
Introdução
Este laboratório continuará a abordar o HDFS, um dos principais componentes do Hadoop. Aprender neste laboratório ajudará você a entender os princípios de funcionamento e as operações básicas do HDFS, bem como os métodos de acesso para o WebHDFS na arquitetura de software Hadoop.
Introdução ao HDFS
Como o nome indica, HDFS (Hadoop Distributed File System) é um componente de armazenamento distribuído dentro do framework Hadoop, sendo tolerante a falhas e escalável.
O HDFS pode ser usado como parte de um cluster Hadoop ou como um sistema de arquivos distribuído universal e independente. Por exemplo, o HBase é construído com base no HDFS e o Spark também pode usar o HDFS como uma das fontes de dados. Aprender a arquitetura e as operações básicas do HDFS será de grande ajuda para a configuração, aprimoramento e diagnóstico de clusters específicos.
O HDFS é o armazenamento distribuído usado pelas aplicações Hadoop, a fonte e o destino dos dados. Os clusters HDFS são compostos principalmente por NameNodes que gerenciam metadados do sistema de arquivos e DataNodes que armazenam os dados reais. A arquitetura é mostrada na imagem a seguir, que ilustra os padrões de interação entre NameNodes, DataNodes e Clients:
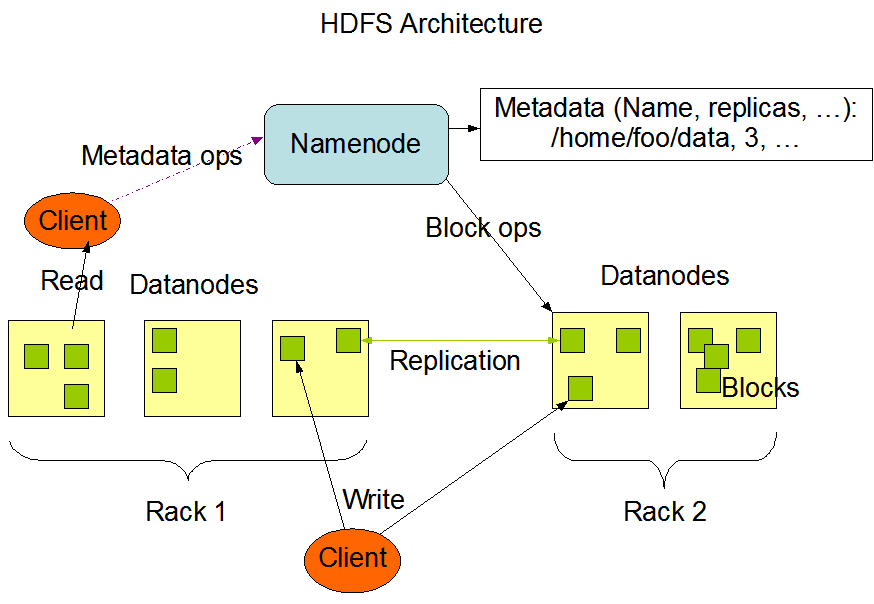 Esta imagem é citada do site oficial do Hadoop.
Esta imagem é citada do site oficial do Hadoop.
Resumo da Introdução ao HDFS:
- Visão Geral do HDFS: HDFS (Hadoop Distributed File System) é um componente de armazenamento distribuído tolerante a falhas e escalável dentro do framework Hadoop.
- Arquitetura: Os clusters HDFS consistem em NameNodes para gerenciar metadados e DataNodes para armazenar dados reais. A arquitetura segue um modelo Master/Slave com um NameNode e múltiplos DataNodes.
- Armazenamento de Arquivos: Os arquivos no HDFS são divididos em blocos armazenados em DataNodes, com um tamanho de bloco padrão de 64MB.
- Operações: O NameNode lida com as operações do namespace do sistema de arquivos, enquanto os DataNodes gerenciam as solicitações de leitura e escrita dos clientes.
- Interações: Os clientes se comunicam com o NameNode para metadados e interagem diretamente com os DataNodes para dados de arquivos.
- Implantação: Tipicamente, um único nó dedicado executa o NameNode, enquanto cada outro nó executa uma instância de DataNode. O HDFS é construído usando Java, fornecendo portabilidade em diferentes ambientes.
Compreender esses pontos-chave sobre o HDFS ajudará na configuração, otimização e diagnóstico eficazes de clusters Hadoop.
Resumo do Sistema de Arquivos
Namespace do Sistema de Arquivos
- Organização Hierárquica: Tanto o HDFS quanto os sistemas de arquivos Linux tradicionais suportam a organização hierárquica de arquivos com uma estrutura de árvore de diretórios, permitindo que usuários e aplicações criem diretórios e armazenem arquivos.
- Acesso e Operações: Os usuários podem interagir com o HDFS através de várias interfaces de acesso, como linhas de comando e APIs, permitindo operações como criação, exclusão, movimentação e renomeação de arquivos.
- Suporte a Recursos: A partir da versão 3.3.6, o HDFS não implementa cotas de usuário, direitos de acesso, hard links ou soft links. No entanto, versões futuras podem suportar esses recursos, pois a arquitetura permite sua implementação.
- Gerenciamento do NameNode: O NameNode no HDFS lida com todas as alterações no namespace e nas propriedades do sistema de arquivos, incluindo o gerenciamento do fator de replicação de arquivos, que especifica o número de cópias de um arquivo a serem mantidas no HDFS.
Cópia de Dados
No início do desenvolvimento, o HDFS foi projetado para armazenar arquivos muito grandes em um grande cluster de forma distribuída e altamente confiável. Como mencionado anteriormente, o HDFS armazena arquivos em blocos. Especificamente, ele armazena cada arquivo como uma sequência de blocos. Exceto pelo último bloco, todos os blocos do arquivo têm o mesmo tamanho.
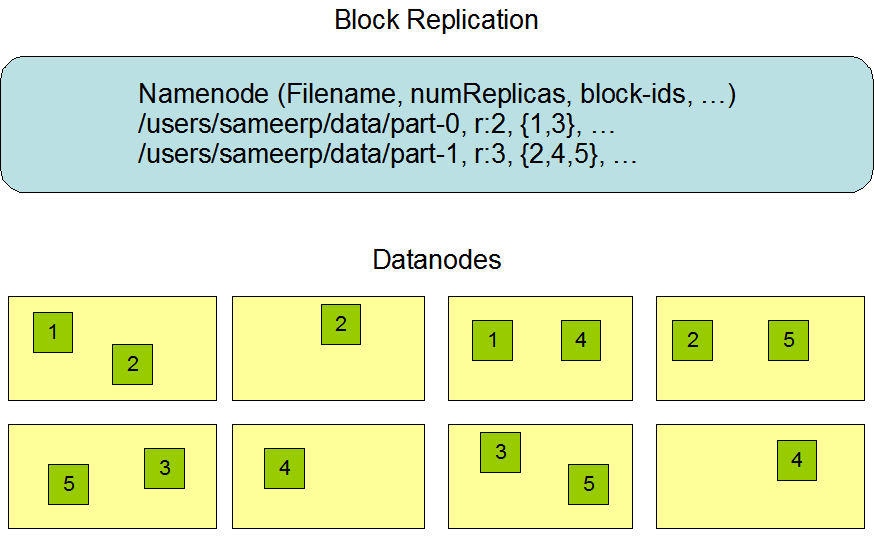 Esta imagem é citada do site oficial do Hadoop.
Esta imagem é citada do site oficial do Hadoop.
A Replicação de Dados e Alta Disponibilidade do HDFS:
- Replicação de Dados: No HDFS, os arquivos são divididos em blocos que são replicados em vários DataNodes para garantir a tolerância a falhas. O fator de replicação pode ser especificado quando o arquivo é criado ou modificado, com cada arquivo tendo um único escritor em um determinado momento.
- Gerenciamento de Replicação: O NameNode gerencia como os blocos de arquivos são copiados recebendo relatórios de heartbeat e status de blocos dos DataNodes. Os DataNodes relatam seu estado de trabalho através de heartbeats, e os relatórios de status de blocos contêm informações sobre todos os blocos armazenados no DataNode.
- Alta Disponibilidade: O HDFS fornece um grau de alta disponibilidade restaurando internamente cópias de arquivos perdidas de outras partes do cluster em caso de corrupção de disco ou outras falhas. Esse mecanismo ajuda a manter a integridade e a confiabilidade dos dados dentro do sistema de armazenamento distribuído.
Persistência dos Metadados do Sistema de Arquivos
- Gerenciamento do Namespace: O namespace do HDFS, contendo metadados do sistema de arquivos, é armazenado no NameNode. Cada alteração nos metadados do sistema de arquivos é registrada em um EditLog, que persiste transações como a criação de arquivos. O EditLog é armazenado no sistema de arquivos local.
- FsImage: Todo o namespace do sistema de arquivos, incluindo o mapeamento de bloco para arquivo e atributos, é armazenado em um arquivo chamado FsImage. Este arquivo também é salvo no sistema de arquivos local onde o NameNode reside.
- Processo de Checkpoint: O processo de Checkpoint envolve a leitura do FsImage e do EditLog do disco na inicialização do NameNode. Todas as transações no EditLog são aplicadas ao FsImage na memória, que é então salvo de volta no disco para persistência. Após este processo, o EditLog antigo pode ser truncado. Na versão atual (3.3.6), os checkpoints ocorrem apenas durante a inicialização do NameNode, mas versões futuras podem introduzir checkpointing periódico para melhorar a confiabilidade e a consistência dos dados.
Outras Características
- Fundamento TCP/IP: Todos os protocolos de comunicação no HDFS são construídos sobre o conjunto de protocolos TCP/IP, garantindo a troca confiável de dados entre os nós no sistema de arquivos distribuído.
- Protocolo do Cliente: A comunicação entre o cliente e o NameNode é facilitada através do protocolo do Cliente. O cliente inicia uma conexão com portas TCP configuráveis no NameNode para interagir com os metadados do sistema de arquivos.
- Protocolo do DataNode: A comunicação entre os DataNodes e o NameNode depende do protocolo do DataNode. Os DataNodes se comunicam com o NameNode para relatar seu status, enviar sinais de heartbeat e transferir blocos de dados como parte do sistema de armazenamento distribuído.
- Chamada de Procedimento Remoto (RPC): Tanto o protocolo do Cliente quanto o protocolo do DataNode são abstraídos usando mecanismos de Chamada de Procedimento Remoto (RPC). O NameNode responde às solicitações RPC iniciadas pelos DataNodes ou clientes, mantendo um papel passivo no processo de comunicação.
O seguinte é algum material para leitura estendida:
Trocar de Usuário
Antes de escrever o código da tarefa, você deve primeiro mudar para o usuário hadoop. Dê um duplo clique para abrir o terminal Xfce na sua área de trabalho e digite o seguinte comando. A senha do usuário hadoop é hadoop; ela será necessária ao mudar de usuário:
su - hadoop
labex:~/ $ su - hadoop
hadoop:~$
dica: a senha do usuário hadoop é hadoop
Inicializando o HDFS
O Namenode deve ser inicializado antes de usar o HDFS pela primeira vez. Esta operação pode ser comparada à formatação de um disco, portanto, use este comando com cautela ao armazenar dados no HDFS.
Caso contrário, reinicie o experimento nesta seção. Use o "Ambiente Padrão" e inicialize o HDFS com o seguinte comando:
/home/hadoop/hadoop/bin/hdfs namenode -format
dica: O comando acima irá formatar o sistema de arquivos HDFS, você precisa deletar o diretório de dados do HDFS antes de executar o comando.
Então, você precisa parar os serviços relacionados ao Hadoop e deletar os dados do Hadoop.
stop-all.sh
rm -rf ~/hadoopdata
Quando você vir a seguinte mensagem, a inicialização estará completa:
2024-03-01 11:16:10,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
Importando Arquivos
Como o HDFS é um sistema de armazenamento distribuído em camadas construído sobre discos locais, você precisa importar dados para ele antes de usar o HDFS.
A primeira e mais conveniente maneira de preparar alguns arquivos é usar o arquivo de configuração do Hadoop como exemplo.
Primeiro, você precisa iniciar o daemon HDFS:
/home/hadoop/hadoop/sbin/start-dfs.sh
Visualize os serviços:
hadoop:~$ jps
8341 SecondaryNameNode
7962 NameNode
8474 Jps
8107 DataNode
Crie um diretório e copie os dados digitando o seguinte comando no terminal:
cd /home/hadoop
mkdir sample_data
cp -r /home/hadoop/hadoop/etc/hadoop/* sample_data/
Liste o conteúdo do diretório:
hadoop:~$ ls /home/hadoop/sample_data/
capacity-scheduler.xml kms-log4j.properties
configuration.xsl kms-site.xml
...
Qualquer operação no HDFS começa com hdfs dfs e é complementada pelos parâmetros operacionais correspondentes. O parâmetro mais comumente usado é put, que é usado da seguinte forma e pode ser inserido no terminal:
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/hadoop-policy.xml /policy.xml
Liste o conteúdo do diretório:
hadoop:~$ hdfs dfs -ls /policy.xml
-rw-r--r-- 1 hadoop supergroup 11765 2024-03-01 11:37 /policy.xml
O último /policy.xml do comando significa que o nome do arquivo armazenado no HDFS é policy.xml e o caminho é / (diretório raiz). Se você quiser continuar usando o nome do arquivo anterior, pode especificar o caminho / diretamente.
Se você precisar fazer upload de vários arquivos, pode especificar o caminho do arquivo do diretório local continuamente e terminar com o caminho de armazenamento de destino do HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop
/home/hadoop/hadoop/bin/hdfs dfs -put /home/hadoop/sample_data/httpfs-env.sh /home/hadoop/sample_data/mapred-env.sh /user/hadoop
Liste o conteúdo do diretório:
hadoop:~$ hdfs dfs -ls /user/hadoop
Found 2 items
-rw-r--r-- 1 hadoop supergroup 1484 2024-03-01 11:42 /user/hadoop/httpfs-env.sh
-rw-r--r-- 1 hadoop supergroup 1764 2024-03-01 11:42 /user/hadoop/mapred-env.sh
Para especificar parâmetros relacionados a caminhos, as regras são as mesmas do sistema Linux. Você pode usar curingas (como *.sh) para simplificar a operação.
Operações com Arquivos
Da mesma forma, você pode usar o parâmetro -ls para listar os arquivos no diretório especificado:
/home/hadoop/hadoop/bin/hdfs dfs -ls /user/hadoop
Os arquivos listados aqui podem variar dependendo do ambiente do experimento.
Se você precisar ver o conteúdo de um arquivo, pode usar o parâmetro cat. A coisa mais fácil de pensar é especificar um caminho de arquivo diretamente no HDFS. Se você precisar comparar diretórios locais com arquivos no HDFS, pode especificar seus caminhos separadamente. No entanto, deve-se notar que o diretório local precisa começar com o indicador file://, complementado pelo caminho do arquivo (como /home/hadoop/.bashrc, não se esqueça da / na frente). Caso contrário, qualquer caminho especificado aqui será reconhecido por padrão como o caminho no HDFS:
/home/hadoop/hadoop/bin/hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
A saída é a seguinte:
hadoop:~$ hdfs dfs -cat file:///home/hadoop/.bashrc /user/hadoop/mapred-env.sh
## ~/.bashrc: executed by bash(1) for non-login shells.
## see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
## for examples
## If not running interactively, don't do anything
case $- in
...
Se você precisar copiar um arquivo para outro caminho, pode usar o parâmetro cp:
/home/hadoop/hadoop/bin/hdfs dfs -cp /user/hadoop/mapred-env.sh /user/hadoop/copied_file.txt
Da mesma forma, se você precisar mover um arquivo, use o parâmetro mv. Isso é basicamente o mesmo que o formato de comando do sistema de arquivos Linux:
/home/hadoop/hadoop/bin/hdfs dfs -mv /user/hadoop/mapred-env.sh /moved_file.txt
Use o parâmetro lsr para listar o conteúdo do diretório atual, incluindo o conteúdo dos subdiretórios. A saída é a seguinte:
hdfs dfs -lsr /
Se você quiser anexar algum novo conteúdo a um arquivo no HDFS, pode usar o parâmetro appendToFile. E, ao especificar o caminho do arquivo local a ser anexado, você pode especificar vários deles. O último parâmetro será o objeto a ser anexado. O arquivo deve existir no HDFS, caso contrário, um erro será relatado:
echo 1 >> a.txt
echo 2 >> b.txt
/home/hadoop/hadoop/bin/hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
Você pode usar o parâmetro tail para ver o conteúdo da cauda do arquivo (a parte final do arquivo) para confirmar se a anexação foi bem-sucedida:
/home/hadoop/hadoop/bin/hdfs dfs -tail /user/hadoop/mapred-env.sh
Visualize a saída do comando tail:
hadoop:~$ echo 1 >> a.txt
echo 2 >> b.txt
hdfs dfs -appendToFile a.txt b.txt /user/hadoop/mapred-env.sh
hadoop:~$ hdfs dfs -tail /user/hadoop/mapred-env.sh
1
2
Se você precisar excluir um arquivo ou um diretório, use o parâmetro rm. Este parâmetro também pode ser acompanhado por -r e -f, que têm os mesmos significados que têm para o comando do sistema de arquivos Linux rm:
/home/hadoop/hadoop/bin/hdfs dfs -rm /moved_file.txt
O conteúdo do arquivo moved_file.txt será excluído, e o comando retornará a seguinte saída 'Deleted /moved_file.txt'
Operações com Diretórios
No conteúdo anterior, aprendemos como criar um diretório no HDFS. Na verdade, se você precisar criar vários diretórios de uma vez, pode especificar diretamente os caminhos de vários diretórios como parâmetros. O parâmetro -p indica que seu diretório pai será criado automaticamente se não existir:
/home/hadoop/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop/dir1 /user/hadoop/dir2/sub_dir1
Se você quiser ver quanto espaço um determinado arquivo ou diretório ocupa, pode usar o parâmetro du:
/home/hadoop/hadoop/bin/hdfs dfs -du /user/hadoop/
A saída é a seguinte:
hadoop:~$ hdfs dfs -du /user/hadoop/
1764 1764 /user/hadoop/copied_file.txt
0 0 /user/hadoop/dir1
0 0 /user/hadoop/dir2
1484 1484 /user/hadoop/httpfs-env.sh
4 4 /user/hadoop/mapred-env.sh
Exportando Arquivos
Na seção anterior, apresentamos principalmente as operações de arquivo e diretório no HDFS. Se uma aplicação como o MapReduce for calculada e o arquivo que registra o resultado for gerado, você pode usar o parâmetro get para exportá-lo para o diretório local do sistema Linux.
O primeiro parâmetro de caminho aqui se refere ao caminho no HDFS, e o último caminho se refere ao caminho salvo no diretório local:
/home/hadoop/hadoop/bin/hdfs dfs -get /user/hadoop/mapred-env.sh /home/hadoop/exported_file.txt
Se a exportação for bem-sucedida, você pode encontrar o arquivo em seu diretório local:
cd ~
ls
A saída é a seguinte:
a.txt b.txt exported_file.txt hadoop hadoopdata sample_data
Operação Web do Hadoop
Interface de Gerenciamento Web
Cada NameNode ou DataNode executa internamente um servidor web que exibe informações básicas, como o estado atual do cluster. Na configuração padrão, a página inicial do NameNode é http://localhost:9870/. Ela lista estatísticas básicas para DataNodes e clusters.
Abra um navegador web e insira o seguinte na barra de endereço:
http://localhost:9870/
Você pode ver o número de nós DataNode ativos no "cluster" atual em Summary:
A interface web também pode ser usada para navegar por diretórios e arquivos dentro do HDFS. Na barra de menu no topo, clique no link "Browse the file system" (Navegar pelo sistema de arquivos) em "Utilities" (Utilitários):
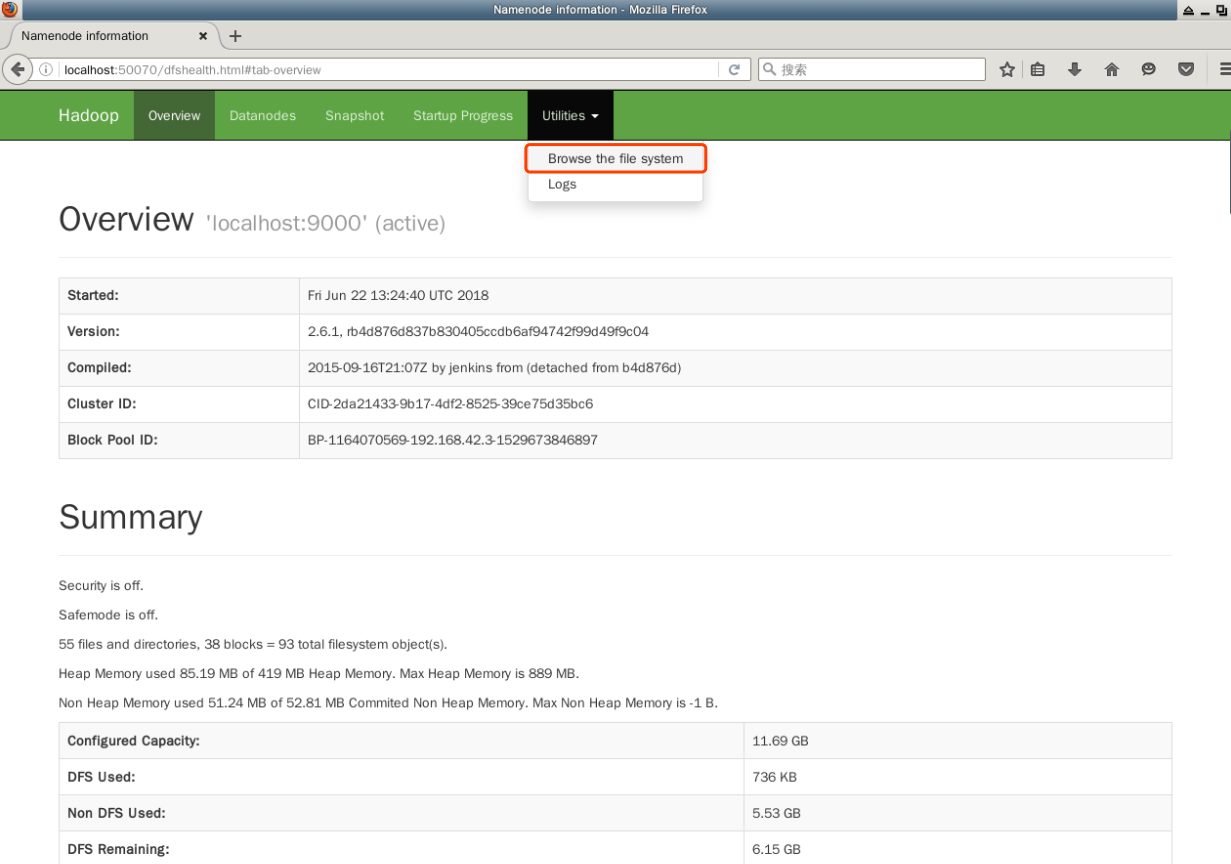
Encerrar um Cluster Hadoop
Agora terminamos de apresentar algumas das operações básicas do WebHDFS. Mais instruções podem ser encontradas na documentação do WebHDFS. Este laboratório chegou ao fim. Como um hábito, ainda precisamos fechar o cluster Hadoop:
/home/hadoop/hadoop/sbin/stop-yarn.sh
/home/hadoop/hadoop/sbin/stop-dfs.sh
hadoop:~$ jps
11633 Jps
Resumo
Este laboratório apresentou a arquitetura do HDFS. Além disso, aprendemos os comandos básicos de operação do HDFS a partir da linha de comando e, em seguida, passamos para o padrão de acesso web do HDFS, o que ajudará o HDFS a funcionar como um serviço de armazenamento real para aplicações externas.
Este laboratório não lista nenhum cenário de exclusão de arquivos no WebHDFS. Você pode verificar a documentação por conta própria. Mais recursos estão escondidos na documentação oficial, então certifique-se de manter o interesse em ler a documentação.
O seguinte é o material para leitura estendida:


