
Введение
Добро пожаловать в этот практический лабораторный практикум по классификации методом K-ближайших соседей (KNN) с использованием scikit-learn! Scikit-learn — это мощная и популярная библиотека Python для машинного обучения. Алгоритм KNN является одним из самых простых, но эффективных алгоритмов классификации. Он классифицирует новую точку данных на основе преобладающего класса ее 'k' ближайших соседей в пространстве признаков. В этом лабораторном практикуме вы пройдете полный процесс построения модели машинного обучения: загрузка знаменитого набора данных Iris, разделение его на обучающий и тестовый наборы, инициализация и обучение классификатора KNN, и, наконец, использование обученной модели для прогнозирования на новых, ранее невидимых данных. К концу этого лабораторного практикума вы получите твердое понимание основного рабочего процесса для контролируемого обучения (supervised learning) в scikit-learn.
Загрузка набора данных Iris с помощью datasets.load_iris()
На этом этапе вы начнете с загрузки необходимых данных. Мы будем использовать классический набор данных Iris, который удобно включен в scikit-learn. Сначала вам нужно импортировать модуль datasets из sklearn. Затем вы вызовете функцию load_iris() для получения данных.
Понимание load_iris():
- Тип возвращаемого значения: Возвращает объект
Bunch(похожий на словарь), содержащий:.data: Матрица признаков (150 образцов × 4 признака: длина чашелистика, ширина чашелистика, длина лепестка, ширина лепестка).target: Массив меток (виды: 0=setosa, 1=versicolor, 2=virginica).feature_names: Названия 4 признаков.target_names: Названия 3 видов
- Назначение: Предоставляет чистый, готовый к использованию набор данных для практики классификации.
Мы присвоим их переменным X и y соответственно, что является распространенной конвенцией в машинном обучении (X для признаков, y для меток).
Откройте файл main.py в редакторе слева и добавьте следующий код.
from sklearn import datasets
## Загрузка набора данных Iris
iris = datasets.load_iris()
## Присвоение признаков переменной X и меток переменной y
X = iris.data
y = iris.target
## Вы можете вывести форму, чтобы увидеть размеры
print("Features shape:", X.shape)
print("Labels shape:", y.shape)
Теперь запустите скрипт из терминала, чтобы увидеть вывод.
python3 main.py
Вы должны увидеть размеры матрицы признаков и вектора меток.
Features shape: (150, 4)
Labels shape: (150,)
Это означает, что у нас есть 150 образцов (цветов) и 4 признака для каждого образца.
Разделение данных на обучающую и тестовую выборки с помощью train_test_split из sklearn.model_selection
На этом этапе вы разделите набор данных на две части: обучающий набор и тестовый набор. Это важный шаг в машинном обучении для оценки производительности модели на невидимых данных.
Понимание параметров train_test_split():
test_size=0.3: Резервирует 30% данных для тестирования, 70% для обучения.random_state=42: Обеспечивает воспроизводимость разделений (один и тот же случайный генератор при каждом запуске).- Назначение: Предотвращает переобучение (overfitting) путем оценки модели на невидимых данных.
- Вывод: Возвращает четыре массива: X_train, X_test, y_train, y_test.
Мы обучаем модель на обучающем наборе, а затем тестируем ее предсказательную способность на тестовом наборе. Scikit-learn предоставляет удобную функцию train_test_split для этой цели. Вам нужно импортировать ее из sklearn.model_selection.
Добавьте следующий код в конец вашего файла main.py.
from sklearn.model_selection import train_test_split
## Разделение данных на обучающий и тестовый наборы
## test_size=0.3 означает, что 30% данных будут использованы для тестирования
## random_state обеспечивает воспроизводимость
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
## Вывод размеров новых наборов
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
Теперь снова запустите скрипт.
python3 main.py
Вывод теперь будет включать размеры ваших обучающих и тестовых наборов.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Инициализация KNeighborsClassifier с параметром n_neighbors=3 из sklearn.neighbors
На этом этапе вы инициализируете классификатор K-ближайших соседей (K-Nearest Neighbors). Основная идея KNN заключается в предсказании класса точки данных путем рассмотрения классов ее 'k' ближайших соседей.
Понимание параметров KNeighborsClassifier():
n_neighbors=3: Количество ближайших соседей, которые будут учитываться при предсказании.- Меньшие значения (например, 1-3): Более чувствительны к шуму, могут привести к переобучению (overfitting).
- Большие значения (например, 5-7): Более сглаженные границы принятия решений, более устойчивы.
- Поведение алгоритма: Для предсказания находит k ближайших точек из обучающего набора и использует голосование большинством.
- Отсутствие фазы обучения: KNN является "ленивым учеником" (lazy learner) — он хранит обучающие данные и выполняет вычисления во время предсказания.
KNeighborsClassifier — это класс в scikit-learn, реализующий этот алгоритм. Вам нужно импортировать его из sklearn.neighbors. Давайте создадим объект классификатора и назовем его clf.
Добавьте следующий код в конец вашего файла main.py.
from sklearn.neighbors import KNeighborsClassifier
## Инициализация классификатора KNN с n_neighbors=3
clf = KNeighborsClassifier(n_neighbors=3)
Этот код не производит никакого вывода, но он создает объект классификатора в памяти, готовый к обучению на следующем шаге.
Обучение классификатора с помощью clf.fit(X_train, y_train)
На этом этапе вы обучите, или 'приведете в соответствие' (fit), классификатор, используя ваши обучающие данные. Для алгоритма KNN фаза 'обучения' очень проста: она заключается лишь в сохранении всего обучающего набора данных (X_train и y_train).
Понимание метода .fit():
- Входные параметры:
X_train(матрица признаков),y_train(целевые метки). - Что он делает: Сохраняет обучающие данные в памяти для последующего использования при предсказании.
- Специфика KNN: В отличие от других алгоритмов, KNN не изучает параметры во время
fit. - Назначение: Подготавливает модель к предсказаниям на новых данных.
Когда требуется предсказание для новой точки, алгоритм находит 'k' ближайших точек в этом сохраненном наборе данных и принимает решение. Чтобы обучить модель в scikit-learn, вы используете метод .fit() объекта классификатора. Метод принимает обучающие признаки (X_train) и соответствующие им обучающие метки (y_train) в качестве аргументов.
Добавьте следующую строку кода в конец файла main.py.
## Обучение классификатора с использованием обучающих данных
clf.fit(X_train, y_train)
print("Classifier trained successfully.")
После добавления кода запустите скрипт.
python3 main.py
Вы увидите подтверждающее сообщение о том, что классификатор был обучен.
Features shape: (150, 4)
Labels shape: (150,)
X_train shape: (105, 4)
X_test shape: (45, 4)
Classifier trained successfully.
Предсказание классов с помощью clf.predict(X_test)
На этом заключительном этапе вы будете использовать обученный классификатор для выполнения предсказаний на тестовых данных. Теперь, когда модель 'обучилась' на обучающих данных, мы можем передать ей признаки тестового набора (X_test), которые она никогда раньше не видела, и попросить предсказать класс для каждого образца.
Понимание метода .predict():
- Входной параметр:
X_test(матрица признаков для невиданных данных). - Процесс алгоритма: Для каждого тестового образца находит k ближайших соседей в обучающих данных и использует голосование большинством.
- Вывод: Массив предсказанных меток классов (такой же длины, как и входные образцы).
- Метрика расстояния: По умолчанию использует евклидово расстояние для измерения сходства между точками.
- Назначение: Оценивает производительность модели на новых, невиданных данных.
Это делается с помощью метода .predict(). Метод принимает тестовые признаки (X_test) в качестве входных данных и возвращает массив предсказанных меток. Мы сохраним эти предсказания в переменной predictions и выведем их в консоль. Вы также можете вывести фактические метки (y_test), чтобы увидеть, насколько хорошо модель себя показала.
Добавьте финальный фрагмент кода в ваш файл main.py.
## Выполнение предсказаний на тестовых данных
predictions = clf.predict(X_test)
print("Predictions on test data:", predictions)
print("Actual labels of test data:", y_test)
Теперь запустите полный скрипт.
python3 main.py
Вы увидите массив предсказанных меток классов для тестового набора, за которым следует массив истинных меток.
... (предыдущий вывод) ...
Classifier trained successfully.
Predictions on test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Actual labels of test data: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1
0 0 0 2 1 1 0 0]
Примечание: Массивы вывода показаны здесь полностью. Сравнивая два массива, вы можете увидеть, что предсказания идеально совпадают с фактическими метками, что указывает на отличную производительность модели на этом тестовом наборе.
Визуализация результатов классификации KNN
На этом бонусном этапе вы создадите визуализации, чтобы лучше понять результаты классификации KNN. Визуализация помогает увидеть, насколько хорошо ваша модель себя показала, и понять границы принятия решений, созданные алгоритмом KNN.
Понимание визуализации данных в классификации:
- Диаграммы рассеяния (Scatter plots): Показывают взаимосвязи между признаками и распределение классов.
- Цветовое кодирование: Различные цвета представляют разные классы (виды).
- Обучающие и тестовые данные: Помогает понять обобщающую способность модели.
- Точность предсказаний: Визуальное сравнение предсказанных и фактических меток.
Добавьте следующий код в конец вашего файла main.py для создания визуализаций:
import matplotlib.pyplot as plt
import numpy as np
## Создание подграфиков для нескольких визуализаций
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
## График 1: Обучающие данные с разными цветами для каждого класса
scatter1 = axes[0].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis', alpha=0.7, s=50)
axes[0].set_xlabel('Sepal Length (cm)')
axes[0].set_ylabel('Sepal Width (cm)')
axes[0].set_title('Training Data Distribution')
axes[0].legend(*scatter1.legend_elements(), title="Classes")
## График 2: Предсказания тестовых данных против фактических меток
## Создание сравнения: правильные предсказания против неправильных
test_predictions = clf.predict(X_test)
correct_predictions = (test_predictions == y_test)
## Отображение правильных предсказаний
correct_mask = correct_predictions
scatter2_correct = axes[1].scatter(X_test[correct_mask, 0], X_test[correct_mask, 1],
c=y_test[correct_mask], cmap='viridis', alpha=0.7, s=50, marker='o')
## Отображение неправильных предсказаний с другим маркером
incorrect_mask = ~correct_predictions
if np.any(incorrect_mask):
scatter2_incorrect = axes[1].scatter(X_test[incorrect_mask, 0], X_test[incorrect_mask, 1],
c=test_predictions[incorrect_mask], cmap='viridis',
alpha=0.7, s=80, marker='x', edgecolors='red', linewidths=2)
axes[1].set_xlabel('Sepal Length (cm)')
axes[1].set_ylabel('Sepal Width (cm)')
axes[1].set_title('Test Data: Predictions vs Actual\n(correct=●, incorrect=✕)')
## Создание легенды
legend_elements = [plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='Correct'),
plt.Line2D([0], [0], marker='x', color='red', markersize=8, label='Incorrect')]
axes[1].legend(handles=legend_elements)
plt.tight_layout()
plt.savefig('knn_classification_results.png', dpi=150, bbox_inches='tight')
print("Visualization saved to knn_classification_results.png")
## Дополнительно: Отображение точности предсказаний
accuracy = np.mean(correct_predictions) * 100
print(f"Model Accuracy: {accuracy:.1f}%")
Запустите обновленный скрипт:
python3 main.py
Вы должны увидеть вывод, включающий:
... (предыдущий вывод) ...
Visualization saved to knn_classification_results.png
Model Accuracy: 100.0%
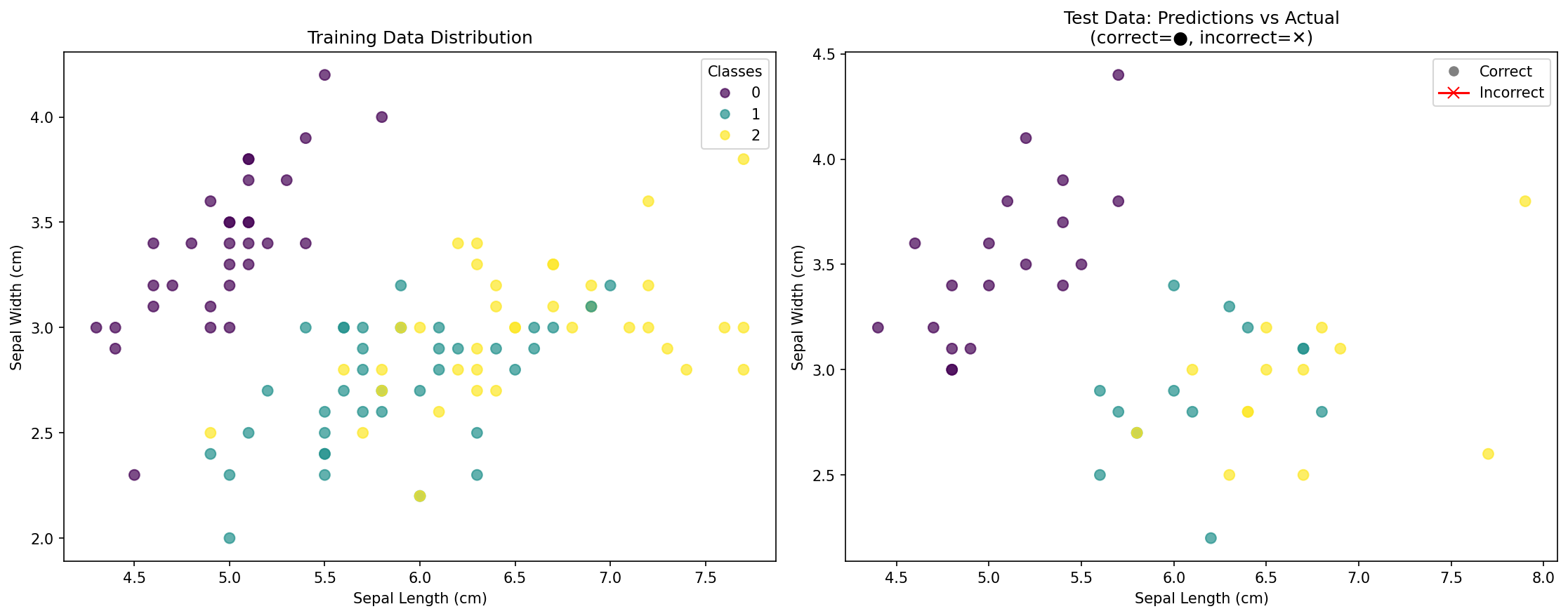
Что показывает визуализация:
- Левый график: Распределение точек обучающих данных, окрашенных по их фактическому виду.
- Правый график: Точки тестовых данных, показывающие:
- Круги (●): Правильно классифицированные точки.
- Крестики (✕): Неправильно классифицированные точки (если таковые имеются).
- Оценка точности: Общий процент правильных предсказаний.
Эта визуализация помогает понять:
- Как классы распределены в пространстве признаков.
- Не переобучается ли ваша модель или хорошо ли она обобщает.
- Какие области могут быть сложными для классификации.
- Эффективность вашей модели KNN визуально.
Резюме
Поздравляем с завершением этой лабораторной работы! Вы успешно создали и обучили модель классификации K-ближайших соседей (K-Nearest Neighbors, KNN) с использованием scikit-learn. Вы освоили фундаментальный рабочий процесс проекта машинного обучения с учителем, который включает:
- Загрузку набора данных с помощью
sklearn.datasets. - Разделение данных на обучающий и тестовый наборы с помощью
train_test_split. - Инициализацию классификатора, в данном случае
KNeighborsClassifier. - Обучение модели на обучающих данных с использованием метода
.fit(). - Выполнение предсказаний на новых, невиданных данных с использованием метода
.predict(). - Визуализацию результатов для понимания производительности модели и закономерностей принятия решений.
Этот процесс составляет основу для многих задач машинного обучения. Отсюда вы можете изучить, как более формально оценивать производительность вашей модели с использованием таких метрик, как точность (accuracy), прецизионность (precision) и полнота (recall), или поэкспериментировать с различными значениями n_neighbors, чтобы увидеть, как это влияет на результат. Вы также можете попробовать визуализировать границы принятия решений или использовать различные метрики расстояния в вашем классификаторе KNN.


