
Введение
В этой лабораторной работе вы узнаете об индексах MySQL и методах оптимизации производительности. Лабораторная работа посвящена созданию и управлению индексами для повышения производительности запросов к базе данных.
Вы начнете с создания таблицы users и вставки образца данных. Затем вы создадите индекс по одному столбцу в столбце username и узнаете, как проверить его создание. Лабораторная работа также охватит анализ планов запросов с использованием EXPLAIN, добавление составных индексов для запросов по нескольким столбцам и удаление неиспользуемых индексов для поддержания эффективности базы данных.
Создание одноколоночного индекса в таблице
На этом шаге вы научитесь создавать индекс по одному столбцу в MySQL. Индексы имеют решающее значение для повышения производительности запросов к базе данных, особенно при работе с большими таблицами. Индекс по столбцу позволяет базе данных быстро находить строки, соответствующие определенному значению в этом столбце, без необходимости сканировать всю таблицу.
Понимание индексов
Представьте себе индекс как указатель в книге. Вместо того чтобы читать всю книгу для поиска конкретной темы, вы можете использовать указатель, чтобы быстро найти нужные страницы. Аналогично, индекс базы данных помогает движку базы данных быстро находить нужные строки.
Создание таблицы
Сначала давайте создадим простую таблицу с именем users для демонстрации создания индекса. Откройте терминал в виртуальной машине LabEx. Вы можете использовать ярлык Xfce Terminal на рабочем столе.
Подключитесь к серверу MySQL от имени пользователя root:
sudo mysql -u root
Сначала создайте базу данных для этой лабораторной работы и выберите ее:
CREATE DATABASE lab_db;
USE lab_db;
Теперь создайте таблицу users:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Это SQL-выражение создает таблицу с именем users со столбцами id, username, email и created_at. Столбец id установлен как первичный ключ и автоматически увеличивается.
Давайте вставим некоторые образцы данных в таблицу users:
INSERT INTO users (username, email) VALUES
('john_doe', 'john.doe@example.com'),
('jane_smith', 'jane.smith@example.com'),
('peter_jones', 'peter.jones@example.com');
Создание индекса по одному столбцу
Теперь давайте создадим индекс по столбцу username. Это поможет ускорить запросы, которые ищут пользователей по их имени пользователя.
CREATE INDEX idx_username ON users (username);
Это выражение создает индекс с именем idx_username по столбцу username таблицы users.
Проверка индекса
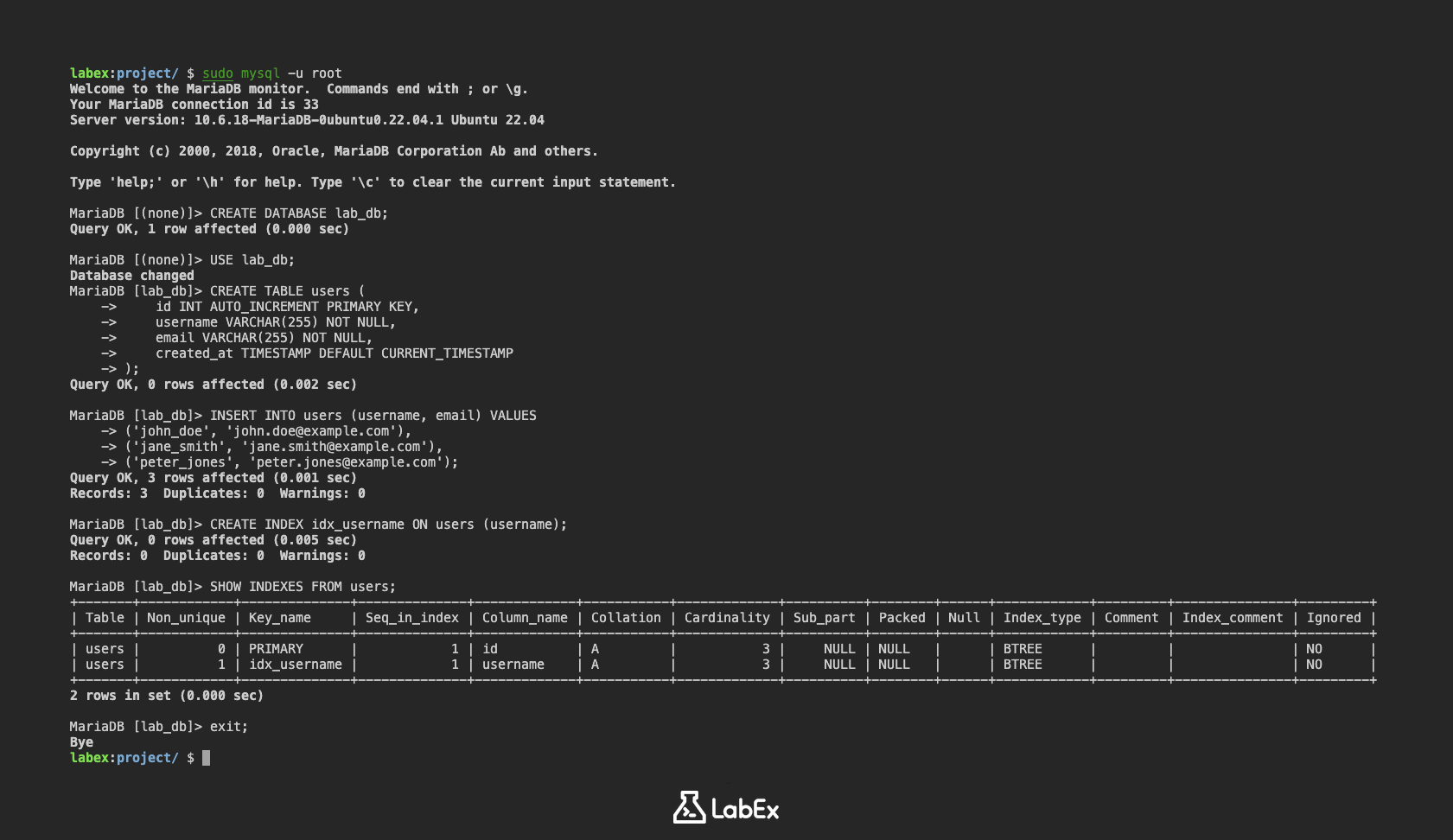
Вы можете проверить, был ли создан индекс, используя команду SHOW INDEXES:
SHOW INDEXES FROM users;
Вывод покажет детали индексов в таблице users, включая индекс idx_username, который вы только что создали. Вы должны увидеть строку, где Key_name равен idx_username, а Column_name равен username.
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 3 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 3 | NULL | NULL | | BTREE | | | NO |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
Теперь вы успешно создали индекс по одному столбцу в таблице. Это улучшит производительность запросов, которые фильтруют данные на основе индексированного столбца.
Анализ плана запроса с помощью EXPLAIN
На этом шаге вы научитесь использовать оператор EXPLAIN в MySQL для анализа плана выполнения запроса. Понимание плана запроса необходимо для выявления узких мест в производительности и оптимизации ваших запросов.
Что такое план запроса?
План запроса — это дорожная карта, которую движок базы данных использует для выполнения запроса. Он описывает порядок доступа к таблицам, используемые индексы и алгоритмы, применяемые для получения данных. Анализируя план запроса, вы можете понять, как база данных выполняет ваш запрос, и выявить области для улучшения.
Использование оператора EXPLAIN
Оператор EXPLAIN предоставляет информацию о том, как MySQL выполняет запрос. Он показывает задействованные таблицы, используемые индексы, порядок соединения (join order) и другие детали, которые помогут вам понять производительность запроса.
Теперь давайте проанализируем простой запрос с помощью EXPLAIN.
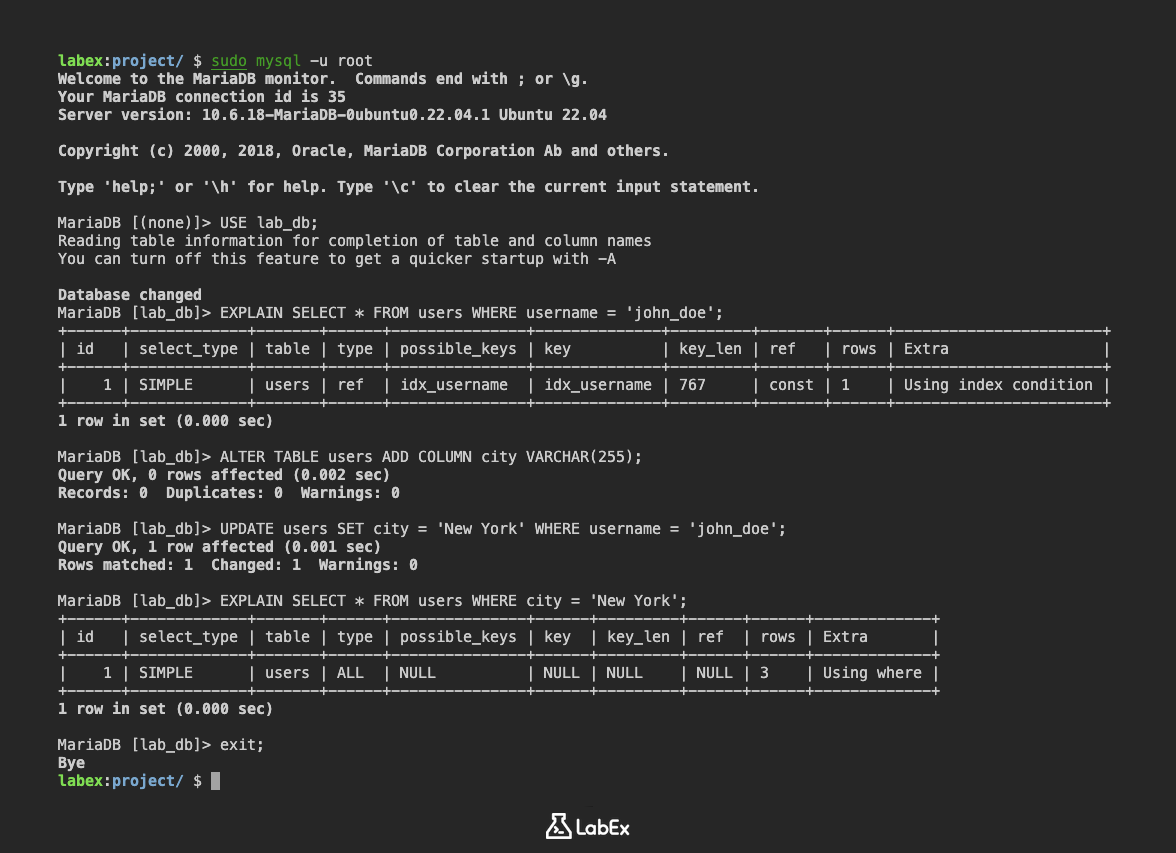
EXPLAIN SELECT * FROM users WHERE username = 'john_doe';
Вывод оператора EXPLAIN будет представлять собой таблицу с несколькими столбцами. Вот разбивка некоторых наиболее важных столбцов:
id: Идентификатор оператора SELECT.select_type: Тип запроса SELECT (например,SIMPLE,PRIMARY,SUBQUERY).table: Обрабатываемая таблица.type: Тип соединения (join type). Это один из наиболее важных столбцов. Распространенные значения включают:system: Таблица содержит только одну строку.const: Таблица содержит не более одной совпадающей строки, которая считывается в начале запроса.eq_ref: Для каждой комбинации строк из предыдущих таблиц считывается одна строка из этой таблицы. Это используется при соединении по индексированному столбцу.ref: Для каждой комбинации строк из предыдущих таблиц из этой таблицы считываются все совпадающие строки. Это используется при соединении по индексированному столбцу.range: Извлекаются только строки в заданном диапазоне с использованием индекса.index: Выполняется полное сканирование индекса.ALL: Выполняется полное сканирование таблицы. Это наименее эффективный тип.
possible_keys: Индексы, которые MySQL мог бы использовать для поиска строк в таблице.key: Индекс, который MySQL фактически использовал.key_len: Длина ключа, которую использовал MySQL.ref: Столбцы или константы, которые сравниваются с индексом.rows: Количество строк, которое, по оценкам MySQL, придется просмотреть для выполнения запроса.Extra: Дополнительная информация о том, как MySQL выполняет запрос. Распространенные значения включают:Using index: Запрос может быть удовлетворен только с использованием индекса.Using where: MySQL необходимо отфильтровать строки после доступа к таблице.Using temporary: MySQL необходимо создать временную таблицу для выполнения запроса.Using filesort: MySQL необходимо отсортировать строки после доступа к таблице.
Интерпретация вывода EXPLAIN
Для запроса SELECT * FROM users WHERE username = 'john_doe' вывод EXPLAIN должен выглядеть примерно так:
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | users | ref | idx_username | idx_username | 767 | const | 1 | Using index condition |
+------+-------------+-------+------+---------------+--------------+---------+-------+------+-----------------------+
В этом примере:
typeравенref, что означает, что MySQL использует индекс для поиска совпадающей строки.possible_keysиkeyоба показываютidx_username, что означает, что MySQL использует индексidx_username, который мы создали на предыдущем шаге.rowsравен1, что означает, что MySQL оценивает, что ей придется просмотреть только одну строку для выполнения запроса.
Анализ запроса без индекса
Теперь давайте проанализируем запрос, который не использует индекс. Сначала добавим новый столбец в таблицу users под названием city:
ALTER TABLE users ADD COLUMN city VARCHAR(255);
Теперь выполним EXPLAIN для запроса, который ищет по city. Поскольку мы еще не добавили никаких данных в столбец city, давайте обновим одну из строк:
UPDATE users SET city = 'New York' WHERE username = 'john_doe';
Теперь снова выполните оператор EXPLAIN:
EXPLAIN SELECT * FROM users WHERE city = 'New York';
Вывод может выглядеть так:
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------+
В этом примере:
typeравенALL, что означает, что MySQL выполняет полное сканирование таблицы.possible_keysиkeyоба равныNULL, что означает, что MySQL не использует никаких индексов.rowsравен3, что означает, что MySQL оценивает, что ей придется просмотреть все 3 строки в таблице для выполнения запроса.ExtraпоказываетUsing where, что означает, что MySQL необходимо отфильтровать строки после доступа к таблице.
Это указывает на то, что запрос не оптимизирован и может выиграть от индекса по столбцу city.
Добавление составного индекса для многоколоночных запросов
На этом шаге вы научитесь создавать составной индекс в MySQL. Составной индекс — это индекс по двум или более столбцам в таблице. Он может значительно повысить производительность запросов, которые фильтруют данные на основе нескольких столбцов.
Что такое составной индекс?
Составной индекс — это индекс, охватывающий несколько столбцов. Он полезен, когда запросы часто используют несколько столбцов в предложении WHERE. Порядок столбцов в составном индексе имеет значение. Индекс наиболее эффективен, когда столбцы указаны в том же порядке в предложении WHERE запроса.
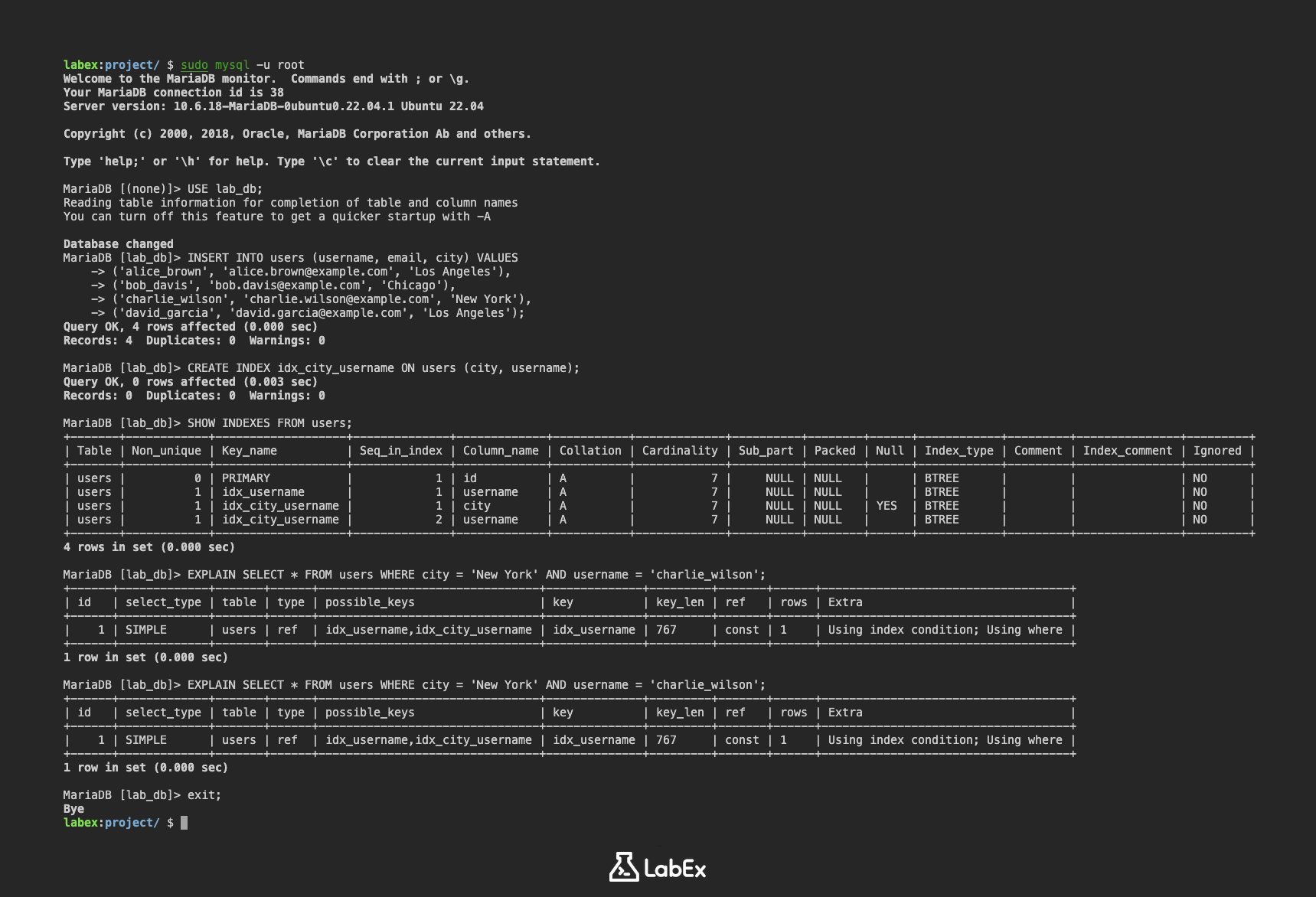
Давайте добавим больше данных в таблицу users, включая разные города:
INSERT INTO users (username, email, city) VALUES
('alice_brown', 'alice.brown@example.com', 'Los Angeles'),
('bob_davis', 'bob.davis@example.com', 'Chicago'),
('charlie_wilson', 'charlie.wilson@example.com', 'New York'),
('david_garcia', 'david.garcia@example.com', 'Los Angeles');
Создание составного индекса
Предположим, вы часто выполняете запросы, которые фильтруют пользователей по city и username. В этом случае вы можете создать составной индекс по столбцам city и username.
CREATE INDEX idx_city_username ON users (city, username);
Это выражение создает индекс с именем idx_city_username по столбцам city и username таблицы users.
Проверка индекса
Вы можете проверить, был ли создан индекс, используя команду SHOW INDEXES:
SHOW INDEXES FROM users;
Вывод покажет детали индексов в таблице users, включая индекс idx_city_username, который вы только что создали. Вы должны увидеть две строки для idx_city_username: одну для столбца city и одну для столбца username.
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_username | 1 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
Использование составного индекса
Чтобы увидеть преимущества составного индекса, вы можете использовать команду EXPLAIN для анализа запроса, который использует оба столбца city и username в предложении WHERE.
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
Вывод EXPLAIN покажет, что запрос использует индекс idx_city_username, что означает, что база данных может быстро найти совпадающую строку без сканирования всей таблицы. Обратите внимание на столбцы possible_keys и key в выводе. Если индекс используется, вы увидите idx_city_username в этих столбцах.
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | users | ref | idx_username,idx_city_username | idx_username | 767 | const | 1 | Using index condition; Using where |
+------+-------------+-------+------+--------------------------------+--------------+---------+-------+------+------------------------------------+
Порядок столбцов в индексе
Порядок столбцов в составном индексе имеет значение. Если вы создадите индекс по (username, city) вместо (city, username), индекс будет менее эффективен для запросов, которые фильтруют по city, а затем по username.
Например, если бы у нас был индекс по (username, city) и мы выполнили следующий запрос:
EXPLAIN SELECT * FROM users WHERE city = 'New York' AND username = 'charlie_wilson';
MySQL может не использовать индекс или использовать его лишь частично, поскольку столбец city не является ведущим столбцом в индексе.
Удаление неиспользуемого индекса
На этом шаге вы научитесь удалять неиспользуемый индекс в MySQL. Хотя индексы могут значительно улучшить производительность запросов, они также увеличивают накладные расходы на операции записи (вставки, обновления и удаления). Поэтому важно выявлять и удалять индексы, которые больше не используются.
Зачем удалять неиспользуемые индексы?
Неиспользуемые индексы занимают дисковое пространство и могут замедлять операции записи. При изменении данных в таблице движок базы данных также должен обновлять все индексы этой таблицы. Если индекс не используется ни одним запросом, он просто добавляет ненужные накладные расходы.
На предыдущих шагах мы создали индекс с именем idx_username по столбцу username. Предположим, что после анализа ваших шаблонов запросов вы определили, что этот индекс больше не используется.
Удаление индекса
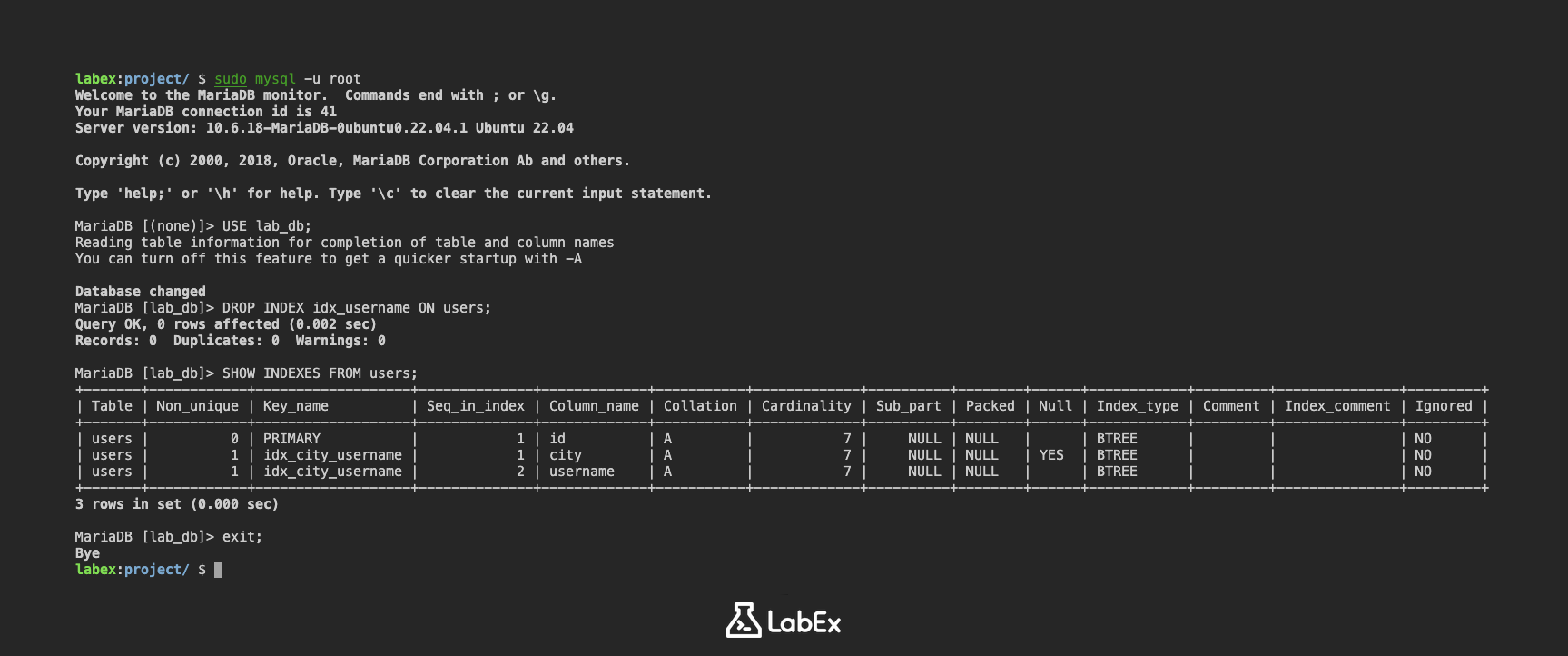
Чтобы удалить индекс idx_username, вы можете использовать оператор DROP INDEX:
DROP INDEX idx_username ON users;
Это выражение удаляет индекс idx_username из таблицы users.
Проверка удаления индекса
Вы можете проверить, был ли удален индекс, используя команду SHOW INDEXES:
SHOW INDEXES FROM users;
Вывод покажет детали индексов в таблице users. Вы больше не должны видеть индекс idx_username в выводе.
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| users | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | NO |
| users | 1 | idx_city_username | 1 | city | A | 7 | NULL | NULL | YES | BTREE | | | NO |
| users | 1 | idx_city_username | 2 | username | A | 7 | NULL | NULL | | BTREE | | | NO |
+-------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
Идентификация неиспользуемых индексов
В реальных сценариях идентификация неиспользуемых индексов может быть сложной задачей. MySQL предоставляет несколько инструментов и методов для помощи в этой задаче:
- MySQL Enterprise Audit: Эта функция позволяет регистрировать все запросы, выполненные на вашем сервере. Затем вы можете анализировать журналы запросов, чтобы определить, какие индексы используются.
- Performance Schema: Performance Schema предоставляет подробную информацию о производительности сервера, включая использование индексов.
- Сторонние инструменты: Несколько сторонних инструментов могут помочь вам отслеживать использование индексов и выявлять неиспользуемые индексы.
Регулярно отслеживая использование индексов и удаляя неиспользуемые, вы можете повысить общую производительность вашей базы данных.
Теперь, когда мы завершили все шаги, выйдем из консоли MySQL:
exit;
Резюме
В этой лабораторной работе вы научились создавать одноколоночный индекс в MySQL для улучшения производительности запросов. Вы также научились использовать оператор EXPLAIN для анализа планов выполнения запросов и выявления узких мест в производительности. Кроме того, вы практиковались в создании составных индексов для многоколоночных запросов и удалении неиспользуемых индексов для поддержания эффективности базы данных. Понимание и эффективное использование индексов является фундаментальным навыком для оптимизации производительности базы данных.


