Introduction
L'essence de Docker est d'utiliser LXC pour réaliser des fonctionnalités similaires à celles d'une machine virtuelle, économisant ainsi les ressources matérielles et offrant aux utilisateurs plus de ressources de calcul. Ce projet combine le langage C++ avec les technologies Namespace et Control Group de Linux pour implémenter un simple conteneur Docker.
Enfin, nous allons réaliser les fonctionnalités suivantes pour le conteneur :
- Système de fichiers indépendant
- Prise en charge de l'accès réseau
👀 Aperçu
$ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
$ sudo./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
🎯 Tâches
Dans ce projet, vous allez apprendre :
- Comment créer un simple conteneur Docker en utilisant le langage C++ et la technologie Namespace de Linux
- Comment implémenter un système de fichiers indépendant pour le conteneur
- Comment activer l'accès réseau pour le conteneur
🏆 Réalisations
Après avoir terminé ce projet, vous serez en mesure de :
- Créer un simple conteneur Docker en utilisant le langage C++ et la technologie Namespace de Linux
- Implémenter un système de fichiers indépendant pour le conteneur
- Activer l'accès réseau pour le conteneur
Technologie Namespace Linux
En C++, nous sommes familiers avec le mot-clé namespace. En C++, chaque espace de noms (namespace) isole les mêmes noms dans différents morceaux de code. Ainsi, tant que les noms des espaces de noms sont différents, les noms des éléments de code dans ces espaces de noms peuvent être identiques, résolvant ainsi le problème de conflits de noms dans le code.
La technologie Linux Namespace, quant à elle, est une fonctionnalité offerte par le noyau Linux qui fournit une solution d'isolation des ressources pour les applications, similaire au concept de namespace en C++. Nous savons que des ressources telles que les PID (identifiants de processus), les IPC (communications inter-processus) et le réseau sont normalement gérées par le système d'exploitation. Cependant, Linux Namespace permet de rendre ces ressources non globales et de les assigner à des espaces de noms spécifiques.
Dans le domaine de la technologie Docker, nous entendons souvent des termes tels que LXC (Linux Containers) et la virtualisation au niveau du système d'exploitation (OS-level virtualization). Le LXC utilise la technologie Namespace pour isoler les ressources entre différents conteneurs. Grâce à cette technologie, les processus dans différents conteneurs appartiennent à des espaces de noms distincts et ne s'interfèrent pas les uns avec les autres. En résumé, la technologie Namespace offre une forme légère de virtualisation qui nous permet d'interagir avec les propriétés système à partir de perspectives différentes.
Sous Linux, l'appel système le plus important lié à Namespace est clone(). Le but de clone() est de restreindre les threads à un espace de noms spécifique lors de la création de processus.
Encapsulation des appels système
Étant donné que les appels système Linux sont écrits en C, nous devons écrire du code C++ pour notre projet. Afin de maintenir un style de codage cohérent et purement en C++, nous allons d'abord encapsuler ces API nécessaires sous une forme C++, ce qui nous permettra également de mieux comprendre comment ces API sont utilisées.
Nous allons utiliser les API suivantes :
clone()
Les appels système clone et fork sont tous deux utilisés pour créer des processus sous Linux. Cependant, fork n'est qu'une petite partie de clone. La différence entre eux réside dans le fait que fork ne crée qu'un processus enfant qui est une copie exacte du processus parent, tandis que clone est plus puissant car il permet de copier sélectivement les ressources du processus parent vers le processus enfant. Les ressources qui ne sont pas copiées sont partagées entre les processus via une copie de pointeur (arg). Les ressources spécifiques à copier peuvent être spécifiées à l'aide de flags, et la fonction retourne le PID du processus enfant.
Nous savons qu'un processus se compose de quatre éléments principaux :
- Un segment de code à exécuter
- Un espace de pile privé pour le processus
- Un bloc de contrôle de processus (PCB - Process Control Block)
- Des espaces de noms (namespaces) spécifiques au processus
Les deux premiers éléments correspondent aux paramètres fn et child_stack dans clone. Le bloc de contrôle de processus est contrôlé par le noyau et nous n'avons pas besoin de nous en soucier. Par conséquent, les espaces de noms sont associés au paramètre flags. Afin d'atteindre notre objectif de création d'un conteneur Docker, les principaux paramètres dont nous avons besoin sont les suivants :
Classification de l'espace de noms (Namespace) Paramètre de l'appel système
UTS CLONE_NEWUTS
Montage CLONE_NEWNS
PID CLONE_NEWPID
Réseau CLONE_NEWNET
D'après les noms, on peut voir que CLONE_NEWNS fournit le montage lié au système de fichiers pour la copie et les ressources liées au système de fichiers, CLONE_NEWUTS permet de définir le nom d'hôte, CLONE_NEWPID offre un support pour un espace de processus indépendant, et CLONE_NEWNET fournit un support lié au réseau.
execv()
int execv(const char *path, char *const argv[]);
execv exécute le fichier exécutable spécifié par path. Cet appel système permet à notre processus enfant d'exécuter /bin/bash afin de maintenir le conteneur en cours d'exécution.
sethostname()
int sethostname(const char *name, size_t len);
Comme son nom l'indique, cet appel système est utilisé pour définir le nom d'hôte. Il est important de noter que, puisque les chaînes de caractères au style C utilisent des pointeurs et que la longueur de la chaîne ne peut pas être déterminée directement, le paramètre len est utilisé pour obtenir la longueur de la chaîne.
chdir()
int chdir(const char *path);
Nous savons que tout programme s'exécute dans un répertoire spécifique. Lorsque nous devons accéder à des ressources, nous pouvons utiliser des chemins relatifs au lieu de chemins absolus pour accéder aux ressources pertinentes. chdir nous permet de changer le répertoire de travail de notre programme, ce qui peut être utilisé à certaines fins non divulguées.
chroot()
Cet appel système est utilisé pour changer le répertoire racine :
int chroot(const char *path);
mount()
Cet appel système est utilisé pour monter des systèmes de fichiers, similaire à la commande mount.
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
Création d'un sous - processus de conteneur
Accédez au répertoire ~/project et créez un fichier nommé docker.hpp. Dans ce fichier, nous allons tout d'abord créer un espace de noms (namespace) nommé docker qui peut être appelé par notre code externe.
//
// docker.hpp
// cpp_docker
//
// Fichiers d'en-tête pour les appels système
#include <sys/wait.h> // waitpid
#include <sys/mount.h> // mount
#include <fcntl.h> // open
#include <unistd.h> // execv, sethostname, chroot, fchdir
#include <sched.h> // clone
// Bibliothèque standard C
#include <cstring>
// Bibliothèque standard C++
#include <string> // std::string
#define STACK_SIZE (512 * 512) // Définir la taille de l'espace du processus enfant
namespace docker {
//.. où la magie de Docker commence
}
Commençons par définir quelques variables pour améliorer la lisibilité :
// Défini dans l'espace de noms `docker`
typedef int proc_status;
proc_status proc_err = -1;
proc_status proc_exit = 0;
proc_status proc_wait = 1;
Avant de définir la classe de conteneur, analysons les paramètres nécessaires pour créer un conteneur. Nous ne considérerons pas pour l'instant la configuration liée au réseau. Pour créer un conteneur Docker à partir d'une image, nous n'avons qu'à spécifier le nom d'hôte et l'emplacement de l'image. Par conséquent :
// Configuration de démarrage du conteneur Docker
typedef struct container_config {
std::string host_name; // Nom d'hôte
std::string root_dir; // Répertoire racine du conteneur
} container_config;
Maintenant, définissons la classe container et faisons - la effectuer la configuration nécessaire pour le conteneur dans le constructeur :
class container {
private:
// Améliore la lisibilité
typedef int process_pid;
// Pile du processus enfant
char child_stack[STACK_SIZE];
// Configuration du conteneur
container_config config;
public:
container(container_config &config) {
this->config = config;
}
};
Avant de penser aux méthodes spécifiques de la classe container, pensons d'abord à comment nous utiliserions cette classe container. Pour cela, créons un fichier main.cpp dans le dossier ~/project :
//
// main.cpp
// cpp_docker
//
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
// Configurer le conteneur
//...
docker::container container(config);// Construire le conteneur en fonction de la configuration
container.start(); // Démarrer le conteneur
std::cout << "stop container..." << std::endl;
return 0;
}
Dans main.cpp, pour rendre le démarrage du conteneur concis et facile à comprendre, supposons que le conteneur est démarré à l'aide d'une méthode start(). Cela fournit une base pour écrire le fichier docker.hpp plus tard.
Maintenant, revenons à docker.hpp et implémentons la méthode start() :
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// Effectuer les configurations pertinentes pour le conteneur
//...
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE, // Se déplacer vers le bas de la pile
SIGCHLD, // Envoyer un signal au processus parent lorsque le processus enfant se termine
this);
waitpid(child_pid, nullptr, 0); // Attendre la fin du processus enfant
}
La méthode docker::container::start() utilise l'appel système clone() de Linux. Pour passer l'objet instance docker::container à la fonction de rappel setup, nous pouvons le passer à l'aide du quatrième argument de clone(). Ici, nous passons le pointeur this.
Quant à la fonction setup, nous en créons une expression lambda. En C++, une expression lambda avec une liste de capture vide peut être passée comme pointeur de fonction. Par conséquent, setup devient la fonction de rappel passée à clone().
Vous pouvez également utiliser une fonction membre statique définie dans la classe au lieu d'une expression lambda, mais cela rendrait le code moins élégant.
Dans le constructeur de cette classe container, nous définissons une fonction de gestion du processus enfant à appeler par l'appel système clone(). Nous utilisons typedef pour changer le type de retour de cette fonction en proc_status. Lorsque cette fonction retourne proc_wait, le processus enfant cloné par clone() attendra pour se terminer.
Cependant, cela n'est pas suffisant car nous n'avons effectué aucune configuration dans le processus. Par conséquent, notre programme se terminera immédiatement car il n'y a rien d'autre à faire une fois le processus démarré. Comme nous le savons, dans Docker, pour maintenir un conteneur en cours d'exécution, nous pouvons utiliser :
docker run -it ubuntu:14.04 /bin/bash
Cela lie STDIN au /bin/bash du conteneur. Ajoutons donc une méthode start_bash() à la classe docker::container :
private:
void start_bash() {
// Convertir en toute sécurité une chaîne std::string C++ en une chaîne de caractères au style C char *
// À partir de C++14, cette affectation directe est interdite : `char *str = "test";`
std::string bash = "/bin/bash";
char *c_bash = new char[bash.length()+1]; // +1 pour '\0'
strcpy(c_bash, bash.c_str());
char* const child_args[] = { c_bash, NULL };
execv(child_args[0], child_args); // Exécuter /bin/bash dans le processus enfant
delete []c_bash;
}
Et appelons - la dans setup :
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->start_bash();
return proc_wait;
}
Maintenant, nous pouvons voir les actions suivantes :
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $./a.out
...start container
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ mkdir test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ ls
a.out docker.hpp main.cpp test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ exit
exit
stop container...
Dans les étapes ci - dessus, nous vérifions d'abord le hostname actuel, compilons le code que nous avons écrit jusqu'à présent, l'exécutons et entrons dans notre conteneur. Nous pouvons voir qu'après être entrés dans le conteneur, l'invite bash change, ce qui est ce que nous attendions.
Cependant, il est facile de remarquer que ce n'est pas le résultat que nous voulons, car cela est exactement le même que notre système hôte. Toute opération effectuée dans ce "conteneur" affectera directement le système hôte.
C'est là que nous introduisons les espaces de noms (namespaces) requis dans l'API clone.
Permettre au conteneur d'avoir son propre nom d'hôte
Comme mentionné précédemment dans la section sur les appels système, il est assez simple de définir le nom d'hôte d'un processus enfant à l'aide d'un appel système. Par conséquent, nous créons une méthode privée pour la classe docker::container :
private:
// Définir le nom d'hôte du conteneur
void set_hostname() {
sethostname(this->config.host_name.c_str(), this->config.host_name.length());
}
Nous apportons également des modifications à la méthode start() comme suit :
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// Configurer le conteneur
_this->set_hostname();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // Ajouter l'espace de noms UTS
SIGCHLD, // Envoyer un signal au parent lorsque le processus enfant se termine
this);
waitpid(child_pid, nullptr, 0); // Attendre la fin du processus enfant
}
Dans le fichier main.cpp, nous configurons le nom du nom d'hôte :
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
……
Maintenant, recompilons le code :
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $./a.out
...start container
stop container...
On observe que notre conteneur se termine immédiatement. C'est parce que dès que nous introduisons l'espace de noms (namespace), notre programme nécessite des privilèges de superutilisateur. Par conséquent, nous devons exécuter le programme avec sudo :
labex:project/ $ sudo./a.out
...start container
root@labex:/home/labex/project## hostname
labex
root@labex:/home/labex/project## exit
exit
stop container...
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
Cependant, cela n'atteint toujours pas l'effet souhaité du conteneur car, comme nous pouvons le voir avec la commande ls, nous pouvons toujours accéder au répertoire de la machine hôte.
Permettre au conteneur d'avoir son propre système de fichiers
Dans la technologie Docker, les conteneurs sont créés à partir d'images. Étant donné que nous voulons implémenter un conteneur, il est naturel que nous devions le créer à partir d'une image. Heureusement, nous avons préparé une image Docker pour vous. Vous pouvez l'obtenir en la téléchargeant depuis :
cd ~/project
wget --header="User-Agent: Mozilla/5.0" https://file.labex.io/lab/171925/docker-image.tar
Ensuite, extrayez - la dans le dossier ~/project/labex :
mkdir labex
tar -xf docker-image.tar --directory labex/
rm docker-image.tar
Ici, vous pourriez rencontrer des erreurs d'extraction. C'est parce que dans l'environnement, certains fichiers sont interdits d'être créés de l'extérieur. Cela n'affecte pas notre implémentation de notre propre conteneur, alors ignorez - le simplement.
tar: dev/agpgart: Cannot mknod: Operation not permitted
tar: dev/audio: Cannot mknod: Operation not permitted
tar: dev/audio1: Cannot mknod: Operation not permitted
tar: dev/audio2: Cannot mknod: Operation not permitted
tar: dev/audio3: Cannot mknod: Operation not permitted
tar: dev/audioctl: Cannot mknod: Operation not permitted
……
Une fois l'extraction terminée, nous verrons un répertoire Linux presque complet sous labex :
labex:project/ $ ls labex
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Maintenant, nous voulons que docker::container entre dans ce répertoire et l'utilise comme répertoire racine, masquant l'accès externe du sous - processus au démarrage :
private:
// Définir le répertoire racine
void set_rootdir() {
// Appel système chdir, basculer vers un certain répertoire
chdir(this->config.root_dir.c_str());
// Appel système chroot, définir le répertoire racine, puisque nous
// avons déjà basculé vers le répertoire actuel précédemment
// nous pouvons simplement utiliser le répertoire actuel comme répertoire racine
chroot(".");
}
Ensuite, complétez la configuration pertinente dans main.cpp :
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
……
Et activez CLONE_NEWNS dans l'appel clone() pour activer l'espace de noms de montage (Mount Namespace) :
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // Espace de noms UTS
CLONE_NEWNS| // Espace de noms de montage
SIGCHLD, // Un signal est envoyé au processus parent lorsque le processus enfant se termine
this);
waitpid(child_pid, nullptr, 0); // Attendre la fin du processus enfant
}
Maintenant, recompilons :
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $ sudo./a.out
...start container
root@labex:/## ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@labex:/## hostname
labex
En exécutant ls, nous pouvons voir que le processus enfant vit maintenant dans un répertoire linux complet.
Permettre au conteneur d'avoir son propre système de processus
Cependant, il y a toujours un problème. Si nous utilisons des commandes comme ps ou top, nous pouvons toujours observer tous les processus du processus parent. Ce n'est pas l'effet souhaité. Par exemple, nous pouvons voir a.out dans la sortie de ps, et la valeur de l'identifiant de processus (PID - Process ID) est également très grande.
Pour résoudre ce problème, nous devons introduire l'espace de noms PID (PID Namespace) pour isoler l'espace PID des processus enfants du processus parent.
private:
// Configurer un espace de noms de processus indépendant
void set_procsys() {
// Monter le système de fichiers proc
mount("none", "/proc", "proc", 0, nullptr);
mount("none", "/sys", "sysfs", 0, nullptr);
}
De même, nous devons toujours ajouter cette partie de code dans start(), en introduisant CLONE_NEWPID :
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // Espace de noms UTS
CLONE_NEWNS| // Espace de noms de montage
CLONE_NEWPID| // Espace de noms PID
SIGCHLD, // Un signal est envoyé au processus parent lorsque le processus enfant se termine
this);
waitpid(child_pid, nullptr, 0); // Attendre la fin du processus enfant
}
Maintenant, lorsque nous compilons et exécutons à nouveau, nous verrons que le conteneur a son propre espace de processus indépendant :
À ce stade, nous avons utilisé la technologie d'espaces de noms (Namespace) sous Linux pour isoler les ressources dans les processus enfants et donner à notre conteneur Docker son propre espace de processus et son propre système de fichiers.
Cependant, le conteneur ne peut toujours pas accéder au réseau, et nous pouvons même accéder aux périphériques réseau de la machine hôte en utilisant ifconfig. Ce n'est pas ce que nous voulons. Ensuite, nous allons améliorer davantage le conteneur pour le rendre plus semblable à un conteneur complet, en offrant un support pour l'accès au réseau.
Principes de réseau Docker
Précédemment, nous avons eu une compréhension préliminaire de la façon dont Docker implémente un conteneur fermé. Cependant, nous avons également découvert que le conteneur Docker que nous avons implémenté ne prend pas en charge l'accès au réseau et qu'il n'est pas possible pour les différents conteneurs que nous exécutons d'avoir la capacité de communiquer entre eux.
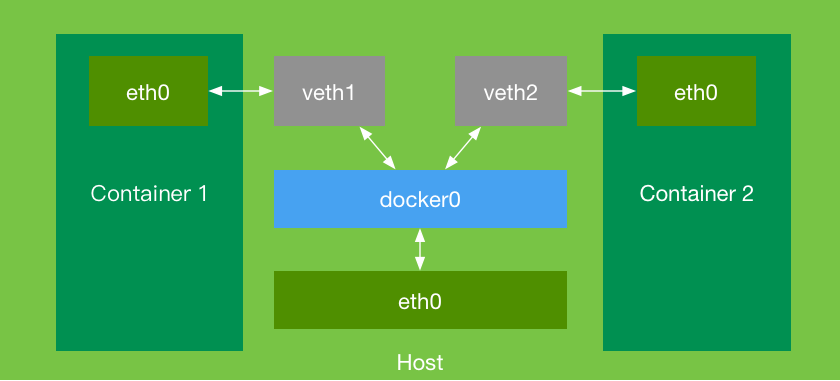
Le principe de communication réseau entre les conteneurs Docker est réalisé grâce à un pont appelé 'docker0'. Les deux conteneurs, 'container1' et 'container2', ont chacun leur propre périphérique réseau, 'eth0'. Toutes les requêtes réseau seront acheminées via 'eth0'. Étant donné que les conteneurs vivent dans des processus enfants, afin de permettre la communication entre leurs interfaces 'eth0', une paire de périphériques réseau, 'veth1' et 'veth2', doit être créée et ajoutée au pont 'docker0'. Cela permet au pont de transférer et de router sans condition les requêtes réseau générées par les interfaces 'eth0' à l'intérieur du conteneur, permettant ainsi la communication entre les conteneurs.
Par conséquent, pour que les conteneurs que nous écrivons aient des capacités de communication réseau, nous devons d'abord créer un pont qu'ils peuvent utiliser. Pour plus de commodité, nous utiliserons directement le 'docker0' existant dans l'environnement.
Préparation pour la création de réseau
Utiliser l'API Linux native pour manipuler le réseau est une tâche très complexe, qui implique également de nombreuses opérations en langage C. Afin de nous concentrer davantage sur le codage en C++, voici quelques "outils" déjà implémentés pour vous, qui vous permettront de manipuler le réseau plus facilement.
Entrez dans le répertoire
/tmpet nous vous avons fourni quatre fichiers :network.h,nl.h,network.cetnl.c.
Copiez ces quatre fichiers dans le répertoire ~/project :
cp /tmp/network.h /tmp/nl.h /tmp/network.c /tmp/nl.c ~/project/
Le code des trois derniers fichiers est extrait de l'ensemble d'outils LXC. Cependant, ce code est écrit en langage C. Étant donné que C++ et C ne sont plus compatibles à partir de C++11, afin que C++ puisse appeler ce code sans problème, nous devons avoir quelques connaissances en programmation mixte C/C++.
Tout d'abord, nous savons que la transformation du code source en fichiers exécutables n'est pas faite directement, mais en plusieurs étapes : prétraitement, compilation, assemblage et liaison. Habituellement, nous utilisons l'étape g++ main.cpp pour effectuer toutes les étapes ci - dessus d'un coup.
Cependant, lorsque le projet devient plus grand et que le nombre de fichiers source augmente, il n'est pas rentable de recompiler tout le projet pour un changement mineur. À ce stade, nous pouvons d'abord compiler le code en fichiers .o, puis effectuer le travail de liaison. Cela nous permet également de compiler un fichier lié compilé en langage C et le code source relatif à C++ en même temps.
C++ et C ont des méthodes de compilation et de traitement différentes, donc lorsque nous voulons compiler un ensemble de code en langage C, nous devons utiliser la macro __cplusplus et extern "C".
Dans network.h, les déclarations d'interface pertinentes de network.c sont stockées. Si nous commentons les parties commentées suivantes :
// #ifdef __cplusplus
// extern "C"
// {
// #endif
#include <sys/types.h>
int netdev_set_flag(const char *name, int flag);
……
void new_hwaddr(char *hwaddr);
// #ifdef __cplusplus
// }
// #endif
En utilisant gcc pour le compiler directement en fichiers .o :
gcc -c network.c nl.c
Et ensuite en utilisant le code suivant :
// test.cpp
#include "network.h"
int main() {
new_hwaddr(nullptr);
return 0;
}
Pour le compiler et le tester :
g++ test.cpp network.o nl.o -std=c++11
Nous constatons que la compilation échoue et affiche une erreur undefined reference to 'new_hwaddr(char*)'.
/usr/bin/ld: /tmp/ccz4DEEy.o: in function `main':
test.cpp:(.text+0xe): undefined reference to `new_hwaddr(char*)'
collect2: error: ld returned 1 exit status
En d'autres termes :
Lorsque nous voulons compiler et lier des bibliothèques C en C++, nous devons envelopper la déclaration pertinente de l'interface :
#ifdef __cplusplus
extern "C"
{
#endif
// Fonctions d'interface C
#ifdef __cplusplus
}
#endif
À ce moment, nous recompilons network.c et nl.c en fichiers .o à nouveau, puis nous compilons *.o avec test.cpp pour les compiler avec succès.
Création d'un réseau de conteneurs
Sur la base de la section précédente sur le principe réseau de Docker, nous pouvons résumer les étapes suivantes pour permettre aux conteneurs que nous créons de prendre en charge le réseau :
- Créer une paire de périphériques réseau virtuels veth1/veth2 ;
- Définir l'adresse MAC de veth1 ;
- Ajouter veth1 au pont labex0 ;
- Activer veth1 ;
- Créer un processus enfant ;
- Déplacer veth2 dans l'espace de noms réseau du processus enfant et le renommer en eth0 ;
- Attendre la fin du processus enfant ;
- Supprimer les périphériques réseau veth1 et veth2 ;
Nous devons donc optimiser davantage la logique de la méthode start().
Tout d'abord, nous devons ajouter la configuration liée au réseau à docker::container_config :
Inclure les fichiers d'en-tête :
#include <net/if.h> // if_nametoindex
#include <arpa/inet.h> // inet_pton
#include "network.h"
Ajouter la configuration docker::container_config :
// Configuration de démarrage du conteneur Docker
typedef struct container_config {
std::string host_name; // Nom d'hôte
std::string root_dir; // Répertoire racine du conteneur
std::string ip; // Adresse IP du conteneur
std::string bridge_name; // Nom du pont
std::string bridge_ip; // Adresse IP du pont
} container_config;
Ensuite, définir l'adresse IP du conteneur, le nom du pont à ajouter docker0 et l'adresse IP du pont dans main.cpp :
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
// Configurer les paramètres réseau
config.ip = "192.168.0.100"; // Adresse IP du conteneur
config.bridge_name = "docker0"; // Pont hôte
config.bridge_ip = "192.168.0.1"; // Adresse IP du pont hôte
docker::container container(config);
container.start();
std::cout << "stop container..." << std::endl;
return 0;
}
Refactorisons la méthode start() en fonction de la logique de chargement des périphériques réseau ci-dessus :
private:
// Sauvegarder les périphériques réseau du conteneur pour la suppression
char *veth1;
char *veth2;
public:
void start() {
char veth1buf[IFNAMSIZ] = "labex0X";
char veth2buf[IFNAMSIZ] = "labex0X";
// Créer une paire de périphériques réseau, l'un à charger sur l'hôte, l'autre à déplacer dans le conteneur du processus enfant
veth1 = lxc_mkifname(veth1buf); // L'API lxc_mkifname nécessite d'ajouter au moins un "X" au nom du périphérique réseau virtuel pour prendre en charge la création aléatoire de périphériques réseau virtuels
veth2 = lxc_mkifname(veth2buf); // Cela permet de garantir la création correcte des périphériques réseau. Voir l'implémentation de lxc_mkifname dans network.c pour plus de détails
lxc_veth_create(veth1, veth2);
// Définir l'adresse MAC de veth1
setup_private_host_hw_addr(veth1);
// Ajouter veth1 au pont
lxc_bridge_attach(config.bridge_name.c_str(), veth1);
// Activer veth1
lxc_netdev_up(veth1);
// Certains travaux de configuration avant la création du conteneur
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
// Configurer le réseau à l'intérieur du conteneur
//...
_this->start_bash();
return proc_wait;
};
// Créer le conteneur en utilisant clone
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // Espace de noms UTS
CLONE_NEWNS| // Espace de noms de montage
CLONE_NEWPID| // Espace de noms PID
CLONE_NEWNET| // Espace de noms réseau
SIGCHLD, // Le processus enfant enverra un signal au processus parent lorsqu'il se terminera
this);
// Déplacer veth2 dans le conteneur et le renommer en eth0
lxc_netdev_move_by_name(veth2, child_pid, "eth0");
waitpid(child_pid, nullptr, 0); // Attendre la fin du processus enfant
}
~container() {
// N'oubliez pas de supprimer les périphériques réseau virtuels créés lors de la sortie
lxc_netdev_delete_by_name(veth1);
lxc_netdev_delete_by_name(veth2);
}
Note : Ajouter
CLONE_NEWNETdansclone.
À partir des étapes ci-dessus, nous pouvons voir qu'après avoir créé les périphériques réseau et lors de la création du processus enfant, nous devons effectuer des configurations liées à l'intérieur du conteneur en collaboration avec les périphériques réseau externes :
- Activer le périphérique
loà l'intérieur du conteneur ; - Configurer l'adresse IP de
eth0; - Activer
eth0; - Définir la passerelle ;
- Définir l'adresse MAC de
eth0;
private:
void set_network() {
int ifindex = if_nametoindex("eth0");
struct in_addr ipv4;
struct in_addr bcast;
struct in_addr gateway;
// Fonction de transformation d'adresse IP qui convertit les adresses IP entre la notation décimale pointée et la notation binaire
inet_pton(AF_INET, this->config.ip.c_str(), &ipv4);
inet_pton(AF_INET, "255.255.255.0", &bcast);
inet_pton(AF_INET, this->config.bridge_ip.c_str(), &gateway);
// Configurer l'adresse IP de eth0
lxc_ipv4_addr_add(ifindex, &ipv4, &bcast, 16);
// Activer lo
lxc_netdev_up("lo");
// Activer eth0
lxc_netdev_up("eth0");
// Définir la passerelle
lxc_ipv4_gateway_add(ifindex, &gateway);
// Définir l'adresse MAC de eth0
char mac[18];
new_hwaddr(mac);
setup_hw_addr(mac, "eth0");
}
Ensuite, appeler cette méthode dans la fonction setup du conteneur :
……
_this->set_procsys();
_this->set_network(); // Collaboration pour la configuration réseau à l'intérieur du conteneur
_this->start_bash();
return proc_wait;
À ce stade, puisque nous avons commencé à utiliser les fichiers liés compilés network.o et nl.o, écrivons un très simple Makefile :
C = gcc
CXX = g++
C_LIB = network.c nl.c
C_LINK = network.o nl.o
MAIN = main.cpp
LD = -std=c++11
OUT = docker-run
all:
make container
container:
$(C) -c $(C_LIB)
$(CXX) $(LD) -o $(OUT) $(MAIN) $(C_LINK)
clean:
rm *.o $(OUT)
Note : La commande dans le Makefile doit commencer par une tabulation et non par des espaces. Cela est dû au fait que l'interpréteur Markdown convertit une tabulation en quatre espaces. Lorsque vous écrivez un Makefile, assurez-vous d'utiliser une tabulation et non quatre espaces. Sinon, le Makefile affichera une erreur "Makefile:10: *** missing separator. Stop."
Compilez et exécutez à nouveau, puis entrez dans le conteneur. Nous pouvons utiliser ifconfig pour vérifier le réseau :
labex:project/ $ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
labex:project/ $ sudo./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Résumé
Grâce à ce projet, nous avons progressivement réussi les points suivants : intégrer un système de fichiers dans un conteneur et permettre l'accès aux réseaux externes.
Nous avons créé avec succès un conteneur Docker de base. Vous pouvez optimiser davantage ce conteneur pour obtenir une émulation plus réaliste.