
소개
Python 을 이용한 데이터 분석의 세계에 오신 것을 환영합니다! 본 실습에서는 Python 에서 가장 인기 있고 강력한 오픈 소스 데이터 조작 및 분석 라이브러리인 Pandas 를 소개합니다.
본 과정을 시작하기 전에 기본적인 Python 프로그래밍 기술을 갖추고 시스템 PATH 에 Python 이 올바르게 설정되어 있는지 확인해야 합니다. 아직 Python 을 배우지 않았다면 Python 학습 경로에서 시작할 수 있습니다. 또한, Pandas 작업에 필수적인 사전 요구 사항인 NumPy 가 설치되어 있어야 합니다. NumPy 를 배워야 한다면 NumPy 학습 경로를 살펴보세요.
Pandas 는 고성능의 사용하기 쉬운 데이터 구조와 데이터 분석 도구를 제공합니다. Pandas 의 두 가지 주요 데이터 구조는 Series(1 차원) 와 DataFrame(2 차원) 입니다.
본 실습에서는 시작에 필요한 기본적인 내용을 다룹니다. 다음을 수행하게 됩니다:
- 환경에 Pandas 가 설치되어 있는지 확인합니다.
- Python 스크립트로 Pandas 라이브러리를 가져옵니다.
- 첫 번째 Pandas
Series객체를 생성합니다. Series내의 데이터에 접근합니다.Series의 기본적인 속성을 검사합니다.
본 실습은 초보자를 대상으로 하며 Pandas 에 대한 사전 지식은 필요하지 않습니다. 시작해 봅시다!
pip 를 사용하여 Pandas 설치
이 단계에서는 pandas가 환경에 올바르게 설치되었는지 확인할 것입니다. LabEx 환경에는 시간을 절약하기 위해 Python 과 Pandas 가 사전 설치되어 있습니다. 이를 확인하고 버전을 확인할 수 있습니다.
설치된 Python 패키지의 세부 정보를 확인하려면 pip show 명령을 사용할 수 있습니다. pip는 Python 의 패키지 설치 프로그램입니다.
터미널을 열고 다음 명령을 실행하여 설치된 pandas 패키지에 대한 정보를 표시합니다:
pip show pandas
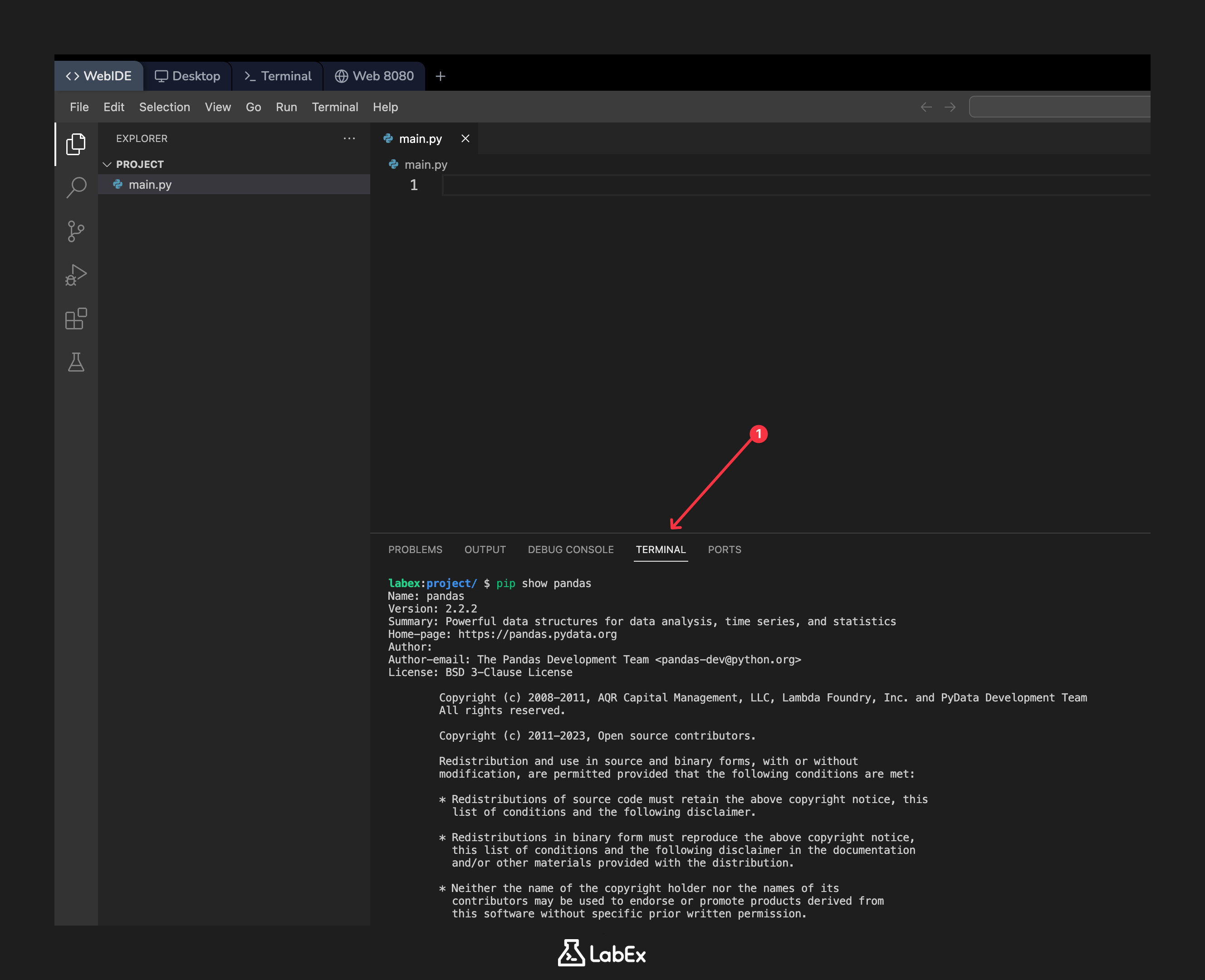
패키지의 이름, 버전, 요약 및 위치를 자세히 설명하는 출력이 표시되어야 합니다. 버전은 2.2.2 또는 유사해야 합니다.
Name: pandas
Version: 2.2.2
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author: The Pandas Development Team
Author-email: pandas-dev@python.org
License: BSD-3-Clause
Location: /usr/local/lib/python3.10/dist-packages
Requires: numpy, python-dateutil, pytz, tzdata
Required-by:
이를 통해 pandas를 Python 스크립트에서 사용할 준비가 되었음을 확인할 수 있습니다.
Pandas 를 pd 로 가져오기
이 단계에서는 Pandas 라이브러리를 가져오기 위한 첫 번째 Python 코드를 작성합니다. 관례적으로 Pandas 는 별칭 pd로 가져옵니다. 이렇게 하면 코드가 더 짧고 읽기 쉬워집니다.
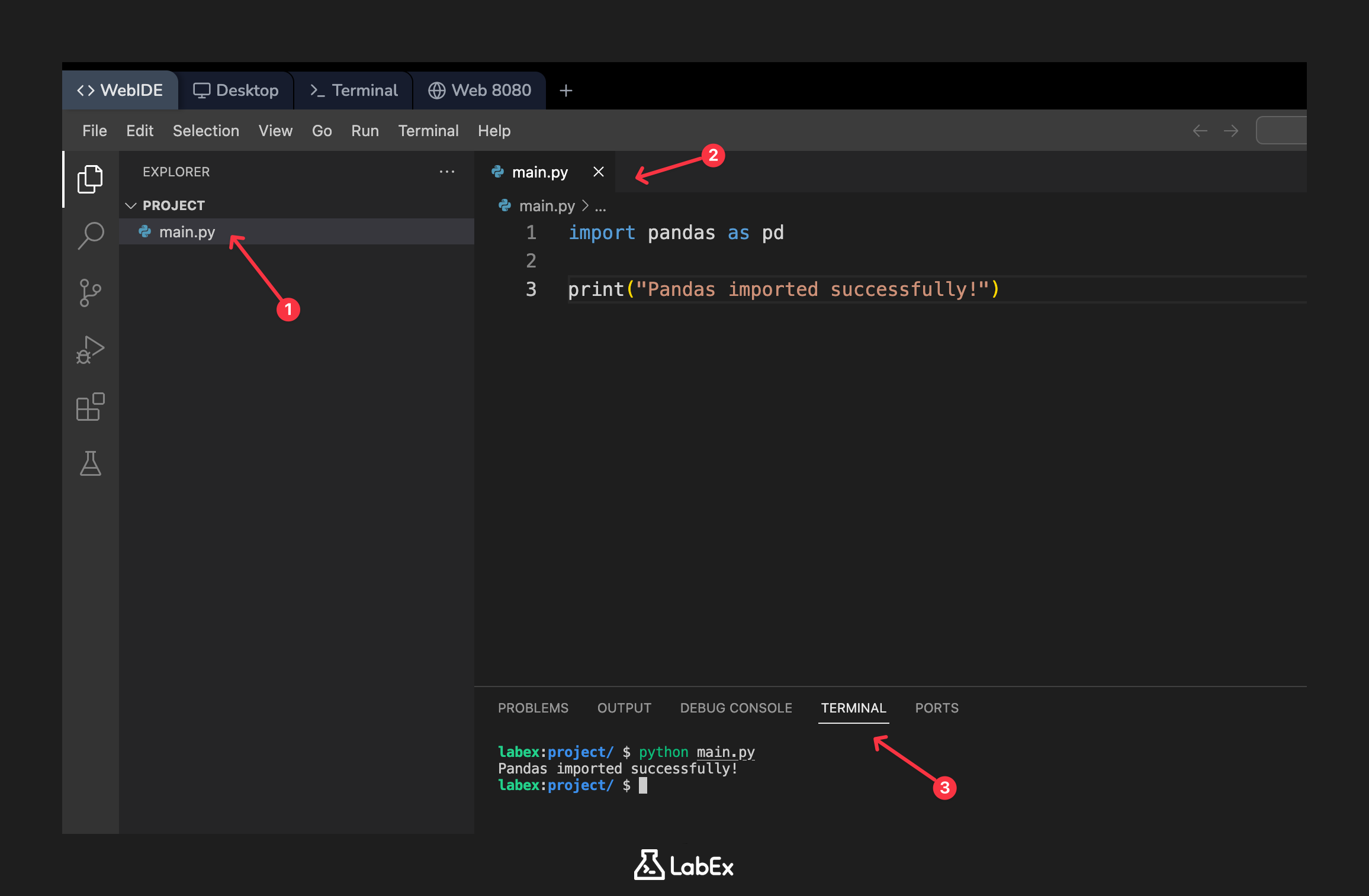
WebIDE 의 왼쪽 파일 탐색기에서 main.py라는 파일을 볼 수 있습니다. 이 파일은 여러분을 위해 생성되었습니다. 이 파일을 클릭하여 편집기에서 엽니다.
이제 main.py에 다음 코드를 추가하여 pandas 를 가져오고 확인 메시지를 출력합니다:
import pandas as pd
print("Pandas imported successfully!")
import pandas as pd: 이 줄은 Python 에게 Pandas 라이브러리를 로드하고pd라는 별칭을 부여하도록 지시합니다. 이제부터pd.를 사용하여 Pandas 함수 및 객체에 접근할 수 있습니다.print(...): 이것은 터미널에 출력을 표시하는 표준 Python 함수입니다.
스크립트를 실행하려면 터미널로 이동하여 다음 명령을 실행합니다:
python main.py
터미널에 확인 메시지가 출력되는 것을 볼 수 있습니다:
Pandas imported successfully!
이를 통해 Python 스크립트가 Pandas 라이브러리를 성공적으로 가져와 사용할 수 있음을 확인할 수 있습니다.
리스트에서 간단한 Series 생성
이 단계에서는 첫 번째 Pandas Series를 생성합니다. Series는 정수, 문자열 또는 부동 소수점과 같은 모든 데이터 유형을 보유할 수 있는 1 차원 배열과 유사한 객체입니다. Pandas 에서 데이터의 기본 구성 요소입니다.
Python 리스트를 pd.Series() 생성자에 전달하여 Series를 생성할 수 있습니다.
main.py 파일을 수정합니다. 이전 print 문을 다음 코드로 바꿔 Series 를 생성하고 출력합니다:
import pandas as pd
## 숫자로 이루어진 Python 리스트
data = [10, 20, 30, 40, 50]
## 리스트로부터 Pandas Series 생성
s = pd.Series(data)
## Series 출력
print(s)
제안: 위의 코드를 코드 편집기에 복사한 다음 각 코드 줄을 주의 깊게 읽어 기능을 이해하십시오. 추가 설명이 필요한 경우 "코드 설명" 버튼 👆를 클릭할 수 있습니다. Labby 와 상호 작용하여 개인화된 도움을 받을 수 있습니다.
data = [...]: 먼저 간단한 정수 Python 리스트를 정의합니다.s = pd.Series(data):pd(Pandas) 라이브러리에서Series생성자를 호출하고 리스트를 전달합니다. 이렇게 하면Series객체가 생성됩니다.
이제 터미널에서 스크립트를 다시 실행합니다:
python main.py
출력에는 Series가 표시됩니다. 왼쪽의 인덱스 (0-4) 와 오른쪽의 값 (10-50) 이라는 두 개의 열이 있음을 알 수 있습니다. 인덱스가 지정되지 않은 경우 Pandas 는 기본 정수 인덱스를 자동으로 생성합니다.
0 10
1 20
2 30
3 40
4 50
dtype: int64
인덱스로 Series 요소 접근하기
이 단계에서는 생성한 Series에서 개별 요소 또는 요소의 하위 집합에 접근하는 방법을 배웁니다. 데이터 접근은 데이터 분석의 기본적인 작업입니다. Python 리스트를 사용하는 것과 유사하게 인덱스를 사용하여 Series의 요소에 접근할 수 있습니다.
main.py를 수정하여 특정 요소에 접근하고 출력해 보겠습니다. 첫 번째 요소 (인덱스 0) 와 요소 슬라이스를 접근할 것입니다.
main.py 파일을 다음 코드로 업데이트합니다. 전체 Series 를 출력하는 줄 다음에 새로운 print 문을 추가합니다.
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
print("The full Series:")
print(s)
## 첫 번째 요소 (인덱스 0) 에 접근
print("\nFirst element:", s[0])
## 요소 슬라이스에 접근 (인덱스 1 부터 시작하여 인덱스 3 직전까지)
print("\nElements from index 1 to 2:")
print(s[1:3])
s[0]: 인덱스0에 있는 값인10을 검색합니다.s[1:3]: 이것을 슬라이싱이라고 합니다. 인덱스1부터 시작하여 인덱스3을 포함하지 않는 요소까지 검색합니다. 이렇게 하면 인덱스1과2의 요소가 얻어집니다.
스크립트를 실행하여 결과를 확인합니다:
python main.py
출력에는 전체 Series와 함께 접근한 특정 요소가 표시됩니다.
The full Series:
0 10
1 20
2 30
3 40
4 50
dtype: int64
First element: 10
Elements from index 1 to 2:
1 20
2 30
dtype: int64
Series 데이터 타입 및 shape 출력하기
이 단계에서는 Series의 두 가지 중요한 속성인 데이터 타입 (dtype) 과 형태 (shape) 를 검사하는 방법을 배웁니다. 이러한 속성을 이해하는 것은 디버깅 및 데이터 유효성 검사에 매우 중요합니다.
dtype: 이 속성은Series에 저장된 값의 데이터 타입을 알려줍니다 (예: 정수는int64, 부동 소수점 숫자는float64, 문자열은object).shape: 이 속성은Series의 차원을 나타내는 튜플을 반환합니다. 1 차원인Series의 경우,n이 요소의 개수일 때(n,)형태의 단일 값을 가진 튜플이 됩니다.
main.py를 업데이트하여 이 두 속성을 출력해 보겠습니다. 스크립트 끝에 다음 줄을 추가합니다:
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
## ... (이전 print 문은 제거하거나 유지할 수 있습니다)
## Series 의 데이터 타입 출력
print("\nData type:", s.dtype)
## Series 의 형태 (shape) 출력
print("Shape:", s.shape)
이제 마지막으로 스크립트를 실행합니다:
python main.py
출력에는 이제 Series의 데이터 타입과 형태가 포함됩니다.
Data type: int64
Shape: (5,)
이는 Series가 64 비트 정수를 포함하고 있으며 5 개의 요소를 가지고 있음을 나타냅니다.
요약
축하합니다! Pandas 에 대한 이 소개 실습을 성공적으로 완료했습니다.
이 실습에서는 이 강력한 라이브러리를 다루는 기본적인 첫 단계를 배웠습니다. 다음을 수행했습니다:
- 환경에서
pandas설치를 확인했습니다. - 표준 별칭
pd를 사용하여 Python 스크립트에pandas라이브러리를 가져왔습니다. - Python 리스트에서 기본적인 1 차원
Series를 생성했습니다. - 인덱싱 및 슬라이싱을 사용하여
Series에서 요소에 접근했습니다. dtype및shape속성을 검사하여Series의 구조와 데이터 타입을 이해했습니다.
이것들은 DataFrame과 같은 더 복잡한 데이터 구조로 이동하고 더 고급 데이터 분석 작업을 수행할 때 필요한 필수적인 구성 요소입니다. 계속 연습하세요!


