
介绍
欢迎来到 scikit-learn 的机器学习世界!任何机器学习项目中最重要且最关键的步骤之一就是加载和理解你的数据。Scikit-learn 是一个强大且用户友好的 Python 机器学习库,它提供了几个内置数据集来帮助你入门。
在本实验中,你将使用著名的鸢尾花(Iris)数据集。你将学习如何加载此数据集,检查其结构,访问特征数据和目标标签,最后创建一个简单的可视化图表来初步了解数据的分布。这些基础知识对于任何有志于成为数据科学家或机器学习工程师的人来说都至关重要。
使用 datasets.load_iris() 加载 Iris 数据集
在本步骤中,你将学习如何加载 scikit-learn 的一个内置数据集。我们将使用 sklearn.datasets 模块中的 load_iris() 函数。此函数返回一个 "Bunch" 对象,它类似于 Python 字典,包含数据集及其元数据。
首先,打开屏幕左侧文件浏览器中的 main.py 文件。我们将在该文件中编写所有代码。
现在,将以下代码添加到 main.py 中以导入必要的模块并加载数据集。
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
此代码导入 datasets 模块并调用 load_iris() 函数,将生成的数据集对象存储在名为 iris 的变量中。
要执行你的脚本,请在 WebIDE 中打开一个终端(你可以使用 "Terminal" -> "New Terminal" 菜单),然后运行以下命令。你当前所在的目录已经是 ~/project。
python3 main.py
你不会看到任何输出,这是正常的。我们已经将数据加载到了 iris 变量中,但我们还没有要求脚本打印任何内容。在接下来的步骤中,我们将探索这个 iris 对象的内容。
使用 iris.data 访问数据数组
在本步骤中,你将访问数据集的核心:特征数据。我们创建的 iris 对象包含一个名为 data 的属性,它保存了一个 NumPy 数组,其中包含每朵花的测量值。每一行代表一个样本(一朵花),每一列代表一个特征(一项测量)。
让我们修改 main.py 文件来打印这个数据数组,看看它是什么样子的。
使用以下代码更新你的 main.py 文件:
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
## Print the data array
print(iris.data)
现在,从你的终端再次运行脚本:
python3 main.py
你应该会在终端看到一个很大的数字数组被打印出来。这是数据集中所有 150 个花样本的特征数据。每个样本有 4 个特征。
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
...
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
使用 iris.target 访问目标数组
在本步骤中,你将访问数据集中每个样本的标签。在监督式机器学习中,这些标签被称为“目标”(target)。iris 对象将它们存储在 target 属性中。对于鸢尾花数据集,目标代表了每朵花的种类。
种类被编码为整数:setosa 为 0,versicolor 为 1,virginica 为 2。iris.target 属性是一个 NumPy 数组,其中包含 iris.data 中每个样本对应的整数。
让我们修改 main.py 来打印目标数组。
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
## Print the target array
print(iris.target)
从你的终端运行脚本:
python3 main.py
输出将是一个由 0、1 和 2 组成的数组,代表这 150 朵花各自的种类。
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
通过 iris.feature_names 探索特征名称
在本步骤中,你将学习如何找出 iris.data 数组中的列实际代表什么。虽然我们知道有四个特征,但从数据数组本身来看,它们的名称并不明显。iris 对象方便地将这些名称存储在 feature_names 属性中。
这对于理解和解释你的数据非常有帮助。让我们修改 main.py 来打印这些特征名称。
更新你的 main.py 文件:
from sklearn import datasets
## Load the Iris dataset
iris = datasets.load_iris()
## Print the feature names
print(iris.feature_names)
现在,从你的终端运行脚本:
python3 main.py
输出将是一个字符串列表,告诉你 iris.data 中四个列的名称。
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
现在你知道这四个特征分别对应了花萼长度、花萼宽度、花瓣长度和花瓣宽度,单位都是厘米。
使用 matplotlib.pyplot.scatter(iris.data[:, 0], iris.data[:, 1]) 可视化数据
在最后这个步骤中,你将执行一个简单的数据可视化,以查看两个特征之间的关系。可视化是数据探索的关键部分。我们将使用 matplotlib 库,这是一个流行的 Python 绘图工具,来创建一个散点图。
我们将绘制第一个特征(花萼长度)与第二个特征(花萼宽度)的关系图。为了从我们的数据中选择这些列,我们使用 NumPy 切片:
iris.data[:, 0]选择所有行(:)和第一列(0)。iris.data[:, 1]选择所有行(:)和第二列(1)。
由于在此环境中直接显示绘图屏幕不理想,我们将把绘图保存到一个名为 iris_plot.png 的图像文件中。
使用以下代码更新你的 main.py 文件:
from sklearn import datasets
import matplotlib.pyplot as plt
## Load the Iris dataset
iris = datasets.load_iris()
## We will plot the first two features: Sepal Length vs Sepal Width
X = iris.data[:, :2]
y = iris.target
plt.scatter(X[:, 0], X[:, 1])
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('Sepal Length vs Sepal Width')
## Save the plot to a file
plt.savefig('iris_plot.png')
print("Plot saved to iris_plot.png")
从你的终端运行脚本:
python3 main.py
你将看到一条确认消息。
Plot saved to iris_plot.png
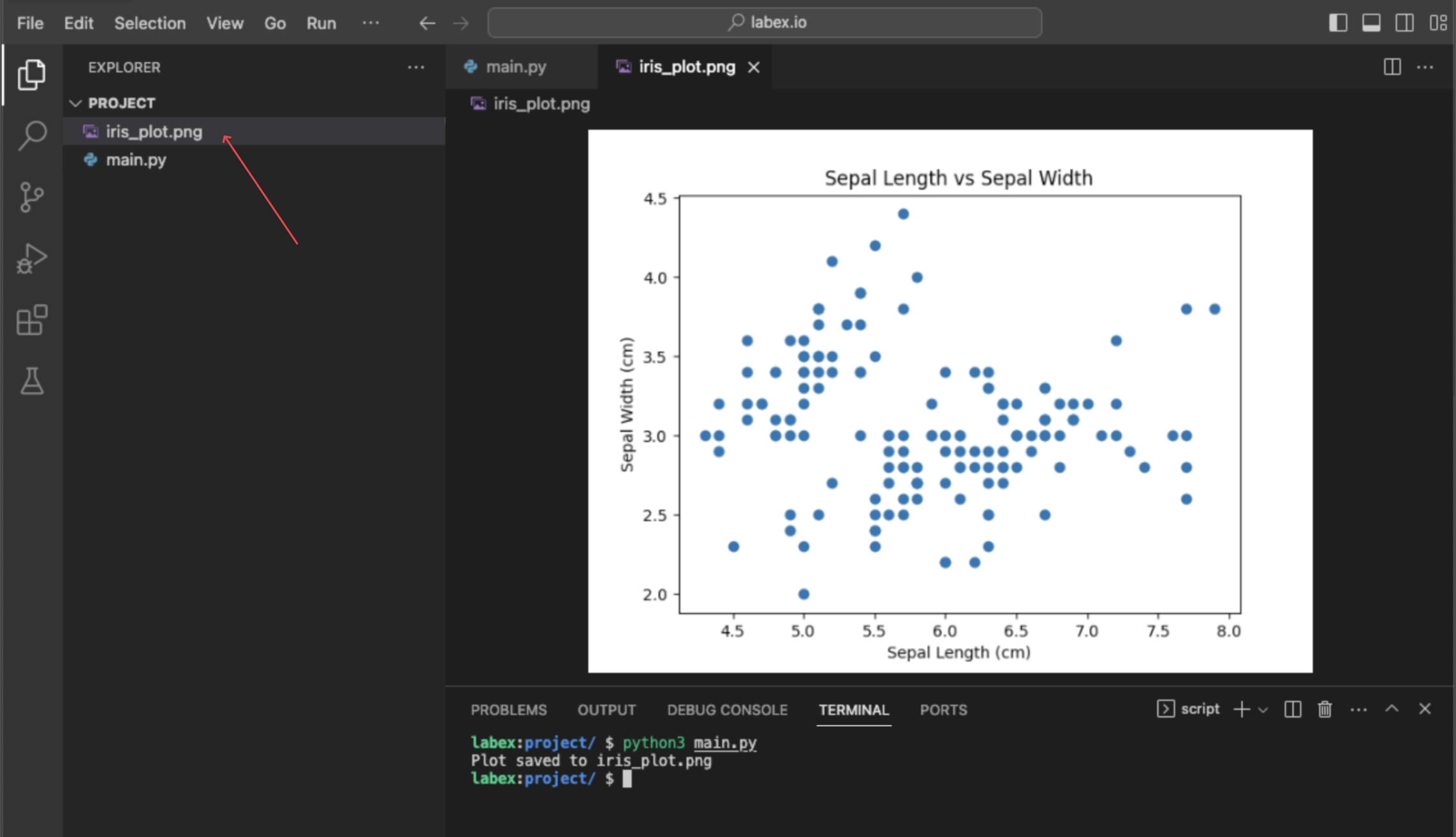
此命令不会直接显示绘图,但它会在你的 ~/project 目录中创建一个名为 iris_plot.png 的新文件。你可以双击左侧文件浏览器中的此文件来查看你的散点图。
总结
恭喜你完成了这个实验!你已经成功迈出了使用 scikit-learn 进行数据处理的第一步。
在这个实验中,你学习了如何:
- 使用
sklearn.datasets.load_iris()加载内置数据集。 - 通过
.data属性访问特征矩阵。 - 通过
.target属性访问目标标签。 - 通过检查
.feature_names属性来理解特征的含义。 - 通过创建散点图并将其保存到文件,使用
matplotlib执行基本的数据可视化。
这些基本技能是更高级机器学习任务的基石。你现在已经准备好探索其他数据集并开始构建你自己的机器学习模型了。


