
Введение
Добро пожаловать в мир машинного обучения с scikit-learn! Одним из первых и наиболее важных шагов в любом проекте машинного обучения является загрузка и понимание ваших данных. Scikit-learn, мощная и удобная библиотека для машинного обучения на Python, предоставляет несколько встроенных наборов данных, которые помогут вам начать работу.
В этой лабораторной работе вы будете работать со знаменитым набором данных ирисов (Iris flower dataset). Вы узнаете, как загрузить этот набор данных, изучить его структуру, получить доступ к данным признаков (feature data) и целевым меткам (target labels), и, наконец, создадите простую визуализацию, чтобы получить первое представление о распределении данных. Эти фундаментальные знания необходимы любому начинающему специалисту по данным (data scientist) или инженеру машинного обучения (machine learning engineer).
Загрузка набора данных Iris с помощью datasets.load_iris()
На этом шаге вы узнаете, как загрузить один из встроенных наборов данных scikit-learn. Мы будем использовать функцию load_iris() из модуля sklearn.datasets. Эта функция возвращает объект типа "Bunch", который похож на словарь Python и содержит набор данных вместе с его метаданными.
Сначала откройте файл main.py в файловом проводнике слева от экрана. Весь наш код будет написан в этом файле.
Теперь добавьте следующий код в main.py, чтобы импортировать необходимый модуль и загрузить набор данных.
from sklearn import datasets
## Загрузка набора данных Iris
iris = datasets.load_iris()
Этот код импортирует модуль datasets и вызывает функцию load_iris(), сохраняя полученный объект набора данных в переменной с именем iris.
Чтобы выполнить ваш скрипт, откройте терминал в WebIDE (вы можете использовать меню "Terminal" -> "New Terminal") и выполните следующую команду. Ваша текущая директория уже ~/project.
python3 main.py
Вы не увидите никакого вывода, и это нормально. Мы загрузили данные в переменную iris, но еще не попросили наш скрипт ничего напечатать. На следующих шагах мы изучим содержимое этого объекта iris.
Доступ к массиву данных через iris.data
На этом шаге вы получите доступ к основной части набора данных: данным признаков (feature data). Объект iris, который мы создали, содержит атрибут data, который хранит массив NumPy с измерениями для каждого цветка. Каждая строка представляет собой образец (цветок), а каждый столбец представляет признак (измерение).
Давайте изменим файл main.py, чтобы вывести этот массив данных и посмотреть, как он выглядит.
Обновите ваш файл main.py следующим кодом:
from sklearn import datasets
## Загрузка набора данных Iris
iris = datasets.load_iris()
## Печать массива данных
print(iris.data)
Теперь снова запустите скрипт из вашего терминала:
python3 main.py
В терминале вы должны увидеть большой массив чисел. Это данные признаков для всех 150 образцов цветов в наборе данных. Каждый образец имеет 4 признака.
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
...
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
Доступ к целевому массиву через iris.target
На этом шаге вы получите доступ к меткам (labels) для каждого образца в наборе данных. В обучении с учителем (supervised machine learning) эти метки называются "целью" (target). Объект iris хранит их в атрибуте target. Для набора данных Iris цели представляют собой виды (species) каждого цветка.
Виды кодируются целыми числами: 0 для сетозы (setosa), 1 для версиколор (versicolor) и 2 для вирджиники (virginica). Атрибут iris.target представляет собой массив NumPy, содержащий соответствующее целое число для каждого образца в iris.data.
Давайте изменим main.py, чтобы вывести целевой массив.
from sklearn import datasets
## Загрузка набора данных Iris
iris = datasets.load_iris()
## Печать целевого массива
print(iris.target)
Запустите скрипт из вашего терминала:
python3 main.py
Вывод будет представлять собой массив из нулей, единиц и двоек, соответствующих видам каждого из 150 цветов.
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Изучение названий признаков с помощью iris.feature_names
На этом шаге вы узнаете, что на самом деле представляют собой столбцы в массиве iris.data. Хотя мы знаем, что признаков четыре, их названия не очевидны из самого массива данных. Объект iris удобно хранит эти названия в атрибуте feature_names.
Это очень полезно для понимания и интерпретации ваших данных. Давайте изменим main.py, чтобы вывести эти названия признаков.
Обновите ваш файл main.py:
from sklearn import datasets
## Загрузка набора данных Iris
iris = datasets.load_iris()
## Печать названий признаков
print(iris.feature_names)
Теперь запустите скрипт из вашего терминала:
python3 main.py
Вывод будет представлять собой список строк, содержащий название каждого из четырех столбцов в iris.data.
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Теперь вы знаете, что четыре признака соответствуют длине чашелистика (sepal length), ширине чашелистика (sepal width), длине лепестка (petal length) и ширине лепестка (petal width), все в сантиметрах.
Визуализация данных с помощью matplotlib.pyplot.scatter(iris.data[:, 0], iris.data[:, 1])
На заключительном этапе вы выполните простую визуализацию данных, чтобы увидеть взаимосвязь между двумя признаками. Визуализация является ключевой частью исследования данных. Мы будем использовать библиотеку matplotlib, популярный инструмент для построения графиков в Python, для создания диаграммы рассеяния (scatter plot).
Мы построим график первого признака (длина чашелистика) против второго признака (ширина чашелистика). Чтобы выбрать эти столбцы из наших данных, мы используем срезы NumPy (NumPy slicing):
iris.data[:, 0]выбирает все строки (:) и первый столбец (0).iris.data[:, 1]выбирает все строки (:) и второй столбец (1).
Вместо отображения графика на экране, что не идеально для данной среды, мы сохраним его в файл изображения с именем iris_plot.png.
Обновите ваш файл main.py следующим кодом:
from sklearn import datasets
import matplotlib.pyplot as plt
## Загрузка набора данных Iris
iris = datasets.load_iris()
## Мы построим график первых двух признаков: Длина чашелистика против Ширины чашелистика
X = iris.data[:, :2]
y = iris.target
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('Sepal Length vs Sepal Width')
## Сохранение графика в файл
plt.savefig('iris_plot.png')
print("Plot saved to iris_plot.png")
Запустите скрипт из вашего терминала:
python3 main.py
Вы увидите подтверждающее сообщение.
Plot saved to iris_plot.png
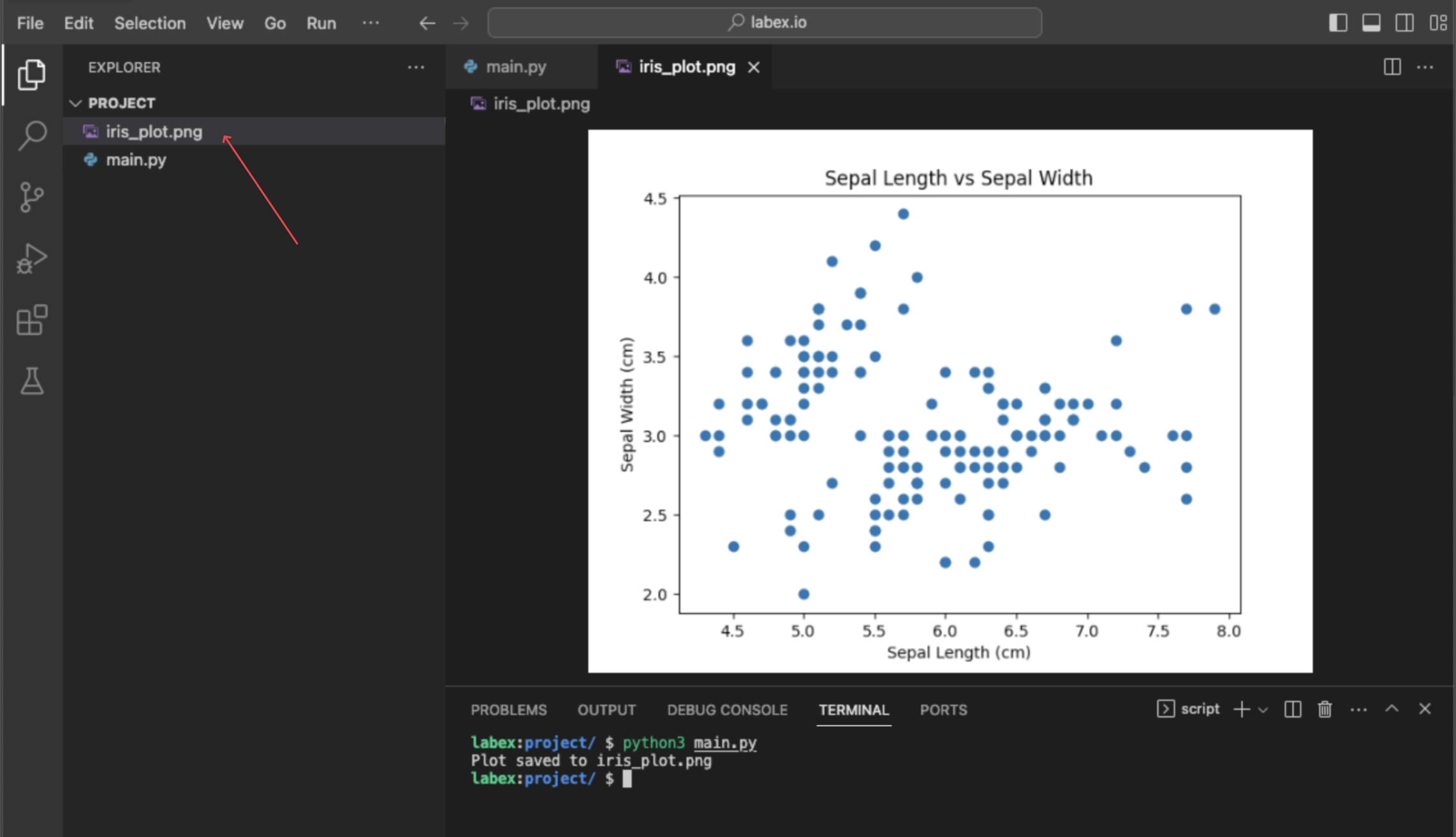
Эта команда не отобразит график напрямую, но создаст новый файл с именем iris_plot.png в вашем каталоге ~/project. Вы можете дважды щелкнуть этот файл в файловом менеджере слева, чтобы просмотреть вашу диаграмму рассеяния.
Резюме
Поздравляем с завершением этой лабораторной работы! Вы успешно сделали первые шаги в работе с данными с помощью scikit-learn.
В этой лабораторной работе вы научились:
- Загружать встроенный набор данных с помощью
sklearn.datasets.load_iris(). - Получать доступ к матрице признаков через атрибут
.data. - Получать доступ к меткам целевой переменной через атрибут
.target. - Понимать значение признаков, просматривая атрибут
.feature_names. - Выполнять базовую визуализацию данных, создавая диаграмму рассеяния с помощью
matplotlibи сохраняя ее в файл.
Эти фундаментальные навыки являются основой для более сложных задач машинного обучения. Теперь вы готовы исследовать другие наборы данных и начать создавать собственные модели машинного обучения.


