
介绍
在本实验中,你将探索 PostgreSQL 视图管理。主要目标是理解和实现不同类型的视图,包括简单视图和物化视图。
你将首先基于 employees 表定义一个简单视图,演示如何创建选择特定列的视图。然后,你将学习如何通过视图查询和潜在修改数据。最后,本实验涵盖了物化视图的创建和填充,以及手动刷新这些视图以保持其最新状态。
定义一个简单的视图
本步骤中,你将学习如何在 PostgreSQL 中定义一个简单视图。视图是基于 SQL 语句结果集的虚拟表。它们对于简化复杂查询、提供抽象和控制数据访问非常有用。
理解视图
视图本质上是一个存储的查询。当你查询一个视图时,PostgreSQL 执行底层查询并返回结果集,就像它是一个真实的表一样。视图本身不存储数据;它们提供了一种不同的方式来访问存储在基表中的数据。
创建 employees 表
首先,让我们创建一个名为 employees 的表来进行操作。打开终端并连接到 PostgreSQL 数据库,以 postgres 用户身份登录:
sudo -u postgres psql
现在,创建 employees 表:
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
department VARCHAR(50),
salary DECIMAL(10, 2)
);
接下来,向 employees 表插入一些示例数据:
INSERT INTO employees (first_name, last_name, department, salary) VALUES
('John', 'Doe', 'Sales', 60000.00),
('Jane', 'Smith', 'Marketing', 75000.00),
('Robert', 'Jones', 'Sales', 62000.00),
('Emily', 'Brown', 'IT', 80000.00),
('Michael', 'Davis', 'Marketing', 70000.00);
你可以通过运行以下查询来验证数据:
SELECT * FROM employees;
你应该在输出中看到插入的数据。
定义 employee_info 视图
现在我们已经有了一个包含数据的表,让我们创建一个简单的视图。这个视图将只显示每个员工的姓名和部门。我们可以使用以下 SQL 语句定义一个名为 employee_info 的视图:
CREATE VIEW employee_info AS
SELECT first_name, last_name, department
FROM employees;
这条语句创建了一个名为 employee_info 的视图,它从 employees 表中选择 first_name、last_name 和 department 列。
查询视图
要查询视图,你可以像使用普通表一样使用 SELECT 语句:
SELECT * FROM employee_info;
此查询将返回所有员工的姓名和部门,正如在视图中定义的那样。
描述视图
你可以在 psql 中使用 \d 命令来描述视图:
\d employee_info
这将显示视图定义及其包含的列。
通过视图查询和修改数据
本步骤中,你将学习如何在 PostgreSQL 中通过视图查询和修改数据。虽然视图主要用于查询数据,但在某些情况下,它们也可以用于修改基表中的底层数据。
通过视图查询数据
如前一步所示,通过视图查询数据非常简单。你可以使用 SELECT 语句从视图中检索数据,就像它是一个普通表一样。
例如,要检索 employee_info 视图中的所有数据:
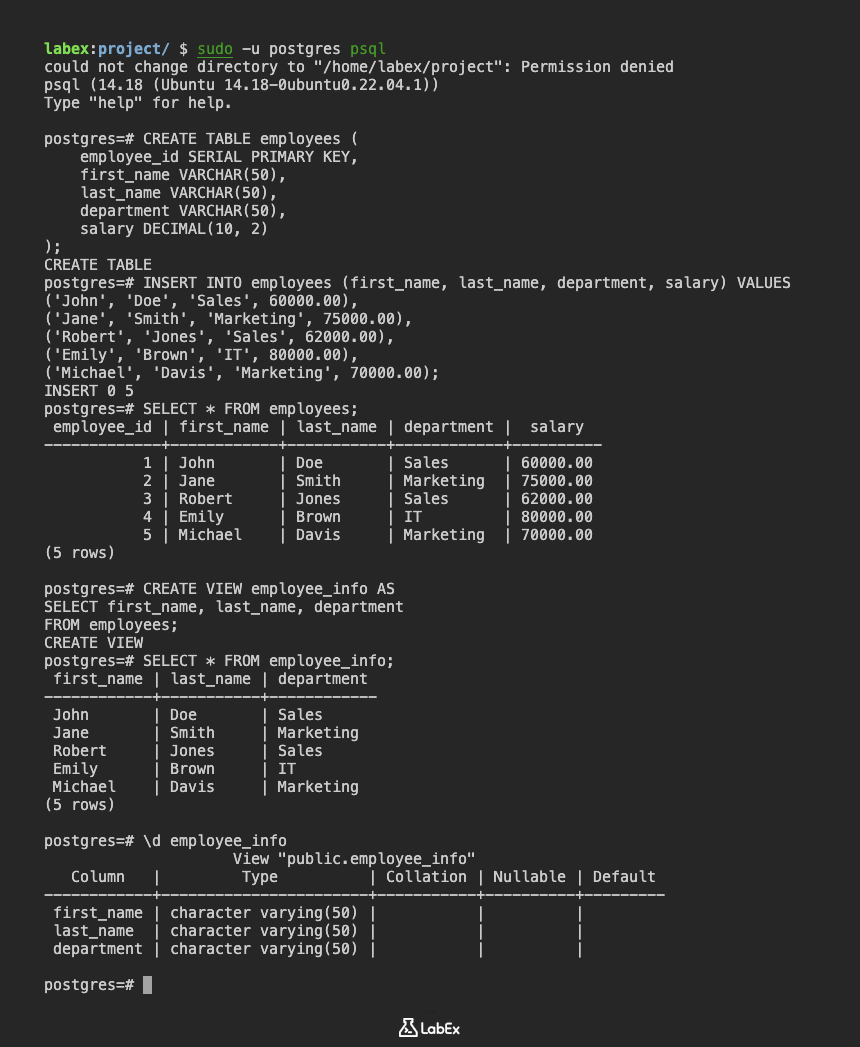
SELECT * FROM employee_info;
你还可以使用 WHERE 子句和其他 SQL 结构来过滤和排序数据:
SELECT * FROM employee_info WHERE department = 'Sales';
此查询将仅返回销售部门的员工。
通过视图修改数据
通过视图修改数据在某些条件下是可能的。视图必须足够简单,以便 PostgreSQL 能够确定要更新的基表和列。通常,如果视图满足以下条件,则可以修改它:
- 它只从一个表中选择数据。
- 它不包含聚合函数(例如,
SUM、AVG、COUNT)。 - 它不包含
GROUP BY、HAVING或DISTINCT子句。
让我们创建一个包含 employee_id 的另一个视图,以便更容易进行更新:
CREATE VIEW employee_details AS
SELECT employee_id, first_name, last_name, department, salary
FROM employees;
现在,让我们尝试通过 employee_details 视图更新员工的薪资:
UPDATE employee_details
SET salary = 65000.00
WHERE employee_id = 1;
这条语句将 employee_id 为 1 的员工的薪资更新为 65000.00。
你可以通过直接查询 employees 表来验证更新:
SELECT * FROM employees WHERE employee_id = 1;
你应该看到 employee_id 为 1 的员工的薪资已更新。
通过视图插入数据
你也可以通过视图插入数据,前提是该视图包含基表中所有非空列。由于我们的 employee_details 视图包含 employees 表的所有列,因此我们可以插入新员工:
INSERT INTO employee_details (first_name, last_name, department, salary)
VALUES ('David', 'Lee', 'IT', 90000.00);
请注意,我们没有指定 employee_id,因为它是一个序列列,并将自动生成。
验证插入:
SELECT * FROM employees WHERE first_name = 'David' AND last_name = 'Lee';
通过视图删除数据
类似地,你可以通过可修改的视图删除数据:
DELETE FROM employee_details WHERE first_name = 'David' AND last_name = 'Lee';
验证删除:
SELECT * FROM employees WHERE first_name = 'David' AND last_name = 'Lee';
重要考虑事项
- 不是所有视图都是可修改的。包含连接、聚合或其他复杂操作的复杂视图通常是只读的。
- 通过视图修改数据可能会影响性能。PostgreSQL 需要将视图操作转换为对底层基表的操作。
- 当通过视图修改数据时,请谨慎操作,因为更改将直接影响基表。
创建和填充物化视图
本步骤中,你将学习如何在 PostgreSQL 中创建和填充物化视图。与普通视图不同,物化视图将查询结果集存储为物理表。这可以显著提高查询性能,尤其对于复杂查询或访问远程数据源的查询。但是,当底层数据发生变化时,物化视图中的数据不会自动更新。你需要手动刷新它,或者安排它定期刷新。
创建物化视图
要创建物化视图,请使用 CREATE MATERIALIZED VIEW 语句。让我们创建一个名为 employee_salaries 的物化视图,该视图显示每个部门的平均薪资。
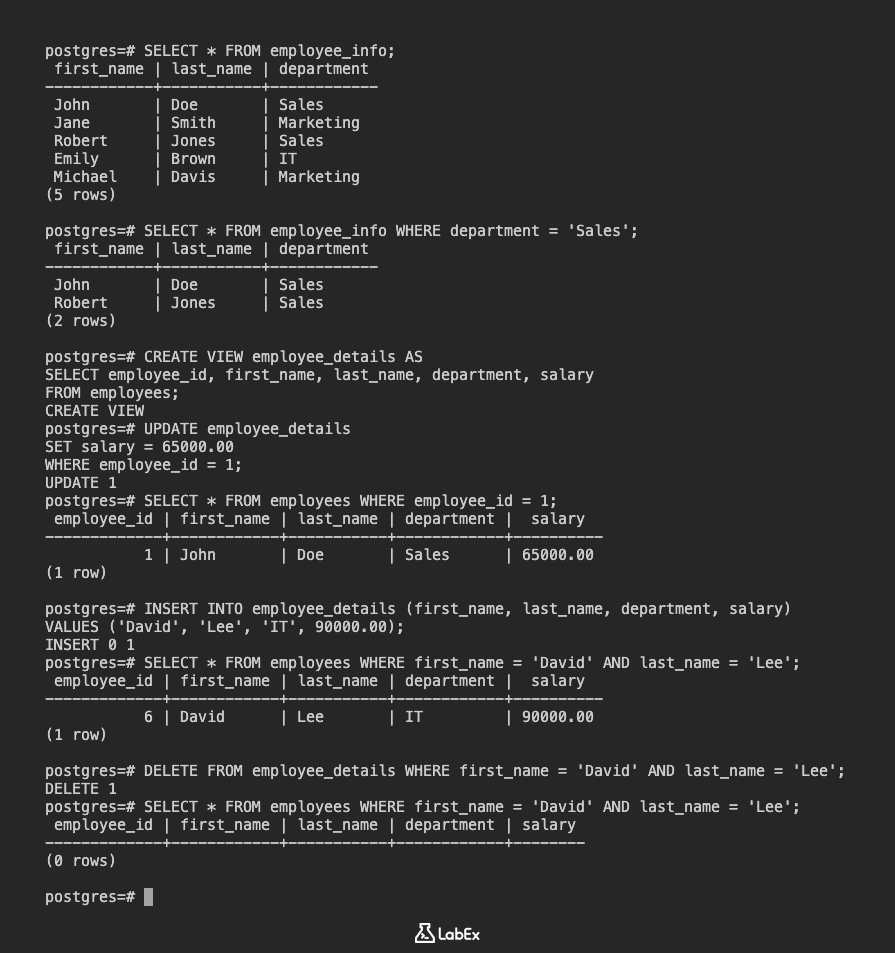
CREATE MATERIALIZED VIEW employee_salaries AS
SELECT department, AVG(salary) AS average_salary
FROM employees
GROUP BY department;
此语句创建了一个名为 employee_salaries 的物化视图,它根据 employees 表中的数据计算每个部门的平均薪资。
查询物化视图
你可以像查询普通表一样查询物化视图:
SELECT * FROM employee_salaries;
这将返回每个部门的部门名称和平均薪资,基于 employees 表在物化视图创建时的状态。
填充物化视图
创建物化视图时,它会自动填充初始数据。但是,如果 employees 表中的底层数据发生变化,employee_salaries 物化视图中的数据不会自动更新。
让我们向 employees 表插入新员工:
INSERT INTO employees (first_name, last_name, department, salary) VALUES
('Alice', 'Johnson', 'IT', 85000.00);
现在,如果你再次查询 employee_salaries 物化视图:
SELECT * FROM employee_salaries;
你会注意到,IT 部门的平均薪资并没有反映新员工,因为物化视图尚未刷新。
描述物化视图
你可以在 psql 中使用 \d 命令来描述物化视图:
\d employee_salaries
这将显示物化视图的定义及其包含的列。
手动刷新物化视图
在本步骤中,你将学习如何在 PostgreSQL 中手动刷新物化视图。如前一步所述,当底层数据发生变化时,物化视图不会自动更新。要反映最新数据,你需要显式地刷新它们。
刷新物化视图
要刷新物化视图,你使用 REFRESH MATERIALIZED VIEW 语句。主要有两种选项:
REFRESH MATERIALIZED VIEW view_name: 这将通过重新执行定义它的查询来刷新物化视图。它会获取物化视图上的ACCESS EXCLUSIVE锁,阻止并发访问。REFRESH MATERIALIZED VIEW CONCURRENTLY view_name: 这将在不阻塞并发查询的情况下刷新物化视图。但是,这要求物化视图至少有一个索引。
让我们首先尝试使用标准的 REFRESH MATERIALIZED VIEW 命令刷新 employee_salaries 物化视图:
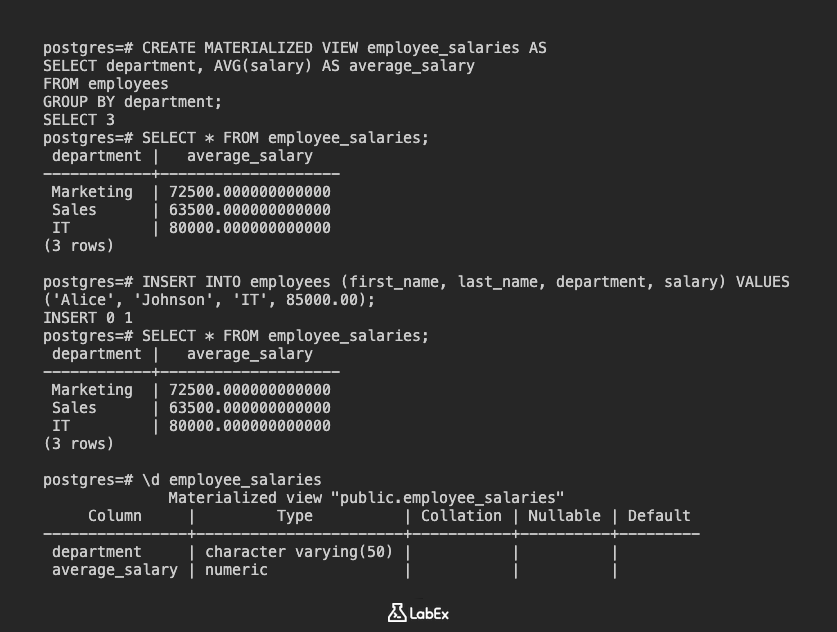
REFRESH MATERIALIZED VIEW employee_salaries;
现在,再次查询 employee_salaries 物化视图:
SELECT * FROM employee_salaries;
你应该会看到 IT 部门的平均工资已更新,以反映新员工的情况。
并发刷新
要并发刷新物化视图,我们首先需要在其上创建一个 UNIQUE 索引。这是并发刷新的要求,因为 PostgreSQL 需要一种方法来唯一标识行,以便在不锁定整个视图的情况下执行刷新。我们的 employee_salaries 视图中的 department 列是唯一的,因为我们的视图是按部门分组的,所以我们可以在其上创建唯一索引。
让我们在 department 列上创建一个唯一索引:
CREATE UNIQUE INDEX idx_employee_salaries_department ON employee_salaries (department);
现在,我们可以并发刷新物化视图:
REFRESH MATERIALIZED VIEW CONCURRENTLY employee_salaries;
再次查询 employee_salaries 物化视图,以确认数据仍然是最新的:
SELECT * FROM employee_salaries;
选择正确的刷新方法
- 对于简单的物化视图,或者当你能容忍短暂的不可用时间时,请使用
REFRESH MATERIALIZED VIEW。 - 对于较大的物化视图,或者当你需要最大限度地减少对并发查询的干扰时,请使用
REFRESH MATERIALIZED VIEW CONCURRENTLY。请记住先在物化视图上创建索引。
重要注意事项
- 刷新物化视图可能是一项资源密集型操作,特别是对于大型数据集。
- 考虑使用
cron等工具安排定期刷新,以保持物化视图中的数据最新。
请记住通过输入 \q 并按 Enter 来退出 psql shell。
总结
在本实验中,你学习了如何在 PostgreSQL 中定义简单的视图。你首先创建了一个名为 employees 的表,包含员工 ID、名字、姓氏、部门和薪资等列,并填充了示例数据。然后,你定义了一个名为 employee_info 的视图,它从 employees 表中选择名字、姓氏和部门,演示了视图如何简化查询并提供对底层数据的特定视角。
你还学习了如何通过视图查询和修改数据,以及如何创建和刷新物化视图。物化视图将查询结果存储为一张表,从而提高复杂查询的性能。你探索了不同的物化视图刷新方法,包括并发刷新以最大限度地减少中断。

