
介绍
在本实验中,你将学习 MySQL 索引和性能优化技术。本实验侧重于创建和管理索引以提高数据库查询性能。
你将首先创建一个 users 表并插入示例数据。然后,你将在 username 列上创建一个单列索引,并学习如何验证其创建。本实验还将涵盖使用 EXPLAIN 分析查询计划、为多列查询添加复合索引以及删除未使用的索引以维护数据库效率。
在表上创建单列索引
在本步骤中,你将学习如何在 MySQL 中创建单列索引。索引对于提高数据库查询性能至关重要,尤其是在处理大型表时。对列创建索引可以使数据库快速定位匹配该列特定值的行,而无需扫描整个表。
理解索引
将索引想象成书中的目录。你无需阅读整本书来查找特定主题,而是可以使用目录快速找到相关页面。同样,数据库索引可以帮助数据库引擎快速查找特定行。
创建表
首先,让我们创建一个名为 users 的简单表来演示索引的创建。在 LabEx VM 中打开一个终端。你可以使用桌面上的 Xfce Terminal 快捷方式。
以 root 用户连接到 MySQL 服务器:
sudo mysql -u root
首先,为本实验创建一个数据库并选择它:
CREATE DATABASE lab_db;
USE lab_db;
现在,创建 users 表:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
此 SQL 语句创建了一个名为 users 的表,其中包含 id、username、email 和 created_at 列。id 列被设置为主键并自动递增。
让我们向 users 表插入一些示例数据:
INSERT INTO users (username, email) VALUES
('john_doe', 'john.doe@example.com'),
('jane_smith', 'jane.smith@example.com'),
('peter_jones', 'peter.jones@example.com');
创建单列索引
现在,让我们在 username 列上创建一个索引。这将有助于加快按用户名搜索用户的查询速度。
CREATE INDEX idx_username ON users (username);
此语句在 users 表的 username 列上创建了一个名为 idx_username 的索引。
验证索引
你可以使用 SHOW INDEXES 命令来验证索引是否已创建:
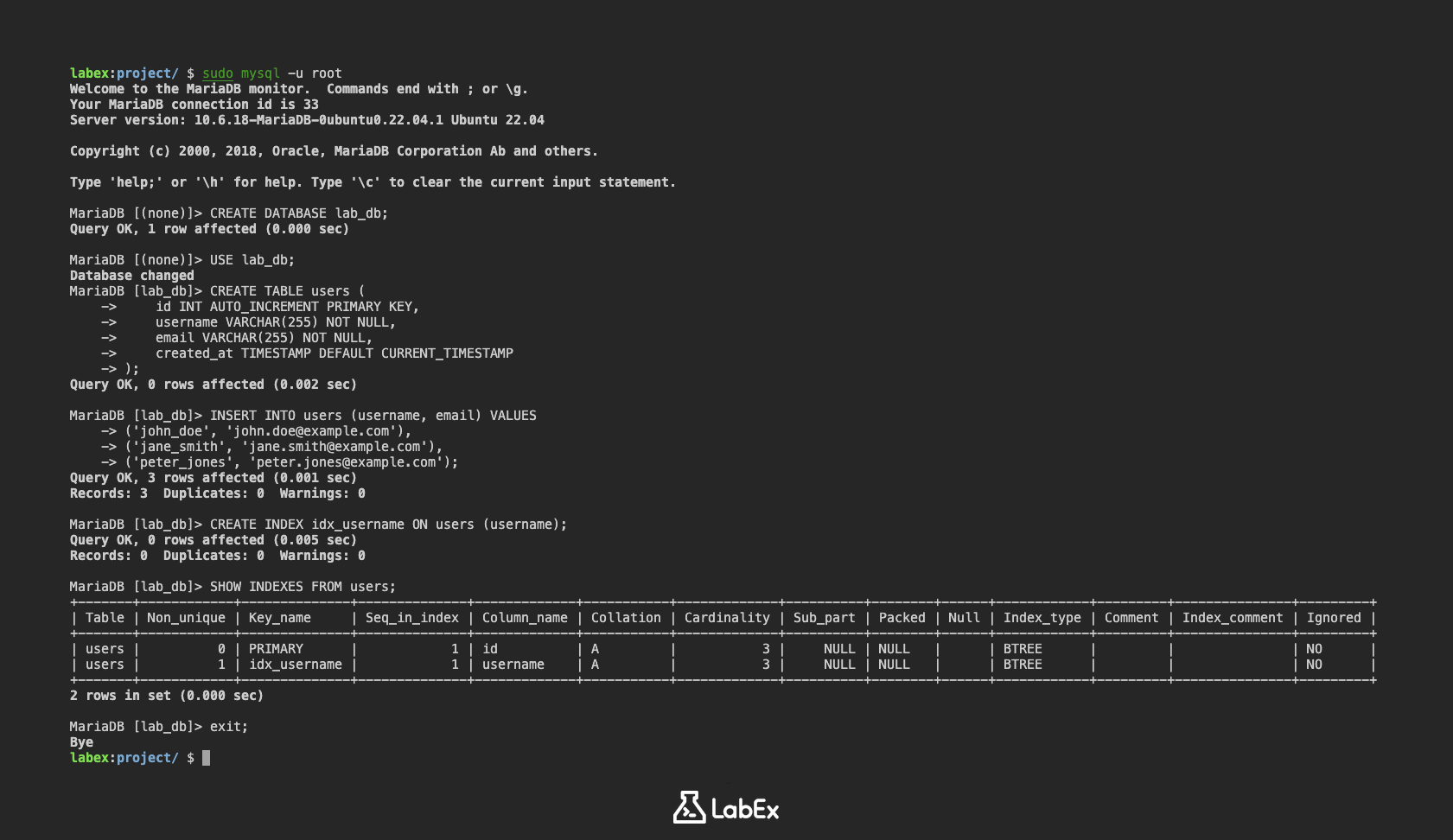
SHOW INDEXES FROM users;
输出将显示 users 表上索引的详细信息,包括你刚刚创建的 idx_username 索引。你应该看到一行,其中 Key_name 是 idx_username,Column_name 是 username。
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 3 | NULL | NULL | | BTREE | | | NO |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
你现在已成功在表上创建了单列索引。这将提高基于索引列过滤数据的查询的性能。
使用 EXPLAIN 分析查询计划
在本步骤中,你将学习如何使用 MySQL 中的 EXPLAIN 语句来分析查询执行计划。理解查询计划对于识别性能瓶颈和优化查询至关重要。
什么是查询计划?
查询计划是数据库引擎用于执行查询的路线图。它描述了访问表的顺序、使用的索引以及用于检索数据的算法。通过分析查询计划,你可以了解数据库是如何执行你的查询的,并找出需要改进的地方。
使用 EXPLAIN 语句
EXPLAIN 语句提供有关 MySQL 如何执行查询的信息。它显示涉及的表、使用的索引、连接顺序以及其他可以帮助你理解查询性能的详细信息。
现在,让我们使用 EXPLAIN 来分析一个简单的查询。
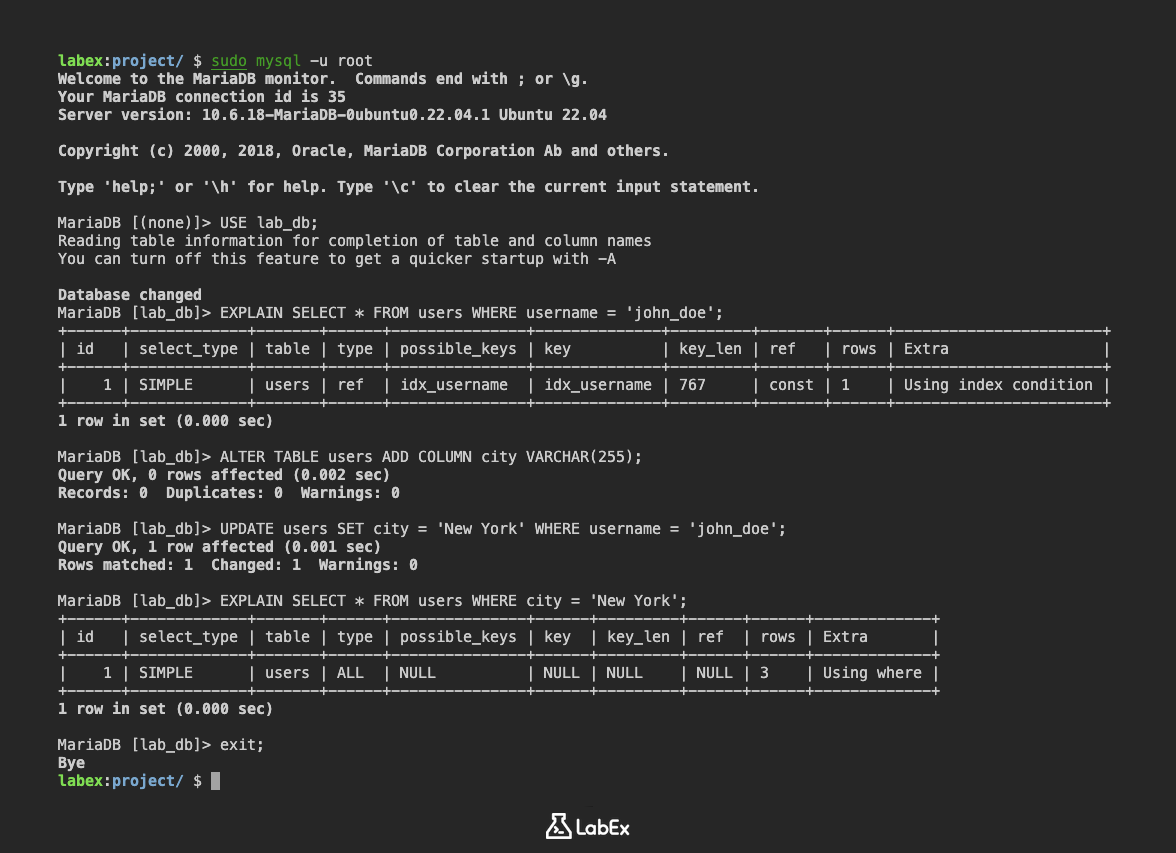
EXPLAIN SELECT * FROM users WHERE username = 'john_doe';
EXPLAIN 语句的输出将是一个包含多个列的表。以下是一些最重要的列的细分:
id: SELECT 语句的 ID。select_type: SELECT 查询的类型(例如,SIMPLE、PRIMARY、SUBQUERY)。table: 正在访问的表。type: 连接类型。这是最重要的列之一。常见值包括:system: 表只有一行。const: 表最多有一行匹配,该行在查询开始时读取。eq_ref: 对于来自前一个表的每一行组合,从该表中读取一行。当在索引列上进行连接时使用。ref: 对于来自前一个表的每一行组合,从该表中读取所有匹配的行。当在索引列上进行连接时使用。range: 只检索给定范围内的行,使用索引。index: 执行完整的索引扫描。ALL: 执行完整的表扫描。这是效率最低的类型。
possible_keys: MySQL 可能用于在表中查找行的索引。key: MySQL 实际使用的索引。key_len: MySQL 使用的键的长度。ref: 与索引进行比较的列或常量。rows: MySQL 估计执行查询需要检查的行数。Extra: 关于 MySQL 如何执行查询的附加信息。常见值包括:Using index: 查询可以使用索引来满足。Using where: MySQL 需要在访问表后过滤行。Using temporary: MySQL 需要创建一个临时表来执行查询。Using filesort: MySQL 需要在访问表后对行进行排序。
解释 EXPLAIN 输出
对于查询 SELECT * FROM users WHERE username = 'john_doe',EXPLAIN 的输出应如下所示:
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | users | ref | idx_username | idx_username | 767 | const | 1 | Using index condition |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
在此示例中:
type为ref,这意味着 MySQL 正在使用索引来查找匹配的行。possible_keys和key都显示为idx_username,这意味着 MySQL 正在使用我们在上一步中创建的idx_username索引。rows为1,这意味着 MySQL 估计执行查询只需检查一行。
分析没有索引的查询
现在,让我们分析一个不使用索引的查询。首先,让我们向 users 表添加一个名为 city 的新列:
ALTER TABLE users ADD COLUMN city VARCHAR(255);
现在,让我们对按 city 搜索的查询运行 EXPLAIN。由于我们尚未向 city 列添加任何数据,让我们更新其中一行:
UPDATE users SET city = 'New York' WHERE username = 'john_doe';
现在,再次运行 EXPLAIN 语句:
EXPLAIN SELECT * FROM users WHERE city = 'New York';
输出可能如下所示:
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
在此示例中:
type为ALL,这意味着 MySQL 正在执行完整的表扫描。possible_keys和key均为NULL,这意味着 MySQL 未使用任何索引。rows为3,这意味着 MySQL 估计执行查询需要检查表中的所有 3 行。Extra显示Using where,这意味着 MySQL 需要在访问表后过滤行。
这表明该查询未优化,并且可以从 city 列上的索引中受益。
为多列查询添加复合索引
在本步骤中,你将学习如何在 MySQL 中创建复合索引。复合索引是表上两个或多个列的索引。它可以显著提高基于多列过滤数据的查询的性能。
什么是复合索引?
复合索引是涵盖多个列的索引。当查询在 WHERE 子句中频繁使用多个列时,它会很有用。复合索引中列的顺序很重要。当查询的 WHERE 子句中以相同的顺序指定列时,索引最有效。
让我们向 users 表添加更多数据,包括不同的城市:
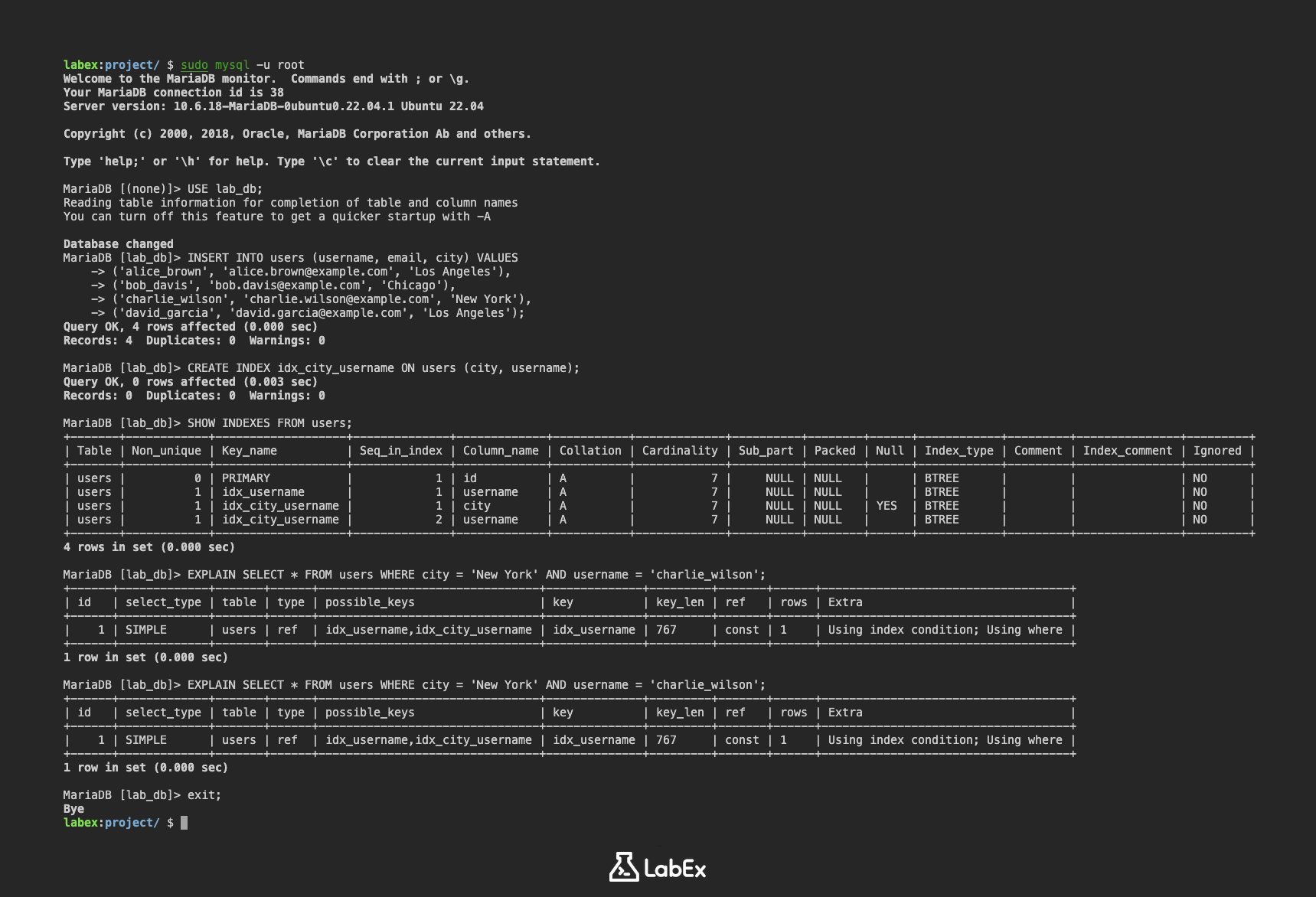
INSERT INTO users (username, email, city) VALUES
('alice_brown', 'alice.brown@example.com', 'Los Angeles'),
('bob_davis', 'bob.davis@example.com', 'Chicago'),
('charlie_wilson', 'charlie.wilson@example.com', 'New York'),
('david_garcia', 'david.garcia@example.com', 'Los Angeles');
创建复合索引
假设你经常运行按 city 和 username 过滤用户的查询。在这种情况下,你可以在 city 和 username 列上创建复合索引。
CREATE INDEX idx_city_username ON users (city, username);
此语句在 users 表的 city 和 username 列上创建了一个名为 idx_city_username 的索引。
验证索引
你可以使用 SHOW INDEXES 命令来验证索引是否已创建:
SHOW INDEXES FROM users;
输出将显示 users 表上索引的详细信息,包括你刚刚创建的 idx_city_username 索引。你应该看到 idx_city_username 的两行,一行是 city 列,另一行是 username 列。
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
使用复合索引
要查看复合索引的优势,你可以使用 EXPLAIN 命令来分析在 WHERE 子句中使用 city 和 username 列的查询。
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
EXPLAIN 输出将显示查询正在使用 idx_city_username 索引,这意味着数据库可以快速找到匹配的行,而无需扫描整个表。在输出中查找 possible_keys 和 key 列。如果正在使用索引,你将在这些列中看到 idx_city_username。
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | users | ref | idx_username,idx_city_username | idx_username | 767 | const | 1 | Using index condition; Using where |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
索引中的列顺序
复合索引中列的顺序很重要。如果你创建的索引是 (username, city) 而不是 (city, username),那么对于先按 city 再按 username 过滤的查询,该索引的效率会降低。
例如,如果我们有一个索引 (username, city) 并运行以下查询:
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
MySQL 可能不会使用该索引,或者可能只部分使用它,因为 city 列不是索引中的前导列。
删除未使用的索引
在本步骤中,你将学习如何在 MySQL 中删除未使用的索引。虽然索引可以显著提高查询性能,但它们也会增加写操作(插入、更新和删除)的开销。因此,识别并删除不再使用的索引非常重要。
为什么要删除未使用的索引?
未使用的索引会占用磁盘空间并可能减慢写操作的速度。当表中的数据被修改时,数据库引擎还必须更新该表上的所有索引。如果索引未被任何查询使用,它只会增加不必要的开销。
在前面的步骤中,我们在 username 列上创建了一个名为 idx_username 的索引。假设在分析你的查询模式后,你确定不再使用此索引。
删除索引
要删除 idx_username 索引,你可以使用 DROP INDEX 语句:
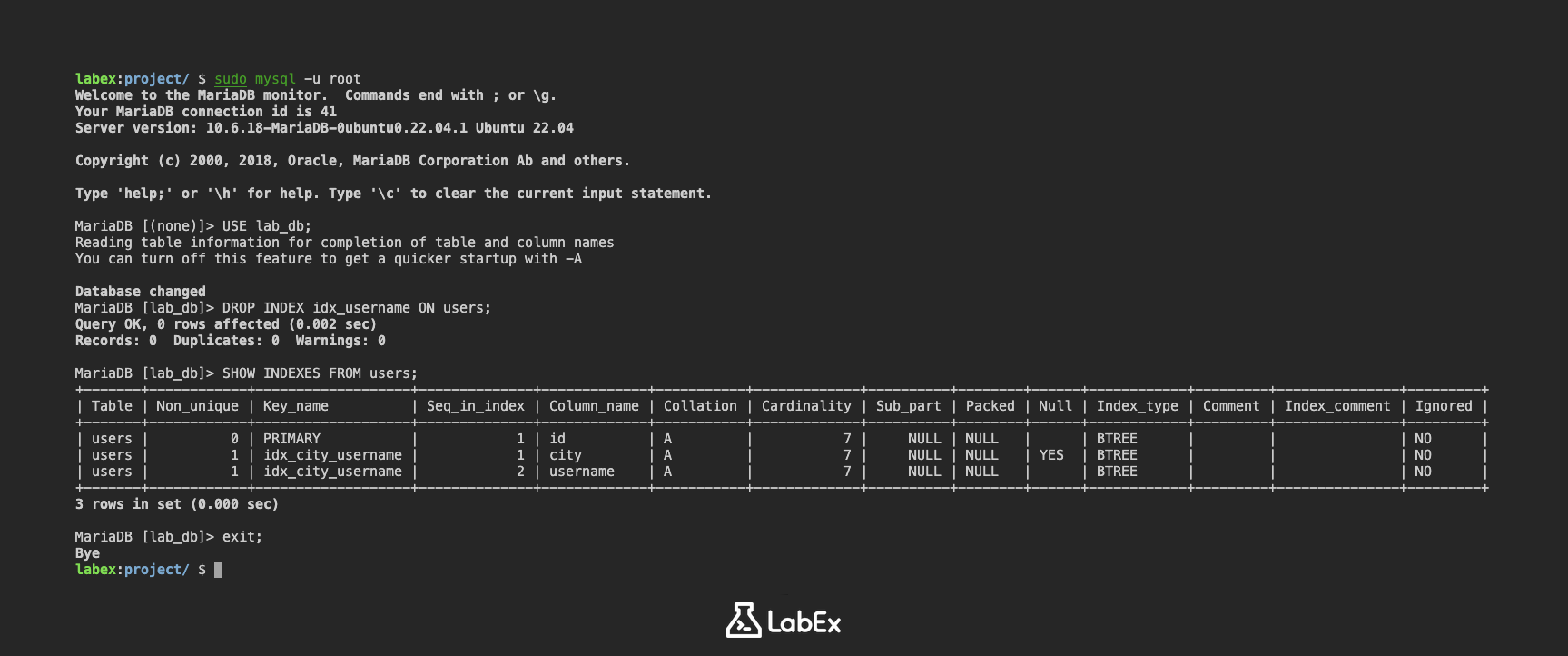
DROP INDEX idx_username ON users;
此语句从 users 表中删除 idx_username 索引。
验证索引删除
你可以使用 SHOW INDEXES 命令来验证索引是否已被删除:
SHOW INDEXES FROM users;
输出将显示 users 表上索引的详细信息。你不应该再在输出中看到 idx_username 索引。
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
识别未使用的索引
在实际场景中,识别未使用的索引可能具有挑战性。MySQL 提供了多种工具和技术来帮助你完成此任务:
- MySQL Enterprise Audit: 此功能允许你记录服务器上执行的所有查询。然后,你可以分析查询日志来确定正在使用哪些索引。
- Performance Schema: Performance Schema 提供了有关服务器性能的详细信息,包括索引使用情况。
- 第三方工具: 多个第三方工具可以帮助你监控索引使用情况并识别未使用的索引。
通过定期监控你的索引使用情况并删除未使用的索引,你可以提高数据库的整体性能。
现在我们已经完成了所有步骤,让我们退出 MySQL 控制台:
exit;
总结
在本实验中,你学习了如何在 MySQL 中创建单列索引以提高查询性能。你还学习了如何使用 EXPLAIN 语句来分析查询执行计划并识别性能瓶颈。此外,你还练习了为多列查询创建复合索引以及删除未使用的索引以保持数据库效率。有效理解和利用索引是优化数据库性能的一项基本技能。


