
介绍
欢迎来到 Python 数据分析的世界!在本实验中,你将接触到 Pandas,这是 Python 中最流行、最强大的开源数据处理和分析库。
在开始本课程之前,你应该具备基本的 Python 编程技能,并确保 Python 已正确配置在你的系统 PATH 中。如果你还没有学习 Python,可以从我们的 Python 学习路径 开始。此外,你应该已安装 NumPy,因为它是 Pandas 操作的重要先决条件。如果你需要学习 NumPy,可以探索我们的 NumPy 学习路径。
Pandas 提供了高性能、易于使用的数据结构和数据分析工具。Pandas 的两个主要数据结构是 Series(一维)和 DataFrame(二维)。
在本实验中,你将学习入门所需的基础知识。你将:
- 验证你的环境中是否已安装 Pandas。
- 将 Pandas 库导入 Python 脚本。
- 创建你的第一个 Pandas
Series对象。 - 访问
Series中的数据。 - 检查
Series的基本属性。
本实验专为初学者设计,无需任何 Pandas 预备知识。让我们开始吧!
使用 pip 安装 Pandas
在此步骤中,我们将验证 pandas 是否已在环境中正确安装。LabEx 环境预装了 Python 和 Pandas,以节省你的时间。你可以确认这一点并检查其版本。
要查看已安装的 Python 包的详细信息,你可以使用 pip show 命令。pip 是 Python 的包安装程序。
打开终端并运行以下命令,以显示已安装的 pandas 包的信息:
pip show pandas
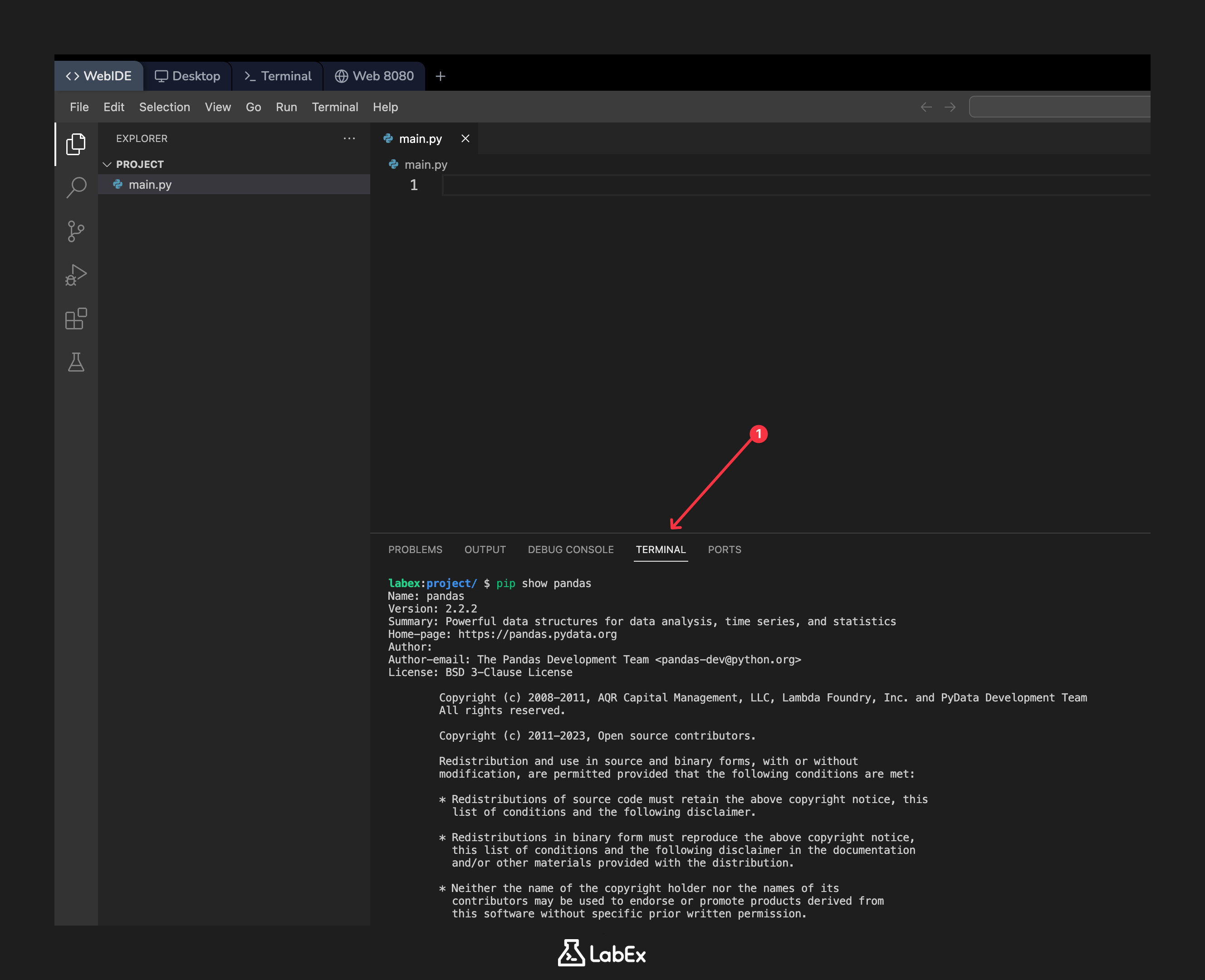
你应该会看到一个输出,详细说明了包的名称、版本、摘要和位置。版本应为 2.2.2 或类似版本。
Name: pandas
Version: 2.2.2
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author: The Pandas Development Team
Author-email: pandas-dev@python.org
License: BSD-3-Clause
Location: /usr/local/lib/python3.10/dist-packages
Requires: numpy, python-dateutil, pytz, tzdata
Required-by:
这证实 pandas 已准备好在你的 Python 脚本中使用。
导入 Pandas 并别名为 pd
在此步骤中,你将编写第一行 Python 代码来导入 Pandas 库。按照惯例,Pandas 通常使用别名 pd 进行导入。这使得代码更简洁、更易读。
在 WebIDE 的左侧文件浏览器中,你会看到一个名为 main.py 的文件。这个文件已经为你创建好了。点击它在编辑器中打开。
现在,将以下代码添加到 main.py 中,以导入 pandas 并打印一条确认消息:
import pandas as pd
print("Pandas imported successfully!")
import pandas as pd: 这行代码告诉 Python 加载 Pandas 库并为其指定别名pd。从现在开始,你可以使用pd.来访问 Pandas 的函数和对象。print(...): 这是一个标准的 Python 函数,用于将输出显示到终端。
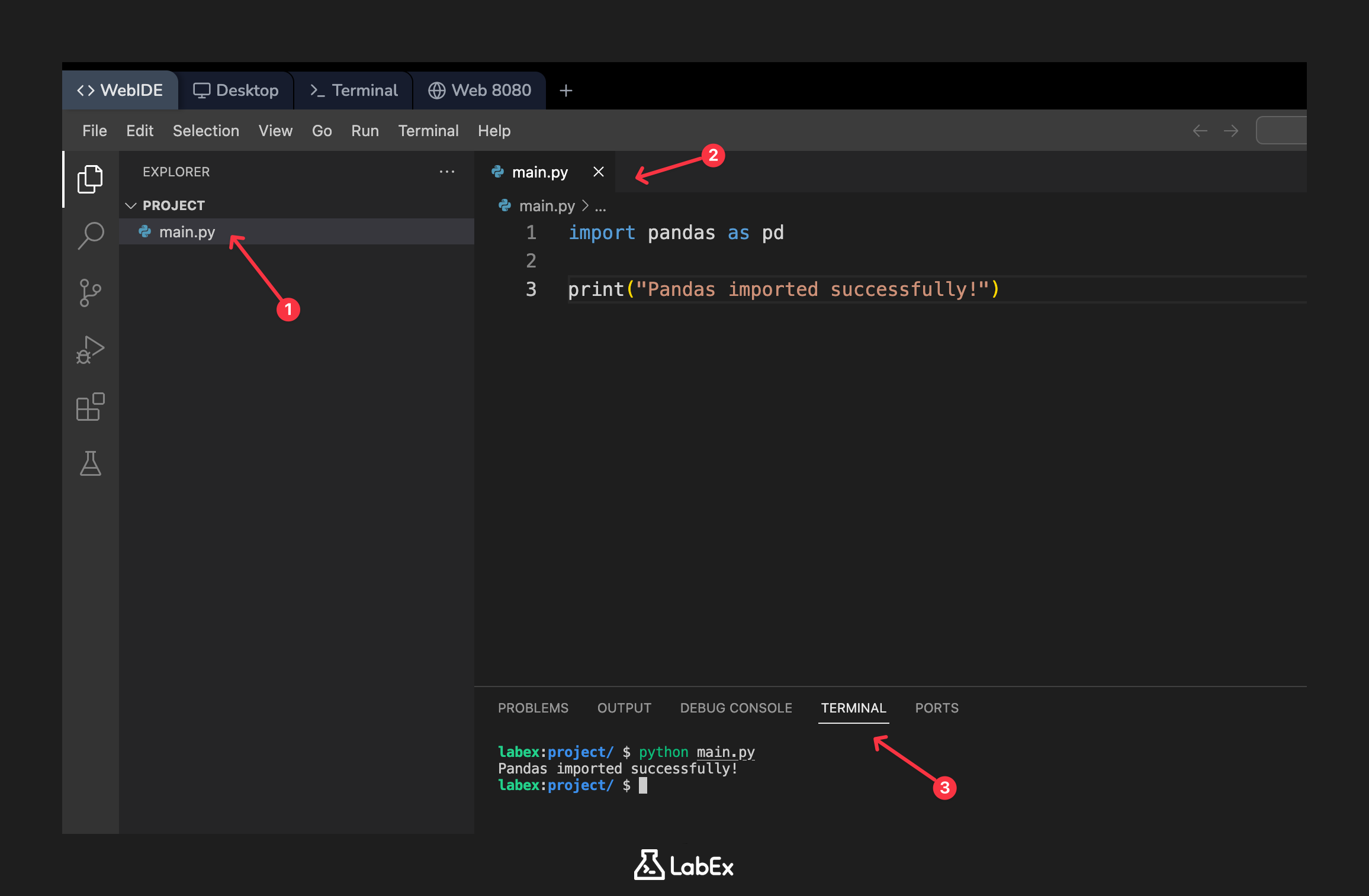
要运行你的脚本,请转到终端并执行以下命令:
python main.py
你应该会在终端看到确认消息被打印出来:
Pandas imported successfully!
这证实了你的 Python 脚本可以成功导入并使用 Pandas 库。
从列表创建简单的 Series
在此步骤中,你将创建你的第一个 Pandas Series。Series 是一个一维的类数组对象,可以容纳任何数据类型,例如整数、字符串或浮点数。它是 Pandas 中数据构建的基本单元。
你可以通过将 Python 列表传递给 pd.Series() 构造函数来创建 Series。
修改你的 main.py 文件。用以下代码替换之前的 print 语句,以创建并打印一个 Series:
import pandas as pd
## A Python list of numbers
data = [10, 20, 30, 40, 50]
## Create a Pandas Series from the list
s = pd.Series(data)
## Print the Series
print(s)
建议: 你可以将上面的代码复制到你的代码编辑器中,然后仔细阅读每一行代码以理解其功能。如果你需要进一步的解释,可以点击“解释代码”按钮 👆。你可以与 Labby 互动以获得个性化帮助。
data = [...]: 我们首先定义一个简单的整数 Python 列表。s = pd.Series(data): 我们调用pd(Pandas) 库中的Series构造函数,并将我们的列表传递给它。这将创建一个Series对象。
现在,再次从终端运行脚本:
python main.py
输出将显示你的 Series。请注意,它有两列:左侧是索引(0-4),右侧是值(10-50)。如果未指定索引,Pandas 会自动创建一个默认的整数索引。
0 10
1 20
2 30
3 40
4 50
dtype: int64
通过索引访问 Series 中的元素
在此步骤中,你将学习如何访问你创建的 Series 中的单个元素或元素子集。访问数据是数据分析中的一项基本操作。你可以使用索引来访问 Series 中的元素,这与访问 Python 列表类似。
让我们修改 main.py 来访问并打印特定的元素。我们将访问第一个元素(索引为 0)以及一个元素切片。
用以下代码更新你的 main.py 文件。在打印整个 Series 的那一行之后,添加新的 print 语句。
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
print("The full Series:")
print(s)
## Access the first element (at index 0)
print("\nFirst element:", s[0])
## Access a slice of elements (from index 1 up to, but not including, 3)
print("\nElements from index 1 to 2:")
print(s[1:3])
s[0]: 这会检索索引为0的值,即10。s[1:3]: 这被称为切片(slicing)。它会检索从索引1开始到索引3(不包含3)结束的元素。这将得到索引为1和2的元素。
运行脚本以查看结果:
python main.py
你的输出现在应该显示完整的 Series,然后是你访问的特定元素。
The full Series:
0 10
1 20
2 30
3 40
4 50
dtype: int64
First element: 10
Elements from index 1 to 2:
1 20
2 30
dtype: int64
打印 Series 的数据类型和形状
在此步骤中,你将学习如何检查 Series 的两个重要属性:其数据类型(dtype)和形状(shape)。理解这些属性对于调试和数据验证至关重要。
dtype: 此属性告诉你Series中存储的值的数据类型(例如,整数为int64,浮点数为float64,字符串为object)。shape: 此属性返回一个表示Series维度的元组。对于一维的Series,它将是一个包含单个值的元组(n,),其中n是元素的数量。
让我们更新 main.py 来打印这两个属性。将以下行添加到你的脚本末尾:
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
## ... (之前的 print 语句可以移除或保留)
## Print the data type of the Series
print("\nData type:", s.dtype)
## Print the shape of the Series
print("Shape:", s.shape)
现在,最后一次运行脚本:
python main.py
输出现在将包含你的 Series 的数据类型和形状。
Data type: int64
Shape: (5,)
这表明你的 Series 包含 64 位整数,并且有 5 个元素。
总结
恭喜!你已成功完成了这个关于 Pandas 的入门实验。
在这个实验中,你学习了使用这个强大库的基本第一步。你已:
- 验证了环境中
pandas的安装。 - 使用标准的别名
pd将pandas库导入到 Python 脚本中。 - 从 Python 列表中创建了一个基本的一维
Series。 - 使用索引和切片访问了
Series中的元素。 - 检查了
dtype和shape属性,以了解Series的结构和数据类型。
这些是你继续学习更复杂的数据结构(如 DataFrame)和执行更高级数据分析任务所需的基本构建块。请继续练习!


