
Введение
Добро пожаловать на вашу первую лабораторную работу по scikit-learn! Scikit-learn — одна из самых популярных и мощных библиотек машинного обучения с открытым исходным кодом для Python. Она предоставляет широкий спектр инструментов для интеллектуального анализа данных и анализа данных, построенных на основе NumPy, SciPy и matplotlib.
Перед началом этого курса вы должны обладать базовыми навыками программирования на Python и убедиться, что Python правильно настроен в переменной среды PATH вашей системы. Если вы еще не изучили Python, вы можете начать с нашего Пути обучения Python. Кроме того, у вас должны быть установлены NumPy и Pandas, поскольку они являются важными предварительными условиями для операций scikit-learn. Если вам нужно изучить эти библиотеки, вы можете ознакомиться с нашим Путем обучения NumPy и Путем обучения Pandas.
В этой лабораторной работе вы изучите основные шаги для начала работы с scikit-learn в среде LabEx. Мы пройдемся по проверке установки, импорту модулей и загрузке одного из встроенных наборов данных scikit-learn. Это подтвердит, что ваша среда правильно настроена для будущих экспериментов по машинному обучению.
Установите scikit-learn с помощью pip install scikit-learn
На этом шаге мы обсудим, как установить библиотеку scikit-learn. В типичной среде Python на вашем локальном компьютере вы бы использовали pip, установщик пакетов для Python, для установки новых библиотек. Команда для установки scikit-learn выглядит следующим образом:
pip install scikit-learn
Однако, чтобы сделать ваш процесс обучения более гладким, среда LabEx поставляется с предварительно установленными scikit-learn и ее зависимостями. Поэтому вам не нужно выполнять команду установки здесь. Мы показываем ее для справки, чтобы вы знали, как настроить scikit-learn на своем собственном компьютере.
Перейдем к следующему шагу, чтобы начать использовать библиотеку.
Импортируйте scikit-learn как from sklearn import datasets
На этом шаге вы напишете первую строку кода на Python для взаимодействия с библиотекой scikit-learn. Прежде чем вы сможете использовать любые функции или объекты из библиотеки в Python, вы должны сначала импортировать их в свой скрипт.
Scikit-learn включает модуль datasets, который содержит утилиты для загрузки и получения популярных эталонных наборов данных. Мы импортируем этот модуль, чтобы использовать его на следующем шаге.
Сначала найдите файл main.py в файловом проводнике слева от вашего WebIDE. Щелкните по нему, чтобы открыть в редакторе. Теперь добавьте следующую строку кода в файл main.py:
from sklearn import datasets
Эта строка указывает Python найти библиотеку sklearn и импортировать из нее модуль datasets, делая его функции доступными для нас. После добавления кода сохраните файл. Мы добавим больше кода и запустим скрипт на следующих шагах.
Проверьте установку с помощью sklearn.version
На этом шаге мы проверим, правильно ли установлен и доступен scikit-learn, проверив его номер версии. Это распространенная практика для обеспечения правильной настройки библиотеки в вашей среде. Каждая установка scikit-learn имеет специальный атрибут __version__, который содержит эту информацию.
Давайте добавим код в наш файл main.py для вывода версии. Нам также нужно импортировать сам пакет верхнего уровня sklearn. Измените ваш файл main.py следующим образом:
import sklearn
from sklearn import datasets
print(sklearn.__version__)
Теперь давайте запустим этот скрипт. Откройте терминал в вашем WebIDE (обычно вы можете найти значок + или меню "Terminal"). В терминале, который должен открыться в директории /home/labex/project, выполните следующую команду:
python3 main.py
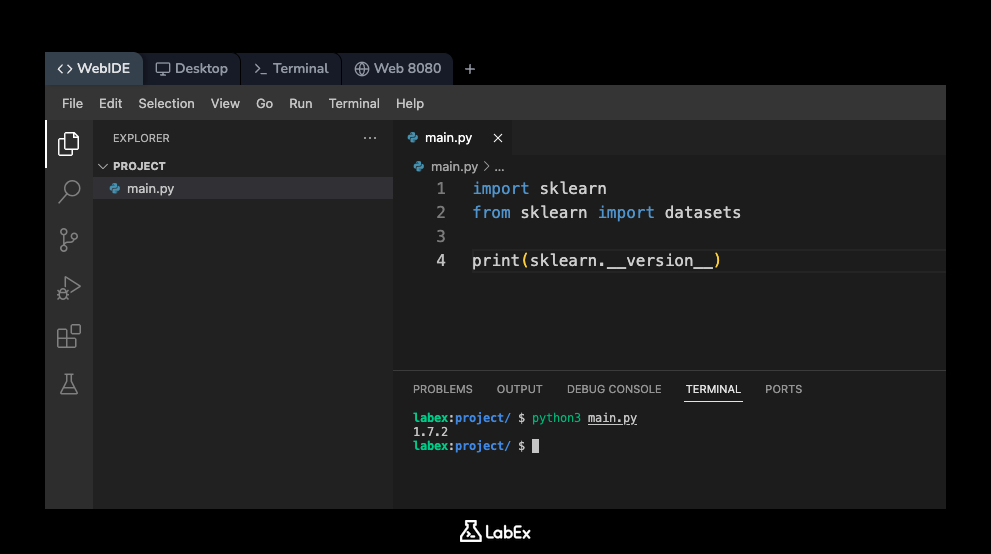
Вы должны увидеть установленную версию scikit-learn, выведенную в консоль. Вывод будет выглядеть примерно так (точный номер версии может отличаться):
1.x.x
Это подтверждает, что Python может успешно импортировать и использовать библиотеку scikit-learn.
Загрузите пример набора данных с помощью datasets.load_iris()
На этом шаге мы будем использовать ранее импортированный модуль datasets для загрузки набора данных. Scikit-learn поставляется с несколькими небольшими стандартными наборами данных, которые не требуют загрузки с внешнего веб-сайта. Они полезны для начала работы и тестирования алгоритмов.
Мы загрузим набор данных Ирисов (Iris dataset) — классический и очень известный набор данных в области машинного обучения. Он содержит измерения 150 цветков ириса трех разных видов.
Для его загрузки мы используем функцию datasets.load_iris(). Давайте изменим файл main.py, чтобы загрузить набор данных и сохранить его в переменной с именем iris. Мы также добавим оператор печати, чтобы подтвердить, что набор данных был загружен.
Обновите ваш файл main.py следующим содержимым:
import sklearn
from sklearn import datasets
## Загрузка набора данных Ирисов
iris = datasets.load_iris()
print("Набор данных Ирисов успешно загружен.")
Предложение: Вы можете скопировать приведенный выше код в свой редактор кода, затем внимательно прочитать каждую строку кода, чтобы понять ее функцию. Если вам требуется дополнительное объяснение, вы можете нажать кнопку "Explain Code" 👆. Вы можете взаимодействовать с Labby для получения персонализированной помощи.
Сохраните файл и снова запустите его из терминала:
python3 main.py
Теперь вывод должен быть следующим:
Набор данных Ирисов успешно загружен.
Это указывает на то, что функция load_iris() выполнилась без ошибок, и набор данных теперь доступен в переменной iris в нашем скрипте.
Выведите ключи набора данных с помощью print(iris.keys())
На этом шаге мы изучим структуру набора данных Ирисов, который мы только что загрузили. Объект, возвращаемый функцией load_iris(), является объектом типа Bunch, который похож на словарь Python. Он содержит ключи и значения, описывающие набор данных.
Чтобы увидеть, какая информация доступна, мы можем вывести его ключи с помощью метода .keys(). Это покажет нам все компоненты набора данных, такие как сами данные, метки целевых классов и описательные имена.
Измените ваш файл main.py, чтобы вывести ключи объекта iris. Ваш окончательный скрипт должен выглядеть следующим образом:
import sklearn
from sklearn import datasets
## Загрузка набора данных Ирисов
iris = datasets.load_iris()
## Вывод ключей набора данных
print(iris.keys())
Сохраните файл и запустите его в последний раз из терминала:
python3 main.py
Вывод покажет различные части объекта набора данных:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
Вот краткое описание наиболее важных ключей:
data: Массив, содержащий данные признаков (измерения цветков).target: Массив, содержащий метки (виды каждого цветка).feature_names: Названия признаков (например, 'sepal length (cm)').target_names: Названия целевых видов (например, 'setosa').DESCR: Полное описание набора данных.
Выведя эти ключи, вы успешно загрузили и проинспектировали набор данных, завершив базовый процесс настройки.
Резюме
Поздравляем! Вы успешно завершили эту вводную лабораторную работу по настройке и проверке вашей среды scikit-learn.
В этой лабораторной работе вы научились:
- Понимать процесс установки scikit-learn.
- Проверять версию библиотеки, чтобы подтвердить успешную настройку.
- Импортировать модули из библиотеки scikit-learn.
- Загружать встроенный набор данных, набор данных Ирисов.
- Изучать базовую структуру объекта набора данных scikit-learn.
Теперь вы готовы перейти к более интересным лабораторным работам, где вы будете изучать предварительную обработку данных, обучение моделей и оценку с использованием мощных инструментов, предоставляемых scikit-learn.


