
Introdução
O OpenAI Whisper se destaca na conversão de fala de vários arquivos de mídia, incluindo áudio e vídeo, em texto escrito. Este tutorial irá guiá-lo através dos usos essenciais e mais sofisticados do comando Whisper, facilitando transcrições de alta precisão.
Dominando o Whisper para Transcrição de Mídia
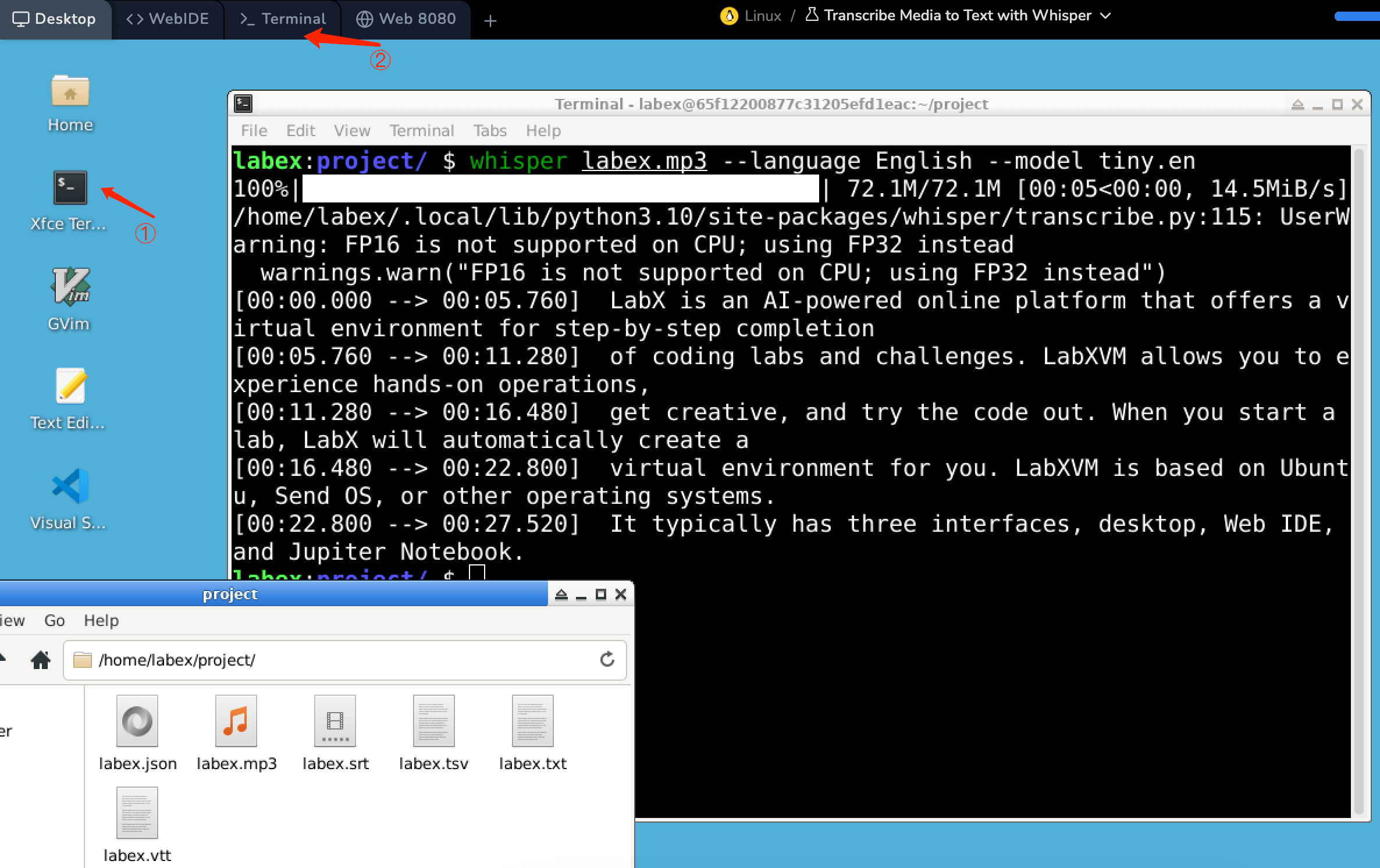
Há um áudio labex.mp3 em /home/labex/project, abra o terminal ( ① ou ② na figura ) no ambiente e insira o seguinte comando:
whisper labex.mp3 --language English --model tiny.en
Neste comando, whisper é instruído a transcrever o arquivo de mídia labex.mp3.
- O parâmetro
--languageé definido como Inglês, indicando o idioma falado na mídia. - A opção
--modelseleciona o modelo Whisper a ser usado, comtiny.ensendo um modelo menor e mais rápido, otimizado para o idioma inglês, adequado para tarefas rápidas ou hardware menos potente.
Após executar o comando Whisper para transcrever o conteúdo da mídia, vários arquivos podem ser gerados em /home/labex/project, cada um servindo a um propósito e formato distintos para o texto transcrito. Aqui está uma visão geral de cada tipo de arquivo:
- output.json: Este arquivo contém os resultados detalhados da transcrição em formato JSON, que é um formato de intercâmbio de dados leve, fácil de ler e escrever para humanos e fácil de analisar e gerar para máquinas. O arquivo JSON inclui não apenas o texto transcrito, mas também metadados adicionais, como carimbos de data/hora, pontuações de confiança e, possivelmente, identificação do orador. Este formato é particularmente útil para aplicações que exigem processamento ou análise detalhada dos resultados da transcrição, como para gerar legendas com tempo preciso ou para analisar padrões de fala.
- output.srt: O formato de arquivo SRT (SubRip Subtitle) é usado para representar legendas ou legendas ocultas. Cada entrada em um arquivo SRT consiste em um número de sequência, o intervalo de tempo durante o qual o texto deve ser exibido e o próprio texto. Arquivos SRT são amplamente suportados por software e plataformas de reprodução de vídeo, tornando este formato ideal para adicionar legendas a vídeos.
- output.tsv: TSV significa Tab-Separated Values (Valores Separados por Tabulação). Este formato é semelhante ao CSV (Comma-Separated Values), mas usa tabulações como delimitadores entre os campos de dados. Um arquivo output.tsv do Whisper pode conter texto transcrito junto com informações de tempo e pontuações de confiança, separadas por tabulações. Este formato pode ser útil para tarefas de análise de dados ou para importar os resultados da transcrição para bancos de dados ou planilhas.
- output.txt: Este é um arquivo de texto simples contendo apenas o texto transcrito sem nenhum carimbo de data/hora ou metadados. A simplicidade deste formato o torna adequado para aplicações onde o conteúdo do texto é mais importante do que o tempo ou onde o texto precisa ser lido ou processado por humanos ou software básico de processamento de texto.
- output.vtt: VTT (Web Video Text Tracks) é outro formato de arquivo de legenda semelhante ao SRT, mas com mais recursos. É o formato padrão para legendas de tags de vídeo HTML5 e oferece suporte para estilização e posicionamento de legendas. O formato VTT é particularmente útil para conteúdo de vídeo da web, pois permite uma experiência de visualização mais rica com legendas personalizáveis.
Cada um desses arquivos serve a diferentes casos de uso, desde documentos de texto simples até análises detalhadas ou legendagem de vídeo, proporcionando flexibilidade na forma como os resultados da transcrição são utilizados.
Resumo
Este tutorial guiou você através do uso do OpenAI Whisper para transcrever conteúdo de arquivos de mídia em texto. Começando pelos conceitos básicos, aprendemos a transcrever um simples arquivo de mídia em inglês. Em seguida, avançamos para explorar recursos adicionais para otimizar o processo de transcrição, como escolher diferentes modelos e processamento em lote. O Whisper se destaca como uma ferramenta versátil para transcrever uma ampla variedade de arquivos de mídia com facilidade.


