
Introducción
Este laboratorio se centra principalmente en los fundamentos de Hadoop y está dirigido a estudiantes con un cierto conocimiento de Linux para que comprendan la arquitectura del sistema de software Hadoop, así como los métodos básicos de implementación.
Por favor, introduzca todo el código de ejemplo del documento por su cuenta y, en la medida de lo posible, no solo copie y pegue. Solo de esta manera podrá familiarizarse mejor con el código. Si tiene problemas, revise detenidamente la documentación, de lo contrario puede ir al foro para obtener ayuda y comunicación.
Introducción a Hadoop
Apache Hadoop es un marco de software de código abierto que admite aplicaciones distribuidas intensivas en datos, publicado bajo la Licencia Apache 2.0.
La biblioteca de software Apache Hadoop es un marco que permite el procesamiento distribuido de grandes conjuntos de datos en clústers de cómputo mediante un modelo de programación simple. Está diseñado para escalar desde un solo servidor hasta miles de máquinas, cada una de las cuales proporciona cómputo y almacenamiento locales en lugar de depender de hardware para garantizar alta disponibilidad.
Conceptos básicos
Un proyecto Hadoop incluye principalmente los siguientes cuatro módulos:
- Hadoop Common: Una aplicación pública que ofrece soporte para otros módulos de Hadoop.
- Hadoop Distributed File System (HDFS): Un sistema de archivos distribuido que ofrece acceso de alta rendimiento a los datos de las aplicaciones.
- Hadoop YARN: Marco de planificación de tareas y administración de recursos de clúster.
- Hadoop MapReduce: Un marco de cómputo paralelo para conjuntos de datos a gran escala basado en YARN.
Para los usuarios nuevos en Hadoop, deberían centrarse en HDFS y MapReduce. Como marco de cómputo distribuido, HDFS satisface los requisitos de almacenamiento del marco para los datos y MapReduce satisface los requisitos de cálculo del marco para los datos.
La siguiente imagen muestra la arquitectura básica de un clúster Hadoop:
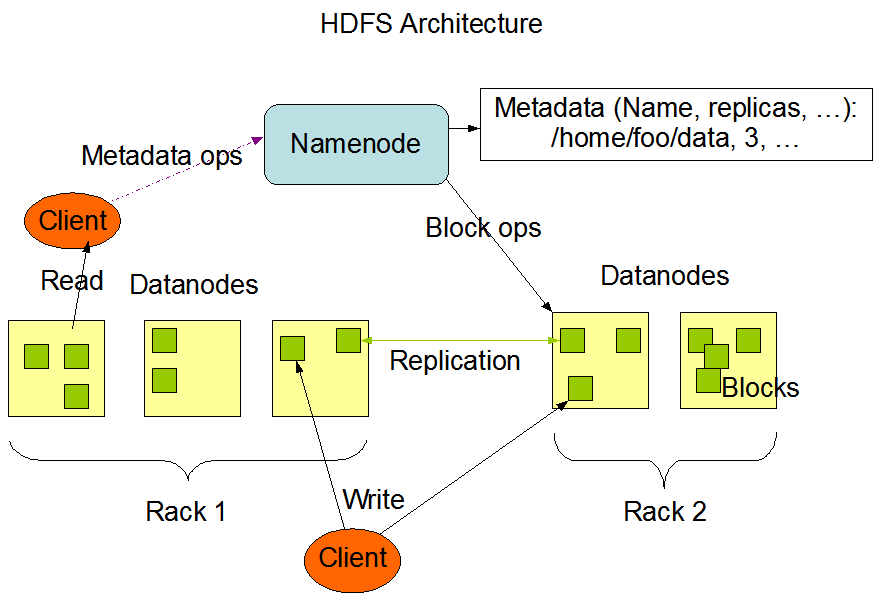
Esta imagen se cita de la página web oficial de Hadoop.
Ecosistema de Hadoop
Al igual que Facebook ha derivado el repositorio de datos Hive basado en Hadoop, hay muchos proyectos de código abierto relacionados en la comunidad. A continuación se presentan algunos proyectos activos recientes:
- HBase: Una base de datos distribuida escalable que admite el almacenamiento de datos estructurados para tablas grandes.
- Hive: Una infraestructura de repositorio de datos que ofrece resumen de datos y consultas temporales.
- Pig: Lenguaje de flujo de datos avanzado y marco de ejecución para cómputo paralelo.
- ZooKeeper: Servicio de coordinación de alto rendimiento para aplicaciones distribuidas.
- Spark: Un motor de cálculo de datos de Hadoop rápido y versátil con un modelo de programación simple y expresivo que admite ETL (extracción, transformación y carga) de datos, aprendizaje automático, procesamiento de flujos y cómputo gráfico.
Este laboratorio comenzará con Hadoop, presentando los usos básicos de los componentes relacionados.
Es importante destacar que Spark, un marco de cómputo en memoria distribuido, nace del sistema Hadoop. Tiene una buena herencia para componentes como HDFS y YARN, y también mejora algunas de las deficiencias existentes de Hadoop.
Algunos de ustedes pueden tener preguntas sobre la superposición entre los escenarios de uso de Hadoop y Spark, pero aprender el patrón de trabajo y el patrón de programación de Hadoop ayudará a profundizar la comprensión del marco de Spark, que es la razón por la que se debe aprender Hadoop primero.
Implementación de Hadoop
Para los principiantes, no hay muchas diferencias entre las versiones de Hadoop posteriores a la versión 2.0. Esta sección tomará la versión 3.3.6 como ejemplo.
Hadoop tiene tres patrones de implementación principales:
- Patrón independiente: Se ejecuta en un solo proceso en un solo computador.
- Patrón pseudo-distribuido: Se ejecuta en múltiples procesos en un solo computador. Este patrón simula un escenario de "multi-nodo" en un solo nodo.
- Patrón completamente distribuido: Se ejecuta en un solo proceso en cada uno de múltiples computadores.
A continuación, instalaremos la versión 3.3.6 de Hadoop en un solo computador.
Configuración de usuarios y grupos de usuarios
Haga doble clic para abrir la terminal Xfce en su escritorio y escriba el siguiente comando para crear un usuario llamado hadoop:
cd ~
sudo adduser hadoop
Y, siga las instrucciones para ingresar la contraseña del usuario hadoop; por ejemplo, para establecer la contraseña en hadoop.
Nota: Cuando ingrese la contraseña, no hay indicación en el comando. Puede simplemente presionar la tecla Enter cuando haya terminado.
Luego, agregue el usuario hadoop creado al grupo de usuarios sudo para otorgarle privilegios más elevados:
sudo usermod -G sudo hadoop
Verifique que el usuario hadoop haya sido agregado al grupo sudo escribiendo el siguiente comando:
sudo cat /etc/group | grep hadoop
Debería ver la siguiente salida:
sudo:x:27:shiyanlou,labex,hadoop
Instalando JDK
Como se mencionó en el contenido anterior, Hadoop se desarrolla principalmente en Java. Por lo tanto, para ejecutarlo se requiere un entorno Java.
Las diferentes versiones de Hadoop tienen sutiles diferencias en los requisitos de la versión de Java. Para saber qué versión de JDK debe elegir para su Hadoop, puede leer Hadoop Java Versions en el sitio web de la wiki de Hadoop.
Cambie de usuario:
su - hadoop
Instale la versión 11 de JDK escribiendo el siguiente comando en la terminal:
sudo apt update
sudo apt install openjdk-11-jdk -y
Una vez que lo haya instalado con éxito, verifique la versión actual de Java:
java -version
Ver la salida:
openjdk version "11.0.22" 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu222.04.1, mixed mode, sharing)
Configurar inicio de sesión SSH sin contraseña
El propósito de instalar y configurar SSH es facilitar la ejecución de scripts relacionados con el demonio de administración remota en Hadoop. Estos scripts requieren el servicio sshd.
Al configurar, primero cambie al usuario hadoop. Escriba el siguiente comando en la terminal para hacerlo:
su hadoop
Si hay un mensaje que le pida que ingrese una contraseña, simplemente ingrese la contraseña que se especificó cuando se creó el usuario (hadoop) anteriormente:
Después de cambiar de usuario con éxito, el indicador de comando debería ser como se muestra arriba. Los pasos siguientes se realizarán como usuario hadoop.
A continuación, genere la clave para el inicio de sesión SSH sin contraseña.
Lo que se conoce como "sin contraseña" es cambiar el patrón de autenticación de SSH de inicio de sesión con contraseña a inicio de sesión con clave para que cada componente de Hadoop no tenga que ingresar la contraseña a través de la interacción del usuario al acceder mutuamente, lo que puede reducir muchas operaciones redundantes.
Primero cambie al directorio home del usuario y luego use el comando ssh-keygen para generar la clave RSA.
Por favor, escriba el siguiente comando en la terminal:
cd /home/hadoop
ssh-keygen -t rsa
Cuando se le presente información como la ubicación donde se almacena la clave, puede presionar la tecla Enter para usar el valor predeterminado.
La imagen de arte aleatorio de la clave es:
+---[RSA 3072]----+
| ..+. |
| . =. o |
| .o o *. |
| o... + o |
| = +.S.. + |
| + + +++.. |
| . B.O+. |
| o +oXo*E |
| =.+==o. |
+----[SHA256]-----+
Después de generar la clave, se generará la clave pública en el directorio .ssh bajo el directorio home del usuario.
La operación específica se muestra en la figura siguiente:
Luego continúe escribiendo el siguiente comando para agregar la clave pública generada al registro de autenticación del host. Asigne los permisos de escritura al archivo authorized_keys, de lo contrario no se ejecutará correctamente durante la verificación:
cat.ssh/id_rsa.pub >> .ssh/authorized_keys
chmod 600.ssh/authorized_keys
Después de que la adición haya sido exitosa, intente iniciar sesión en el localhost. Por favor, escriba el siguiente comando en la terminal:
ssh localhost
Cuando inicie sesión por primera vez, se le pedirá que confirme la huella digital de la clave pública, simplemente escriba yes y confirme. Luego, cuando inicie sesión nuevamente, será un inicio de sesión sin contraseña:
...
Bienvenido al Servicio de Cómputo Elástico de Alibaba Cloud!
Para ejecutar un comando como administrador (usuario "root"), use "sudo <command>".
Vea "man sudo_root" para obtener detalles.
hadoop:~$
Debe escribir el comando history -w o salir de la terminal para guardar los cambios y pasar el script de verificación.
Instalando Hadoop
Ahora, puede descargar el paquete de instalación de Hadoop. La página web oficial proporciona el enlace de descarga de la última versión de Hadoop. También puede usar el comando wget para descargar el paquete directamente en la terminal.
Escriba el siguiente comando en la terminal para descargar el paquete:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Una vez que se complete la descarga, puede usar el comando tar para extraer el paquete:
tar zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 hadoop
sudo chown -R hadoop:hadoop /home/hadoop
Puede encontrar la ubicación de JAVA_HOME ejecutando el comando dirname $(dirname $(readlink -f $(which java))) en la terminal.
dirname $(readlink -f $(which java))
Luego, abra el archivo .zshrc con un editor de texto en la terminal:
vim /home/hadoop/.bashrc
Agregue lo siguiente al final del archivo /home/hadoop/.bashrc:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Guarde y salga del editor vim. Luego escriba el comando source en la terminal para activar las variables de entorno recién agregadas:
source /home/hadoop/.bashrc
Verifique la instalación ejecutando el comando hadoop version en la terminal.
hadoop@iZj6cgdabeniugz9ypibzxZ:~$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
Configuración del patrón pseudo-distribuido
En la mayoría de los casos, Hadoop se utiliza en un entorno de clúster, es decir, es necesario desplegar Hadoop en varios nodos. Al mismo tiempo, Hadoop también puede ejecutarse en un solo nodo en patrón pseudo-distribuido, simulando escenarios de multi-nodo a través de múltiples procesos Java independientes. En la fase inicial de aprendizaje, no es necesario gastar muchos recursos en crear diferentes nodos. Por lo tanto, esta sección y los capítulos siguientes utilizarán principalmente el patrón pseudo-distribuido para la implementación del "clúster" de Hadoop.
Crear directorios
Para comenzar, cree los directorios namenode y datanode dentro del directorio home del usuario Hadoop. Ejecute el comando siguiente para crear estos directorios:
rm -rf ~/hadoopdata
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Luego, es necesario modificar los archivos de configuración de Hadoop para que funcione en patrón pseudo-distribuido.
Editar core-site.xml
Abra el archivo core-site.xml con un editor de texto en la terminal:
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
En el archivo de configuración, modifique el valor de la etiqueta configuration al siguiente contenido:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
El elemento de configuración fs.defaultFS se utiliza para indicar la ubicación del sistema de archivos que utiliza el clúster por defecto:
Guarde el archivo y salga de vim después de editar.
Editar hdfs-site.xml
Abra otro archivo de configuración hdfs-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
En el archivo de configuración, modifique el valor de la etiqueta configuration al siguiente:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Este elemento de configuración se utiliza para indicar el número de copias de archivos en HDFS, que por defecto es 3. Dado que lo hemos desplegado de manera pseudo-distribuida en un solo nodo, se modifica a 1:
Guarde el archivo y salga de vim después de editar.
Editar hadoop-env.sh
A continuación, edite el archivo hadoop-env.sh:
vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
Cambie el valor de JAVA_HOME a la ubicación real del JDK instalado, es decir, /usr/lib/jvm/java-11-openjdk-amd64.
Nota: Puede usar el comando
echo $JAVA_HOMEpara verificar la ubicación real del JDK instalado.
Guarde el archivo y salga del editor vim después de editar.
Editar yarn-site.xml
A continuación, edite el archivo yarn-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
Agregue lo siguiente a la etiqueta configuration:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Guarde el archivo y salga del editor vim después de editar.
Editar mapred-site.xml
Finalmente, es necesario editar el archivo mapred-site.xml.
Abra el archivo con el editor vim:
vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
Del mismo modo, agregue lo siguiente a la etiqueta configuration:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>
Guarde el archivo y salga del editor vim después de editar.
Prueba de inicio de Hadoop
Primero, abra la terminal Xfce en el escritorio y cambie al usuario Hadoop:
su -l hadoop
La inicialización de HDFS se centra principalmente en el formato:
/home/hadoop/hadoop/bin/hdfs namenode -format
Consejo: debe eliminar el directorio de datos de HDFS antes de formatearlo.
Si ve este mensaje, significa que se ha realizado con éxito:
2024-02-29 18:24:53,887 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Debe escribir el comando history -w o salir de la terminal para guardar el historial y pasar el script de verificación.
Iniciar HDFS
Una vez que se complete la inicialización de HDFS, puede iniciar los demonios de NameNode y DataNode. Una vez iniciados, las aplicaciones de Hadoop (como las tareas de MapReduce) pueden leer y escribir archivos en/desde HDFS.
Inicie el demonio escribiendo el siguiente comando en la terminal:
/home/hadoop/hadoop/sbin/start-dfs.sh
Ver el resultado:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [iZj6cjditp4l7k0fylhhfbZ]
iZj6cjditp4l7k0fylhhfbZ: Warning: Permanently added 'izj6cjditp4l7k0fylhhfbz' (ED25519) to the list of known hosts.
Para confirmar que Hadoop se ha ejecutado correctamente en patrón pseudo-distribuido, puede usar la herramienta de visualización de procesos de Java jps para ver si hay un proceso correspondiente.
Escriba el siguiente comando en la terminal:
jps
Como se muestra en la figura, si ve los procesos de NameNode, DataNode y SecondaryNameNode, significa que el servicio de Hadoop está funcionando correctamente:
Ver archivos de registro y la interfaz web de usuario (WebUI)
Cuando Hadoop no se inicia correctamente o se informan errores durante la ejecución de una tarea (o cualquier otra cosa), además de la información de aviso de la terminal, la revisión de los registros es la mejor manera de localizar un problema. La mayoría de los problemas se pueden encontrar a través de los registros del software relacionado para determinar la causa y encontrar una solución. Como aprendiz en el campo de los datos masivos, la capacidad para analizar registros es tan importante como la capacidad para aprender el marco de cómputo y debe tomarse en serio.
La salida predeterminada de los registros de los demonios de Hadoop se encuentra en el directorio de registros (logs) bajo el directorio de instalación. Escriba el siguiente comando en la terminal para entrar en el directorio de registros:
ls /home/hadoop/hadoop/logs
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-datanode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-namenode-iZj6cjditp4l7k0fylhhfbZ.out
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.log
hadoop-hadoop-secondarynamenode-iZj6cjditp4l7k0fylhhfbZ.out
SecurityAuth-hadoop.audit
Puede usar el editor vim para ver cualquier archivo de registro.
Después de que se haya iniciado HDFS, también se proporciona una página web que muestra el estado del clúster a través del servicio web interno. Cambie hasta la parte superior de la máquina virtual LabEx y haga clic en "Web 8088" para abrir la página web:
Después de abrir la página web, puede ver la vista general del clúster, el estado del DataNode y demás:
Sientase libre de hacer clic en el menú en la parte superior de la página para explorar los consejos y funciones.
Debe escribir el comando history -w o salir de la terminal para guardar el historial y pasar el script de verificación.
Prueba de carga de archivos en HDFS
Una vez que HDFS está en ejecución, se puede considerar como un sistema de archivos. Aquí, para probar la funcionalidad de carga de archivos, es necesario crear un directorio (un nivel profundo en cada paso, hasta el nivel de directorio requerido) y tratar de cargar algunos archivos del sistema Linux a HDFS:
cd ~
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user
/home/hadoop/hadoop/bin/hdfs dfs -mkdir /user/hadoop
Después de crear el directorio con éxito, use el comando hdfs dfs -put para cargar los archivos del disco local (los archivos de configuración de Hadoop seleccionados al azar aquí) a HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/hadoop/etc/hadoop /user/hadoop/input
Casos de prueba de PI
La gran mayoría de las aplicaciones de Hadoop desplegadas en entornos de producción del mundo real y que resuelven problemas del mundo real se basan en el modelo de programación MapReduce representado por WordCount. Por lo tanto, WordCount se puede utilizar como un programa "HelloWorld" para comenzar con Hadoop, o puede agregar sus propias ideas para resolver problemas específicos.
Iniciar la tarea
Al final de la sección anterior, cargamos algunos archivos de configuración a HDFS, como ejemplo. A continuación, podemos intentar ejecutar el caso de prueba de PI para obtener las estadísticas de frecuencia de palabras de estos archivos y mostrarlas según nuestras reglas de filtrado.
Inicie el servicio de cálculo de YARN en la terminal primero:
/home/hadoop/hadoop/sbin/start-yarn.sh
Luego escriba el siguiente comando para iniciar la tarea:
/home/hadoop/hadoop/bin/hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 3 3
Ver los resultados de salida:
Estimated value of Pi is 3.55555555555555555556
Entre los parámetros anteriores, hay tres parámetros sobre la ruta. Son: la ubicación del paquete jar, la ubicación del archivo de entrada y la ubicación de almacenamiento del resultado de salida. Al especificar la ruta, debe desarrollar la costumbre de especificar una ruta absoluta. Esto ayudará a localizar problemas rápidamente y a entregar el trabajo pronto.
Una vez completada la tarea, puede ver los Resultados.
Cerrar el servicio de HDFS
Después del cálculo, si no hay ningún otro programa de software que utilice los archivos en HDFS, debe cerrar el demonio de HDFS en tiempo.
Como usuario de clústeres distribuidos y marcos de cómputo relacionados, debe desarrollar la buena costumbre de verificar activamente el estado del hardware y software relacionado cada vez que se abra o cierre el clúster, se instale hardware o software, o se realice cualquier tipo de actualización.
Utilice el siguiente comando en la terminal para cerrar los demonios de HDFS y YARN:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
Debe escribir el comando history -w o salir de la terminal para guardar el historial y pasar el script de verificación.
Resumen
Esta práctica ha introducido la arquitectura de Hadoop, los métodos de instalación y despliegue en patrón de ejecución independiente y patrón pseudo-distribuido, y ha ejecutado WordCount para pruebas básicas.
A continuación se presentan los principales puntos de esta práctica:
- Arquitectura de Hadoop
- Módulo principal de Hadoop
- Cómo utilizar el patrón de ejecución independiente de Hadoop
- Despliegue en patrón pseudo-distribuido de Hadoop
- Usos básicos de HDFS
- Caso de prueba de WordCount
En general, Hadoop es un marco de cómputo y almacenamiento comúnmente utilizado en el campo de los datos masivos. Sus funciones deben ser exploradas más detenidamente. Por favor, conserve la costumbre de consultar materiales técnicos y siga aprendiendo en las siguientes prácticas.


