
介绍
欢迎来到你的第一个 scikit-learn 实验!Scikit-learn 是 Python 中最流行、最强大的开源机器学习库之一。它提供了广泛的数据挖掘和数据分析工具,构建在 NumPy、SciPy 和 matplotlib 之上。
在开始本课程之前,你应该具备基本的 Python 编程技能,并确保 Python 已正确配置在你的系统 PATH 中。如果你还没有学习 Python,可以从我们的 Python 学习路径 开始。此外,你应该安装 NumPy 和 Pandas,因为它们是 scikit-learn 操作的基本先决条件。如果你需要学习这些库,可以探索我们的 NumPy 学习路径 和 Pandas 学习路径。
在本实验中,你将学习在 LabEx 环境中开始使用 scikit-learn 的基本步骤。我们将引导你完成验证安装、导入模块以及加载 scikit-learn 的内置数据集。这将确认你的环境已为未来的机器学习实验正确配置。
使用 pip install scikit-learn 安装 scikit-learn
在本步骤中,我们将讨论如何安装 scikit-learn 库。在本地机器的典型 Python 环境中,你会使用 pip(Python 的包安装器)来安装新库。安装 scikit-learn 的命令是:
pip install scikit-learn
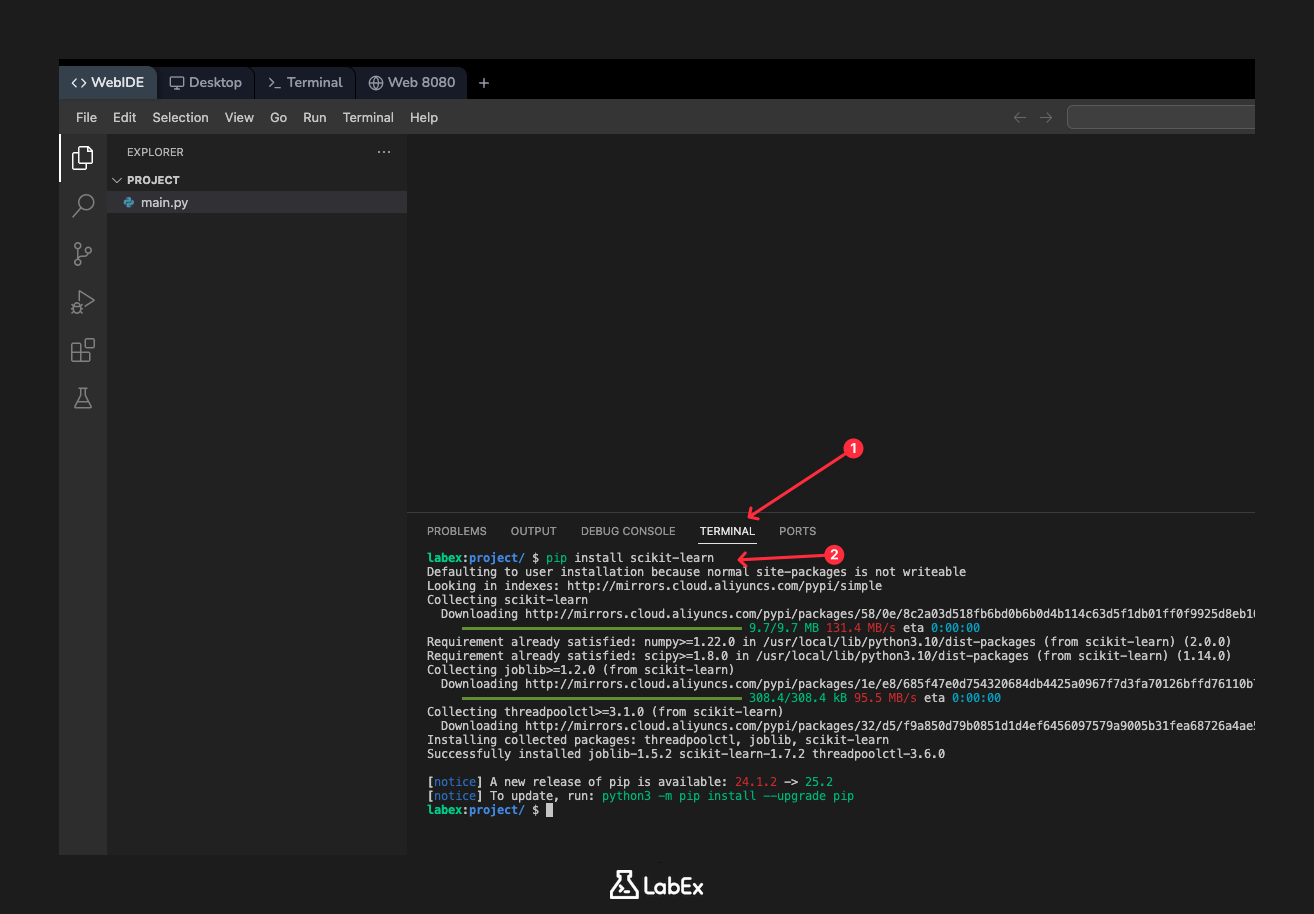
然而,为了让你的学习体验更顺畅,LabEx 环境已经预装了 scikit-learn 及其依赖项。因此,你无需在此处运行安装命令。我们展示它是为了供你参考,以便你知道如何在自己的计算机上设置 scikit-learn。
让我们继续下一步,开始使用该库。
导入 scikit-learn,使用 from sklearn import datasets
在本步骤中,你将编写第一行 Python 代码来与 scikit-learn 库进行交互。在 Python 中,在你可以在脚本中使用库中的任何函数或对象之前,必须先将其导入。
Scikit-learn 包含一个名为 datasets 的模块,其中包含加载和获取流行参考数据集的实用工具。我们将导入此模块,以便在后续步骤中使用它。
首先,在 WebIDE 左侧的文件浏览器中找到 main.py 文件。点击它在编辑器中打开。现在,将以下代码行添加到 main.py 文件中:
from sklearn import datasets
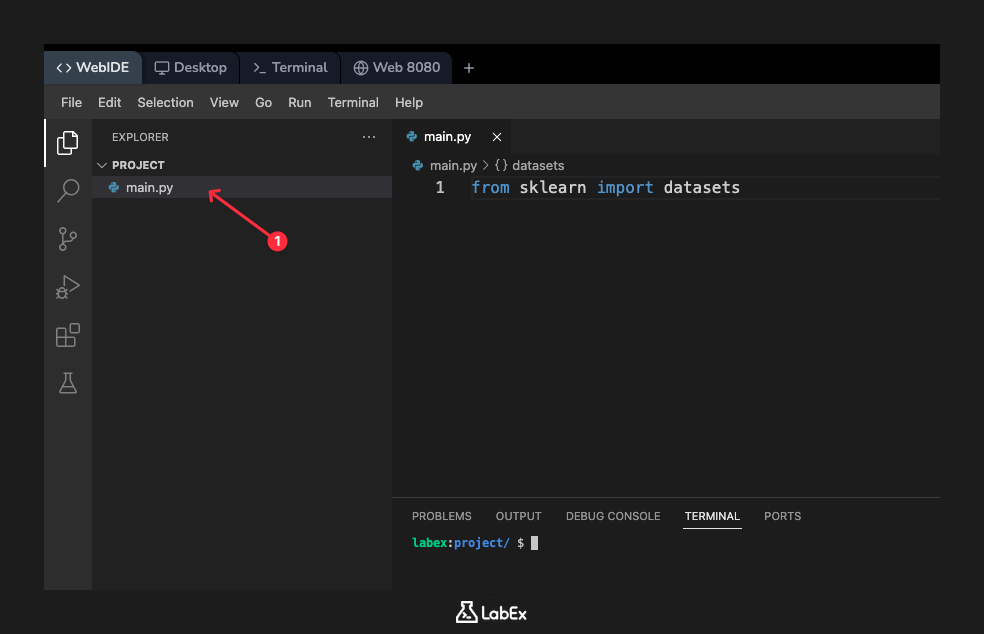
这行代码告诉 Python 查找 sklearn 库,并从中导入 datasets 模块,使其函数可供我们使用。添加代码后,保存文件。我们将在接下来的步骤中添加更多代码并运行脚本。
使用 sklearn.__version__ 验证安装
在本步骤中,我们将通过检查其版本号来验证 scikit-learn 是否已正确安装并可访问。这是确保库在你的环境中正确设置的常用做法。每个 scikit-learn 安装都有一个名为 __version__ 的特殊属性,其中包含此信息。
让我们向 main.py 文件添加代码以打印版本。我们还需要导入顶级的 sklearn 包本身。将你的 main.py 文件修改为如下所示:
import sklearn
from sklearn import datasets
print(sklearn.__version__)
现在,让我们运行此脚本。在你的 WebIDE 中打开一个终端(通常可以找到一个 + 图标或一个“Terminal”菜单)。在终端中(它应该在 /home/labex/project 目录中打开),执行以下命令:
python3 main.py
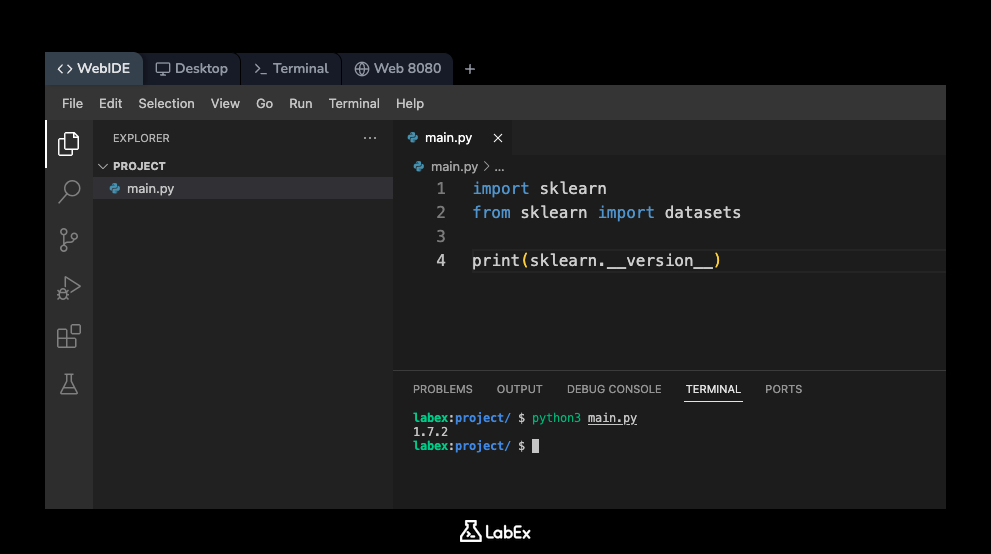
你应该会在控制台中看到已安装的 scikit-learn 版本。输出将与此类似(确切的版本号可能会有所不同):
1.x.x
这证实了 Python 可以成功导入并使用 scikit-learn 库。
使用 datasets.load_iris() 加载鸢尾花(iris)数据集
在本步骤中,我们将使用之前导入的 datasets 模块来加载一个样本数据集。Scikit-learn 包含几个小型、标准的数据集,无需从外部网站下载。这些数据集对于入门和测试算法非常有用。
我们将加载 Iris 数据集,这是机器学习领域一个经典且非常著名的数据集。它包含了 150 朵来自三个不同物种的鸢尾花测量数据。
要加载它,我们使用 datasets.load_iris() 函数。让我们修改 main.py 文件来加载数据集并将其存储在一个名为 iris 的变量中。我们还将添加一个打印语句来确认数据集已加载。
使用以下内容更新你的 main.py 文件:
import sklearn
from sklearn import datasets
## 加载 iris 数据集
iris = datasets.load_iris()
print("Iris dataset loaded successfully.")
建议: 你可以将上面的代码复制到你的代码编辑器中,然后仔细阅读每一行代码以理解其功能。如果你需要进一步的解释,可以点击“Explain Code”按钮 👆。你可以与 Labby 互动以获得个性化帮助。
保存文件并再次从终端运行它:
python3 main.py
输出现在应该是:
Iris dataset loaded successfully.
这表明 load_iris() 函数已成功执行,并且数据集现在在我们的脚本中的 iris 变量中可用。
使用 print(iris.keys()) 打印数据集的键
在本步骤中,我们将检查刚刚加载的 Iris 数据集的结构。load_iris() 返回的对象是一个 Bunch 对象,它类似于 Python 字典。它包含描述数据集的键和值。
要查看有哪些可用信息,我们可以使用 .keys() 方法打印它的键。这将向我们展示数据集的所有组成部分,例如数据本身、目标标签以及描述性名称。
修改你的 main.py 文件以打印 iris 对象的键。你的最终脚本应如下所示:
import sklearn
from sklearn import datasets
## 加载 iris 数据集
iris = datasets.load_iris()
## 打印数据集的键
print(iris.keys())
保存文件并最后一次从终端运行它:
python3 main.py
输出将显示数据集对象的不同部分:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
以下是对最重要的键的简要说明:
data: 包含特征数据(花卉测量值)的数组。target: 包含标签(每朵花的物种)的数组。feature_names: 特征的名称(例如,“sepal length (cm)”)。target_names: 目标物种的名称(例如,“setosa”)。DESCR: 数据集的完整描述。
通过打印这些键,你已成功加载并检查了数据集,完成了基本设置过程。
总结
恭喜你!你已成功完成了这个关于设置和验证 scikit-learn 环境的入门实验。
在这个实验中,你学会了如何:
- 理解 scikit-learn 的安装过程。
- 验证库的版本以确认安装成功。
- 从 scikit-learn 库导入模块。
- 加载内置样本数据集 Iris。
- 检查 scikit-learn 数据集对象的基本结构。
你现在已准备好进行更令人兴奋的实验,在这些实验中,你将使用 scikit-learn 提供的强大工具来探索数据预处理、模型训练和评估。


