
はじめに
前のセクションでは、Go の配列について説明しました。しかし、配列には制限があります。一度宣言して初期化すると、その長さを変更することはできません。そのため、日常的なプログラミングにおいて配列が広く使われることはありません。対照的に、スライス(Slice)はより一般的に使用され、より柔軟なデータ構造を提供します。
学習ポイント:
- スライスの定義
- スライスの初期化
- スライスの操作(追加、削除、変更、検索)
- スライスの拡張
- スライスの切り出し(トランケーション)
- 多次元スライス
スライスとは何か
スライスは配列に似ており、同じデータ型の要素を保持するコンテナです。しかし、配列には制限があります。一度宣言して初期化すると、その長さを変更することはできません。配列にも用途はありますが、柔軟性に欠けます。そのため、日々のプログラミングではスライスの方がより一般的に使用されます。
Go において、スライスは配列を使用して実装されています。スライスは本質的に、長さを変更できる動的配列です。スライスでは、配列では不可能な要素の追加、削除、変更、検索といった操作を行うことができます。
スライスの定義
スライスの初期化構文は配列の構文と非常によく似ています。主な違いは、要素の長さを指定する必要がない点です。次のコードを見てみましょう。
// 長さ 5 の配列を宣言
var a1 [5]byte
// スライスを宣言
var s1 []byte
スライスは配列への参照である
int 型の配列を宣言した場合、配列の各要素のゼロ値は 0 になります。
しかし、スライスを宣言した場合、スライスのゼロ値は nil になります。これを確認するために、slice.go というファイルを作成してみましょう。
touch ~/project/slice.go
以下のコードを入力します。
package main
import "fmt"
func main() {
var a [3]int
var s []int
fmt.Println(a[0] == 0) // true
fmt.Println(s == nil) // true
}
go run slice.go
コードを実行すると、以下の出力が表示されます。
true
true
ここでは配列 a とスライス s を作成しました。配列 a の最初の要素が 0 であるか、そしてスライス s が nil であるかを比較・確認しています。
見ての通り、スライスを宣言したときのゼロ値は nil です。これは、スライス自体がデータを保存しているのではなく、配列を参照しているだけだからです。スライスは、基底となる配列構造を指し示しています。
スライスのデータ構造
スライスは複合データ型であり、構造体(struct)としても知られています。これは、異なる型のフィールドで構成される複合型です。スライスの内部構造は、ポインタ、長さ(length)、容量(capacity)の 3 つの要素で構成されています。
type slice struct {
elem *type
len int
cap int
}
前述の通り、この構造体は基底となる配列を参照します。elem ポインタは配列の最初の要素を指し、type は参照される配列要素の型です。
len と cap はそれぞれスライスの長さと容量を表します。len() 関数と cap() 関数を使用して、スライスの長さと容量を取得できます。
以下の図は、スライスが int 型の基底配列を参照しており、長さが 5、容量が 5 である状態を示しています。
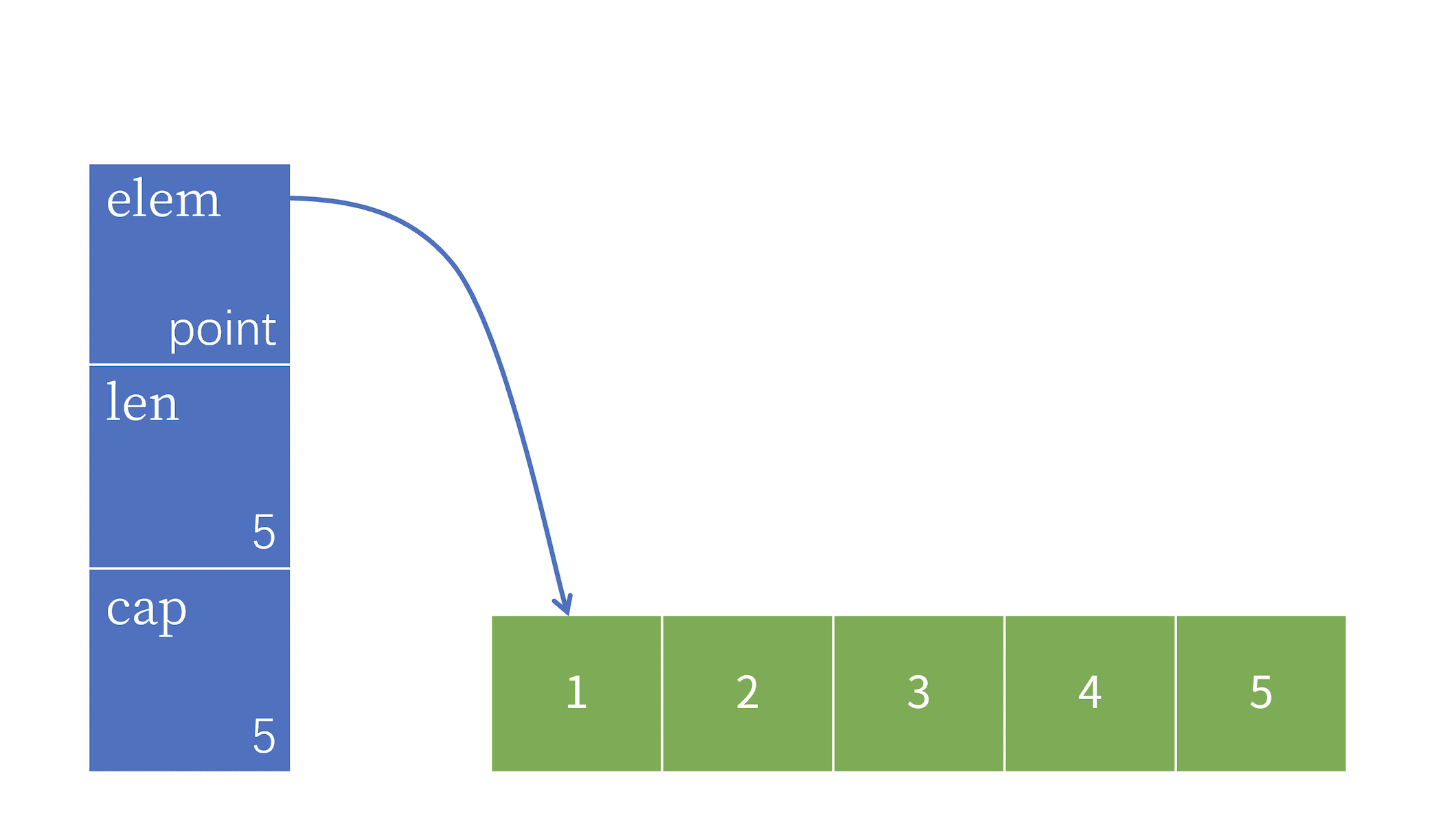
新しいスライスを定義すると、elem ポインタはゼロ値(つまり nil)に初期化されます。ポインタの概念については後の実験で紹介しますが、現時点では、ポインタが値のメモリ番地を指し示すものであると理解しておいてください。上の図では、elem ポインタは基底配列の最初の要素のアドレスを指しています。
スライスの操作:追加、削除、変更、検索
配列またはスライスの切り出し(トランケーション)
スライスの基底構造は配列であるため、配列の指定した範囲を抽出してスライスの参照先とすることができます。次のコードセグメントでこれを確認しましょう。
package main
import "fmt"
func main() {
// 長さ 10 の整数配列を定義
a := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 空のスライスを宣言
var s1 []int
fmt.Println("Slice s1 is empty:", s1 == nil)
// 配列の切り出しを使用してスライスを取得
s1 = a[1:5]
s2 := a[2:5]
s3 := a[:]
fmt.Println("Slice s1, s2, and s3 are empty:", s1 == nil, s2 == nil, s3 == nil)
fmt.Println("Elements in array a:", a)
fmt.Println("Elements in slice s1:", s1)
fmt.Println("Elements in slice s2:", s2)
fmt.Println("Elements in slice s3:", s3)
}
出力は以下の通りです。
Slice s1 is empty: true
Slice s1, s2, and s3 are empty: false false false
Elements in array a: [0 1 2 3 4 5 6 7 8 9]
Elements in slice s1: [1 2 3 4]
Elements in slice s2: [2 3 4]
Elements in slice s3: [0 1 2 3 4 5 6 7 8 9]
このプログラムでは、まず配列 a を宣言して初期化し、次に配列の切り出し(トランケーション)を使用して配列の一部を空のスライス s1 に割り当てています。これにより、新しいスライスが作成されます。
a[1:5] は、配列からスライスを作成することを表します。スライスの範囲は、配列 a のインデックス 1 からインデックス 5 までですが、5 番目の要素は含まれません。
注意: プログラミング言語では、最初の要素のインデックスは 1 ではなく 0 です。同様に、配列の 2 番目の要素のインデックスは 1 になります。
:= 演算子を使用して、切り出した配列を直接スライス s2 に代入しています。s3 も同様ですが、範囲が指定されていないため、配列のすべての要素を切り出します。
下の図は切り出しのイメージです。スライスの緑色の部分は、青色の配列への参照を表していることに注意してください。言い換えれば、両者は同じ基底配列 a を共有しています。
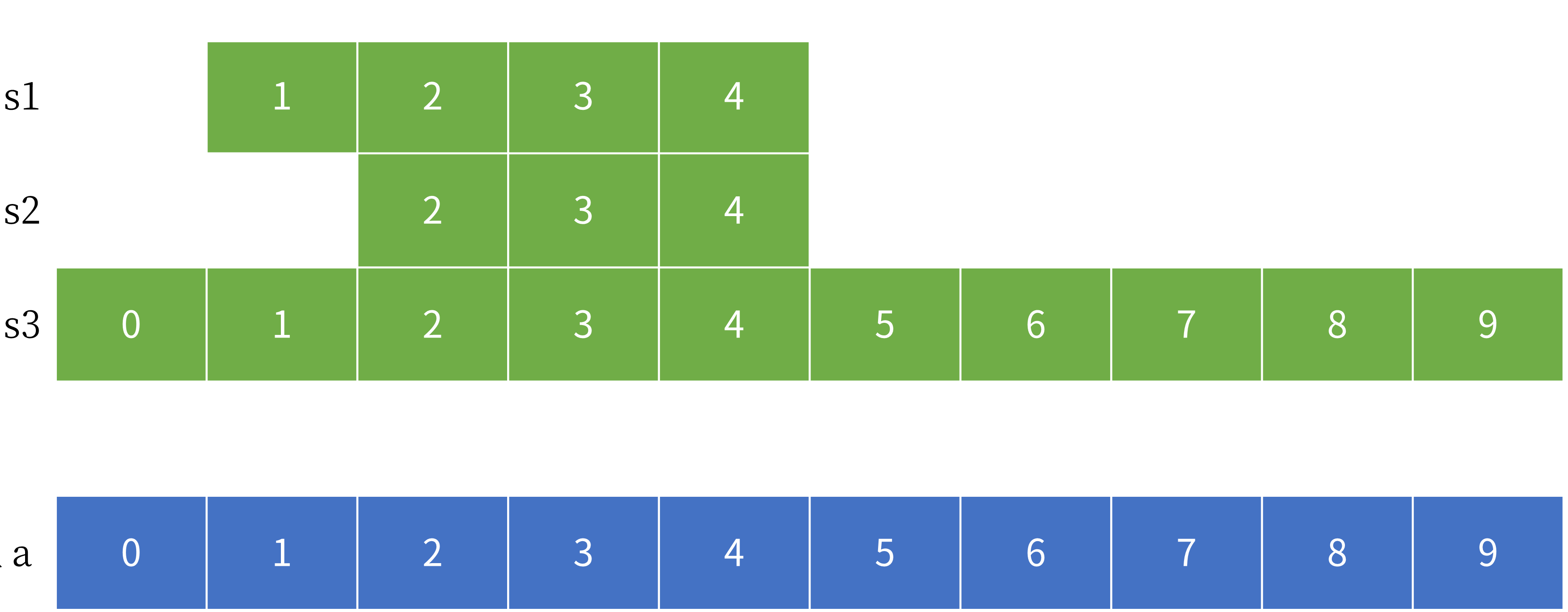
スライスの切り出し構文は以下の通りです。
[開始位置:終了位置]
開始位置 と 終了位置 はどちらもオプションの引数です。配列のすべての要素を取得したい場合は、両方の引数を省略できます。これは前述のプログラムの s3 := a[:] で示されています。
特定のインデックス以降のすべての要素を取得したい場合は、終了位置 パラメータを省略できます。例えば、a1[3:] はインデックス 3 から始まるすべての要素を取得します。
特定のインデックスより前のすべての要素を取得したい場合は、開始位置 パラメータを省略できます。例えば、a1[:4] はインデックス 0 からインデックス 4 までのすべての要素を抽出しますが、インデックス 4 の要素は含まれません。
配列からスライスを抽出するだけでなく、既存のスライスから新しいスライスを抽出することもできます。操作は配列の場合と同じです。以下に簡単な例を示します。
package main
import "fmt"
func main() {
// 長さ 10 の整数配列を定義
a := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 初期スライス s1 を作成
var s1 []int
s1 = a[1:7]
fmt.Printf("Slice s1: %d\tLength: %d\tCapacity: %d\n", s1, len(s1), cap(s1))
// 初期スライス s1 から新しいスライス s2 を抽出
s2 := s1[2:4]
fmt.Printf("Slice s1: %d\tLength: %d\tCapacity: %d\n", s2, len(s2), cap(s2))
}
出力は以下の通りです。
Slice s1: [1 2 3 4 5 6] Length: 6 Capacity: 9
Slice s1: [3 4] Length: 2 Capacity: 7
このプログラムでは、配列 a を切り出すことでスライス s1 を取得しました。s1 の範囲はインデックス 1 から 7 です。次に := を使用して、s1 から新しいスライス s2 を抽出しました。s1 の切り出しは連続しているため、新しいスライス s2 も連続したものになります。
スライスを切り出すと容量(Capacity)が変化することに気づくでしょう。ルールは以下の通りです。
容量 c のスライスを切り出す場合、s[i:j] の長さは j-i になり、容量は c-i になります。
s1 の場合、基底配列は a であり、a[1:7] の容量は 9(つまり 10-1)です。
s2 の場合、基底配列は s1 と同じです。前のステップで切り出された部分の容量が 9 であったため、s1[2:4] の容量は 7(つまり 9-2)になります。
スライスの値を変更すると基底配列の要素の値も同時に影響を受ける
スライスはデータを保持せず配列を参照しているだけなので、スライスの値を変更すると、基底となる配列の値も同時に変更されます。これを実証してみましょう。
package main
import "fmt"
func main() {
// 長さ 10 の整数配列を定義
a := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := a[2:5]
s2 := a[:]
fmt.Println("Before Modification: ")
fmt.Println("Elements in array a: ", a)
fmt.Println("Elements in array a: ", s1)
fmt.Println("Elements in array a: ", s2)
// スライス s1 のインデックス 2 の値を 23 に変更
s1[2] = 23
fmt.Println("After Modification: ")
fmt.Println("Elements in array a: ", a)
fmt.Println("Elements in array a: ", s1)
fmt.Println("Elements in array a: ", s2)
}
出力は以下の通りです。
Before Modification:
Elements in array a: [0 1 2 3 4 5 6 7 8 9]
Elements in array a: [2 3 4]
Elements in array a: [0 1 2 3 4 5 6 7 8 9]
After Modification:
Elements in array a: [0 1 2 3 23 5 6 7 8 9]
Elements in array a: [2 3 23]
Elements in array a: [0 1 2 3 23 5 6 7 8 9]
このプログラムでは、スライス s1 と s2 の両方が配列 a を参照しています。スライス s1 がインデックス 2 の値を 23 に変更すると、配列 a とスライス s2 の値も更新されます。
配列のインデックス 4 の値が 23 に変更されていることがわかります(s1 := a[2:5] なので、s1[0] は a[2]、s1[1] は a[3]、s1[2] は a[4] を参照しているためです)。その結果、配列 a とスライス s2 の両方のインデックス 4 の値が変更されました。
これはプログラム開発においてデバッグが困難なバグの原因となる可能性があります。したがって、日常的なプログラミングでは、複数のスライスが同じ基底配列を参照することを可能な限り避けるべきです。
スライスへの要素の追加
このセクションでは、スライスに要素を追加するために使用される append 関数を紹介します。構文は以下の通りです。
func append(slice []Type, elems ...Type) []Type
最初の引数は対象となるスライス slice で、残りの引数はスライスに追加する要素です。末尾の []Type は、append 関数が slice と同じデータ型の新しいスライスを返すことを示しています。
... の後の elems は、これが可変長引数であることを表しており、1 つ以上のパラメータを入力できることを意味します。
append 関数の使用例を以下に示します。
package main
import "fmt"
func main() {
// 長さ 10 の整数配列を定義
a := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := a[1:7]
fmt.Printf("Initial s1 value: %d\tLength: %d\tCapacity: %d\n", s1, len(s1), cap(s1))
s1 = append(s1, 12)
fmt.Printf("Modified s1 value: %d\tLength: %d\tCapacity: %d\n", s1, len(s1), cap(s1))
s1 = append(s1, 14, 14)
fmt.Printf("Modified s1 value: %d\tLength: %d\tCapacity: %d\n", s1, len(s1), cap(s1))
}
出力は以下の通りです。
Initial s1 value: [1 2 3 4 5 6] Length: 6 Capacity: 9
Modified s1 value: [1 2 3 4 5 6 12] Length: 7 Capacity: 9
Modified s1 value: [1 2 3 4 5 6 12 14 14] Length: 9 Capacity: 9
このプログラムでは、まず配列 a を切り出してスライス s1 を作成しました。s1 の範囲はインデックス 1 から 7 です。:= 演算子を使用して、append の戻り値を s1 に代入しています。append を使用して要素を追加すると、スライスの容量が変化することがあります。要素数が容量を超えると、スライスの容量は倍増します。
スライスの拡張ルールは以下の通りです。
- スライスの基底配列が新しい要素を収容できる場合、スライスの容量は変化しません。
- スライスの基底配列が新しい要素を収容できない場合、Go はより大きな配列を作成し、元のスライスの値を新しい配列にコピーしてから、追加された値を新しい配列に追加します。
注意: スライスの拡張は常に倍増するわけではありません。要素のサイズ、拡張される要素の数、コンピュータのハードウェアなどの要因に依存します。詳細については、スライスの高度なセクションを参照してください。
スライス内の要素の削除
Go にはスライスから要素を削除するための専用のキーワードや関数はありませんが、配列の切り出しを利用して同様の機能、あるいはそれ以上の機能を実現できます。
以下のコードは、スライス s のインデックス 5 にある要素を削除し、それを新しいスライス s1 に代入します。
package main
import "fmt"
func main() {
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 削除前のスライス s を表示
fmt.Println(s)
s1 := append(s[:5], s[6:]...)
// インデックス 5 の要素を削除した後のスライス s と s1 を表示
fmt.Printf("%d\n%d\n", s, s1)
}
出力は以下の通りです。
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 6 7 8 9 9]
[0 1 2 3 4 6 7 8 9]
特定のインデックスを削除する鍵は append 文にあります。これは、インデックス 6 以降の要素をインデックス 5 より前の要素に付け加えています。
この操作は、実質的に値を前方に上書きしていることになります。例えば、要素 5 は要素 6 で上書きされ、要素 6 は要素 7 で上書きされ、という具合に要素 9 まで続き、それが新しいスライスに追加されます。そのため、この時点での基底配列の値は [0 1 2 3 4 6 7 8 9 9] になります。
この時点で s1 の長さと容量を確認すると、長さは 9 ですが容量は 10 であることがわかります。これは s1 が s の切り出しへの参照であり、同じ基底配列を共有しているためです。
package main
import "fmt"
func main() {
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
fmt.Println(s)
s1 := append(s[:5], s[6:]...)
// s1 の長さと容量を確認
fmt.Println(len(s1), cap(s1))
fmt.Printf("\n%d\n%d\n\n", s, s1)
// スライス s を変更
s[3] = 22
fmt.Printf("%d\n%d\n", s, s1)
}
出力は以下の通りです。
[0 1 2 3 4 5 6 7 8 9]
9 10
[0 1 2 3 4 6 7 8 9 9]
[0 1 2 3 4 6 7 8 9]
[0 1 2 22 4 6 7 8 9 9]
[0 1 2 22 4 6 7 8 9]
チャレンジ
特定の位置の要素を削除するだけでなく、切り出しを使用してスライスから特定の範囲の要素を削除することもできます。操作は特定のインデックスを削除する場合と同じです。簡単な練習をしてみましょう。
slice1.go というファイルを作成します。スライス a を作成し、以下のように初期化します。次に、切り出しを使用して、3 より大きく 7 より小さい要素を含まない別のスライス s を作成します。最後に、新しいスライスを出力します。
a := []int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
出力例:
[9 8 7 3 2 1 0]
- ヒント: スライスの開始インデックスに注意してください(インデックスは 0 から始まることを忘れずに)。
- 要件:
slice1.goファイルは~/projectディレクトリに配置する必要があります。
スライスの拡張
スライスには len と cap という 2 つの属性があります。len は現在スライスにある要素の数を表し、cap はスライスが保持できる最大要素数を表します。
スライスに追加された要素の数がその容量を超えるとどうなるでしょうか?一緒に確認してみましょう。
package main
import "fmt"
func main() {
s1 := make([]int, 3)
s2 := make([]int, 3, 5)
fmt.Println("Before Append in s1:", s1, "Length:", len(s1), "Capacity:", cap(s1))
fmt.Println("Before Append in s2:", s2, "Length:", len(s2), "Capacity:", cap(s2))
s1 = append(s1, 12)
s2 = append(s2, 22)
fmt.Println("After Append in s1:", s1, "Length:", len(s1), "Capacity:", cap(s1))
fmt.Println("After Append in s2:", s2, "Length:", len(s2), "Capacity:", cap(s2))
}
プログラムを実行するには、以下のコマンドを実行します。
go run slice.go
出力は以下の通りです。
Before Append in s1: [0 0 0] Length: 3 Capacity: 3
Before Append in s2: [0 0 0] Length: 3 Capacity: 5
After Append in s1: [0 0 0 12] Length: 4 Capacity: 6
After Append in s2: [0 0 0 22] Length: 4 Capacity: 5
このプログラムでわかるように、スライスに要素を追加し、その要素数が元の容量を超えると、スライスの容量は自動的に増加します。
スライスの拡張ルールは以下の通りです。
- スライスの基底配列が新しい要素を保持できる場合、スライスの容量は変化しません。
- スライスの基底配列が新しい要素を保持できない場合、Go はより大きな配列を作成し、元のスライスの値を新しい配列にコピーし、その後に追加された値を新しい配列に追加します。
注意: スライスの容量が常に倍増するとは限りません。要素のサイズ、要素数、およびコンピュータのハードウェアに依存します。詳細については、スライスの高度なセクションを参照してください。
スライスのコピー
copy 関数を使用して、あるスライスを別のスライスに複製できます。構文は以下の通りです。
func copy(dst, src []Type) int
dst はコピー先のスライス、src はコピー元のスライスです。戻り値の int はコピーされた要素の数を示し、これは len(dst) と len(src) の小さい方の値になります。
注意: copy 関数は要素を追加(拡張)することはありません。
例を以下に示します。
package main
import "fmt"
func main() {
s1 := []int{0, 1, 2, 3}
s2 := []int{8, 9}
s3 := []int{0, 1, 2, 3}
s4 := []int{8, 9}
// s1 を s2 にコピー
n1 := copy(s2, s1)
// s4 を s3 にコピー
n2 := copy(s3, s4)
fmt.Println(n1, s1, s2)
fmt.Println(n2, s3, s4)
}
プログラムを実行するには、以下のコマンドを実行します。
go run slice.go
出力は以下の通りです。
2 [0 1 2 3] [0 1]
2 [8 9 2 3] [8 9]
このプログラムでは、スライス s1 の値をスライス s2 にコピーし、スライス s4 の値をスライス s3 にコピーしました。copy 関数はコピーされた要素の数を返します。
s1 と s2 の値、および s3 と s4 の値に注目してください。最初の copy 関数は s1[0, 1, 2, 3] を s2[8, 9] にコピーします。s1 と s2 の最小の長さは 2 なので、2 つの値がコピーされます。コピー先のスライス s2 は [0, 1] に変更されます。
2 番目の copy 関数は s4[8, 9] を s3[0, 1, 2, 3] にコピーします。s3 と s4 の最小の長さは 2 なので、2 つの値がコピーされます。その結果、s3 は [8, 9, 2, 3] に変更されます。
スライスの反復処理
スライスの反復処理(トラバース)は、配列の反復処理と同様です。配列で使用できるすべての反復処理方法は、スライスでも使用できます。
チャレンジ
この練習では、スライスと配列の反復処理に関する理解をテストし、強化します。
slice2.go というファイルを作成します。配列 a1 とスライス s1 を宣言し、以下のように初期化します。次に、配列 a1 とスライス s1 の要素を反復処理し、それらのインデックスと値を出力します。
a1 := [5]int{1, 2, 3, 9, 7}
s1 := []int{1, 8, 12, 1, 3}
出力例:
Element a1 at index 0 is 1
Element a1 at index 1 is 2
Element a1 at index 2 is 3
Element a1 at index 3 is 9
Element a1 at index 4 is 7
Element s1 at index 0 is 1
Element s1 at index 1 is 8
Element s1 at index 2 is 12
Element s1 at index 3 is 1
Element s1 at index 4 is 3
- 要件:
slice2.goファイルは~/projectディレクトリに配置する必要があります。 - ヒント: 要素を反復処理するには、
range形式またはインデックス形式を使用できます。
まとめ
このセクションでは、スライスとその使用方法について学びました。配列と比較して、スライスはより柔軟で多用途です。複数のスライスを扱う場合は、予期しない操作を避けるために注意が必要です。


