
介绍
本实验将继续探讨 HDFS,这是 Hadoop 的主要组件之一。学习本实验将帮助你理解 HDFS 的工作原理和基本操作,以及在 Hadoop 软件架构中访问 WebHDFS 的方法。
HDFS 简介
顾名思义,HDFS(Hadoop Distributed File System)是 Hadoop 框架中的一个分布式存储组件,具有容错性和可扩展性。
HDFS 可以作为 Hadoop 集群的一部分使用,也可以作为一个独立的通用分布式文件系统。例如,HBase 是基于 HDFS 构建的,而 Spark 也可以将 HDFS 作为数据源之一。学习 HDFS 的架构和基本操作对于特定集群的配置、优化和故障诊断将有很大帮助。
HDFS 是 Hadoop 应用程序使用的分布式存储,既是数据的来源,也是数据的目的地。HDFS 集群主要由 NameNodes(管理文件系统元数据) 和 DataNodes(存储实际数据) 组成。其架构如下图所示,展示了 NameNodes、DataNodes 和 Clients 之间的交互模式:
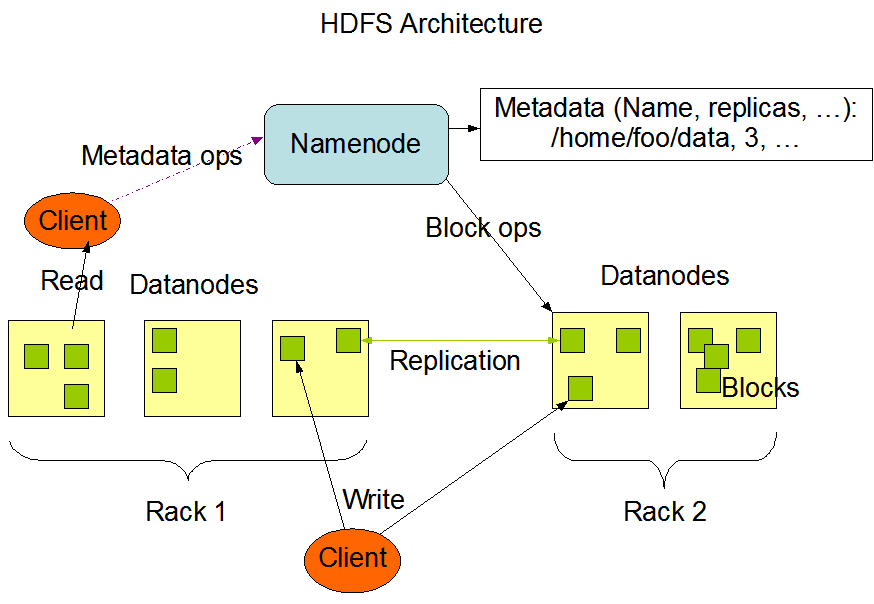
此图引用自 Hadoop 官方网站。
HDFS 介绍总结:
- HDFS 概述:HDFS(Hadoop 分布式文件系统)是 Hadoop 框架中一个具有容错性和可扩展性的分布式存储组件。
- 架构:HDFS 集群由管理元数据的 NameNodes 和存储实际数据的 DataNodes 组成。其架构遵循主从(Master/Slave)模型,包含一个 NameNode 和多个 DataNodes。
- 文件存储:HDFS 中的文件被划分为多个块,存储在不同的 DataNodes 上,默认块大小为 64MB。
- 操作:NameNode 处理文件系统命名空间操作,而 DataNodes 管理来自客户端的读写请求。
- 交互:客户端与 NameNode 通信以获取元数据,并直接与 DataNodes 交互以获取文件数据。
- 部署:通常,一个专用节点运行 NameNode,而其他每个节点运行一个 DataNode 实例。HDFS 使用 Java 构建,提供了跨不同环境的可移植性。
理解这些关于 HDFS 的关键点将有助于有效地配置、优化和诊断 Hadoop 集群。
文件系统总结
文件系统命名空间
- 层次化组织:HDFS 和传统的 Linux 文件系统都支持层次化的文件组织方式,采用目录树结构,允许用户和应用程序创建目录并存储文件。
- 访问与操作:用户可以通过命令行和 API 等多种访问接口与 HDFS 交互,支持文件的创建、删除、移动和重命名等操作。
- 功能支持:截至 3.3.6 版本,HDFS 尚未实现用户配额、访问权限、硬链接或软链接功能。然而,未来的版本可能会支持这些功能,因为其架构允许实现这些特性。
- NameNode 管理:HDFS 中的 NameNode 负责处理文件系统命名空间和属性的所有更改,包括管理文件的复制因子(replication factor),即指定文件在 HDFS 上维护的副本数量。
数据复制
在开发初期,HDFS 被设计为以跨节点、高可靠性的方式在大型集群中存储非常大的文件。如前所述,HDFS 以块的形式存储文件。具体来说,它将每个文件存储为一系列块。除了最后一个块外,文件中的所有块大小相同。
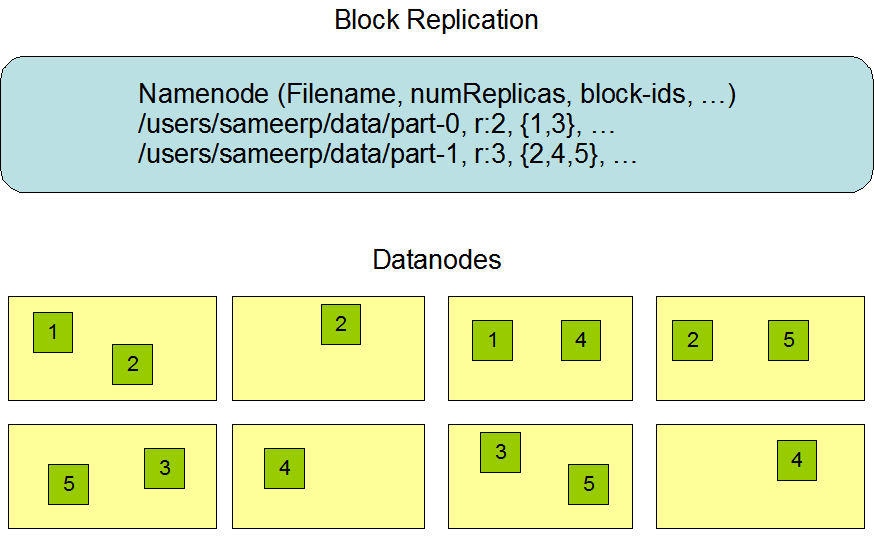
此图引用自 Hadoop 官方网站。
HDFS 数据复制与高可用性:
- 数据复制:在 HDFS 中,文件被划分为块,并在多个 DataNodes 之间复制,以确保容错性。复制因子可以在文件创建或修改时指定,每个文件在任何时刻只能有一个写入者。
- 复制管理:NameNode 通过接收来自 DataNodes 的心跳和块状态报告来管理文件块的复制。DataNodes 通过心跳报告其工作状态,块状态报告包含 DataNode 上存储的所有块的信息。
- 高可用性:HDFS 通过从集群的其他部分恢复丢失的文件副本,在磁盘损坏或其他故障情况下提供一定程度的高可用性。这种机制有助于维护分布式存储系统中的数据完整性和可靠性。
文件系统元数据的持久化
- 命名空间管理:HDFS 命名空间包含文件系统元数据,存储在 NameNode 中。文件系统元数据的每次更改都会记录在 EditLog 中,EditLog 持久化诸如文件创建等事务。EditLog 存储在本地文件系统中。
- FsImage:整个文件系统命名空间,包括块到文件的映射和属性,存储在一个名为 FsImage 的文件中。该文件也保存在 NameNode 所在的本地文件系统中。
- 检查点(Checkpoint)过程:检查点过程涉及在 NameNode 启动时从磁盘读取 FsImage 和 EditLog。EditLog 中的所有事务都会应用到内存中的 FsImage,然后将其保存回磁盘以实现持久化。在此过程之后,旧的 EditLog 可以被截断。在当前版本(3.3.6)中,检查点仅在 NameNode 启动时发生,但未来的版本可能会引入定期检查点以提高可靠性和数据一致性。
其他特性
- 基于 TCP/IP:HDFS 中的所有通信协议都建立在 TCP/IP 协议栈之上,确保分布式文件系统中节点之间的可靠数据交换。
- 客户端协议:客户端与 NameNode 之间的通信通过客户端协议(Client protocol)实现。客户端连接到 NameNode 上可配置的 TCP 端口,以与文件系统元数据进行交互。
- DataNode 协议:DataNodes 与 NameNode 之间的通信依赖于 DataNode 协议。DataNodes 与 NameNode 通信以报告其状态、发送心跳信号并传输数据块,作为分布式存储系统的一部分。
- 远程过程调用(RPC):客户端协议和 DataNode 协议都通过远程过程调用(RPC)机制进行抽象。NameNode 响应由 DataNodes 或客户端发起的 RPC 请求,在通信过程中保持被动角色。
以下是扩展阅读的一些资料:
切换用户
在编写任务代码之前,你应该先切换到 hadoop 用户。双击打开桌面上的 Xfce 终端,并输入以下命令。hadoop 用户的密码是 hadoop,切换用户时需要输入:
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
提示:hadoop 用户的密码是 hadoop
初始化 HDFS
在使用 HDFS 之前,需要先初始化 Namenode。此操作可以类比为格式化磁盘,因此在 HDFS 上存储数据时请谨慎使用此命令。
否则,请在本节中重新启动实验。使用“默认环境”并通过以下命令初始化 HDFS:
/home/hadoop/hadoop/bin/hdfs namenode -format
提示:上述命令将格式化 HDFS 文件系统,运行此命令前需要删除 HDFS 数据目录。
因此,你需要停止与 Hadoop 相关的服务并删除 Hadoop 数据:
stop-all.sh
rm -rf ~/hadoopdata
当你看到以下消息时,表示初始化已完成:
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
导入文件
由于 HDFS 是一个构建在本地磁盘之上的分层 分布式存储系统,在使用 HDFS 之前,你需要将数据导入其中。
准备文件的第一种也是最方便的方法是使用 Hadoop 的配置文件作为示例。
首先,你需要启动 HDFS 守护进程:
/home/hadoop/hadoop/sbin/start-dfs.sh
查看服务状态:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
创建一个目录并复制数据,在终端中输入以下命令:
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
列出目录内容:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
任何对 HDFS 的操作都以 hdfs dfs 开头,并辅以相应的操作参数。最常用的参数是 put,其用法如下,可以在终端中输入:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
列出目录内容:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
命令的最后一部分 /policy.xml 表示存储在 HDFS 中的文件名为 policy.xml,路径为 /(根目录)。如果你想继续使用之前的文件名,可以直接指定路径 /。
如果需要上传多个文件,可以连续指定本地目录的文件路径,并以 HDFS 目标存储路径结尾:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
列出目录内容:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
对于指定路径相关的参数,规则与 Linux 系统中的规则相同。你可以使用通配符(如 *.sh)来简化操作。
文件操作
同样地,你可以使用 -ls 参数列出指定目录中的文件:
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
此处列出的文件可能会因实验环境的不同而有所变化。
如果你需要查看文件的内容,可以使用 cat 参数。最容易想到的是直接在 HDFS 上指定文件路径。如果你需要将本地目录与 HDFS 上的文件进行比较,可以分别指定它们的路径。但需要注意的是,本地目录需要以 file:// 指示符开头,并辅以文件路径(例如 /home/hadoop/.bashrc,不要忘记前面的 /)。否则,此处指定的任何路径都将默认被识别为 HDFS 上的路径:
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
输出如下:
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
如果你需要将文件复制到另一个路径,可以使用 cp 参数:
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
同样地,如果你需要移动文件,可以使用 mv 参数。这与 Linux 文件系统命令格式基本相同:
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
使用 lsr 参数列出当前目录的内容,包括子目录的内容。输出如下:
hdfs dfs -lsr /
如果你想在 HDFS 上的文件中追加一些新内容,可以使用 appendToFile 参数。并且,在指定要追加的本地文件路径时,可以指定多个路径。最后一个参数将是追加的目标文件。该文件必须存在于 HDFS 上,否则会报错:
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
你可以使用 tail 参数查看文件尾部的内容(文件的末尾部分),以确认追加是否成功:
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
查看 tail 命令的输出:
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
如果你需要删除文件或目录,可以使用 rm 参数。该参数还可以伴随 -r 和 -f,它们的含义与 Linux 文件系统命令 rm 中的含义相同:
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
文件 moved_file.txt 的内容将被删除,命令将返回以下输出 'Deleted /moved_file.txt'
目录操作
在前面的内容中,我们已经学习了如何在 HDFS 中创建目录。实际上,如果你需要一次性创建多个目录,可以直接指定多个目录的路径作为参数。-p 参数表示如果父目录不存在,则会自动创建它:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
如果你想查看某个文件或目录占用了多少空间,可以使用 du 参数:
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
输出如下:
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
导出文件
在上一节中,我们主要介绍了 HDFS 中的文件和目录操作。如果某个应用程序(如 MapReduce)计算完成并生成了记录结果的文件,你可以使用 get 参数将其导出到 Linux 系统的本地目录中。
这里的第一个路径参数指的是 HDFS 中的路径,最后一个路径指的是保存在本地目录中的路径:
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
如果导出成功,你可以在本地目录中找到该文件:
cd ~
ls
输出如下:
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Hadoop Web 操作
Web 管理界面
每个 NameNode 或 DataNode 内部都运行着一个 Web 服务器,用于显示集群当前状态等基本信息。在默认配置中,NameNode 的主页是 http://localhost:9870/。它列出了 DataNodes 和集群的基本统计信息。
打开一个网页浏览器,在地址栏中输入以下内容:
http://localhost:9870/
你可以在 Summary 中看到当前“集群”中活跃的 DataNode 节点数量:
Web 界面还可以用于浏览 HDFS 内部的目录和文件。在顶部的菜单栏中,点击“Utilities”下的“Browse the file system”链接:
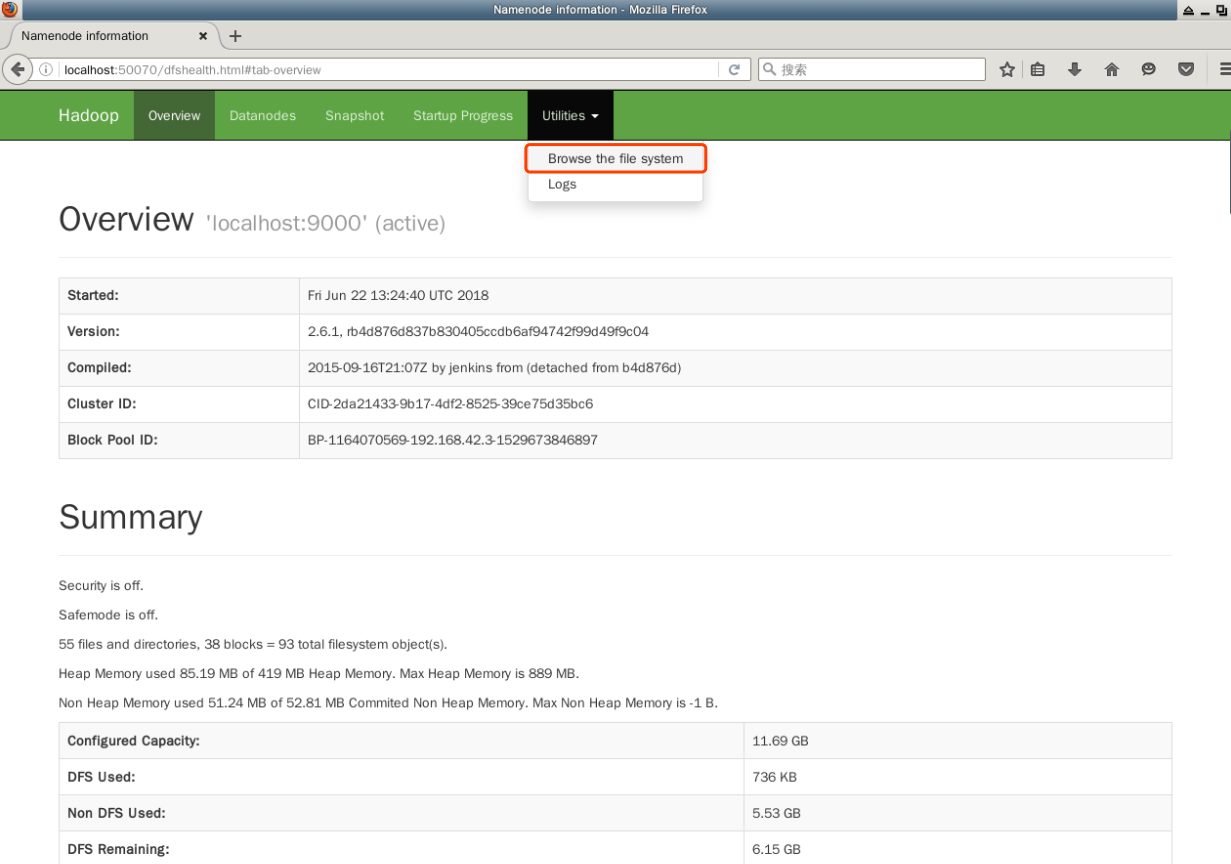
关闭 Hadoop 集群
现在我们已经介绍了一些 WebHDFS 的基本操作。更多说明可以在 WebHDFS 的文档中找到。本实验已接近尾声。按照习惯,我们仍然需要关闭 Hadoop 集群:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
总结
本实验介绍了 HDFS 的架构。同时,我们从命令行学习了基本的 HDFS 操作命令,然后转向了 HDFS 的 Web 访问模式,这将帮助 HDFS 作为外部应用程序的真实存储服务运行。
本实验没有列出任何在 WebHDFS 中删除文件的场景。你可以自行查阅文档。更多功能隐藏在官方文档中,因此请确保保持阅读文档的兴趣。
以下是扩展阅读的材料:


