
Introduction
Dans les versions 2.0 et ultérieures d'Hadoop, le nouveau modèle de gestion des ressources de YARN a été introduit, ce qui facilite le cluster en termes d'utilisation, de gestion des ressources unifiée et de partage de données. Sur la base de la construction du cluster pseudo-distribué Hadoop, cette section vous permettra d'apprendre l'architecture, le principe de fonctionnement, la configuration, ainsi que les techniques de développement et de surveillance du cadre YARN.
Ce laboratoire nécessite une certaine base de programmation Java.
Veuillez saisir vous-même tout le code d'exemple présent dans le document ; évitez autant que possible de simplement copier et coller. De cette manière, vous serez plus familier avec le code. Si vous rencontrez des problèmes, relisez attentivement la documentation, ou vous pouvez aller sur le forum pour demander de l'aide et communiquer.
Architecture et composants de YARN
YARN, introduit dans Hadoop 0.23 comme partie de MapReduce 2.0 (MRv2), a révolutionné la gestion des ressources et la planification des tâches dans les clusters Hadoop :
- Découpage de JobTracker :
MRv2découpe les fonctions deJobTrackeren démon séparés -ResourceManagerpour la gestion des ressources etApplicationMasterpour la planification et la surveillance des tâches. - ResourceManager global : Chaque application a un
ApplicationMastercorrespondant, qui peut être une tâche MapReduce ou un DAG décrivant la tâche. - Cadre de calcul de données : Le
ResourceManager, leSlaveet leNodeManagerforment un cadre dans lequel le ResourceManager gouverne toutes les ressources d'application. - Composants de ResourceManager : Le
Schedulerattribue des ressources en fonction de contraintes telles que la capacité et les files d'attente, tandis que l'ApplicationsManagergère les soumissions de tâches et l'exécution des ApplicationMaster. - Allocation de ressources : Les exigences en ressources sont définies à l'aide de conteneurs de ressources avec des éléments tels que la mémoire, le CPU, le disque et le réseau.
- Rôle de NodeManager : NodeManager surveille l'utilisation des ressources des conteneurs et rapporte à ResourceManager et Scheduler.
- Tâches d'ApplicationMaster : ApplicationMaster négocie des conteneurs de ressources avec Scheduler, suit l'état et surveille l'avancement.
La figure suivante illustre la relation :

YARN assure la compatibilité de l'API avec les versions antérieures, permettant une transition transparente pour l'exécution de tâches MapReduce. Comprendre l'architecture et les composants de YARN est essentiel pour une gestion efficace des ressources et une planification des tâches dans les clusters Hadoop.
Démarrer le démon Hadoop
Avant d'apprendre les paramètres de configuration pertinents et les techniques de développement d'applications YARN, nous devons démarrer le démon Hadoop pour qu'il soit disponible à tout moment.
Tout d'abord, double-cliquez pour ouvrir le terminal Xfce sur le bureau et entrez la commande suivante pour vous connecter en tant qu'utilisateur hadoop :
su - hadoop
Astuce : Le mot de passe est 'hadoop' pour l'utilisateur 'hadoop'.
Une fois la connexion établie, vous pouvez démarrer les démons liés à Hadoop, y compris les frameworks HDFS et YARN.
Veuillez entrer les commandes suivantes dans le terminal pour démarrer les démons :
/home/hadoop/hadoop/sbin/start-dfs.sh
/home/hadoop/hadoop/sbin/start-yarn.sh
Une fois le démarrage terminé, vous pouvez choisir d'utiliser la commande jps pour vérifier si les démons associés sont en cours d'exécution.
hadoop:~$ jps
3378 NodeManager
3028 SecondaryNameNode
3717 Jps
2791 DataNode
2648 NameNode
3240 ResourceManager
Préparer le fichier de configuration
Dans cette section, nous allons étudier yarn-site.xml, qui est l'un des principaux fichiers de configuration d'Hadoop, pour voir quelles configurations peuvent être effectuées pour le cluster YARN dans ce fichier.
Pour éviter tout abus de modification du fichier de configuration, il est préférable de copier le fichier de configuration d'Hadoop dans un autre répertoire puis de l'ouvrir.
Pour ce faire, veuillez entrer la commande suivante dans le terminal pour créer un nouveau répertoire pour le fichier de configuration :
mkdir /home/hadoop/hadoop_conf
Ensuite, copiez le fichier de configuration principal yarn-site.xml de YARN à partir du répertoire d'installation vers le nouveau répertoire créé.
Veuillez entrer la commande suivante dans le terminal pour effectuer l'opération :
cp /home/hadoop/hadoop/etc/hadoop/yarn-site.xml /home/hadoop/hadoop_conf/yarn-site.xml
Ensuite, utilisez l'éditeur vim pour ouvrir le fichier et voir son contenu :
vim /home/hadoop/hadoop_conf/yarn-site.xml
Fonctionnement du fichier de configuration
Nous savons qu'il y a deux rôles importants dans le cadre YARN : ResourceManager et NodeManager. Par conséquent, chaque élément de configuration dans le fichier est un paramètre des deux composants ci-dessus.
Il existe de nombreux paramètres de configuration qui peuvent être définis dans ce fichier, mais par défaut, ce fichier ne contient aucun paramètre de configuration personnalisé. Par exemple, le fichier que nous ouvrons maintenant ne contient que l'attribut aux-services qui a été spécifié lors de la configuration précédente du cluster Hadoop pseudo-distribué, comme le montre la figure suivante :
hadoop:~$ cat /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
...
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Ce paramètre de configuration est utilisé pour définir les services dépendants qui doivent être exécutés sur le NodeManager. La valeur de configuration que nous spécifions est mapreduce_shuffle, indiquant que la valeur par défaut du programme MapReduce doit être exécutée sur YARN.
Les paramètres de configuration qui ne sont pas écrits dans le fichier ne fonctionnent-ils pas? Pas exactement. Lorsque les paramètres de configuration ne sont pas explicitement spécifiés dans le fichier, le cadre YARN d'Hadoop lit les valeurs par défaut stockées dans les fichiers internes. Tous les paramètres de configuration explicitement spécifiés dans le fichier yarn-site.xml remplaceront les valeurs par défaut, ce qui est un moyen efficace pour le système Hadoop d'adapter à différents scénarios d'utilisation.
Paramètres de configuration de ResourceManager
Comprendre et configurer correctement les paramètres de ResourceManager dans le fichier yarn-site.xml est essentiel pour une gestion efficace des ressources et une exécution de tâches dans un cluster Hadoop. Voici un résumé des principaux paramètres de configuration liés à ResourceManager :
yarn.resourcemanager.address: Expose l'adresse aux clients pour soumettre des applications et tuer des applications. Le port par défaut est 8032.yarn.resourcemanager.scheduler.address: Expose l'adresse à ApplicationMaster pour demander et libérer des ressources. Le port par défaut est 8030.yarn.resourcemanager.resource-tracker.address: Expose l'adresse à NodeManager pour envoyer des battements de cœur et extraire des tâches. Le port par défaut est 8031.yarn.resourcemanager.admin.address: Expose l'adresse aux administrateurs pour les commandes de gestion. Le port par défaut est 8033.yarn.resourcemanager.webapp.address: Adresse de l'interface Web pour visualiser les informations sur le cluster. Le port par défaut est 8088.yarn.resourcemanager.scheduler.class: Spécifie le nom de la classe principale du planificateur (par exemple, FIFO, CapacityScheduler, FairScheduler).- Configuration des threads :
yarn.resourcemanager.resource-tracker.client.thread-countyarn.resourcemanager.scheduler.client.thread-count
- Allocation de ressources :
yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores
- Gestion de NodeManager :
yarn.resourcemanager.nodes.exclude-pathyarn.resourcemanager.nodes.include-path
- Configuration des battements de cœur :
yarn.resourcemanager.nodemanagers.heartbeat-interval-ms
La configuration de ces paramètres permet de paramétrer finement le comportement de ResourceManager, l'allocation de ressources, la gestion des threads, la gestion de NodeManager et les intervalles de battement de cœur dans un cluster Hadoop. Comprendre ces paramètres de configuration aide à prévenir les problèmes et à assurer un fonctionnement fluide du cluster.
Paramètres de configuration de NodeManager
Configurer les paramètres de NodeManager dans le fichier yarn-site.xml est crucial pour gérer efficacement les ressources et les tâches dans un cluster Hadoop. Voici un résumé des principaux paramètres de configuration liés à NodeManager :
yarn.nodemanager.resource.memory-mb: Spécifie la mémoire physique totale disponible pour NodeManager. Cette valeur reste constante pendant l'exécution de YARN.yarn.nodemanager.vmem-pmem-ratio: Définit le ratio d'allocation de mémoire virtuelle sur mémoire physique. Le ratio par défaut est2.1.yarn.nodemanager.resource.cpu-vcores: Définit le nombre total de processeurs virtuels disponibles pour NodeManager. La valeur par défaut est8.yarn.nodemanager.local-dirs: Chemin pour stocker les résultats intermédiaires sur NodeManager, permettant de configurer plusieurs répertoires.yarn.nodemanager.log-dirs: Chemin vers le répertoire de journal de NodeManager, prenant en charge la configuration de plusieurs répertoires.yarn.nodemanager.log.retain-seconds: Durée maximale de conservation des journaux de NodeManager, la valeur par défaut est de 10800 secondes (3 heures).
La configuration de ces paramètres permet de paramétrer finement l'allocation de ressources, la gestion de la mémoire, les chemins de répertoire et les paramètres de conservation des journaux pour une performance optimale et une utilisation des ressources par NodeManager dans un cluster Hadoop. Comprendre ces paramètres de configuration aide à assurer un fonctionnement fluide et une exécution efficace de tâches dans le cluster.
Requête des paramètres de configuration et références par défaut
Pour explorer tous les paramètres de configuration disponibles dans YARN et d'autres composants Hadoop communs, vous pouvez vous référer aux fichiers de configuration par défaut fournis par Apache Hadoop. Voici les liens pour accéder aux configurations par défaut :
Paramètres de configuration de YARN :
Fichiers de configuration communs :
- core-default.xml (core-site.xml)
- hdfs-default.xml (hdfs-site.xml)
- mapred-default.xml (mapred-site.xml)
L'exploration de ces configurations par défaut fournit des descriptions détaillées de chaque paramètre de configuration et de leurs buts, vous aidant à comprendre le rôle de chaque paramètre dans la conception de l'architecture Hadoop.
Après avoir consulté les configurations, vous pouvez fermer l'éditeur vim pour conclure votre exploration des paramètres de configuration d'Hadoop.
Création de répertoires et de fichiers de projet
Apprenons le processus de développement d'une application YARN en imitant une application d'instance officielle YARN.
Créez tout d'abord un répertoire de projet. Veuillez entrer la commande suivante dans le terminal pour créer le répertoire :
mkdir /home/hadoop/yarn_app
Ensuite, créez deux fichiers de code source dans le projet séparément.
Le premier est Client.java. Utilisez la commande touch dans le terminal pour créer le fichier :
touch /home/hadoop/yarn_app/Client.java
Ensuite, créez le fichier ApplicationMaster.java :
touch /home/hadoop/yarn_app/ApplicationMaster.java
hadoop:~$ tree /home/hadoop/yarn_app/
/home/hadoop/yarn_app/
├── ApplicationMaster.java
└── Client.java
0 directories, 2 files
Écrire le code du client
En écrivant le code pour le Client, vous serez en mesure de comprendre les API et leur rôle nécessaires pour développer le Client dans le cadre YARN.
Le contenu du code est un peu long. Un moyen plus efficace que de le lire ligne par ligne est d'entrer chaque ligne dans le fichier de code source que vous venez de créer.
Tout d'abord, ouvrez le fichier Client.java que vous venez de créer avec l'éditeur vim (ou un autre éditeur de texte) :
vim /home/hadoop/yarn_app/Client.java
Ensuite, ajoutez le corps principal du programme pour indiquer le nom de la classe et le nom du package pour la classe :
package com.labex.yarn.app;
public class Client {
public static void main(String[] args){
//TODO: Éditer le code ici.
}
}
Le code suivant est présenté sous forme de segmentation. Lorsque vous écrivez, insérez le code suivant dans la classe Client (c'est-à-dire le bloc de code où se trouve le commentaire //TODO: Éditer votre code ici).
La première étape que le client doit effectuer est de créer et d'initialiser l'objet YarnClient puis de le démarrer :
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
Après avoir créé Client, nous devons créer un objet d'application YARN et son identifiant d'application :
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
L'objet appResponse contient des informations sur le cluster, telles que les capacités minimales et maximales de ressources du cluster. Ces informations sont nécessaires pour nous permettre de configurer correctement les paramètres lorsque le ApplicationMaster démarre le conteneur approprié.
L'une des principales tâches dans le Client est de définir le ApplicationSubmissionContext. Il définit toutes les informations dont RM a besoin pour démarrer AM.
En général, le Client doit définir les éléments suivants dans le contexte :
- Informations sur l'application : incluent l'identifiant et le nom de l'application.
- Informations sur la file d'attente et la priorité : incluent les files d'attente et les priorités attribuées pour la soumission de l'application.
- Utilisateurs : indique qui est l'utilisateur ayant soumis l'application.
- ContainerLaunchContext : définit les informations du conteneur dans lequel démarrer et exécuter AM. Toutes les informations nécessaires pour exécuter l'application sont définies dans le
ContainerLaunchContext, y compris les ressources locales (fichiers binaires, fichiers jar, etc.), les variables d'environnement (CLASSPATH, etc.), les commandes à exécuter et le jeton sécurisé (RECT) :
// Définir le contexte de soumission de l'application
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
ApplicationId appId = appContext.getApplicationId();
appContext.setKeepContainersAcrossApplicationAttempts(keepContainers);
appContext.setApplicationName(appName);
// Le code suivant est utilisé pour définir les ressources locales d'ApplicationMaster
/ / Les ressources locales doivent être des fichiers locaux ou des packages compressés, etc.
// Dans ce scénario, le package jar est sous forme de fichier et est l'une des ressources locales d'AM.
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
LOG.info("Copier le package jar d'AppMaster depuis le système de fichiers local et l'ajouter à l'environnement local.");
// Copier le package jar d'ApplicationMaster dans le système de fichiers
FileSystem fs = FileSystem.get(conf);
// Créer une ressource locale qui pointe vers le chemin du package jar
addToLocalResources(fs, appMasterJar, appMasterJarPath, appId.toString(), localResources, null);
// Définir les paramètres des journaux, vous pouvez l'omettre
if (!log4jPropFile.isEmpty()) {
addToLocalResources(fs, log4jPropFile, log4jPath, appId.toString(), localResources, null);
}
// Le script shell sera disponible dans le conteneur qui finira par l'exécuter
// Donc, copiez-le d'abord dans le système de fichiers pour que le cadre YARN puisse le trouver
// Vous n'avez pas besoin de le définir comme ressource locale d'AM ici car celui-ci n'en a pas besoin
String hdfsShellScriptLocation = "";
long hdfsShellScriptLen = 0;
long hdfsShellScriptTimestamp = 0;
if (!shellScriptPath.isEmpty()) {
Path shellSrc = new Path(shellScriptPath);
String shellPathSuffix = appName + "/" + appId.toString() + "/" + SCRIPT_PATH;
Path shellDst = new Path(fs.getHomeDirectory(), shellPathSuffix);
fs.copyFromLocalFile(false, true, shellSrc, shellDst);
hdfsShellScriptLocation = shellDst.toUri().toString();
FileStatus shellFileStatus = fs.getFileStatus(shellDst);
hdfsShellScriptLen = shellFileStatus.getLen();
hdfsShellScriptTimestamp = shellFileStatus.getModificationTime();
}
if (!shellCommand.isEmpty()) {
addToLocalResources(fs, null, shellCommandPath, appId.toString(),
localResources, shellCommand);
}
if (shellArgs.length > 0) {
addToLocalResources(fs, null, shellArgsPath, appId.toString(),
localResources, StringUtils.join(shellArgs, " "));
}
// Définir les paramètres d'environnement requis par AM
LOG.info("Définir l'environnement pour le maître d'application");
Map<String, String> env = new HashMap<String, String>();
// Ajouter le chemin du script shell à la variable d'environnement
// AM créera la ressource locale appropriée pour le conteneur final en conséquence
// et le conteneur ci-dessus exécutera le script shell au démarrage
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLOCATION, hdfsShellScriptLocation);
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTTIMESTAMP, Long.toString(hdfsShellScriptTimestamp));
env.put(DSConstants.DISTRIBUTEDSHELLSCRIPTLEN, Long.toString(hdfsShellScriptLen));
// Ajouter le chemin du package AppMaster.jar au classpath
// Notez qu'il n'est pas nécessaire de fournir un classpath lié à Hadoop ici, car nous avons une annotation dans le fichier de configuration externe.
// Le code suivant ajoute tous les paramètres de chemin liés au classpath requis par AM au répertoire actuel
StringBuilder classPathEnv = new StringBuilder(Environment.CLASSPATH.$$())
.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append("./*");
for (String c : conf.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR).append(
"./log4j.properties");
// Définir la commande à exécuter pour AM
Vector<CharSequence> vargs = new Vector<CharSequence>(30);
// Définir la commande exécutable pour Java
LOG.info("Configurer la commande du maître d'application");
vargs.add(Environment.JAVA_HOME.$$() + "/bin/java");
// Définir le nombre de mémoire attribué par les paramètres Xmx sous JVM
vargs.add("-Xmx" + amMemory + "m");
// Définir les noms de classes
vargs.add(appMasterMainClass);
// Définir le paramètre d'ApplicationMaster
vargs.add("--container_memory " + String.valueOf(containerMemory));
vargs.add("--container_vcores " + String.valueOf(containerVirtualCores));
vargs.add("--num_containers " + String.valueOf(numContainers));
vargs.add("--priority " + String.valueOf(shellCmdPriority));
for (Map.Entry<String, String> entry : shellEnv.entrySet()) {
vargs.add("--shell_env " + entry.getKey() + "=" + entry.getValue());
}
if (debugFlag) {
vargs.add("--debug");
}
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/AppMaster.stderr");
// Générer le paramètre final et le configurer
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
LOG.info("Terminé la configuration de la commande du maître d'application " + command.toString());
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Définir le conteneur pour démarrer le contexte d'AM
ContainerLaunchContext amContainer = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
// La requête de définition des types de ressources, y compris la mémoire et les noyaux virtuels de processeur.
Resource capability = Resource.newInstance(amMemory, amVCores);
appContext.setResource(capability);
// Si nécessaire, les données du service YARN sont passées aux applications au format binaire. Mais cela n'est pas nécessaire dans cet exemple.
// amContainer.setServiceData(serviceData);
// Définir le jeton
if (UserGroupInformation.isSecurityEnabled()) {
Credentials credentials = new Credentials();
String tokenRenewer = conf.get(YarnConfiguration.RM_PRINCIPAL);
if (tokenRenewer == null || tokenRenewer.length() == 0) {
throw new IOException(
"Impossible d'obtenir le principal Kerberos du maître pour l'RM à utiliser comme renouvelateur");
}
// Obtenir le jeton du système de fichiers par défaut
final Token<?> tokens[] =
fs.addDelegationTokens(tokenRenewer, credentials);
if (tokens!= null) {
for (Token<?> token : tokens) {
LOG.info("Obtenu dt pour " + fs.getUri() + "; " + token);
}
}
DataOutputBuffer dob = new DataOutputBuffer();
credentials.writeTokenStorageToStream(dob);
ByteBuffer fsTokens = ByteBuffer.wrap(dob.getData(), 0, dob.getLength());
amContainer.setTokens(fsTokens);
}
appContext.setAMContainerSpec(amContainer);
Une fois le processus de configuration terminé, le client peut soumettre des applications avec la priorité et la file d'attente spécifiées :
/ / Définir la priorité d'AM
Priority pri = Priority.newInstance(amPriority);
appContext.setPriority(pri);
// Définir la file d'attente où l'application est soumise à RM
appContext.setQueue(amQueue);
// Soumettre l'application à AM
yarnClient.submitApplication(appContext);
À ce stade, RM acceptera l'application et configurera et lancera AM dans le conteneur affecté en arrière-plan.
Les clients peuvent suivre l'avancement des tâches réelles de diverses manières.
(1) L'une d'entre elles est que vous pouvez communiquer avec RM via la méthode getApplicationReport() de l'objet YarnClient et demander un rapport sur l'application :
// Utiliser l'identifiant d'application pour obtenir son rapport
ApplicationReport report = yarnClient.getApplicationReport(appId);
Les rapports reçus de RM incluent les éléments suivants :
- Informations générales : incluent le numéro (position) de l'application, la file d'attente de soumission de l'application, l'utilisateur ayant soumis l'application et l'heure de démarrage de l'application.
- Détails sur l'ApplicationMaster : l'hôte qui exécute AM, le port RPC qui écoute les requêtes des Clients et les jetons que le Client et AM doivent utiliser pour communiquer.
- Informations de suivi de l'application : si l'application prend en charge une forme de suivi de l'avancement, elle peut définir l'URL de suivi via la méthode
getTrackingUrl()rapportée par l'application et le client peut surveiller l'avancement par cette méthode. - État de l'application : vous pouvez voir l'état de l'application de
ResourceManagerdansgetYarnApplicationState. SiYarnApplicationStateest défini surcomplete, le Client devrait se référer àgetFinalApplicationStatuspour vérifier si la tâche de l'application a été exécutée avec succès. En cas d'échec, plus d'informations sur l'échec peuvent être trouvées avecgetDiagnostics.
(2) Si l'ApplicationMaster le supporte, le Client peut directement interroger l'avancement de AM lui-même en utilisant les informations hostname:rpcport obtenues à partir du rapport sur l'application.
Dans certains cas, si l'application a été exécutée trop longtemps, le Client peut souhaiter terminer l'application. YarnClient prend en charge l'appel à killApplication. Il permet au Client d'envoyer un signal d'arrêt à AM via le ResourceManager. Si tel est le cas, le gestionnaire d'application peut également terminer l'appel grâce à son support de couche RPC, dont le client peut tirer parti.
Le code spécifique est le suivant, mais le code n'est que pour référence et n'a pas besoin d'être écrit dans Client.java :
yarnClient.killApplication(appId);
Après avoir édité le contenu ci-dessus, enregistrez le contenu et quittez l'éditeur vim.
Écrire le code du ApplicationMaster
De manière similaire, utilisez l'éditeur vim pour ouvrir le fichier ApplicationMaster.java et écrire le code :
vim /home/hadoop/yarn_app/ApplicationMaster.java
package com.labex.yarn.app;
public class ApplicationMaster {
public static void main(String[] args){
//TODO: Éditer le code ici.
}
}
L'explication du code est toujours sous forme de segments. Tout le code mentionné ci-dessous devrait être écrit dans la classe ApplicationMaster (c'est-à-dire le bloc de code où se trouve le commentaire //TODO: Éditer le code ici.).
AM est le véritable propriétaire de l'exécution de tâche, qui est démarré par RM et fournit toutes les informations et ressources nécessaires via le Client pour superviser et terminer la tâche.
Puisque AM est démarré dans un seul conteneur, il est probable que le conteneur partage le même hôte physique avec d'autres conteneurs. Compte tenu des fonctionnalités de multi-locataire de la plateforme de calcul cloud et d'autres problèmes, il est possible de ne pas savoir les ports prédéfinis à écouter au début.
Donc, lorsque AM démarre, plusieurs paramètres peuvent lui être donnés via l'environnement. Ces paramètres incluent l'identifiant de conteneur du conteneur AM, l'heure de soumission de l'application et les détails sur l'hôte NodeManager qui exécute AM.
Toutes les interactions avec RM nécessitent une planification d'application. Si ce processus échoue, chaque application peut réessayer. Vous pouvez obtenir ApplicationAttemptId à partir de l'identifiant de conteneur d'AM. Il existe des API associées qui peuvent convertir les valeurs obtenues à partir de l'environnement en objets.
Écrivez le code suivant :
Map<String, String> envs = System.getenv();
String containerIdString = envs.get(ApplicationConstants.AM_CONTAINER_ID_ENV);
If (containerIdString == null) {
// L'identifiant de conteneur devrait être défini dans la variable d'environnement du framework
Throw new IllegalArgumentException(
"Identifiant de conteneur non défini dans l'environnement");
}
ContainerId containerId = ConverterUtils.toContainerId(containerIdString);
ApplicationAttemptId appAttemptID = containerId.getApplicationAttemptId();
Après l'initialisation complète d'AM, nous pouvons démarrer deux clients : un client vers le ResourceManager et l'autre vers le NodeManager. Nous utilisons un gestionnaire d'événements personnalisé pour le configurer, et les détails seront discutés plus tard :
AMRMClientAsync.CallbackHandler allocListener = new RMCallbackHandler();
amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
containerListener = createNMCallbackHandler();
nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
AM doit envoyer périodiquement des battements de cœur à RM afin que ce dernier sache que AM est toujours en cours d'exécution. L'intervalle d'expiration sur RM est défini par YarnConfiguration et sa valeur par défaut est définie par l'élément de configuration YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS dans le fichier de configuration. AM doit s'enregistrer auprès du ResourceManager pour commencer à envoyer des battements de cœur :
// S'enregistrer auprès de RM et commencer à envoyer des battements de cœur à RM
appMasterHostname = NetUtils.getHostname();
RegisterApplicationMasterResponse response = amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
Les informations de réponse du processus d'enregistrement peuvent inclure la capacité maximale de ressources du cluster. Nous pouvons utiliser ces informations pour vérifier la demande de l'application :
// Sauvegarder temporairement les informations sur les capacités de ressources du cluster dans RM
int maxMem = response.getMaximumResourceCapability().getMemory();
LOG.info("Capacité maximale de mémoire des ressources de ce cluster " + maxMem);
int maxVCores = response.getMaximumResourceCapability().getVirtualCores();
LOG.info("Capacité maximale de vNœuds des ressources de ce cluster " + maxVCores);
// Utiliser la limite de mémoire maximale pour contraindre la valeur de demande de capacité de mémoire du conteneur
if (containerMemory > maxMem) {
LOG.info("Mémoire du conteneur spécifiée au-dessus du seuil maximal du cluster."
+ " Utilisation de la valeur maximale." + ", spécifiée=" + containerMemory + ", max="
+ maxMem);
containerMemory = maxMem;
}
if (containerVirtualCores > maxVCores) {
LOG.info("Nombre de cœurs virtuels du conteneur spécifié au-dessus du seuil maximal du cluster."
+ " Utilisation de la valeur maximale." + ", spécifié=" + containerVirtualCores + ", max="
+ maxVCores);
containerVirtualCores = maxVCores;
}
List<Container> previousAMRunningContainers =
response.getContainersFromPreviousAttempts();
LOG.info("Reçu " + previousAMRunningContainers.size()
+ " conteneurs en cours d'exécution de l'AM précédent lors de l'enregistrement de l'AM.");
Selon les exigences de la tâche, AM peut planifier un ensemble de conteneurs pour exécuter des tâches. Nous utilisons ces exigences pour calculer combien de conteneurs nous avons besoin et demander un nombre correspondant de conteneurs :
int numTotalContainersToRequest = numTotalContainers - previousAMRunningContainers.size();
for (int i = 0; i < numTotalContainersToRequest; ++i) {
// Définir l'objet de demande pour la demande de conteneur de RM
ContainerRequest containerAsk = setupContainerAskForRM();
// Envoyer la demande de conteneur à RM
amRMClient.addContainerRequest(containerAsk);
// Cette boucle signifie le sondage de RM pour les conteneurs après avoir obtenu les quotas entièrement alloués
}
La boucle ci-dessus continuera à s'exécuter jusqu'à ce que tous les conteneurs aient été démarrés et que le script shell ait été exécuté (que cela réussisse ou non).
Dans setupContainerAskForRM(), vous devez définir les éléments suivants :
- Capacités de ressources : actuellement, YARN prend en charge les exigences de ressources basées sur la mémoire, donc la demande devrait définir combien de mémoire est nécessaire. Cette valeur est définie en mégabytes et doit être inférieure au multiple exact des capacités maximales et minimales du cluster. Cette ressource mémoire correspond à la limite de mémoire physique imposée sur le conteneur de tâche. Les capacités de ressources incluent également les ressources basées sur le calcul (vNœud).
- Priorité : lors de la demande d'un ensemble de conteneurs, AM peut définir différentes priorités pour les collections. Par exemple, l'AM de MapReduce peut attribuer une priorité plus élevée aux conteneurs requis par la tâche de carte, tandis que le conteneur de tâche de réduction a une priorité plus basse :
Private ContainerRequest setupContainerAskForRM() {
/ / Définir la priorité de la demande
Priority pri = Priority.newInstance(requestPriority);
/ / Définir la demande pour le type de ressource, y compris la mémoire et le CPU
Resource capability = Resource.newInstance(containerMemory,
containerVirtualCores);
ContainerRequest request = new ContainerRequest(capability, null, null, pri);
LOG.info("Demande d'allocation de conteneur : " + request.toString());
Return request;
}
Après que AM ait envoyé une demande d'allocation de conteneur, le conteneur est démarré de manière asynchrone par l'événement handler du client AMRMClientAsync. Les programmes qui gèrent cette logique devraient implémenter l'interface AMRMClientAsync.CallbackHandler.
(1) Lorsque le conteneur est affecté, le gestionnaire doit démarrer un thread. Le thread exécute le code approprié pour démarrer le conteneur. Ici, nous utilisons LaunchContainerRunnable à titre de démonstration. Nous en discuterons plus tard :
@Override
public void onContainersAllocated(List<Container> allocatedContainers) {
LOG.info("Reçu la réponse de RM pour l'allocation de conteneur, allocatedCnt=" + allocatedContainers.size());
numAllocatedContainers.addAndGet(allocatedContainers.size());
for (Container allocatedContainer : allocatedContainers) {
LaunchContainerRunnable runnableLaunchContainer =
new LaunchContainerRunnable(allocatedContainer, containerListener);
Thread launchThread = new Thread(runnableLaunchContainer);
// Démarrer et exécuter le conteneur avec différents threads, ce qui empêche le thread principal de bloquer lorsque tous les conteneurs ne peuvent pas être alloués de ressources
launchThreads.add(launchThread);
launchThread.start();
}
}
(2) Lors de l'envoi d'un battement de cœur, l'événement handler devrait signaler l'avancement de l'application :
@Override
public float getProgress() {
// Définir les informations d'avancement et les signaler à RM lors du prochain envoi de battement de cœur
float progress = (float) numCompletedContainers.get() / numTotalContainers;
Return progress;
}
Le thread de démarrage du conteneur démarre effectivement le conteneur sur NM. Après avoir affecté un conteneur à AM, il doit suivre un processus similaire à celui que suit le Client lorsqu'il configure le ContainerLaunchContext pour l'exécution finale de la tâche sur le conteneur affecté. Après avoir défini le ContainerLaunchContext, AM peut le démarrer via NMClientAsync :
// Définir les commandes nécessaires à exécuter sur le conteneur affecté
Vector<CharSequence> vargs = new Vector<CharSequence>(5);
// Définir la commande exécutable
vargs.add(shellCommand);
// Définir le chemin du script shell
if (!scriptPath.isEmpty()) {
vargs.add(Shell.WINDOWS? ExecBatScripStringtPath
: ExecShellStringPath);
}
// Définir les paramètres pour les commandes shell
vargs.add(shellArgs);
// Ajouter les paramètres de redirection de journal
vargs.add("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout");
vargs.add("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr");
// Obtenir la commande finale
StringBuilder command = new StringBuilder();
for (CharSequence str : vargs) {
command.append(str).append(" ");
}
List<String> commands = new ArrayList<String>();
commands.add(command.toString());
// Définir ContainerLaunchContext pour définir les ressources locales, les variables d'environnement, les commandes et les jetons pour le constructeur.
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, shellEnv, commands, null, allTokens.duplicate(), null);
containerListener.addContainer(container.getId(), container);
nmClientAsync.startContainerAsync(container, ctx);
L'objet NMClientAsync et son gestionnaire d'événements sont responsables de la gestion des événements de conteneur. Cela inclut le démarrage, l'arrêt, les mises à jour d'état et les erreurs pour le conteneur.
Après que l'ApplicationMaster ait déterminé qu'il a terminé, il doit se désenregistrer auprès du Client d'AM-RM puis arrêter le Client :
try {
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
} catch (YarnException ex) {
LOG.error("Échec du désenregistrement de l'application", ex);
} catch (IOException e) {
LOG.error("Échec du désenregistrement de l'application", e);
}
amRMClient.stop();
Le contenu ci-dessus est le code principal de ApplicationMaster. Après édition, enregistrez le contenu et quittez l'éditeur vim.
Le processus de lancement de l'application
Le processus de lancement d'une application sur un cluster Hadoop est le suivant :
Compiler et lancer l'application
Après que le code de la section précédente ait été terminé, vous pouvez le compiler en un package Jar et le soumettre au cluster Hadoop en utilisant un outil de construction tel que Maven et Gradle.
Puisque le processus de compilation nécessite une connexion réseau pour télécharger les dépendances pertinentes, cela prend beaucoup de temps (environ 1 heure au pic). Donc, sautez le processus de compilation ici et utilisez le package Jar déjà compilé dans le répertoire d'installation de Hadoop pour les expériences suivantes.
Dans cette étape, nous utilisons l'exemple Jar simple pour exécuter l'application YARN au lieu de construire le Jar spécifié par Maven.
Veuillez utiliser la commande yarn jar dans le terminal pour soumettre l'exécution. Les paramètres impliqués dans les commandes suivantes sont le chemin du package Jar à exécuter, le nom de la classe principale, le chemin du package Jar soumis au cadre YARN, le nombre de commandes shell à exécuter et le nombre de conteneurs :
/home/hadoop/hadoop/bin/yarn jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Consultez la sortie dans le terminal, et vous pouvez voir l'avancement de l'exécution de l'application.
Estimated value of Pi is 3.55555555555555555556
Pendant l'exécution de la tâche, vous pouvez voir les indications de chaque étape à partir de la sortie du terminal, telles que initialisation du Client, connexion au RM et obtention des informations sur le cluster.
Voir les résultats de l'exécution de l'application
Double-cliquez pour ouvrir le navigateur web Firefox sur le bureau et entrez l'URL suivante dans la barre d'adresse pour voir les informations sur les ressources des nœuds dans le modèle YARN du cluster Hadoop :
http://localhost:8088
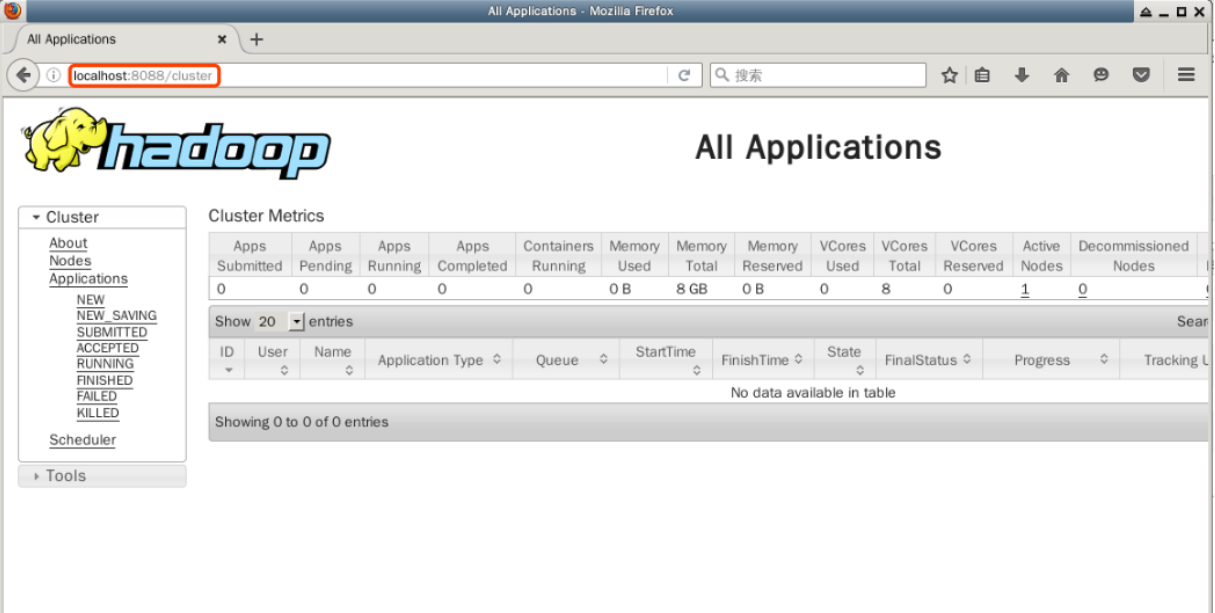
Dans cette page, toutes les informations sur le cluster Hadoop sont affichées, y compris l'état des nœuds, des applications et des planificateurs.
Ce qui est le plus important de tout cela, c'est la gestion de l'application, et nous pourrons voir plus tard l'état d'exécution de l'application soumise ici. Ne fermez pas le navigateur Firefox pour l'instant.
Résumé
Sur la base de la configuration d'un cluster Hadoop pseudo-distribué, ce laboratoire continue de nous apprendre l'architecture, le principe de fonctionnement, la configuration, ainsi que les techniques de développement et de surveillance du cadre YARN. Un grand nombre de fichiers de code et de configuration sont fournis dans le cours, veuillez donc les lire attentivement.


