
소개
이번 실습에서는 가장 인기 있는 Python 라이브러리 중 하나인 scikit-learn을 사용하여 머신러닝 모델을 구축하는 기초를 배웁니다. 가격이나 온도와 같은 연속적인 값을 예측하는 데 사용되는 기본적이면서도 강력한 알고리즘인 선형 회귀(Linear Regression)에 집중할 것입니다.
우리의 목표는 캘리포니아 지역의 중간 주택 가격을 예측할 수 있는 모델을 만드는 것입니다. 이를 위해 scikit-learn에 기본적으로 포함되어 있는 캘리포니아 주택 데이터셋을 사용합니다.
이번 실습을 통해 다음 내용을 학습합니다:
scikit-learn에서 데이터셋 불러오기- 학습 및 테스트를 위한 데이터 준비 및 분할
- 선형 회귀 모델 생성 및 학습
- 학습된 모델을 사용하여 예측 수행
- 결과를 시각화하여 모델 성능 이해하기
모든 작업은 WebIDE 내에서 수행됩니다. 시작해 봅시다!
datasets.fetch_california_housing()으로 캘리포니아 주택 데이터셋 불러오기
이 단계에서는 모델을 위한 데이터셋을 불러오는 것부터 시작합니다. scikit-learn은 학습과 연습에 유용한 여러 내장 데이터셋을 제공합니다. 여기서는 캘리포니아 주택 데이터셋을 사용하겠습니다.
먼저 Python 스크립트를 생성해야 합니다. ~/project 디렉토리에 main.py 파일이 이미 생성되어 있습니다. WebIDE 왼쪽의 파일 탐색기에서 확인할 수 있습니다.
main.py를 열고 다음 코드를 추가하세요. 이 코드는 필요한 라이브러리(sklearn.datasets에서 fetch_california_housing 및 pandas)를 가져오고 데이터셋을 불러옵니다. pandas를 사용하여 데이터를 DataFrame으로 변환할 것입니다. DataFrame은 데이터를 쉽게 확인하고 조작할 수 있는 표 형태의 데이터 구조입니다.
main.py에 다음 코드를 추가하세요:
import pandas as pd
from sklearn.datasets import fetch_california_housing
## 캘리포니아 주택 데이터셋 불러오기
california = fetch_california_housing()
## DataFrame 생성
california_df = pd.DataFrame(california.data, columns=california.feature_names)
california_df['MedHouseVal'] = california.target
## DataFrame의 첫 5개 행 출력
print("California Housing Dataset:")
print(california_df.head())
이제 스크립트를 실행하여 결과를 확인해 봅시다. WebIDE에서 터미널을 열고("Terminal" -> "New Terminal" 메뉴 사용) 다음 명령어를 실행하세요:
python3 main.py
콘솔에 데이터셋의 첫 5개 행이 출력되는 것을 볼 수 있습니다. MedHouseVal 열은 우리의 타겟 변수로, 캘리포니아 지역의 중간 주택 가격을 나타내며 단위는 10만 달러($100,000)입니다.
California Housing Dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude Longitude MedHouseVal
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88 -122.23 4.526
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86 -122.22 3.585
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85 -122.24 3.521
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85 -122.25 3.413
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85 -122.25 3.422
sklearn.model_selection의 train_test_split으로 데이터 분할하기
이 단계에서는 학습 과정을 위해 데이터를 준비합니다. 머신러닝에서 가장 중요한 부분은 모델이 한 번도 본 적 없는 데이터로 모델을 평가하는 것입니다. 이를 위해 데이터셋을 학습 세트(training set)와 테스트 세트(testing set) 두 부분으로 나눕니다. 모델은 학습 세트로 학습하고, 테스트 세트를 사용하여 성능을 확인합니다.
먼저 특징(입력 변수, X)과 타겟(예측하려는 값, y)을 분리해야 합니다. 우리의 경우 X는 MedHouseVal을 제외한 모든 열이 되고, y는 MedHouseVal 열이 됩니다.
그런 다음 sklearn.model_selection의 train_test_split 함수를 사용하여 데이터를 분할합니다.
main.py 파일에 다음 코드를 추가하세요.
from sklearn.model_selection import train_test_split
## 데이터 준비
X = california_df.drop('MedHouseVal', axis=1) ## 특징 (입력 변수)
y = california_df['MedHouseVal'] ## 타겟 변수 (예측하려는 값)
## 데이터를 학습 세트와 테스트 세트로 분할
## test_size=0.2: 데이터의 20%를 테스트용으로, 80%를 학습용으로 사용
## random_state=42: 실행할 때마다 동일한 결과를 얻기 위해 분할을 고정
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
## 분할 확인을 위해 새로운 데이터셋의 형태(shape) 출력
print("\n--- Data Split ---")
print("X_train shape:", X_train.shape) ## 학습 특징
print("X_test shape:", X_test.shape) ## 테스트 특징
print("y_train shape:", y_train.shape) ## 학습 타겟 값
print("y_test shape:", y_test.shape) ## 테스트 타겟 값
이제 터미널에서 스크립트를 다시 실행하세요:
python3 main.py
DataFrame 아래에 새로 생성된 학습 및 테스트 세트의 형태가 출력되는 것을 볼 수 있습니다. 이는 데이터가 올바르게 분할되었음을 의미합니다.
--- Data Split ---
X_train shape: (16512, 8)
X_test shape: (4128, 8)
y_train shape: (16512,)
y_test shape: (4128,)
sklearn.linear_model에서 LinearRegression 모델 초기화하기
이 단계에서는 선형 회귀 모델을 생성합니다. scikit-learn을 사용하면 매우 간단합니다. sklearn.linear_model 모듈에서 LinearRegression 클래스를 가져와 인스턴스를 생성하기만 하면 됩니다.
이 인스턴스는 선형 회귀 알고리즘을 포함하는 객체입니다. 선형 회귀는 y = mx + b 공식을 사용하여 데이터 포인트에 가장 잘 맞는 직선을 찾습니다. 여기서 m은 각 특징에 대한 계수(가중치)이고, b는 절편입니다. 여기서는 대부분의 기본 사례에 잘 작동하는 기본 매개변수를 사용합니다.
 그림 1: 선형 회귀 공식 y = mx + b (m은 기울기, b는 절편)
그림 1: 선형 회귀 공식 y = mx + b (m은 기울기, b는 절편)
main.py 파일에 다음 코드를 추가하세요. 이 코드는 LinearRegression 클래스를 가져오고 모델 객체를 생성합니다.
from sklearn.linear_model import LinearRegression
## 선형 회귀 모델 초기화
model = LinearRegression()
## 모델이 생성되었는지 확인하기 위해 출력
print("\n--- Model Initialized ---")
print(model)
터미널에서 main.py 스크립트를 다시 실행하세요:
python3 main.py
이제 출력에 LinearRegression 객체를 보여주는 줄이 포함됩니다. 이는 모델이 성공적으로 초기화되었음을 의미합니다.
--- Model Initialized ---
LinearRegression()
model.fit(X_train, y_train)으로 모델 학습하기
이 단계에서는 모델을 학습시킵니다. 이 과정을 흔히 모델을 데이터에 "피팅(fitting)"한다고 합니다. 피팅하는 동안 모델은 특징(X_train)과 타겟 변수(y_train) 사이의 관계를 학습합니다. 선형 회귀의 경우, 이는 타겟을 가장 잘 예측하기 위해 각 특징에 대한 최적의 계수를 찾는 것을 의미합니다.
모델 객체의 fit() 메서드를 사용하고 학습 데이터를 인자로 전달합니다.
main.py 파일에 다음 코드를 추가하세요.
## 학습 데이터로 모델 피팅(학습)
## fit() 메서드는 특징(X_train)과 타겟(y_train) 사이의 관계를 학습합니다
## 최소 제곱 최적화를 사용하여 각 특징에 대한 최적의 계수와 절편을 계산합니다
model.fit(X_train, y_train)
## 피팅 후, 모델은 계수와 절편을 학습했습니다.
## 절편은 모든 특징이 0일 때의 예측값을 나타냅니다
print("\n--- Model Trained ---")
print("Intercept:", model.intercept_)
이제 터미널에서 스크립트를 실행하세요:
python3 main.py
스크립트가 실행된 후, 출력에서 선형 회귀 모델의 절편을 보여주는 새로운 섹션을 볼 수 있습니다. 절편은 모든 특징 값이 0일 때의 예측값입니다. 여기서 수치 값을 확인하면 모델이 데이터에 대해 성공적으로 학습되었음을 알 수 있습니다.
--- Model Trained ---
Intercept: -37.023277706064185
model.predict(X_test)로 테스트 데이터 예측하기
마지막 단계에서는 학습된 모델을 사용하여 예측을 수행합니다. 이것이 예측 모델을 구축하는 궁극적인 목표입니다. 학습 중에 모델이 본 적 없는 테스트 데이터(X_test)를 사용하여 성능을 평가합니다.
학습된 모델 객체의 predict() 메서드를 사용하고 테스트 특징(X_test)을 인자로 전달합니다. 이 메서드는 타겟 변수에 대한 예측값 배열을 반환합니다.
main.py 파일에 다음 코드를 추가하세요.
## 테스트 데이터로 예측 수행
## predict() 메서드는 학습된 계수와 절편을 사용하여 예측값을 계산합니다
## 공식: prediction = intercept + (coeff1 * feature1) + (coeff2 * feature2) + ...
predictions = model.predict(X_test)
## 첫 5개의 예측값 출력 (단위는 $100,000)
print("\n--- Predictions ---")
print(predictions[:5])
이제 터미널에서 전체 스크립트를 마지막으로 실행하세요:
python3 main.py
이제 출력에 테스트 세트에 대한 첫 5개의 예측 주택 가격이 포함됩니다. 이 값들은 X_test의 특징을 기반으로 모델이 판단한 중간 주택 가격입니다. 모델의 정확도를 측정하기 위해 이 예측값들을 y_test의 실제 값과 개념적으로 비교해 볼 수 있습니다.
--- Predictions ---
[0.71912284 1.76401657 2.70965883 2.83892593 2.60465725]
축하합니다! scikit-learn을 사용하여 선형 회귀 모델을 성공적으로 구축, 학습 및 사용했습니다.
matplotlib.pyplot.scatter()를 사용하여 모델 예측 시각화하기
마지막 단계에서는 모델의 성능을 더 잘 이해하기 위해 시각화를 수행합니다. 시각화는 원시 숫자만으로는 알기 어려운 패턴과 관계를 파악할 수 있게 해주므로 머신러닝에서 매우 중요합니다.
실제 주택 가격(y_test)과 모델의 예측값을 비교하는 산점도(scatter plot)를 생성합니다. 이러한 유형의 플롯을 "예측값 vs 실제값" 산점도라고 합니다. 모델이 완벽하다면 모든 점은 예측값과 실제값이 같은 대각선(45도 선) 위에 위치할 것입니다.
matplotlib을 사용하여 이 시각화를 생성하고 이미지 파일로 저장합니다.
main.py 파일에 다음 코드를 추가하세요:
import matplotlib.pyplot as plt
## 실제값 vs 예측값을 비교하는 산점도 생성
plt.figure(figsize=(10, 6))
plt.scatter(y_test, predictions, alpha=0.5, color='blue', edgecolors='black')
## 완벽한 예측을 보여주는 대각선 추가 (예측값 = 실제값)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', linewidth=2, label='Perfect Prediction')
## 레이블 및 제목 추가
plt.xlabel('Actual House Prices ($100,000)')
plt.ylabel('Predicted House Prices ($100,000)')
plt.title('Linear Regression: Actual vs Predicted House Prices')
plt.legend()
plt.grid(True, alpha=0.3)
## 플롯을 파일로 저장
plt.savefig('housing_predictions.png', dpi=300, bbox_inches='tight')
plt.close()
print("\n--- Visualization Complete ---")
print("Plot saved to housing_predictions.png")
이제 터미널에서 전체 스크립트를 실행하세요:
python3 main.py
플롯이 저장되었다는 확인 메시지가 표시됩니다.
--- Visualization Complete ---
Plot saved to housing_predictions.png
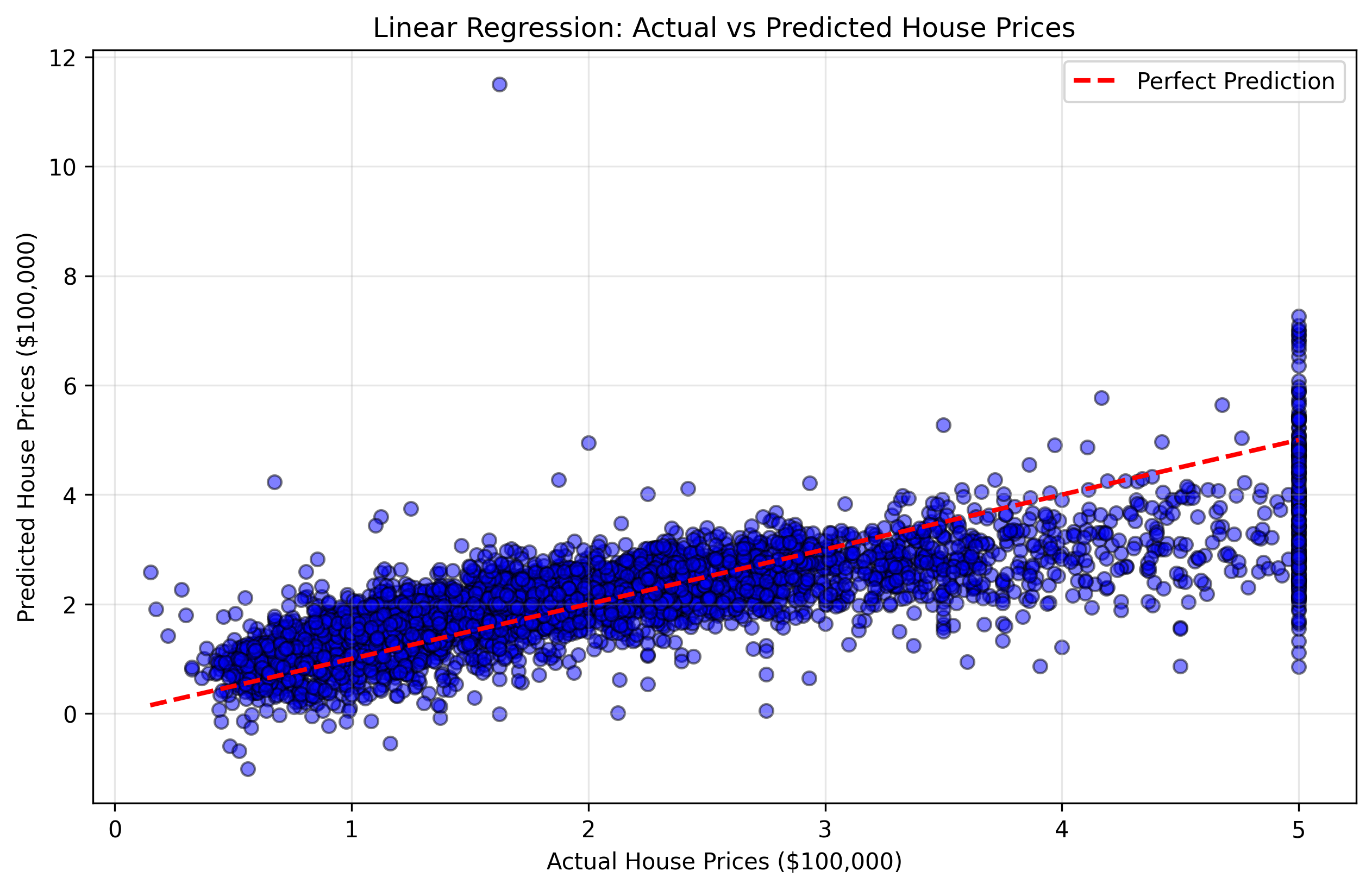 그림 2: 실제 주택 가격과 예측 주택 가격을 보여주는 산점도. 빨간색 대각선에 가까운 점일수록 더 나은 예측을 의미합니다.
그림 2: 실제 주택 가격과 예측 주택 가격을 보여주는 산점도. 빨간색 대각선에 가까운 점일수록 더 나은 예측을 의미합니다.
이 시각화를 통해 다음을 이해할 수 있습니다:
- 대각선 근처의 점들: 모델이 정확하게 예측한 좋은 사례
- 대각선에서 멀리 떨어진 점들: 모델이 큰 오차를 보인 좋지 않은 예측 사례
- 전반적인 패턴: 모델이 특정 가격 범위에서 과대평가하거나 과소평가하는 경향이 있는지 여부
파일 탐색기에서 housing_predictions.png 파일을 더블 클릭하여 시각화를 확인할 수 있습니다.
축하합니다! scikit-learn을 사용하여 선형 회귀 모델을 성공적으로 구축, 학습, 테스트 및 시각화했습니다.
요약
이번 실습에서는 scikit-learn을 사용하여 기본적인 머신러닝 모델을 구축하는 전체 워크플로우를 완료했습니다.
캘리포니아 주택 데이터셋을 불러오고 pandas를 사용하여 준비하는 것부터 시작했습니다. 그런 다음 데이터를 학습 세트와 테스트 세트로 분할하는 것의 중요성을 배우고 train_test_split을 사용하여 분할을 수행했습니다.
이어서 LinearRegression 모델을 초기화하고, fit() 메서드를 사용하여 학습 데이터로 학습시켰으며, 학습된 모델을 사용하여 predict() 메서드로 보지 못한 테스트 데이터에 대한 예측을 수행했습니다. 마지막으로 결과를 시각화하여 모델의 성능을 이해했습니다.
이번 실습은 scikit-learn의 탄탄한 기초를 제공합니다. 이제 다음과 같은 더 고급 주제를 탐색해 볼 수 있습니다:
- 모델 평가: 평균 제곱 오차(MSE)나 R-제곱(R-squared)과 같은 지표를 계산하여 모델 정확도 측정
- 데이터 시각화: 잔차 플롯(residual plots), 특징 중요도 차트, 상관 행렬 등 더 고급 플롯 생성
- 특징 스케일링: 더 나은 성능을 위해 특징 표준화 또는 정규화
- 규제(Regularization): 과적합을 방지하기 위해 Ridge 또는 Lasso 회귀 사용
- 교차 검증(Cross-validation): k-fold 교차 검증을 사용한 더 강력한 평가
- 기타 알고리즘: 랜덤 포레스트(Random Forest), 서포트 벡터 머신(Support Vector Machines) 또는 신경망(Neural Networks) 시도


