
Введение
В этой лабораторной работе вы изучите основы создания модели машинного обучения с использованием одной из самых популярных библиотек Python — scikit-learn. Мы сосредоточимся на линейной регрессии — базовом, но мощном алгоритме, который используется для прогнозирования непрерывных значений, таких как цена или температура.
Наша цель — создать модель, способную предсказывать медианную стоимость жилья в районах Калифорнии. Мы будем использовать набор данных California housing, который удобно встроен в scikit-learn.
В ходе этой работы вы научитесь:
- Загружать набор данных из
scikit-learn. - Подготавливать и разделять данные на обучающую и тестовую выборки.
- Создавать и обучать модель линейной регрессии.
- Использовать обученную модель для получения прогнозов.
- Визуализировать результаты для оценки эффективности модели.
Все задачи вы будете выполнять в WebIDE. Приступим!
Загрузка набора данных о жилье в Калифорнии с помощью datasets.fetch_california_housing()
На этом этапе мы начнем с загрузки набора данных для нашей модели. В scikit-learn есть несколько встроенных наборов данных, которые отлично подходят для обучения и практики. Мы воспользуемся набором данных о жилье в Калифорнии.
Сначала нужно создать Python-скрипт. Файл с именем main.py уже создан для вас в директории ~/project. Вы можете найти его в файловом менеджере слева в WebIDE.
Откройте main.py и добавьте в него следующий код. Этот код импортирует необходимые библиотеки (fetch_california_housing из sklearn.datasets и pandas) и загружает данные. Мы будем использовать pandas для преобразования данных в DataFrame — табличную структуру, которую удобно просматривать и обрабатывать.
Добавьте следующий код в main.py:
import pandas as pd
from sklearn.datasets import fetch_california_housing
## Load the California housing dataset
california = fetch_california_housing()
## Create a DataFrame
california_df = pd.DataFrame(california.data, columns=california.feature_names)
california_df['MedHouseVal'] = california.target
## Print the first 5 rows of the DataFrame
print("California Housing Dataset:")
print(california_df.head())
Теперь запустим скрипт, чтобы увидеть результат. Откройте терминал в WebIDE (используйте меню "Terminal" -> "New Terminal") и выполните следующую команду:
python3 main.py
Вы должны увидеть первые пять строк набора данных в консоли. Столбец MedHouseVal — это наша целевая переменная, представляющая медианную стоимость жилья в районах Калифорнии, выраженную в сотнях тысяч долларов ($100,000).
California Housing Dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
Разделение данных на обучающую и тестовую выборки с помощью train_test_split из sklearn.model_selection
На этом этапе мы подготовим данные для процесса обучения. Важнейшая часть машинного обучения — оценка модели на данных, которые она раньше не видела. Для этого мы разделяем наш набор данных на две части: обучающую выборку (training set) и тестовую выборку (testing set). Модель будет учиться на обучающей выборке, а мы будем использовать тестовую, чтобы проверить, насколько хорошо она работает.
Сначала нужно отделить наши признаки (входные переменные, X) от целевой переменной (значение, которое мы хотим предсказать, y). В нашем случае X — это все столбцы, кроме MedHouseVal, а y — это столбец MedHouseVal.
Затем мы воспользуемся функцией train_test_split из модуля sklearn.model_selection для выполнения разделения.
Добавьте следующий код в ваш файл main.py:
from sklearn.model_selection import train_test_split
## Prepare the data
X = california_df.drop('MedHouseVal', axis=1) ## Features (input variables)
y = california_df['MedHouseVal'] ## Target variable (what we want to predict)
## Split the data into training and testing sets
## test_size=0.2: Reserve 20% of data for testing, 80% for training
## random_state=42: Ensures reproducible splits (same result every run)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
## Print the shapes of the new datasets to confirm the split
print("\n--- Data Split ---")
print("X_train shape:", X_train.shape) ## Training features
print("X_test shape:", X_test.shape) ## Test features
print("y_train shape:", y_train.shape) ## Training target values
print("y_test shape:", y_test.shape) ## Test target values
Теперь снова запустите скрипт из терминала:
python3 main.py
Вы увидите размеры созданных обучающих и тестовых выборок, выведенные после DataFrame. Это подтверждает, что данные были разделены правильно.
--- Data Split ---
X_train shape: (16512, 8)
X_test shape: (4128, 8)
y_train shape: (16512,)
y_test shape: (4128,)
Инициализация модели LinearRegression из sklearn.linear_model
На этом этапе мы создадим нашу модель линейной регрессии. scikit-learn делает это невероятно просто. Нам нужно лишь импортировать класс LinearRegression из модуля sklearn.linear_model и создать его экземпляр.
Этот экземпляр — объект, содержащий алгоритм линейной регрессии. Линейная регрессия находит линию наилучшего соответствия через точки данных, используя формулу: y = mx + b, где m — коэффициенты (веса) для каждого признака, а b — свободный член (intercept). Здесь мы используем параметры по умолчанию, которые хорошо подходят для большинства базовых случаев.
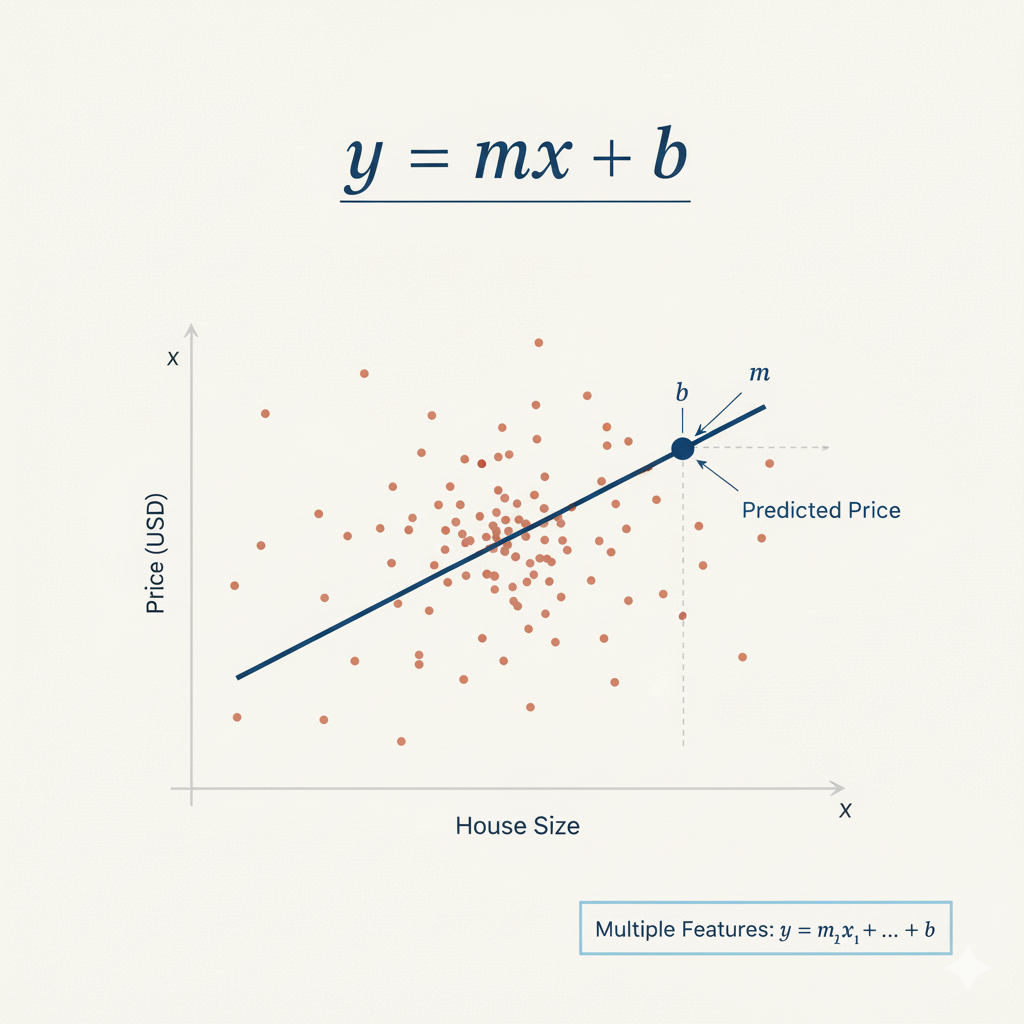 Рисунок 1: Формула линейной регрессии y = mx + b, где m — наклон, а b — свободный член
Рисунок 1: Формула линейной регрессии y = mx + b, где m — наклон, а b — свободный член
Добавьте следующий код в ваш файл main.py. Это импортирует класс LinearRegression и создаст объект модели.
from sklearn.linear_model import LinearRegression
## Initialize the Linear Regression model
model = LinearRegression()
## Print the model to confirm it's created
print("\n--- Model Initialized ---")
print(model)
Снова запустите скрипт main.py из терминала:
python3 main.py
Теперь вывод будет включать строку с объектом LinearRegression. Это подтверждает, что модель успешно инициализирована.
--- Model Initialized ---
LinearRegression()
Обучение модели с помощью model.fit(X_train, y_train)
На этом этапе мы обучим нашу модель. Этот процесс часто называют "подгонкой" (fitting) модели к данным. Во время обучения модель изучает взаимосвязи между признаками (X_train) и целевой переменной (y_train). Для линейной регрессии это означает поиск оптимальных коэффициентов для каждого признака, чтобы максимально точно предсказать целевое значение.
Мы воспользуемся методом fit() нашего объекта модели, передав в качестве аргументов наши обучающие данные.
Добавьте следующий код в ваш файл main.py:
## Fit (train) the model on the training data
## The fit() method learns the relationship between features (X_train) and target (y_train)
## It calculates optimal coefficients for each feature and the intercept using least squares optimization
model.fit(X_train, y_train)
## After fitting, the model has learned the coefficients and intercept.
## The intercept represents the predicted value when all features are zero
print("\n--- Model Trained ---")
print("Intercept:", model.intercept_)
Теперь выполните скрипт из терминала:
python3 main.py
После выполнения скрипта вы увидите новый раздел в выводе, показывающий свободный член (intercept) модели линейной регрессии. Свободный член — это значение прогноза, когда все признаки равны нулю. Появление числового значения здесь подтверждает, что модель успешно обучена на данных.
--- Model Trained ---
Intercept: -37.023277706064185
Прогнозирование на тестовых данных с помощью model.predict(X_test)
На этом заключительном этапе мы используем нашу обученную модель для получения прогнозов. Это конечная цель создания прогностической модели. Мы будем использовать тестовые данные (X_test), которые модель не видела во время обучения, чтобы оценить её эффективность.
Мы воспользуемся методом predict() нашего объекта обученной модели, передав тестовые признаки (X_test) в качестве аргумента. Метод вернет массив прогнозируемых значений для целевой переменной.
Добавьте следующий код в ваш файл main.py:
## Make predictions on the test data
## The predict() method uses the learned coefficients and intercept to calculate predictions
## Formula: prediction = intercept + (coeff1 * feature1) + (coeff2 * feature2) + ...
predictions = model.predict(X_test)
## Print the first 5 predictions (values are in $100,000 units)
print("\n--- Predictions ---")
print(predictions[:5])
Теперь запустите полный скрипт в последний раз из терминала:
python3 main.py
Теперь вывод будет включать первые пять прогнозируемых цен на жилье для тестовой выборки. Эти значения — то, что наша модель считает медианной стоимостью жилья, основываясь на признаках в X_test. Вы можете концептуально сравнить эти прогнозы с фактическими значениями в y_test, чтобы оценить точность модели.
--- Predictions ---
[0.71912284 1.76401657 2.70965883 2.83892593 2.60465725]
Поздравляем! Вы успешно создали, обучили и использовали модель линейной регрессии с помощью scikit-learn.
Визуализация прогнозов модели с помощью matplotlib.pyplot.scatter()
На этом последнем этапе мы создадим визуализацию, чтобы лучше понять эффективность нашей модели. Визуализация критически важна в машинном обучении, так как она помогает увидеть закономерности и взаимосвязи, которые могут быть неочевидны при просмотре "сырых" чисел.
Мы создадим диаграмму рассеяния (scatter plot), которая сравнивает фактические цены на жилье (y_test) с прогнозами нашей модели. Этот тип графика называется "прогнозы против факта". Если бы наша модель была идеальной, все точки лежали бы на диагональной линии (под углом 45 градусов), где прогнозируемые значения равны фактическим.
Мы будем использовать matplotlib для создания этой визуализации и сохранения её в виде файла изображения.
Добавьте следующий код в ваш файл main.py:
import matplotlib.pyplot as plt
## Create a scatter plot comparing actual vs predicted values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5, color='blue', edgecolors='black')
## Add a diagonal line showing perfect predictions (where predicted = actual)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', linewidth=2, label='Perfect Prediction')
## Add labels and title
plt.xlabel('Actual House Prices ($100,000)')
plt.ylabel('Predicted House Prices ($100,000)')
plt.title('Linear Regression: Actual vs Predicted House Prices')
plt.legend()
plt.grid(True, alpha=0.3)
## Save the plot to a file
plt.savefig('housing_predictions.png', dpi=300, bbox_inches='tight')
plt.close()
print("\n--- Visualization Complete ---")
print("Plot saved to housing_predictions.png")
Теперь запустите полный скрипт из терминала:
python3 main.py
Вы увидите подтверждающее сообщение о том, что график был сохранен.
--- Visualization Complete ---
Plot saved to housing_predictions.png
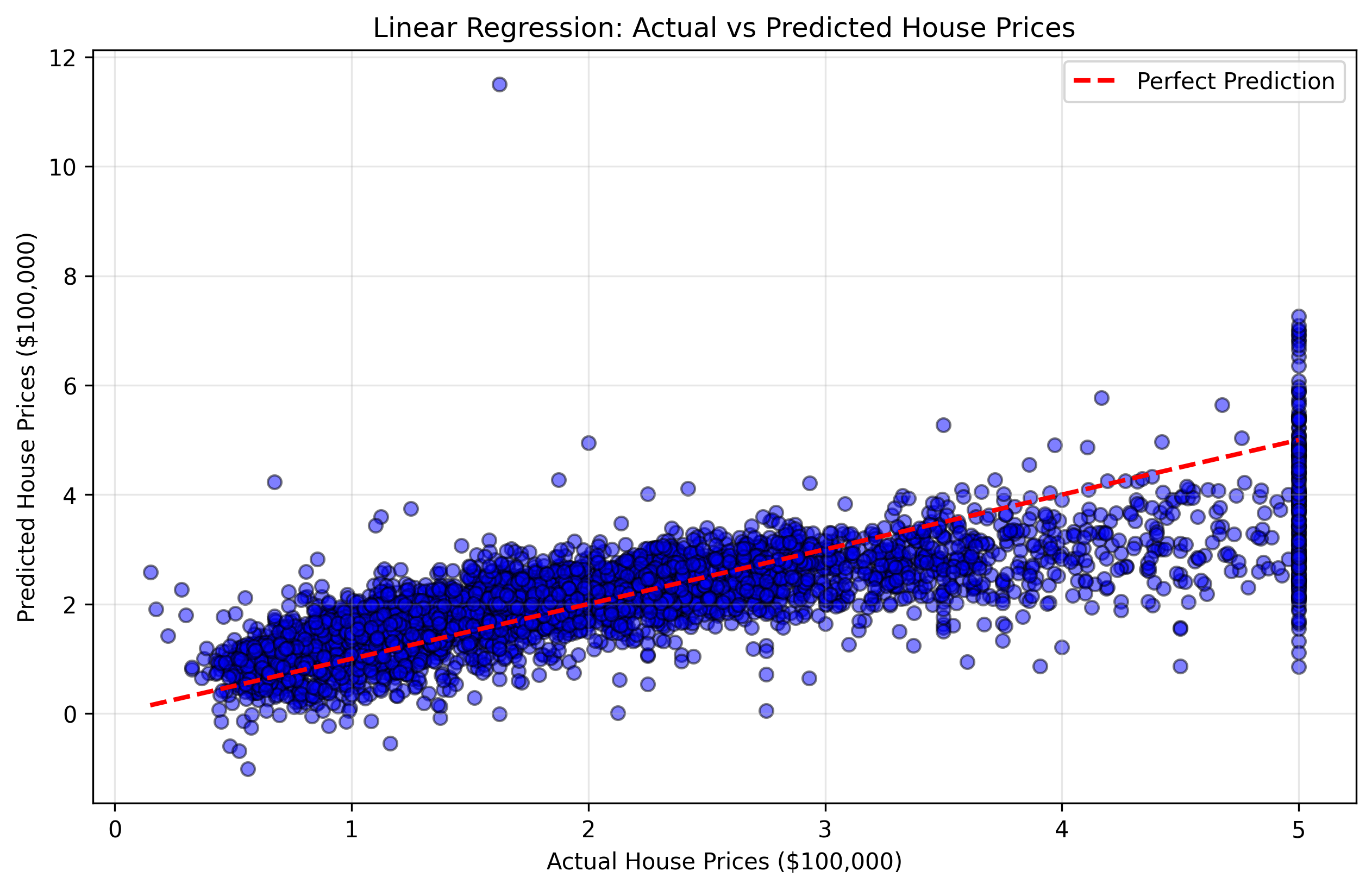 Рисунок 2: Диаграмма рассеяния, показывающая фактические цены на жилье в сравнении с прогнозируемыми. Точки, расположенные ближе к красной диагональной линии, указывают на более точные прогнозы.
Рисунок 2: Диаграмма рассеяния, показывающая фактические цены на жилье в сравнении с прогнозируемыми. Точки, расположенные ближе к красной диагональной линии, указывают на более точные прогнозы.
Эта визуализация поможет вам понять:
- Точки рядом с диагональной линией: Хорошие прогнозы, где модель была точна.
- Точки далеко от диагональной линии: Плохие прогнозы, где модель допустила значительные ошибки.
- Общая закономерность: Склонна ли модель завышать или занижать прогнозы для определенных ценовых диапазонов.
Вы можете дважды щелкнуть по файлу housing_predictions.png в файловом менеджере, чтобы просмотреть вашу визуализацию.
Поздравляем! Вы успешно создали, обучили, протестировали и визуализировали модель линейной регрессии с помощью scikit-learn.
Резюме
В этой лабораторной работе вы прошли полный цикл создания базовой модели машинного обучения с использованием scikit-learn.
Вы начали с загрузки набора данных о жилье в Калифорнии и его подготовки с помощью pandas. Затем вы узнали о важности разделения данных на обучающую и тестовую выборки и выполнили это разделение с помощью train_test_split.
После этого вы инициализировали модель LinearRegression, обучили её на обучающих данных с помощью метода fit(), использовали обученную модель для получения прогнозов на новых тестовых данных с помощью метода predict() и, наконец, визуализировали результаты для оценки эффективности модели.
Эта лабораторная работа закладывает прочный фундамент в работе с scikit-learn. Теперь вы можете изучать более продвинутые темы, такие как:
- Оценка модели: Вычисление метрик, таких как среднеквадратичная ошибка (MSE) или коэффициент детерминации (R-squared), для измерения точности модели.
- Визуализация данных: Создание более сложных графиков, таких как графики остатков, диаграммы важности признаков или корреляционные матрицы.
- Масштабирование признаков: Стандартизация или нормализация признаков для повышения производительности.
- Регуляризация: Использование гребневой (Ridge) или лассо-регрессии (Lasso) для предотвращения переобучения.
- Кросс-валидация: Более надежная оценка с использованием k-блочной кросс-валидации.
- Другие алгоритмы: Попробуйте случайный лес (Random Forest), метод опорных векторов (SVM) или нейронные сети.


