
Введение
Суть Docker заключается в использовании LXC для достижения функциональности, аналогичной виртуальным машинам, тем самым экономя аппаратные ресурсы и предоставляя пользователям больше вычислительных ресурсов. Этот проект объединяет C++ с технологиями Namespace и Control Group Linux для реализации простого Docker-контейнера.
В конце мы добьемся следующих функциональностей для контейнера:
- Независимая файловая система
- Поддержка сетевого доступа
👀 Предварительный просмотр
$ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
$ sudo./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
🎯 Задачи
В этом проекте вы научитесь:
- Как создать простой Docker-контейнер с использованием C++ и технологии Namespace Linux
- Как реализовать независимую файловую систему для контейнера
- Как обеспечить сетевой доступ для контейнера
🏆 Достижения
После завершения этого проекта вы сможете:
- Создать простой Docker-контейнер с использованием C++ и технологии Namespace Linux
- Реализовать независимую файловую систему для контейнера
- Обеспечить сетевой доступ для контейнера
Технология Linux Namespace
В C++ мы знакомы с ключевым словом namespace. В C++ каждый пространство имен изолирует одинаковые имена в разных частях кода, поэтому, если имена пространств имен различны, имена элементов кода в этих пространствах имен могут быть одинаковыми, тем самым решая проблему конфликтов имен в коде.
Linux Namespace, с другой стороны, представляет собой технологию, предоставляемую ядром Linux, которая обеспечивает решение для изоляции ресурсов для приложений, аналогичное концепции namespace в C++. Мы знаем, что такие ресурсы, как PID, IPC и сеть, должны быть управляемыми операционной системой, но Linux Namespace может сделать эти ресурсы не глобальными и назначить их определенным пространствам имен.
В мире технологии Docker мы часто слышим такие термины, как LXC и виртуализация на уровне операционной системы (OS-level virtualization), и LXC использует технологию Namespace для достижения изоляции ресурсов между различными контейнерами. Используя технологию Namespace, процессы в разных контейнерах принадлежат разным пространствам имен и не мешают друг другу. В целом, технология Namespace предоставляет легковесную форму виртуализации, которая позволяет нам управлять системными свойствами с разных точек зрения.
В Linux самой важной системной функцией, связанной с Namespace, является clone(). Цель clone() - ограничить потоки определенному пространству имен при создании процессов.
Инкапсуляция системных вызовов
Поскольку системные вызовы Linux написаны на языке C, нам нужно написать код на C++ для нашего проекта. Чтобы сохранить единый стиль кодирования, полностью на C++, мы сначала инкапсулируем эти необходимые API в C++-форму, что также позволит нам более глубоко понять, как эти API используются.
Мы будем использовать следующие API:
clone()
Системные вызовы clone и fork используются для создания процессов в Linux. Однако fork представляет собой всего лишь часть clone. Разница между ними заключается в том, что fork создает только дочерний процесс, являющийся точной копией родительского процесса, в то время как clone более мощный, так как позволяет выбирать, какие ресурсы родительского процесса копировать в дочерний процесс. Ресурсы, которые не копируются, общие между процессами через копирование указателей (arg). Конкретные ресурсы для копирования можно указать с помощью flags, и функция возвращает PID дочернего процесса.
Мы знаем, что процесс состоит из четырех основных элементов:
- Фрагмент кода для выполнения
- Приватное стековое пространство для процесса
- Блок управления процессом (PCB - Process Control Block)
- Пространства имен, специфичные для процесса
Первые два элемента соответствуют параметрам fn и child_stack в clone. Блок управления процессом контролируется ядром, и нам не нужно об этом беспокоиться. Поэтому пространства имен связаны с параметром flags. Чтобы достичь нашей цели создания Docker-контейнера, основные параметры, которые нам нужны, следующие:
Классификация пространства имен Параметр системного вызова
UTS CLONE_NEWUTS
Mount CLONE_NEWNS
PID CLONE_NEWPID
Network CLONE_NEWNET
По названиям можно видеть, что CLONE_NEWNS обеспечивает монтирование, связанное с файловой системой, для копирования и ресурсов, связанных с файловой системой, CLONE_NEWUTS позволяет устанавливать имя хоста, CLONE_NEWPID обеспечивает поддержку независимого пространства процессов, а CLONE_NEWNET обеспечивает поддержку, связанную с сетью.
execv()
int execv(const char *path, char *const argv[]);
execv выполняет исполняемый файл, указанный в path. Этот системный вызов позволяет нашему дочернему процессу выполнить /bin/bash, чтобы контейнер продолжал работать.
sethostname()
int sethostname(const char *name, size_t len);
Как следует из названия, этот системный вызов используется для установки имени хоста. Стоит упомянуть, что, так как строки в стиле C используют указатели и длина строки не может быть определена непосредственно изнутри, параметр len используется для получения длины строки.
chdir()
int chdir(const char *path);
Мы знаем, что любая программа запускается в определенной директории. Когда нам нужно получить доступ к ресурсам, мы можем использовать относительные пути вместо абсолютных для доступа к соответствующим ресурсам. chdir предоставляет нам возможность изменить рабочую директорию нашей программы, что может быть использовано для определенных целей.
chroot()
Этот системный вызов используется для изменения корневой директории:
int chroot(const char *path);
mount()
Этот системный вызов используется для монтирования файловых систем, аналогично команде mount.
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
Создание подпроцесса контейнера
Войдите в директорию ~/project и создайте файл с именем docker.hpp. В этом файле мы сначала создадим пространство имен docker, которое может быть вызвано нашим внешним кодом.
//
// docker.hpp
// cpp_docker
//
// Заголовочные файлы для системных вызовов
#include <sys/wait.h> // waitpid
#include <sys/mount.h> // mount
#include <fcntl.h> // open
#include <unistd.h> // execv, sethostname, chroot, fchdir
#include <sched.h> // clone
// Стандартная библиотека C
#include <cstring>
// Стандартная библиотека C++
#include <string> // std::string
#define STACK_SIZE (512 * 512) // Определение размера пространства дочернего процесса
namespace docker {
//.. здесь начинается магия Docker
}
Начнем с определения некоторых переменных для улучшения читаемости:
// Определено внутри пространства имен `docker`
typedef int proc_status;
proc_status proc_err = -1;
proc_status proc_exit = 0;
proc_status proc_wait = 1;
Перед определением класса контейнера давайте проанализируем параметры, необходимые для создания контейнера. Пока мы не будем учитывать настройки, связанные с сетью. Чтобы создать Docker-контейнер из образа, нам нужно только указать имя хоста и местоположение образа. Поэтому:
// Конфигурация запуска Docker-контейнера
typedef struct container_config {
std::string host_name; // Имя хоста
std::string root_dir; // Корневая директория контейнера
} container_config;
Теперь определим класс container и заставим его выполнять необходимую конфигурацию контейнера в конструкторе:
class container {
private:
// Улучшает читаемость
typedef int process_pid;
// Стек дочернего процесса
char child_stack[STACK_SIZE];
// Конфигурация контейнера
container_config config;
public:
container(container_config &config) {
this->config = config;
}
};
Перед тем, как думать о конкретных методах класса container, давайте сначала подумаем, как мы будем использовать этот класс container. Для этого создадим файл main.cpp в папке ~/project:
//
// main.cpp
// cpp_docker
//
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
// Настроить контейнер
//...
docker::container container(config);// Создать контейнер на основе конфигурации
container.start(); // Запустить контейнер
std::cout << "stop container..." << std::endl;
return 0;
}
В main.cpp, чтобы запуск контейнера был лаконичным и понятным, предположим, что контейнер запускается с помощью метода start(). Это дает основу для написания файла docker.hpp позже.
Теперь вернемся к docker.hpp и реализуем метод start():
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// Выполнить соответствующую конфигурацию для контейнера
//...
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE, // Переместиться в нижнюю часть стека
SIGCHLD, // Отправить сигнал родительскому процессу при выходе дочернего процесса
this);
waitpid(child_pid, nullptr, 0); // Ждать завершения дочернего процесса
}
Метод docker::container::start() использует системный вызов clone() в Linux. Чтобы передать экземпляр объекта docker::container в функцию обратного вызова setup, мы можем передать его с помощью четвертого аргумента clone(). Здесь мы передаем указатель this.
Что касается функции setup, мы создаем для нее лямбда-выражение. В C++ лямбда-выражение с пустым списком захвата может быть передано как указатель на функцию. Поэтому setup становится функцией обратного вызова, передаваемой в clone().
Вы также можете использовать статическую член-функцию, определенную в классе, вместо лямбда-выражения, но это сделает код менее элегантным.
В конструкторе этого класса container мы определяем функцию обработки дочернего процесса, которая будет вызвана системным вызовом clone(). Мы используем typedef для изменения возвращаемого типа этой функции на proc_status. Когда эта функция возвращает proc_wait, дочерний процесс, склонированный с помощью clone(), будет ждать завершения.
Однако этого недостаточно, так как мы не выполнили никакой конфигурации внутри процесса. В результате наша программа завершится сразу же, так как после запуска процесса не остается ничего другого, кроме выхода. Как мы знаем, в Docker, чтобы держать контейнер запущенным, мы можем использовать:
docker run -it ubuntu:14.04 /bin/bash
Это связывает STDIN с /bin/bash контейнера. Поэтому давайте добавим метод start_bash() в класс docker::container:
private:
void start_bash() {
// Безопасно преобразовать C++ std::string в строку в стиле C char *
// Начиная с C++14, такое прямое присваивание запрещено: `char *str = "test";`
std::string bash = "/bin/bash";
char *c_bash = new char[bash.length()+1]; // +1 для '\0'
strcpy(c_bash, bash.c_str());
char* const child_args[] = { c_bash, NULL };
execv(child_args[0], child_args); // Выполнить /bin/bash в дочернем процессе
delete []c_bash;
}
И вызовем его внутри setup:
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->start_bash();
return proc_wait;
}
Теперь мы можем увидеть следующие действия:
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $./a.out
...start container
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ mkdir test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ ls
a.out docker.hpp main.cpp test
labex@iZj6cboigynrxh4mn2oo16Z:~/project$ exit
exit
stop container...
В приведенных выше шагах мы сначала проверили текущее hostname, скомпилировали написанный нами код, запустили его и вошли в наш контейнер. Мы можем видеть, что после входа в контейнер приглашение bash изменилось, как и ожидалось.
Однако легко заметить, что это не то, что мы хотели, так как это точно такое же, как на нашей хост-системе. Любые операции, выполненные внутри этого "контейнера", будут напрямую влиять на хост-систему.
Вот где мы вводим необходимые пространства имен в API clone.
Разрешение контейнеру иметь собственный hostname
Как упоминалось ранее в разделе о системных вызовах, установка имени хоста для дочернего процесса с помощью системного вызова довольно проста. Поэтому мы создаем приватный метод для класса docker::container:
private:
// Установить имя хоста контейнера
void set_hostname() {
sethostname(this->config.host_name.c_str(), this->config.host_name.length());
}
Мы также вносим изменения в метод start() следующим образом:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
// Настроить контейнер
_this->set_hostname();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // Добавить UTS-пространство имен
SIGCHLD, // Отправить сигнал родительскому процессу при выходе дочернего процесса
this);
waitpid(child_pid, nullptr, 0); // Ждать завершения дочернего процесса
}
В файле main.cpp мы настраиваем имя хоста:
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
……
Теперь перекомпилируем код:
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $./a.out
...start container
stop container...
Можно заметить, что наш контейнер сразу же завершает работу. Это происходит потому, что при использовании пространства имен наша программа требует привилегий суперпользователя. Поэтому нам нужно запустить программу с помощью sudo:
labex:project/ $ sudo./a.out
...start container
root@labex:/home/labex/project## hostname
labex
root@labex:/home/labex/project## exit
exit
stop container...
labex:project/ $ hostname
iZj6cboigynrxh4mn2oo16Z
Однако это все еще не дает желаемого эффекта контейнера, так как, как можно увидеть по команде ls, мы по-прежнему можем получить доступ к директории хост-машины.
Разрешение контейнеру использовать собственную файловую систему
В технологии Docker контейнеры создаются на основе образов. Поскольку мы хотим реализовать собственный контейнер, естественно, что нам нужно создать его на основе образа. К счастью, мы подготовили для вас Docker-образ. Вы можете получить его, загрузив по ссылке:
cd ~/project
wget --header="User-Agent: Mozilla/5.0" https://file.labex.io/lab/171925/docker-image.tar
Затем извлеките его в папку ~/project/labex:
mkdir labex
tar -xf docker-image.tar --directory labex/
rm docker-image.tar
Возможно, при извлечении вы столкнетесь с некоторыми ошибками. Это происходит потому, что в среде создание некоторых файлов извне запрещено. Это не влияет на реализацию нашего собственного контейнера, поэтому можно проигнорировать эти ошибки.
tar: dev/agpgart: Cannot mknod: Operation not permitted
tar: dev/audio: Cannot mknod: Operation not permitted
tar: dev/audio1: Cannot mknod: Operation not permitted
tar: dev/audio2: Cannot mknod: Operation not permitted
tar: dev/audio3: Cannot mknod: Operation not permitted
tar: dev/audioctl: Cannot mknod: Operation not permitted
……
После завершения извлечения в папке labex мы увидим практически полную структуру Linux-директории:
labex:project/ $ ls labex
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Теперь мы хотим, чтобы docker::container перешел в эту директорию и использовал ее как корневую, скрывая внешний доступ дочернего процесса при запуске:
private:
// Установить корневую директорию
void set_rootdir() {
// Системный вызов chdir, переход в определенную директорию
chdir(this->config.root_dir.c_str());
// Системный вызов chroot, установка корневой директории, так как мы
// уже перешли в текущую директорию ранее
// мы можем просто использовать текущую директорию как корневую
chroot(".");
}
Затем заполните соответствующую конфигурацию в main.cpp:
#include "docker.hpp"
#include <iostream>
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
……
И включите CLONE_NEWNS в вызове clone(), чтобы активировать Mount Namespace (пространство имен монтирования):
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack+STACK_SIZE,
CLONE_NEWUTS| // UTS-пространство имен
CLONE_NEWNS| // Пространство имен монтирования
SIGCHLD, // Сигнал отправляется родительскому процессу при выходе дочернего процесса
this);
waitpid(child_pid, nullptr, 0); // Ждать завершения дочернего процесса
}
Теперь перекомпилируем код:
labex:project/ $ g++ main.cpp -std=c++11
labex:project/ $ sudo./a.out
...start container
root@labex:/## ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@labex:/## hostname
labex
При выполнении команды ls можно увидеть, что дочерний процесс теперь работает в полноценной Linux-директории.
Разрешение контейнеру иметь свою собственную систему процессов
Однако остается еще одна проблема. Если мы используем команды, такие как ps или top, мы по-прежнему можем увидеть все процессы в родительском процессе. Это не то, что мы хотим. Например, в выводе команды ps мы можем увидеть a.out, и значение идентификатора процесса (PID) также очень велико.
Для решения этой проблемы нам нужно ввести PID Namespace (пространство имен PID), чтобы изолировать пространство PID дочерних процессов от родительского процесса.
private:
// Настроить независимое пространство имен процессов
void set_procsys() {
// Монтировать файловую систему proc
mount("none", "/proc", "proc", 0, nullptr);
mount("none", "/sys", "sysfs", 0, nullptr);
}
Аналогично, мы все еще должны добавить этот фрагмент кода в метод start(), введя CLONE_NEWPID:
void start() {
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
_this->start_bash();
return proc_wait;
};
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // UTS-пространство имен
CLONE_NEWNS| // Пространство имен монтирования
CLONE_NEWPID| // Пространство имен PID
SIGCHLD, // Сигнал отправляется родительскому процессу при выходе дочернего процесса
this);
waitpid(child_pid, nullptr, 0); // Ждать завершения дочернего процесса
}
Теперь, когда мы снова скомпилируем и запустим программу, мы увидим, что контейнер имеет свое собственное независимое пространство процессов:
На этом этапе мы использовали технологию Namespace в Linux для изоляции ресурсов в дочерних процессах и предоставления нашему Docker-контейнеру собственного пространства процессов и файловой системы.
Однако контейнер все еще не может получить доступ к сети, и мы даже можем получить доступ к сетевым устройствам хост-машины с помощью команды ifconfig. Это не то, что мы хотим. Далее мы будем дополнительно улучшать контейнер, чтобы он стал более похожим на полноценный контейнер, и предоставим поддержку для доступа к сети.
Принципы сетевого взаимодействия Docker
Ранее мы получили предварительное представление о том, как Docker реализует закрытый контейнер. Однако мы также обнаружили, что реализованный нами Docker-контейнер не поддерживает доступ к сети, и различные запущенные контейнеры не могут взаимодействовать друг с другом.
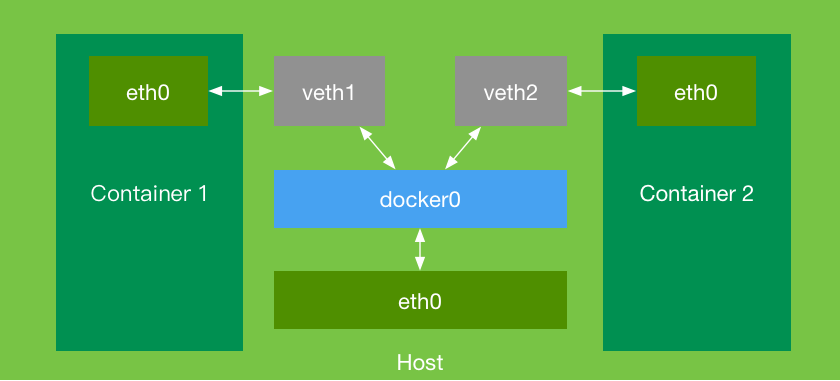
Принцип сетевого взаимодействия между Docker-контейнерами реализуется с помощью моста под названием 'docker0'. Два контейнера, 'container1' и 'container2', имеют свои собственные сетевые устройства 'eth0'. Все сетевые запросы будут перенаправляться через 'eth0'. Поскольку контейнеры работают в дочерних процессах, чтобы обеспечить взаимодействие между их интерфейсами 'eth0', необходимо создать пару сетевых устройств 'veth1' и 'veth2' и добавить их в мост 'docker0'. Это позволяет мосту безусловно перенаправлять и маршрутизировать сетевые запросы, сгенерированные интерфейсами 'eth0' внутри контейнера, обеспечивая взаимодействие между контейнерами.
Поэтому, чтобы наши контейнеры имели возможность сетевого взаимодействия, сначала нужно создать мост, который они смогут использовать. Для удобства мы будем напрямую использовать существующий в среде мост 'docker0'.
Подготовка к созданию сети
Использование нативного API Linux для управления сетью - очень сложная задача, которая также включает множество операций на языке C. Чтобы сосредоточиться больше на программировании на C++, здесь представлены уже реализованные "колеса", которые облегчат вам управление сетью.
Перейдите в директорию
/tmp, и мы предоставили вам четыре файла:network.h,nl.h,network.cиnl.c.
Скопируйте эти четыре файла в директорию ~/project:
cp /tmp/network.h /tmp/nl.h /tmp/network.c /tmp/nl.c ~/project/
Код последних трех файлов взят из набора инструментов LXC. Однако этот код написан на языке C. Поскольку начиная с C++11 C++ и C больше не полностью совместимы, чтобы C++ мог корректно вызывать этот код, нам нужно иметь представление о смешанном программировании на C и C++.
Во - первых, мы знаем, что преобразование исходного кода в исполняемые файлы не происходит напрямую, а проходит через несколько этапов: препроцессинг, компиляция, ассемблирование и связывание. Обычно мы используем команду g++ main.cpp, чтобы выполнить все эти этапы за один раз.
Однако, когда проект становится больше и количество исходных файлов увеличивается, нецелесообразно перекомпилировать весь проект из - за небольшого изменения. В таком случае мы можем сначала скомпилировать код в файлы .o, а затем выполнить связывание. Это также позволяет нам одновременно компилировать файлы, скомпилированные из кода на языке C, и исходный код на C++.
C++ и C имеют разные методы компиляции и обработки, поэтому, когда мы хотим скомпилировать набор кода на языке C, нам нужно использовать макрос __cplusplus и extern "C".
В файле network.h хранятся объявления соответствующих интерфейсов из network.c. Если мы закомментируем следующие части:
// #ifdef __cplusplus
// extern "C"
// {
// #endif
#include <sys/types.h>
int netdev_set_flag(const char *name, int flag);
……
void new_hwaddr(char *hwaddr);
// #ifdef __cplusplus
// }
// #endif
Используя gcc, напрямую скомпилируем их в файлы .o:
gcc -c network.c nl.c
А затем используем следующий код:
// test.cpp
#include "network.h"
int main() {
new_hwaddr(nullptr);
return 0;
}
Для компиляции и тестирования:
g++ test.cpp network.o nl.o -std=c++11
Мы увидим, что компиляция завершается с ошибкой undefined reference to 'new_hwaddr(char*)'.
/usr/bin/ld: /tmp/ccz4DEEy.o: in function `main':
test.cpp:(.text+0xe): undefined reference to `new_hwaddr(char*)'
collect2: error: ld returned 1 exit status
Другими словами:
Когда мы хотим скомпилировать и связать библиотеки на языке C с кодом на C++, нам нужно обернуть соответствующие объявления интерфейсов:
#ifdef __cplusplus
extern "C"
{
#endif
// Функции интерфейса на языке C
#ifdef __cplusplus
}
#endif
В этот момент мы снова компилируем network.c и nl.c в файлы .o, а затем компилируем *.o вместе с test.cpp, и компиляция проходит успешно.
Создание контейнерной сети
На основе предыдущего раздела о сетевом принципе Docker можно сформулировать следующие шаги для того, чтобы созданные нами контейнеры поддерживали сеть:
- Создать пару виртуальных сетевых устройств veth1/veth2;
- Установить MAC - адрес veth1;
- Добавить veth1 в мост labex0;
- Активировать veth1;
- Создать дочерний процесс;
- Переместить veth2 в сетевое пространство имен (network namespace) дочернего процесса и переименовать его в eth0;
- Подождать завершения дочернего процесса;
- Удалить сетевые устройства veth1 и veth2;
Поэтому необходимо дополнительно оптимизировать логику метода start().
Сначала нужно добавить сетевые настройки в docker::container_config:
Подключить заголовочные файлы:
#include <net/if.h> // if_nametoindex
#include <arpa/inet.h> // inet_pton
#include "network.h"
Добавить настройки docker::container_config:
// Конфигурация запуска Docker - контейнера
typedef struct container_config {
std::string host_name; // Имя хоста
std::string root_dir; // Корневая директория контейнера
std::string ip; // IP - адрес контейнера
std::string bridge_name; // Имя моста
std::string bridge_ip; // IP - адрес моста
} container_config;
Затем установить IP - адрес контейнера, имя моста, в который добавить (docker0), и IP - адрес моста в main.cpp:
int main(int argc, char** argv) {
std::cout << "...start container" << std::endl;
docker::container_config config;
config.host_name = "labex";
config.root_dir = "./labex";
// Настройка сетевых параметров
config.ip = "192.168.0.100"; // IP - адрес контейнера
config.bridge_name = "docker0"; // Мост хоста
config.bridge_ip = "192.168.0.1"; // IP - адрес моста хоста
docker::container container(config);
container.start();
std::cout << "stop container..." << std::endl;
return 0;
}
Переработаем метод start() на основе логики загрузки сетевых устройств, описанной выше:
private:
// Сохранить сетевые устройства контейнера для удаления
char *veth1;
char *veth2;
public:
void start() {
char veth1buf[IFNAMSIZ] = "labex0X";
char veth2buf[IFNAMSIZ] = "labex0X";
// Создать пару сетевых устройств, одно из которых будет загружено на хост, а другое будет перемещено в контейнер в дочернем процессе
veth1 = lxc_mkifname(veth1buf); // API lxc_mkifname требует добавления хотя бы одной "X" в имя виртуального сетевого устройства для поддержки случайного создания виртуальных сетевых устройств
veth2 = lxc_mkifname(veth2buf); // Это необходимо для правильного создания сетевых устройств. Подробности см. в реализации lxc_mkifname в network.c
lxc_veth_create(veth1, veth2);
// Установить MAC - адрес veth1
setup_private_host_hw_addr(veth1);
// Добавить veth1 в мост
lxc_bridge_attach(config.bridge_name.c_str(), veth1);
// Активировать veth1
lxc_netdev_up(veth1);
// Некоторые настройки перед созданием контейнера
auto setup = [](void *args) -> int {
auto _this = reinterpret_cast<container *>(args);
_this->set_hostname();
_this->set_rootdir();
_this->set_procsys();
// Настройка сети внутри контейнера
//...
_this->start_bash();
return proc_wait;
};
// Создать контейнер с использованием clone
process_pid child_pid = clone(setup, child_stack,
CLONE_NEWUTS| // UTS - пространство имен
CLONE_NEWNS| // Пространство имен монтирования
CLONE_NEWPID| // Пространство имен PID
CLONE_NEWNET| // Сетевое пространство имен
SIGCHLD, // Дочерний процесс отправит сигнал родительскому процессу при выходе
this);
// Переместить veth2 в контейнер и переименовать его в eth0
lxc_netdev_move_by_name(veth2, child_pid, "eth0");
waitpid(child_pid, nullptr, 0); // Подождать завершения дочернего процесса
}
~container() {
// Не забыть удалить созданные виртуальные сетевые устройства при выходе
lxc_netdev_delete_by_name(veth1);
lxc_netdev_delete_by_name(veth2);
}
Примечание: Добавить
CLONE_NEWNETв вызовclone.
Из вышеперечисленных шагов видно, что после создания сетевых устройств и во время создания дочернего процесса необходимо выполнить соответствующие настройки внутри контейнера в сочетании с внешними сетевыми устройствами:
- Активировать устройство
loвнутри контейнера; - Настроить IP - адрес
eth0; - Активировать
eth0; - Установить шлюз;
- Установить MAC - адрес
eth0;
private:
void set_network() {
int ifindex = if_nametoindex("eth0");
struct in_addr ipv4;
struct in_addr bcast;
struct in_addr gateway;
// Функция преобразования IP - адресов, которая преобразует IP - адреса между точечно - десятичным и двоичным представлениями
inet_pton(AF_INET, this->config.ip.c_str(), &ipv4);
inet_pton(AF_INET, "255.255.255.0", &bcast);
inet_pton(AF_INET, this->config.bridge_ip.c_str(), &gateway);
// Настройка IP - адреса eth0
lxc_ipv4_addr_add(ifindex, &ipv4, &bcast, 16);
// Активировать lo
lxc_netdev_up("lo");
// Активировать eth0
lxc_netdev_up("eth0");
// Установить шлюз
lxc_ipv4_gateway_add(ifindex, &gateway);
// Установить MAC - адрес eth0
char mac[18];
new_hwaddr(mac);
setup_hw_addr(mac, "eth0");
}
Затем вызвать этот метод в setup контейнера:
……
_this->set_procsys();
_this->set_network(); // Сочетание для настройки сети внутри контейнера
_this->start_bash();
return proc_wait;
На этом этапе, так как мы начали использовать скомпилированные файлы network.o и nl.o, напишем очень простой Makefile:
C = gcc
CXX = g++
C_LIB = network.c nl.c
C_LINK = network.o nl.o
MAIN = main.cpp
LD = -std=c++11
OUT = docker-run
all:
make container
container:
$(C) -c $(C_LIB)
$(CXX) $(LD) -o $(OUT) $(MAIN) $(C_LINK)
clean:
rm *.o $(OUT)
Примечание: Команда в Makefile должна начинаться с символа табуляции, а не пробела. Это связано с тем, что интерпретатор Markdown преобразует символ табуляции в четыре пробела. При написании Makefile обязательно используйте символ табуляции, а не четыре пробела. В противном случае Makefile выдаст ошибку "Makefile:10: *** missing separator. Stop."
Скомпилируем и выполним программу снова, а затем войдем в контейнер. Можно использовать ifconfig для проверки сети:
labex:project/ $ make
make container
make[1]: Entering directory '/home/labex/project'
gcc -c network.c nl.c
g++ -std=c++11 -o docker-run main.cpp network.o nl.o
make[1]: Leaving directory '/home/labex/project'
labex:project/ $ sudo./docker-run
...start container
root@labex:/## ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3e:da:01:72
inet6 addr: fe80::dc15:18ff:fe43:53b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38 errors:0 dropped:0 overruns:0 frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:5744 (5.7 KB) TX bytes:726 (726.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Резюме
В рамках этого проекта мы постепенно добились следующего: включили файловую систему в контейнер и обеспечили доступ к внешним сетям.
Мы успешно создали базовый Docker - контейнер. Вы можете дополнительно оптимизировать этот контейнер, чтобы добиться более реалистичной эмуляции.


