简介
在创建数据可视化图表时,添加注释可以极大地提升观众对图表的理解。文本框是一种直接在可视化图表中包含额外信息的有效方式。Matplotlib 是一个用于创建静态、动画和交互式可视化图表的流行 Python 库,它提供了强大的工具,可用于在图表中添加可自定义的文本框。
在这个实验中,你将学习如何使用 Python 在 Matplotlib 图表中放置文本框。你将了解如何在坐标轴坐标中定位文本,这样无论数据尺度如何变化,文本都能相对于图表保持固定位置。此外,你还将学习如何使用 bbox 属性自定义具有不同样式、颜色和透明度的文本框。
在本实验结束时,你将能够为数据可视化项目创建信息丰富且视觉上吸引人的图表,并巧妙地放置注释。
虚拟机使用提示
虚拟机启动完成后,点击左上角切换到 Notebook 标签页,即可访问 Jupyter Notebook 进行练习。
你可能需要等待几秒钟,让 Jupyter Notebook 加载完成。由于 Jupyter Notebook 的限制,操作验证无法实现自动化。
如果你在实验过程中遇到任何问题,请随时向 Labby 寻求帮助。实验结束后,我们希望你能提供反馈,以帮助我们改进实验体验。
创建 Jupyter Notebook 并准备数据
在第一步中,我们将创建一个新的 Jupyter Notebook 并为可视化准备数据。
创建新的 Notebook
在 Notebook 的第一个单元格中,让我们导入必要的库。输入以下代码,然后点击“运行”按钮或按下 Shift + Enter 来运行它:
import matplotlib.pyplot as plt
import numpy as np
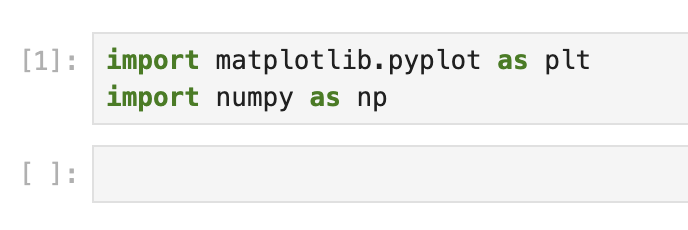
这段代码导入了两个重要的库:
matplotlib.pyplot:一组让 matplotlib 像 MATLAB 一样工作的函数集合numpy:Python 中用于科学计算的基础包
创建示例数据
现在,让我们创建一些用于可视化的示例数据。在一个新的单元格中,输入并运行以下代码:
## Set a random seed for reproducibility
np.random.seed(19680801)
## Generate 10,000 random numbers from a normal distribution
x = 30 * np.random.randn(10000)
## Calculate basic statistics
mu = x.mean()
median = np.median(x)
sigma = x.std()
## Display the statistics
print(f"Mean (μ): {mu:.2f}")
print(f"Median: {median:.2f}")
print(f"Standard Deviation (σ): {sigma:.2f}")
当你运行这个单元格时,你应该会看到类似于以下的输出:
Mean (μ): -0.31
Median: -0.28
Standard Deviation (σ): 29.86
具体的值可能会略有不同。我们创建了一个包含 10000 个从正态分布中生成的随机数的数据集,并计算了三个重要的统计量:
- 均值 (μ):所有数据点的平均值
- 中位数:数据按顺序排列后的中间值
- 标准差 (σ):衡量数据分散程度的指标
这些统计量将在后面用于为我们的可视化添加注释。
创建基本直方图
现在我们已经有了数据,让我们创建一个直方图来可视化其分布。直方图将数据划分为区间(范围),并显示每个区间内数据点的频率。
创建直方图
在你的 Jupyter Notebook 的一个新单元格中,输入并运行以下代码:
## Create a figure and axes
fig, ax = plt.subplots(figsize=(10, 6))
## Create a histogram with 50 bins
histogram = ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Add title and labels
ax.set_title('Distribution of Random Data', fontsize=16)
ax.set_xlabel('Value', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
## Display the plot
plt.tight_layout()
plt.show()
当你运行这个单元格时,你应该会看到一个显示随机数据分布的直方图。输出看起来会是一个以零为中心的钟形曲线(正态分布)。
理解代码
让我们来详细分析代码中每一行的作用:
fig, ax = plt.subplots(figsize=(10, 6)):创建一个图形和坐标轴对象。figsize参数以英寸为单位设置图形的大小(宽度、高度)。histogram = ax.hist(x, bins=50, color='skyblue', edgecolor='black'):为我们的数据x创建一个包含 50 个区间的直方图。区间颜色为天蓝色,边缘为黑色。ax.set_title('Distribution of Random Data', fontsize=16):为图形添加一个字号为 16 的标题。ax.set_xlabel('Value', fontsize=12)和ax.set_ylabel('Frequency', fontsize=12):为 x 轴和 y 轴添加字号为 12 的标签。plt.tight_layout():自动调整图形以适应图形区域。plt.show():显示图形。
直方图展示了我们的数据是如何分布的。由于我们使用了 np.random.randn() 来生成来自正态分布的数据,所以直方图呈现出以 0 为中心的钟形。每个条形的高度代表了落在该区间内的数据点数量。
添加包含统计信息的文本框
现在我们已经有了一个基本的直方图,让我们通过添加一个显示数据统计信息的文本框来对其进行优化。这将使可视化内容对查看者更有参考价值。
创建文本内容
首先,我们需要准备要放入文本框的文本内容。在一个新的单元格中,输入并运行以下代码:
## Create a string with the statistics
textstr = '\n'.join((
r'$\mu=%.2f$' % (mu,), ## Mean
r'$\mathrm{median}=%.2f$' % (median,), ## Median
r'$\sigma=%.2f$' % (sigma,) ## Standard deviation
))
print("Text content for our box:")
print(textstr)
你应该会看到类似于以下的输出:
Text content for our box:
$\mu=-0.31$
$\mathrm{median}=-0.28$
$\sigma=29.86$
这段代码创建了一个多行字符串,其中包含了我们数据的均值、中位数和标准差。让我们来看看这段代码的一些有趣之处:
\n'.join(...)方法将多个字符串连接起来,并用换行符分隔。- 每个字符串前的
r使其成为“原始”字符串,在包含特殊字符时很有用。 $...$符号用于在 matplotlib 中进行 LaTeX 风格的数学格式设置。\mu和\sigma是 LaTeX 符号,分别代表希腊字母 μ(mu)和 σ(sigma)。%.2f是一个格式化说明符,用于显示保留两位小数的浮点数。
创建并添加文本框
现在,让我们重新创建直方图并添加文本框。在一个新的单元格中,输入并运行以下代码:
## Create a new figure and axes
fig, ax = plt.subplots(figsize=(10, 6))
## Create a histogram with 50 bins
histogram = ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Add title and labels
ax.set_title('Distribution of Random Data with Statistics', fontsize=16)
ax.set_xlabel('Value', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
## Define the properties of the text box
properties = dict(boxstyle='round', facecolor='wheat', alpha=0.5)
## Add the text box to the plot
## Position the box in the top left corner (0.05, 0.95) in axes coordinates
ax.text(0.05, 0.95, textstr, transform=ax.transAxes, fontsize=14,
verticalalignment='top', bbox=properties)
## Display the plot
plt.tight_layout()
plt.show()
当你运行这个单元格时,你应该会看到直方图的左上角有一个文本框,显示着统计信息。
理解文本框代码
让我们来详细分析创建文本框的代码的重要部分:
properties = dict(boxstyle='round', facecolor='wheat', alpha=0.5):- 这行代码创建了一个包含文本框属性的字典。
boxstyle='round':使文本框具有圆角。facecolor='wheat':将文本框的背景颜色设置为小麦色。alpha=0.5:使文本框半透明(透明度为 50%)。
ax.text(0.05, 0.95, textstr, transform=ax.transAxes, fontsize=14, verticalalignment='top', bbox=properties):- 这行代码在坐标 (0.05, 0.95) 处向坐标轴添加文本。
transform=ax.transAxes:这一点很关键,它表示坐标使用的是坐标轴单位(0 - 1),而不是数据单位。因此,(0.05, 0.95) 表示“距离绘图左边缘 5%,距离底部边缘 95%”。fontsize=14:设置字体大小。verticalalignment='top':将文本对齐,使文本的顶部位于指定的 y 坐标处。bbox=properties:应用我们定义的文本框属性。
即使你放大绘图或更改数据范围,文本框相对于绘图坐标轴的位置也会保持不变。这是因为我们使用了 transform=ax.transAxes,它使用的是坐标轴坐标,而不是数据坐标。
自定义文本框
既然我们已经成功地在绘图中添加了文本框,那么让我们探索各种自定义选项,使它在视觉上更具吸引力,并适用于不同的场景。
尝试不同的样式
让我们创建一个函数,以便更轻松地尝试不同的文本框样式。在一个新的单元格中,输入并运行以下代码:
def plot_with_textbox(boxstyle, facecolor, alpha, position=(0.05, 0.95)):
"""
Create a histogram with a custom text box.
Parameters:
boxstyle (str): Style of the box ('round', 'square', 'round4', etc.)
facecolor (str): Background color of the box
alpha (float): Transparency of the box (0-1)
position (tuple): Position of the box in axes coordinates (x, y)
"""
## Create figure and plot
fig, ax = plt.subplots(figsize=(8, 5))
ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Set title and labels
ax.set_title(f'Text Box Style: {boxstyle}', fontsize=16)
ax.set_xlabel('Value', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
## Create text box properties
box_props = dict(boxstyle=boxstyle, facecolor=facecolor, alpha=alpha)
## Add text box
ax.text(position[0], position[1], textstr, transform=ax.transAxes,
fontsize=14, verticalalignment='top', bbox=box_props)
plt.tight_layout()
plt.show()
现在,让我们使用这个函数来尝试不同的文本框样式。在一个新的单元格中,输入并运行:
## Try a square box with light green color
plot_with_textbox('square', 'lightgreen', 0.7)
## Try a rounded box with light blue color
plot_with_textbox('round', 'lightblue', 0.5)
## Try a box with extra rounded corners
plot_with_textbox('round4', 'lightyellow', 0.6)
## Try a sawtooth style box
plot_with_textbox('sawtooth', 'lightcoral', 0.4)
当你运行这个单元格时,你会看到四个不同的绘图,每个绘图都有不同样式的文本框。
更改文本框的位置
文本框的位置对于可视化效果至关重要。让我们将文本框放置在绘图的不同角落。在一个新的单元格中,输入并运行:
## Create a figure with a 2x2 grid of subplots
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten() ## Flatten to easily iterate
## Define positions for the four corners
positions = [
(0.05, 0.95), ## Top left
(0.95, 0.95), ## Top right
(0.05, 0.05), ## Bottom left
(0.95, 0.05) ## Bottom right
]
## Define alignments for each position
alignments = [
('top', 'left'), ## Top left
('top', 'right'), ## Top right
('bottom', 'left'), ## Bottom left
('bottom', 'right') ## Bottom right
]
## Corner labels
corner_labels = ['Top Left', 'Top Right', 'Bottom Left', 'Bottom Right']
## Create four plots with text boxes in different corners
for i, ax in enumerate(axes):
## Plot histogram
ax.hist(x, bins=50, color='skyblue', edgecolor='black')
## Set title
ax.set_title(f'Text Box in {corner_labels[i]}', fontsize=14)
## Create text box properties
box_props = dict(boxstyle='round', facecolor='wheat', alpha=0.5)
## Add text box
ax.text(positions[i][0], positions[i][1], textstr,
transform=ax.transAxes, fontsize=12,
verticalalignment=alignments[i][0],
horizontalalignment=alignments[i][1],
bbox=box_props)
plt.tight_layout()
plt.show()
这段代码创建了一个 2x2 的直方图网格,每个直方图的不同角落都有一个文本框。
理解文本框的定位
有几个关键参数可以控制文本框的定位:
- 位置坐标:
(x, y)坐标决定了文本框的放置位置。当使用transform=ax.transAxes时,这些坐标是坐标轴坐标,其中(0, 0)是左下角,(1, 1)是右上角。 - 垂直对齐方式:
verticalalignment参数控制文本相对于 y 坐标的垂直对齐方式:'top':文本的顶部位于指定的 y 坐标处。'center':文本的中心位于指定的 y 坐标处。'bottom':文本的底部位于指定的 y 坐标处。
- 水平对齐方式:
horizontalalignment参数控制文本相对于 x 坐标的水平对齐方式:'left':文本的左边缘位于指定的 x 坐标处。'center':文本的中心位于指定的 x 坐标处。'right':文本的右边缘位于指定的 x 坐标处。
这些对齐选项在将文本放置在角落时尤为重要。例如,在右上角,你需要使用 horizontalalignment='right',这样文本的右边缘才能与绘图的右边缘对齐。
创建包含多个文本元素的最终可视化图表
在这最后一步,我们将结合所学的所有知识,创建一个包含多种不同样式文本元素的综合可视化图表。这将展示如何使用文本框来增强数据故事性。
创建高级可视化图表
让我们创建一个更复杂的图表,其中既包含我们的直方图,又包含一些额外的视觉元素。在一个新的单元格中,输入并运行以下代码:
## Create a figure with a larger size for our final visualization
fig, ax = plt.subplots(figsize=(12, 8))
## Plot the histogram with more bins and a different color
n, bins, patches = ax.hist(x, bins=75, color='lightblue',
edgecolor='darkblue', alpha=0.7)
## Add title and labels with improved styling
ax.set_title('Distribution of Random Data with Statistical Annotations',
fontsize=18, fontweight='bold', pad=20)
ax.set_xlabel('Value', fontsize=14)
ax.set_ylabel('Frequency', fontsize=14)
## Add grid for better readability
ax.grid(True, linestyle='--', alpha=0.7)
## Mark the mean with a vertical line
ax.axvline(x=mu, color='red', linestyle='-', linewidth=2,
label=f'Mean: {mu:.2f}')
## Mark one standard deviation range
ax.axvline(x=mu + sigma, color='green', linestyle='--', linewidth=1.5,
label=f'Mean + 1σ: {mu+sigma:.2f}')
ax.axvline(x=mu - sigma, color='green', linestyle='--', linewidth=1.5,
label=f'Mean - 1σ: {mu-sigma:.2f}')
## Create a text box with statistics in the top left
stats_box_props = dict(boxstyle='round', facecolor='lightyellow',
alpha=0.8, edgecolor='gold', linewidth=2)
stats_text = '\n'.join((
r'$\mathbf{Statistics:}$',
r'$\mu=%.2f$ (mean)' % (mu,),
r'$\mathrm{median}=%.2f$' % (median,),
r'$\sigma=%.2f$ (std. dev.)' % (sigma,)
))
ax.text(0.05, 0.95, stats_text, transform=ax.transAxes, fontsize=14,
verticalalignment='top', bbox=stats_box_props)
## Add an informational text box in the top right
info_box_props = dict(boxstyle='round4', facecolor='lightcyan',
alpha=0.8, edgecolor='deepskyblue', linewidth=2)
info_text = '\n'.join((
r'$\mathbf{About\ Normal\ Distributions:}$',
r'$\bullet\ 68\%\ of\ data\ within\ 1\sigma$',
r'$\bullet\ 95\%\ of\ data\ within\ 2\sigma$',
r'$\bullet\ 99.7\%\ of\ data\ within\ 3\sigma$'
))
ax.text(0.95, 0.95, info_text, transform=ax.transAxes, fontsize=14,
verticalalignment='top', horizontalalignment='right',
bbox=info_box_props)
## Add a legend
ax.legend(fontsize=12)
## Tighten the layout and show the plot
plt.tight_layout()
plt.show()
当你运行这个单元格时,你会看到一个综合可视化图表,其中包含:
- 经过样式优化的数据直方图
- 标记均值和一个标准差范围的垂直线
- 左上角的统计信息文本框
- 右上角关于正态分布的信息文本框
- 解释垂直线含义的图例
理解高级元素
让我们来分析一下我们添加的一些新元素:
- 使用
axvline()绘制垂直线:- 这些线直接在图表上标记重要的统计数据。
label参数可将这些线包含在图例中。
- 多种不同样式的文本框:
- 每个文本框都有不同的用途,并使用独特的样式。
- 统计信息框显示我们从数据中计算出的值。
- 信息框提供关于正态分布的背景信息。
- 增强的格式设置:
- 使用 LaTeX 格式通过
\mathbf{}创建粗体文本。 - 使用
\bullet创建项目符号。 - 使用
\(反斜杠后接一个空格)控制间距。
- 使用 LaTeX 格式通过
- 网格和图例:
- 网格帮助查看者更准确地读取图表中的数值。
- 图例解释彩色线条的含义。
关于文本框放置的最终提示
在可视化图表中放置多个文本元素时,请考虑以下几点:
- 视觉层次:最重要的信息应该最突出。
- 位置:将相关信息放置在可视化图表的相关部分附近。
- 对比度:确保文本在其背景下易于阅读。
- 一致性:对相似类型的信息使用一致的样式。
- 避免杂乱:避免在可视化图表中放置过多的文本元素。
通过精心放置和设置文本框的样式,你可以创建既信息丰富又美观的可视化图表,引导查看者理解数据中的关键见解。
总结
在本次实验中,你学习了如何在 Matplotlib 中有效使用文本框来增强数据可视化效果。让我们回顾一下要点:
涵盖的关键概念
- 创建基本文本框:你学习了如何使用
matplotlib.pyplot.text()函数和bbox参数向绘图中添加文本框。 - 文本框定位:你了解了如何使用
transform=ax.transAxes通过坐标轴坐标来定位文本框,这样无论数据如何缩放,文本都能保持固定位置。 - 文本框样式设置:你探索了如何使用不同的样式(
boxstyle)、颜色(facecolor)、透明度级别(alpha)和边框属性来自定义文本框。 - 文本对齐:你练习了使用
verticalalignment和horizontalalignment来在可视化的不同部分正确定位文本。 - LaTeX 格式:你使用 LaTeX 符号为文本添加数学符号和格式。
- 综合可视化:你创建了一个完整的可视化图表,结合了多种不同样式的文本元素,以讲述一个连贯的数据故事。
实际应用
你在本次实验中学到的技术可以应用于:
- 为绘图添加统计摘要
- 标记数据中的关键特征
- 在可视化中提供背景信息或解释
- 创建具有自定义格式的图例或说明
- 突出重要的发现或见解
下一步计划
为了进一步提升你使用 Matplotlib 进行数据可视化的技能,可以考虑探索以下内容:
- 高级注释技术,如箭头和注释框
- 使用 Matplotlib 的事件处理创建交互式文本元素
- 使用不同的字体和样式自定义文本
- 创建带有协调注释的子图
- 保存包含文本元素的可视化图表以供发表
通过掌握 Matplotlib 中文本注释的技巧,你可以创建更具信息性和专业性的数据可视化图表,有效地向受众传达你的见解。