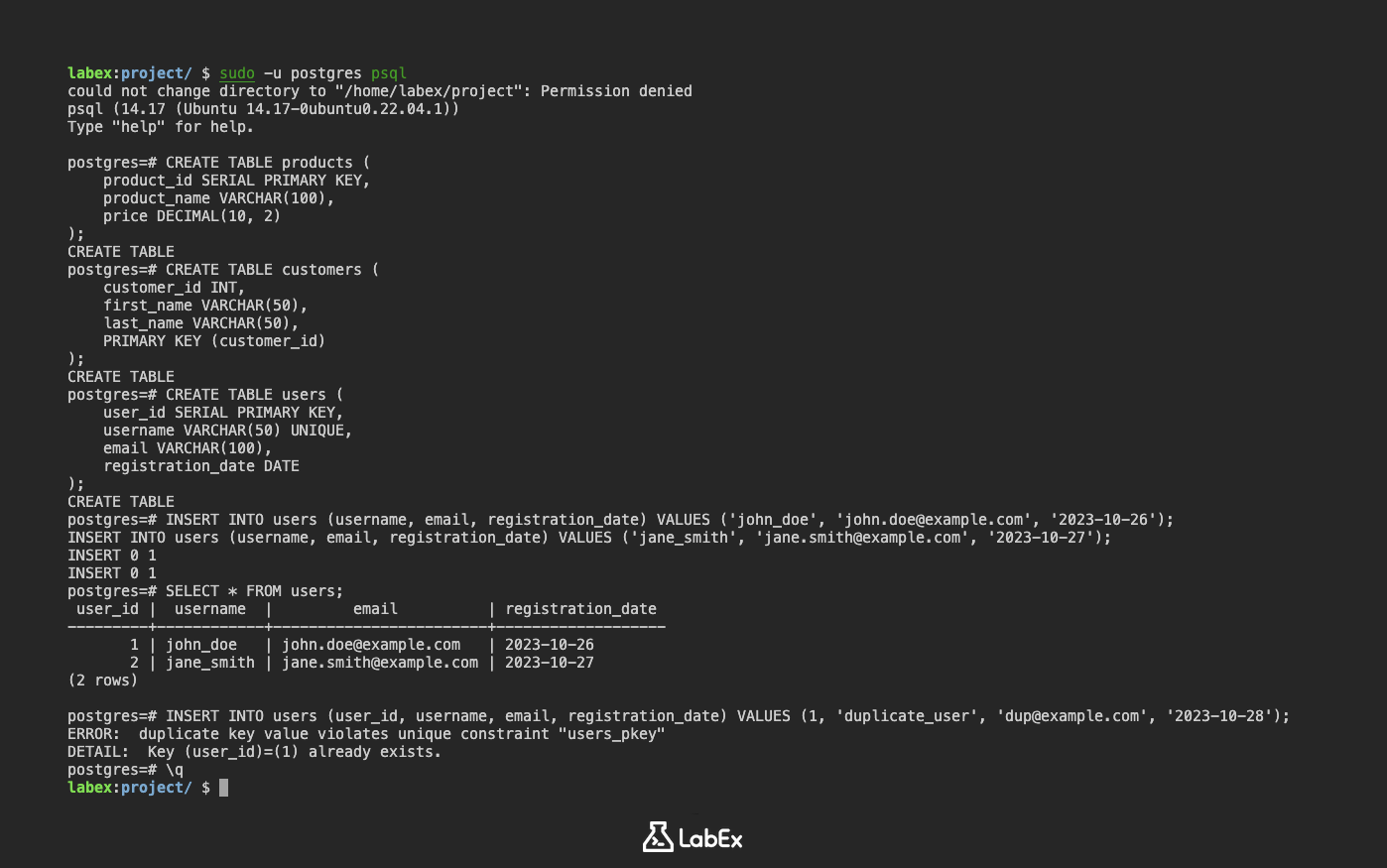
Créer une table avec une clé primaire (Creating a Table with a Primary Key)
Il existe deux façons courantes de définir une clé primaire lors de la création d'une table :
Utiliser la contrainte
PRIMARY KEYdans la définition de la colonne :CREATE TABLE products ( product_id SERIAL PRIMARY KEY, product_name VARCHAR(100), price DECIMAL(10, 2) );Dans cet exemple,
product_idest défini comme la clé primaire en utilisant la contraintePRIMARY KEY. Le mot-cléSERIALcrée automatiquement une séquence pour générer des valeurs entières uniques pourproduct_id.Utiliser la contrainte
PRIMARY KEYséparément :CREATE TABLE customers ( customer_id INT, first_name VARCHAR(50), last_name VARCHAR(50), PRIMARY KEY (customer_id) );Ici, la contrainte
PRIMARY KEYest définie séparément, spécifiant que la colonnecustomer_idest la clé primaire.
Exemple : Création d'une table users avec une clé primaire
Créons une table users avec une clé primaire en utilisant le type SERIAL pour la génération automatique d'ID :
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE,
email VARCHAR(100),
registration_date DATE
);
Dans cette table :
user_idest la clé primaire, générée automatiquement à l'aide deSERIAL.usernameest un nom d'utilisateur unique pour chaque utilisateur.emailest l'adresse e-mail de l'utilisateur.registration_dateest la date d'inscription de l'utilisateur.
Maintenant, insérons des données dans la table users :
INSERT INTO users (username, email, registration_date) VALUES ('john_doe', 'john.doe@example.com', '2023-10-26');
INSERT INTO users (username, email, registration_date) VALUES ('jane_smith', 'jane.smith@example.com', '2023-10-27');
Vous pouvez afficher les données en utilisant :
SELECT * FROM users;
Sortie (Output) :
user_id | username | email | registration_date
---------+------------+---------------------+---------------------
1 | john_doe | john.doe@example.com | 2023-10-26
2 | jane_smith | jane.smith@example.com | 2023-10-27
(2 rows)
Essayer d'insérer une clé primaire en double (Trying to insert a duplicate primary key)
Si vous essayez d'insérer une ligne avec une clé primaire en double, PostgreSQL générera une erreur :
INSERT INTO users (user_id, username, email, registration_date) VALUES (1, 'duplicate_user', 'dup@example.com', '2023-10-28');
Sortie (Output) :
ERROR: duplicate key value violates unique constraint "users_pkey"
DETAIL: Key (user_id)=(1) already exists.
Cela démontre la contrainte de clé primaire en action, empêchant les valeurs en double.
Enfin, quittez le terminal psql :
\q
Vous avez maintenant créé avec succès une table avec une clé primaire et observé comment elle impose l'unicité. Il s'agit d'un concept fondamental dans la conception de bases de données.
Ajouter des contraintes de base (NOT NULL, UNIQUE)
Dans cette étape, nous apprendrons à ajouter des contraintes de base aux tables dans PostgreSQL. Les contraintes sont des règles qui appliquent l'intégrité et la cohérence des données. Nous nous concentrerons sur deux contraintes fondamentales : NOT NULL et UNIQUE.
Tout d'abord, connectons-nous à la base de données PostgreSQL. Ouvrez un terminal et utilisez la commande psql pour vous connecter à la base de données postgres en tant qu'utilisateur postgres.
sudo -u postgres psql
Vous devriez maintenant être dans le terminal interactif PostgreSQL.
Comprendre les contraintes (Understanding Constraints)
Les contraintes sont utilisées pour limiter le type de données qui peuvent être insérées dans une table. Cela garantit l'exactitude et la fiabilité des données dans la base de données.
1. Contrainte NOT NULL
La contrainte NOT NULL garantit qu'une colonne ne peut pas contenir de valeurs NULL. Ceci est utile lorsqu'une information particulière est essentielle pour chaque ligne de la table.
2. Contrainte UNIQUE
La contrainte UNIQUE garantit que toutes les valeurs d'une colonne sont distinctes. Ceci est utile pour les colonnes qui doivent avoir des identifiants ou des valeurs uniques, tels que les noms d'utilisateur ou les adresses e-mail (en plus de la clé primaire).
Ajouter des contraintes lors de la création de la table (Adding Constraints During Table Creation)
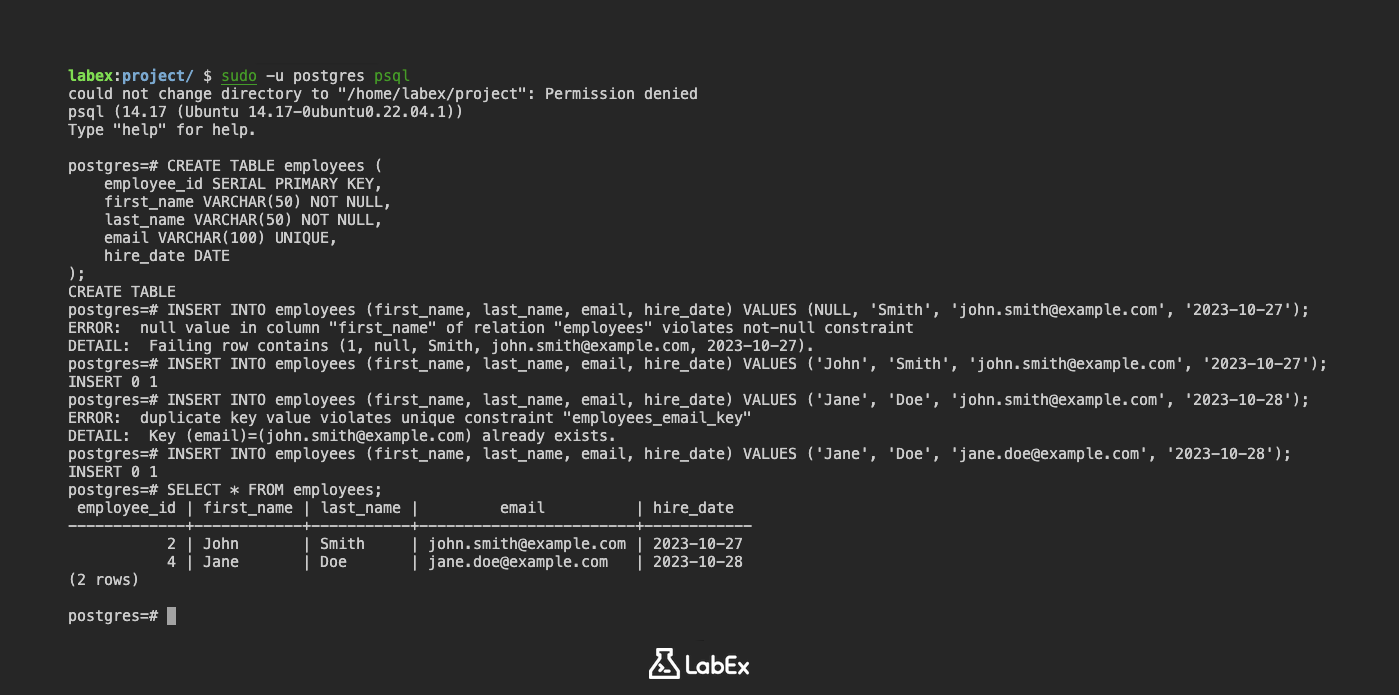
Vous pouvez ajouter des contraintes lorsque vous créez une table. Créons une table appelée employees avec les contraintes NOT NULL et UNIQUE :
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE
);
Dans cette table :
employee_idest la clé primaire.first_nameetlast_namesont déclarés commeNOT NULL, ce qui signifie qu'ils doivent avoir une valeur pour chaque employé.emailest déclaré commeUNIQUE, garantissant que chaque employé a une adresse e-mail unique.
Maintenant, essayons d'insérer des données qui violent ces contraintes.
Tentative d'insertion d'une valeur NULL dans une colonne NOT NULL :
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES (NULL, 'Smith', 'john.smith@example.com', '2023-10-27');
Sortie (Output) :
ERROR: null value in column "first_name" of relation "employees" violates not-null constraint
DETAIL: Failing row contains (1, null, Smith, john.smith@example.com, 2023-10-27).
Cette erreur indique que vous ne pouvez pas insérer une valeur NULL dans la colonne first_name en raison de la contrainte NOT NULL.
Tentative d'insertion d'une valeur en double dans une colonne UNIQUE :
Tout d'abord, insérez une ligne valide :
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('John', 'Smith', 'john.smith@example.com', '2023-10-27');
Maintenant, essayez d'insérer une autre ligne avec le même e-mail :
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'john.smith@example.com', '2023-10-28');
Sortie (Output) :
ERROR: duplicate key value violates unique constraint "employees_email_key"
DETAIL: Key (email)=(john.smith@example.com) already exists.
Cette erreur indique que vous ne pouvez pas insérer une adresse e-mail en double en raison de la contrainte UNIQUE.
Insertion de données valides :
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES ('Jane', 'Doe', 'jane.doe@example.com', '2023-10-28');
Affichez les données :
SELECT * FROM employees;
Sortie (Output) :
employee_id | first_name | last_name | email | hire_date
-------------+------------+-----------+---------------------+------------
1 | John | Smith | john.smith@example.com | 2023-10-27
2 | Jane | Doe | jane.doe@example.com | 2023-10-28
(2 rows)
Enfin, quittez le terminal psql :
\q
Vous avez maintenant créé avec succès une table avec les contraintes NOT NULL et UNIQUE et observé comment elles appliquent l'intégrité des données.
Inspecter la structure de la table
Dans cette étape, nous apprendrons à inspecter la structure des tables dans PostgreSQL. Comprendre la structure d'une table, y compris les noms de colonnes, les types de données, les contraintes et les index, est essentiel pour interroger et manipuler les données efficacement.
Tout d'abord, connectons-nous à la base de données PostgreSQL. Ouvrez un terminal et utilisez la commande psql pour vous connecter à la base de données postgres en tant qu'utilisateur postgres.
sudo -u postgres psql
Vous devriez maintenant être dans le terminal interactif PostgreSQL.
La commande \d
L'outil principal pour inspecter la structure d'une table dans psql est la commande \d (describe - décrire). Cette commande fournit des informations détaillées sur une table, notamment :
- Les noms de colonnes et les types de données
- Les contraintes (clés primaires, contraintes d'unicité, contraintes non nulles)
- Les index
Inspecter la table employees
Inspectons la structure de la table employees que nous avons créée à l'étape précédente :
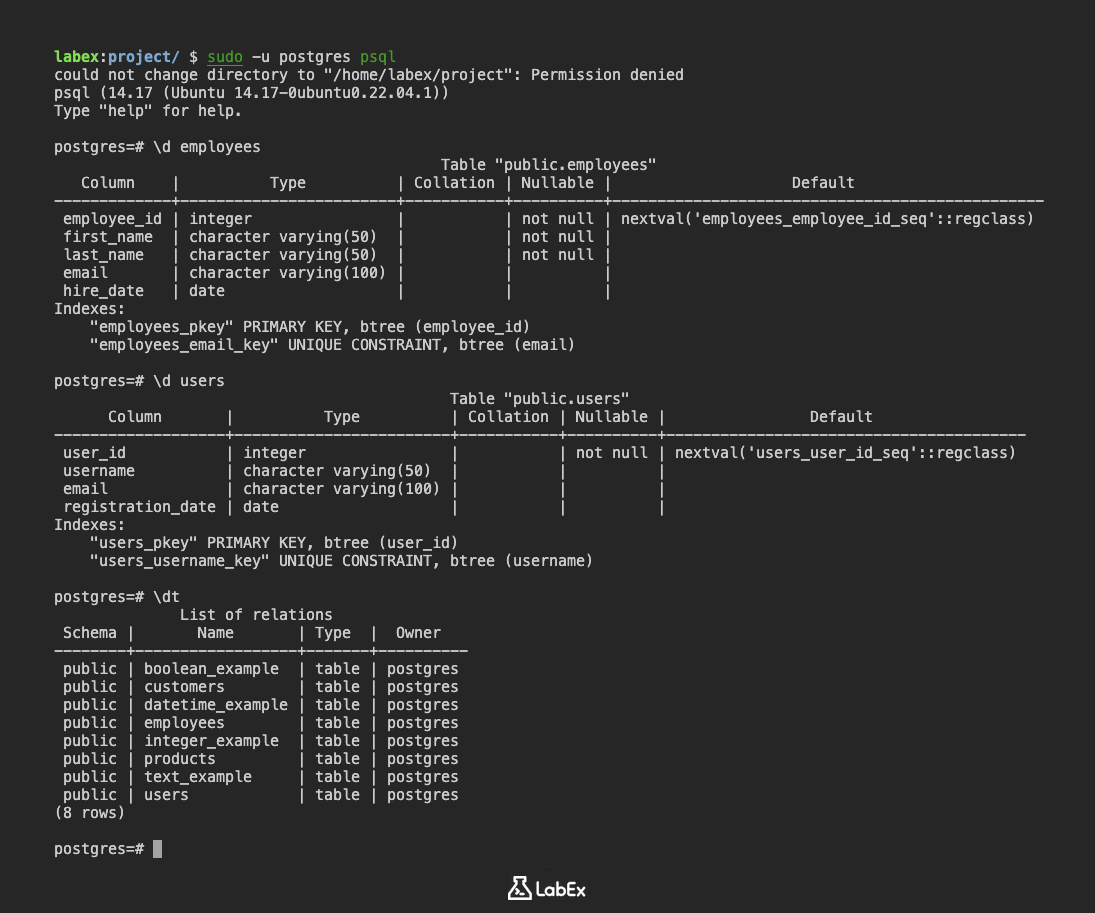
\d employees
Sortie (Output) :
Table "public.employees"
Column | Type | Collation | Nullable | Default
-------------+------------------------+-----------+----------+------------------------------------------------
employee_id | integer | | not null | nextval('employees_employee_id_seq'::regclass)
first_name | character varying(50) | | not null |
last_name | character varying(50) | | not null |
email | character varying(100) | | |
hire_date | date | | |
Indexes:
"employees_pkey" PRIMARY KEY, btree (employee_id)
"employees_email_key" UNIQUE CONSTRAINT, btree (email)
La sortie fournit les informations suivantes :
- Table "public.employees": Indique le nom de la table et le schéma.
- Column: Liste les noms de colonnes (
employee_id,first_name,last_name,email,hire_date). - Type: Affiche le type de données de chaque colonne (
integer,character varying,date). - Nullable: Indique si une colonne peut contenir des valeurs
NULL(not nullou vide). - Default: Affiche la valeur par défaut d'une colonne (le cas échéant).
- Indexes: Liste les index définis sur la table, y compris la clé primaire (
employees_pkey) et la contrainte d'unicité sur la colonneemail(employees_email_key).
Inspecter d'autres tables
Vous pouvez utiliser la commande \d pour inspecter n'importe quelle table de la base de données. Par exemple, pour inspecter la table users créée à l'étape 2 :
\d users
Sortie (Output) :
Table "public.users"
Column | Type | Collation | Nullable | Default
-------------------+------------------------+-----------+----------+----------------------------------------
user_id | integer | | not null | nextval('users_user_id_seq'::regclass)
username | character varying(50) | | |
email | character varying(100) | | |
registration_date | date | | |
Indexes:
"users_pkey" PRIMARY KEY, btree (user_id)
"users_username_key" UNIQUE CONSTRAINT, btree (username)
Lister toutes les tables (Listing all tables)
Pour lister toutes les tables de la base de données actuelle, vous pouvez utiliser la commande \dt :
\dt
Sortie (Output) - variera en fonction des tables que vous avez créées :
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | boolean_example | table | postgres
public | customers | table | postgres
public | datetime_example | table | postgres
public | employees | table | postgres
public | integer_example | table | postgres
public | products | table | postgres
public | text_example | table | postgres
public | users | table | postgres
(8 rows)
Enfin, quittez le terminal psql :
\q
Vous avez maintenant appris à inspecter la structure des tables dans PostgreSQL à l'aide des commandes \d et \dt. C'est une compétence fondamentale pour comprendre et travailler avec les bases de données.
Résumé
Dans ce labo, nous avons exploré les types de données fondamentaux de PostgreSQL, en nous concentrant sur les entiers et le texte. Nous avons découvert INTEGER et SMALLINT pour stocker des valeurs entières, en comprenant leurs différentes plages et cas d'utilisation. Nous avons également examiné TEXT, VARCHAR(n) et CHAR(n) pour la gestion des données textuelles, en notant les distinctions entre les chaînes de longueur variable et de longueur fixe.
De plus, nous avons pratiqué la création de tables en utilisant ces types de données, y compris l'utilisation de SERIAL pour générer automatiquement des séquences de clés primaires. Nous avons inséré des exemples de données dans les tables et vérifié les données à l'aide d'instructions SELECT, consolidant ainsi notre compréhension du comportement de ces types de données dans un contexte de base de données pratique.

